
【話題の話題】AI学習とSNSの関係について調べてみた

はじめに
Xの規約変更をきっかけに、イラストの生成AI対策が加速していて興味深い現象が起きています。個人的には、今まで高解像度だったり大きなサイズの画像を無邪気に公開して被害に遭うことの多かった絵描きさんが、自衛策を考えるようになったのはいい事だと思っています。(正直、現状の対策はAIより悪意ある人間に有効だと思いますが)
とはいえ、なんだか世の中にはいろんな意見が出ていて、Aが正しいと言う人もいれば、Aは誤り、Bが正しいと言う人もいれば、Cじゃなきゃ意味がないと言う人もおり……なんだかこんがらがってきたので、自分で調べてみました。
長くなるので、まずは発端となったXの規約の話から。
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
【前提】あくまで素人が自分で調べた内容のごく個人的なレポートです。
(このnoteは私個人が興味を持ったことについて調べて発表する「大人の自由研究ノート」なので)
自分で調べて自分で考えるか、ちゃんとした専門家に相談するのがベスト!
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
※こちらの記事への引用については、引用の要件を満たしているため、特に事前承諾が必要のないものと認識しています。あらかじめご了承ください
結論

規約上、Xに投稿するあらゆる内容について、X社製のAIの学習を許可することになるが、他社製AIからは守られる確率が高くなる。また、X社製AIの学習については、アカウントを非公開にするか、Grokの設定の部分でオプトアウトが可能(学習を許可しない選択ができる)。
Xは自社以外の会社にXのポストを利用して利益を得ることを許さない方針に転換している様子が見受けられる。AI学習の利用についても、他社製のAI学習の活用については徹底的にガードすることに腐心している。
だが、自社製のAIには利用者の投稿を2023年9月からすでに利用しており、今回の規約変更により、それを明文化した。よって「Xの利用者は原則X社製のAIによるポスト全般のAI学習を、サービス提供の対価として許可する」ことになる。もしくは、2023年9月~2024年11月15日までは断りなくデータが利用されていたが、Grokの設定項目で拒否すること(オプトアウト)が可能である。
色々調べた中でこちらの記事がわかりやすかったです。
結論に至るまでの過程
Xの利用規約について
Xの利用規約は差分取りつつ他社と比較して確認してはいるんだけど、for any purposeという表現がちょっと乱暴すぎて退くならここなのかなーと思ってしまった サードパーティ含むAI学習よりそっちのほうがずっと気になってしまった
2024年11月12日 14:48 Silentroom
Xの利用規約変更の件 書影のアップをどうしたらいいか、いくつかの編集部に問い合わせたところ、今のところ全社から『現状そのままで問題ない』との返答をいただきました。 法務部の見解を教えてくださったところもあるので一部だけ抜粋すると、【投稿データの学習利用については著作権法で著作権者の同意なく著作物のAIの学習利用が認められているので、規約の変更に関係なく、公開されている著作物に関してはXに投稿されていてもいなくても学習がされます】 とのことでした。 例外として【特定の作家のイラストを再現し出力するためにその作家のデータだけ学習させる場合は著作権法に違反する】そうなのですが、それはもう倫理観の問題ですよね
Xから移ろうが移るまいがインターネットに載せた時点で画像を盗られる可能性がある。 だったら規約に記載するXのほうが良心的
その辺りがよくわからない
現行の法律で取り締まれないのであれば新しいルールを作るべきなのでしょうが、新しい技術に法律が追いついていないんでしょうね
作家の皆様はどうされます
皆様の書影を見るのが楽しみだったのに
本当に難しい
午後5:54 · 2024年11月9日 田沢みん
現役エンジニアです。 11/15のXの利用規約に関して、現時点で分かっていることをなるべく正確に整理してみました。
まず、今回の規約変更のうち問題となっているAIの文言追加は、X社いわく「明確化」が目的です。この前提をまず頭に入れてください。 https://privacy.x.com/ja/blog/2024/updates-tos-privacy-policy…
その上で変更箇所を見ていきましょう。
今回のAIに関する変更は、サービス利用規約とプライバシーポリシーの両方に含まれています。
サービス利用規約
このページの変更は、第3条「本サービス上のコンテンツ」のところで、「生成型か他のタイプかを問わず、当社の機械学習や人工知能モデルへの使用やトレーニングなど」という文言が追加されています。
これは「お客様によって提供されたテキストやその他の情報を分析し、その他の方法で本サービスを提供、促進、改善する権利」を具体的に例示したものです。そしてこれが何を意味するかは、ヘルプセンターで明らかになっています。
それによれば、個人が提供する情報や公開ポストを含むメタデータをAIにトレーニングさせることで「Xは検索結果やコンテンツの要約など、より優れたサービスを提供できる」と説明しています。
そして公開ポストについては、フォロワーのみに限定したり、ポストを削除したりすることで「保護」できるとし、また基盤となる生成モデルのトレーニングに公開ポストを使わないようにオプトアウトできるとも書いてあります。
https://help.x.com/ja/rules-and-policies/data-processing-legal-bases…
オプトアウトについては、以下のページへのリンクを案内していることから、Grokの設定からオフにすることを指していると考えられます。 https://help.x.com/ja/using-x/about-grok…
以上のことから、規約に追加された文章は、Grokへのトレーニングも含まれているがオプトアウトできると判断できます。
ただ一方で、基盤モデルのトレーニングに関してはオプトアウト可能という点に留意する必要があります。
つまり、太字で示した以外の用途では使用される可能性があります(個人的にはそれで十分に思いますが人によっては嫌だと思う人もいるかも?)。
一部では、このオプトアウトは11/15からできなくなるという主張が見受けられますが、元々「サービスを提供、促進、改善する権利」に同意をしていて、今までもAIトレーニングに使われていたわけですから、今回AIトレーニングが明記されたからといって、オプトアウトできなくなると考えるのは論理の飛躍というものでしょう。
今回の変更の目的が、あくまで「明確化」である点とも矛盾します。
プライバシーポリシー
次にプライバシーポリシーですが、こちらは、第三者の協力会社へのデータ提供およびその目的についてAIにトレーニングさせる場合があるとの文章が追加されています。
これが具体的に何を意味するかは、やはり先ほどと同じくヘルプセンターに答えがあります。
https://help.x.com/ja/rules-and-policies/data-processing-legal-bases…
まず「データ」とは何か。ヘルプセンターによれば、ユーザーがXに共有するアカウント情報、公開情報、連絡先情報、さらにシステムが収集したログなどがあるようです。懸念となる公開ポストなどのコンテンツはこの「データ」には含まれていません。
そしてそれらを協力会社に提供するわけですが、この詳細についてはヘルプセンターのデータ処理に関するページ内から該当する記載を見つけることができませんでした。つまり現段階では具体的にどうするかは不明と言えそうです。
ところで、この追加に関しては、一部メディアがデータとして販売する可能性を示唆しています。具体的には以下の記事です。 https://socialmediatoday.com/news/x-formerly-twitter-updates-terms-service/730223/…
ただその記事は、11/15の規約変更を「単に法的な観点から明確にしたに過ぎない」と結論づけています。
よって、これはあくまで将来的なデータの販売の可能性に言及したものであるとわかります。
そもそも、Xではヘルプセンターにおいて、「XまたはxAIはあなたのデータを販売しません」と明記しています。
https://help.x.com/ja/using-x/about-grok…
もし11/15から販売を始めてしまうと、「AIトレーニングの明確化」という規約変更の目的から逸脱してしまいます。
また、今後そうなった場合、追加された文章には「オプトアウトしていない場合は」と書いてあるため、ユーザーはデータの提供を拒否できると期待して良いでしょう。たぶん…( Xだから不安は拭えない)。
以上です。
そしてここからは私の所感になりますが、別に今回の規約変更自体は大した問題ではないと思います。 X自体は7月末から公開ポストをGrokのトレーニングに使っていたわけですから、規約変更よりもずっと前から問題は顕在化していたと認識するべきでしょう。 https://japan.cnet.com/article/35222068/…
つまり対策をするなら11/15を待たずに行った方が良いと言えるし、今更とも言えます。
本投稿が今後の活動方針の参考になれば幸いです。
最終更新午後0:28 · 2024年11月13日 なろうファンDB管理人@スコッパー
深層学習のやり方見ても、日本の法律を見てもXのAI利用規約はなんの問題もなさそうだなあと思う。数億単位の絵を食わせる基盤学習モデルで、たかが数枚の絵を食わせたところでそれを再現させるには膨大な時間がかかると思う。
午前9:35 · 2024年11月15日 MASA
ここには冷静な方の意見を取り上げましたが、X(Twitter)って規約変更のたびに憶測が飛び交って大騒ぎになるイメージなんですけど、規約に書いておかないと裁判になっちゃうから書いておく必要があることを、拡大解釈している場合もこれまで多々ありました。
今回のケースは「もともとAI学習に使用していたけれど、それを明文化した」ということが主題のようで、言ってしまえば暗黙の了解としていたことを規約に記しただけ、とも考えられる。その点を踏まえて、"自分にとって"使い続けたいサービスと思えるかどうか判断すればいいと思います。
企業側が行動しているのは、規約に明文化されたことによって、契約としての効力を発揮してしまうからじゃないかなーというのが、個人的な想像。
<参考>基盤モデルとは?
オプトアウトは有効か

これ、書きぶりがなかなかいじわるというか、勘違いしやすい項目だなと思います。解釈が二通りできる。
「Xのポストに加えて」と書いているので、「XのポストはAI学習されている前提」で、さらにGrokとのやり取りを許可するということだと私は解釈しましたが、後半は単に「これは、やり取り、インプット、結果が……」と書いてあるので、「XのポストとGrokのやり取りを(X社等の)AIの学習に使う許可をするか」とも解釈できなくもない。そのため、「Grokの項目にチェックを入れても学習は防げない」と言う人と、「これがAI学習を拒否するチェックボックスだ」と解釈している人も散見されました。
正直なところ、私はこの文章だけではどっちのことを言っているのか、判断しきれません。
色々飛び交っている情報をまとめると、「Xに限らずどこでもAI学習にイラストは使われてしまうが、Xはそれを規約に明文化している(自社製のAI学習に使用することを規約で合意させるが、設定で拒否することも可能?な)SNS」ということかなという印象です。
("「うちはAI学習反対です!」と明文化しているSNSやサービスがあるからそっちを利用する!"という人もいて、そういう感じでサービスを選ぶのもアリですね)
Xに問い合わせた方がいた!
Grokのチェックボックスについては、こういった意見があったので、調べてみました。
オプトアウトの設定画面の日本語が誤訳なんじゃないか説、一応問い合わせてるけど返信が来るかは分からん
午前3:26 · 2024年10月20日 ろぼいん
返信きた!! 結論としては、やっぱり日本語版の翻訳は誤訳で、【ポストがGrokに学習されないようにオプトアウト可能】ということが分かった。 つまり、オプトアウト設定(3枚目)は自分のデータを一切Grokの学習に使わないでね、という設定。
午前4:04 · 2024年10月25日 ろぼいん



引用元の方のブログ記事:
<回答の翻訳>
Hi, If you turn off the setting labeled 'Allow your posts as well as your interactions, inputs, and results with Grok to be used for training and fine-tuning.' your posts will no longer be used to train Grok. This setting encompasses not just your interactions, inputs, and results with Grok, but also your posts.
By disabling this option, you optout of having any of your data, including your posts, utilized for toraining and fine-tuning Grok. Hope this helps!
こんにちは。「'あなたの投稿とGrokとのインタラクション、入力、結果をトレーニングや微調整に使用することを許可する'という設定をオフにすると、あなたの投稿はGrokのトレーニングに使用されなくなります。この設定は、Grokとのインタラクション、入力、結果だけでなく、あなたの投稿も含まれています。このオプションを無効にすることで、あなたの投稿を含むデータがGrokのトレーニングや微調整に利用されることを拒否することになります。お役に立てれば幸いです!
ただ、「Grok関連のやりとりだけでなく、投稿すべてをX社のAIに利用させないよう拒否できる」のならば、もっとわかりやすくできなかったのかなーという引っ掛かりもあります。(よく考えると、Grokに学習させないだけで、Grok以外の命名のAIがあるor出てきた場合は話が別になるなとか……)
投稿全般の許可・拒否であるならば、別項目、もしくは、データ共有とカスタマイズ項目の直下にある「ビジネスパートナーとのデータ共有」みたいに「X社製AIとのデータ共有」もしくは「xAIとのデータ共有」項目を設けるとかだったらわかりやすかったのでは。
実際英語ではどう表記されているのかなーと思っていたら、自分のアカウントにこんな表示が出たので、これが元の文章かな? と推測。


"Grokとほかの協力会社たち
あなたの公開データに加えて、やりとり、入力、結果をGrokおよびxAIのトレーニングと微調整に使用することを許可してください。”
(as well as "同様に" とあるので、「公開データ、やりとり、入力、結果」すべてを同等に扱って、「あなたが投稿する事柄全般をGrokとxAIのトレーニングに許可してね」→Yes or Noとも解釈できる。翻訳のニュアンスが難しい)
”Xは、あなたのXの公開データや、Grokとのユーザーインタラクション、入力、結果をxAIと共有する場合があります。これらのデータは、GrokおよびxAIが開発した他のAIモデルのトレーニングや微調整に使用されます。これにより、私たちはあなたのユーザー体験を継続的に向上させることができます。”
(上記の翻訳)
うーん。どっちかわからなくなってきたぞ。
「Grok関連の許可のみ」のチェックボタンの疑いがまだ晴れない……(「会話履歴を削除」からもそう推測してしまう)。
ではもっと深堀して、先の回答の裏付けを取ってみましょう。
そもそもGrokってどんなAI?
https://help.x.com/ja/using-x/about-grok
Xでは絵描きさんの間で懸念が広がったことから画像生成AIのように勘違いされがちですが、Grokはあくまで大規模言語モデル(LLM)であり、検索機能ありの会話ができるAIであって、これそのものが画像生成AIではないことがわかります。
Grokはどのように訓練されていますか?
Grok-1は、今日のほとんどのLLMと同様に、2023年第3四半期までにインターネット上で公開されたさまざまなテキストデータと、人間のレビュー担当者であるAIチューターによってレビューおよびキュレーションされたデータセットに基づき、xAIによって事前トレーニングされています。なお、Grok-1はXデータ(Xの公開ポストを含む)で事前トレーニングされていません。Grokのトレーニング プロセスの概要については、xAIウェブサイトとモデルカードで説明しています。
改善点
Xではユーザー体験を継続的に改善するため、お客様によるXのポスト、Grokでのやり取り、インプット、結果を、トレーニングや微調整の目的に活用する場合があります。このことは、Grokとのコミュニケーションの際、そのやり取り、インプット、結果がシステムのパフォーマンスのトレーニングおよび強化のために使用される可能性があることも意味します。これにより、次のことが可能になります。Grokが人間の言語およびコミュニケーションを理解する能力を強化します。
Grokが正確で関連性のある、魅力的な回答を提供する能力を向上させます。
Grokのユーモアのセンスと機知を養い、コミュニケーションをより楽しいものにします。
Grokが政治的に偏りがなく、バランスの取れた回答を提供できるようにします。
Xがお客様によるポスト、Grokでのやり取り、インプット、結果を、トレーニングや微調整の目的に使用するための条件を、お客様は以下の方法で管理できます。また、アカウントを非公開にすることで、お客様のポストをGrokのトレーニングに使用させなくすることもできます。
モデルトレーニングをオプトアウトするにはどうすればよいですか?
お客様はGrokユーザーとして、Xがお客様によるポスト、Grokでのやり取り、インプット、結果を使用して、基盤モデルのトレーニングや微調整を行う条件を柔軟に管理できます。以下に、Xでプライバシー設定を管理してオプトアウトする方法を示します。X設定にアクセスして [プライバシーと安全] を選択します
[データ共有とカスタマイズ] を選択します
[Grok] を選択します
[データ共有] が表示されます
[ポストに加えて、Grokでのやり取り、インプット、結果をトレーニングと調整に利用することを許可する] オプションをオンにします。
”Xがお客様によるポスト、Grokでのやり取り、インプット、結果を、トレーニングや微調整の目的に使用するための条件を、お客様は以下の方法で管理できます。また、アカウントを非公開にすることで、お客様のポストをGrokのトレーニングに使用させなくすることもできます。”
やっと、X社に問い合わせた方が得た回答と合致した!
これをオプトアウトの項目の文言としてのせればよかったのでは……
また、X社が他社にデータを売るかについては、「売らない」と明言されています。自身のデータの取り扱いに不安がある場合は、問い合わせもできるようです。

Blueskyの状況
Blueskyの声明に歓喜する人もいるが実際は……
<Bluesky公式の投稿>
A number of artists and creators have made their home on Bluesky, and we hear their concerns with other platforms training on their data. We do not use any of your content to train generative AI, and have no intention of doing so.
”多くのアーティストやクリエイターがBlueskyを拠点にしており、他のプラットフォームが彼らのデータを利用していることに対する懸念を聞いています。私たちはあなたのコンテンツを生成AIのトレーニングに使用することはなく、今後もそのつもりはありません。” (上記内容の翻訳)
<それに対する意見>
ブルスカは自社AI無いので使用するも何も…良くも悪くも技術屋の言葉だ Xはデータは自社AIで使うけど外部の有象無象は旨み啜れないようにクローラーを締め出す ブルスカはデータは自社AI無いので“ウチは”使わないけどクローラー対策してないので外部の有象無象には抜き出される可能性あるってだけの話
俺もこの認識だけどなぁ( ´)Д(`)



結果的に、X社製AIにだけAI学習を許可する(もしくはオプトアウトで拒否する)か、X社製AIを含めたあらゆる生成AIによる学習を黙認する(もしくは自衛でなんとかする)かの二択になってしまっているのが現状と推測されます。
クローリング:
(前略)技術的な文脈では、ウェブクローラーがインターネット上の情報を自動的に収集する行為を指すこともある。
Blueskyでできる対策って?
Blueskyについては、モデレーションの設定でアカウントの非公開が有効というpostがXでバスっていましたが、実はたいした対策にはならないのが現状です。

注記の部分にあるように「他のアプリではこの設定を尊重しない場合があります」という記述があります。あくまで知識のない人が何気なくアクセスしたときに見えない設定なだけで、AI学習を考えるような知識のある人に対しては無意味な対策であることが推測できます。
そもそもBlueskyのスタンスが「なんでもオープンにするSNS」であることに留意が必要です。「Blueskyで公開されている内容はこちらを参照してください。」をクリックして詳細を確認するとそのことがよくわかります。
Why are my posts, likes, and blocks public?
The AT Protocol, which Bluesky is built on, is designed to support public conversations. To make public conversations portable across all sorts of platforms, your data is stored in data repositories that anyone can view. This means that regardless of which server you choose to join, you’ll still be able to see posts across the whole network, and if you choose to change servers, you can easily take all of your data with you. This is what causes the user experience of Bluesky, a federated protocol, to be similar to all the other social media apps you have used before.
<翻訳>
なぜ私の投稿、「いいね」、ブロックが公開なのですか?
BlueskyはATプロトコルに基づいており、公開の会話をサポートするために設計されています。公開の会話をさまざまなプラットフォーム間で移動できるようにするため、データは誰でも閲覧可能なデータリポジトリに保存されています。どのサーバーに参加しても、ネットワーク全体の投稿を見られ、サーバーを変更する際もデータを簡単に持って行けるという特徴があります。これにより、Blueskyのユーザー体験は、他のソーシャルメディアアプリと似たものになります。
つまり、この設定はアカウントをもっている(AI学習や無断転載を目的としている)ユーザーであれは効果がないのはもちろん、非公式アプリやAPIでは普通に閲覧できるということがわかります。
生成AIユーザーをまとめてブロックできるリストというものを作っている方もいるので、そういうものを活用している方もいるようです。たくさんリストができているようなので、一部を紹介します。
(これが有効かどうかは私にはわかりませんが、気持ちが落ち着くならやってもいいと思います。少なくとも生成AIイラストは見なくて済むので)
Bluesky上の生成AIユーザーリスト



XからBlueskyに移動する理由は様々で、生成AIから守られているか否かだけが問題ではない(X社が気に入らない・X社だけに利益を独占されたくない・規約に明記されているのが積極的にAIを許容するようで嫌だ……等)とは思いますが、もし単純に「ともかく生成AIに利用されたくない」という場合は、Blueskyは最適な移動場所ではないかもしれません。
他のSNSは?
① Instagram/Threads
これはかなりざっくりした私見ですが、Instagramはユーザーのデータを自社のために積極的に利用している印象。無料サービスの対価として自身の投稿の利用を許諾するという意味では、そう変わりはない気がします。
ザッカーバーグ氏の全てのプロジェクトは、大量のデータを収集することで知られています。おそらく、個人情報の収集に関してザッカーバーグ帝国に匹敵するのは、遍在的な Googleでしょう。
Threadsも例外ではありません。App Storeのプライバシーに関する説明によりますと、このSNSは手当たり次第全てのユーザーデータを収集します。ただし、留意すべき点がいくつかあります。まず、収集されるデータのリストはInstagramのものと同じです。
とはいえInstagramもオプトアウトが可能なので、この機会にチェックしておくのもいいかもしれません。
② Mastodon/Misskey
Mastodon: 海外製のSNSで、分散型(https://joinmastodon.org/ja/servers)
Misskey: 日本製のSNSで、分散型(https://misskey-hub.net/ja/servers/)
MastodonもMisskeyも個人の有志によって運営されているため、その性格は様々です。ただ、機能として以下のようなものが使えるようなので、それを設定できるようにしている場所を選ぶのも、ひとつの方法かもしれません。
ただし、分散型SNSにも当然デメリットがあります。自身で良く調べて、本当に自分に合っているか検討する必要があります。
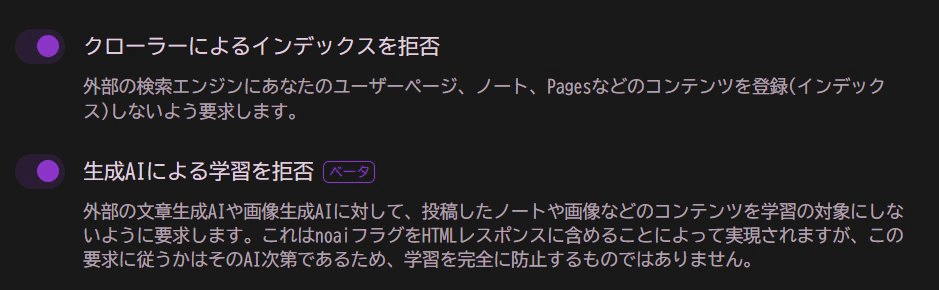
MisskeyはAI学習拒否表示とクローラー対策の設定があるよ。
午前7:43 · 2024年10月17日 べるふぁ
日本製で中央集権型のSNSとしては、タイッツーやくるっぷといったサービスも出ているようですが、まだまだユーザー数が少ない。それでも、自分に合うと考えて楽しく使っている方もいて、少しずつコミュニティが育っているのではないでしょうか。単なるユーザー数だけではなく、サービスそのもののスタンスが自分に合っているかでSNSを選ぶ時代になってきたのかもしれません。
個人的には、Twitter一強の世界ではなく、様々なコミュニティができている現状は、それなりに面白い世界になってきたように感じます。
こんな場所もあったので、参考に。
※この情報はあくまで2024年11月19日現在のものです※