
【画像系AI講座】ConvNeXt V2とは何か?解説します!

この記事では、ConvNeXt(V1)(ConvNeXt-V1と呼びます)からの進化形であるConvNeXt-V2について、その仕組みや改善点を紹介します。
ConvNeXtって?
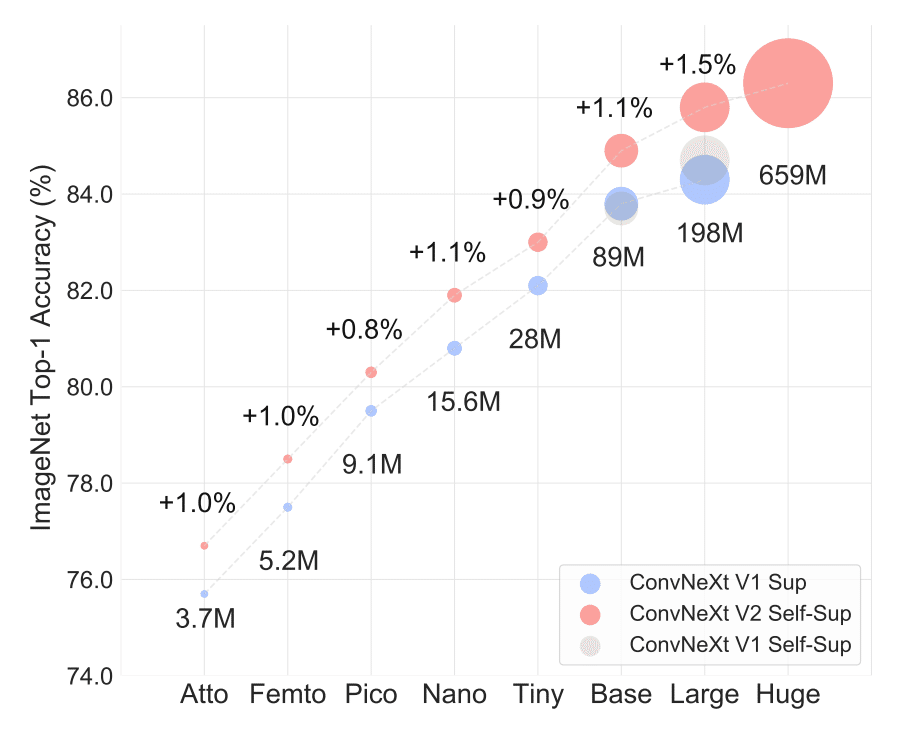
ConvNeXt-V1/V2は画像系のタスクで用いられる、CNNをベースにしつつもVision Transformerの構造を模したモデルです。画像分類タスクだけではなく、セマンティックセグメンテーションや物体検出モデルのバックボーンとしても用いられます。ConvNeXt-V2はConvNeXt-V1と比較して、ImageNet-1KのValidationデータセット上でのTop-1精度で一貫して高いスコアを出しています。
様々な画像分類モデルをお手軽に利用できるライブラリであるtimm(PyTorch Image Models)でも提供されており、以下のように使用できます。
# ConvNeXt-V1
import timm
import torch
# timm==v0.6.12を使用しました
convnext = timm.create_model("convnext_tiny_384_in22ft1k")
convnext.eval()
with torch.inference_mode():
prediction = convnext(your_input_image)開発バージョン(2023年3月23日時点)ではConvNeXt-V2も使用可能になっています。
# ConvNeXt-V2
import timm
import torch
convnext = timm.create_model("convnextv2_tiny.fcmae")
convnext.eval()
with torch.inference_mode():
prediction = convnext(your_input_image)この記事の構成
ConvNeXt-V2における重要な改善点は以下の2つです。
(1) 自己教師あり学習を用いた事前学習の導入
(2) アーキテクチャの一部を改善
この記事では上の2点の解説を順番に行います。それではさっそく(1)からみていきましょう!
Masked Autoencoders(MAE)を用いた事前学習をCNNに対して適用する
このセクションでは、自己教師あり学習やその一種であるMAEを振り返ってから、MAEをCNNに適用する際に発生する問題とその解決方法を紹介します。また、おまけとしてMAEやConvNeXt-V2のエンコーダーの実装の一部を紹介します(内容には直接関係ないのでConvNeXt-V2の概要だけを確認したい方は飛ばしていただくことも可能です)。
自己教師あり学習とは?
MAEとは自己教師あり学習の手法の一つで、自己教師あり学習とは、入力データ(画像に絞って入力画像と呼びます)からあるルールに従って正解ラベル(手動または半自動でつけられた正解ラベルと区別するために自己教師あり学習で作られる正解ラベルを擬似正解ラベルと呼ぶことにします)を自動的に作り出し、それをもとに特徴量の学習を行う手法のことを指します。自己教師あり学習を用いることで、画像分類など画像に関連するさまざまなタスクを解く上で有用な特徴量を学習できることが知られています。次の画像は自己教師あり学習の一例です。

あべこべにされた入力画像(b)から元の画像の並び(c)を予測するタスクを解くことで、画像分類・物体検出・セマンティックセグメンテーションなどさまざまな画像に関連するタスクに有用な特徴量を学習することができます。正解ラベルを持たないデータセット上でも学習を行えるので、より大きなデータセットを準備しやすいという利点があります。これにより、正解ラベルを持たない大規模なデータセットで自己教師あり学習を用いて特徴量を学習した後、正解ラベルを持つデータセットでモデル全体をファインチューニングすることで精度をよりよくするといった手順を踏めるようになりました。事前学習時に解くタスクを上流タスク、ファインチューニング時に解くタスクを下流タスクと呼びます。
MAEとは?
MAEは自己教師あり学習の一種で、入力画像を細かいパッチに分割した上で、大多数のパッチをマスクして元の画像を再構成するタスクが設定されます。損失関数としてMean Squared Error(MSE)が使用されます。モデルにはVision Transformer(ViT)で構成されるエンコーダーとデコーダーが使用されます。

こちらがMAEの全体図です。エンコーダーとデコーダーにはViTが用いられます。エンコーダーへの入力列からマスクされたパッチは除外されます。グレーの四角は[MASK]トークンを表しており、再構成する対象を表します。エンコーダーによって得られたトークンベクトルと[MASK]トークンのトークンベクトルがデコーダーに入力され、再構成されたパッチとマスクする前のパッチで再構成誤差を計算して誤差信号として使用します。上流タスクでの学習が完了後、エンコーダーのパラメーターの値で初期化を行って下流タスクでファインチューニングを行います。どのようにマスキングが行われるのか具体例を通して確認してみましょう。

ImageNet(Validation)上での入力画像(左)・予測結果(真ん中)・擬似正解ラベル(右)です。入力画像において、196個のパッチの内、157個のパッチがマスクされています。大多数のパッチがマスクされているので、再構成した結果はぼやけていたり内容が若干違っていたりするものの、擬似正解ラベルと比較してそれらしい内容を再構成できていることがわかります。これは、多様な画像に対してMAEが一般化できていることを示唆しています。
ここで、MAEのエンコーダーへの入力列からマスクされたパッチが除外されていることに注目してみます。[MASK]トークンを使用する代わりに入力列から除外することで計算量を減らす目的もありますが、こうすることで、入力画像のパッチ間で情報のリークを防いで下流のタスクに有用な特徴量を学習できるメリットがあります。この点についてもう少し詳しくみてみましょう。
☕ 入力列に対する前処理(おまけ)
MAEのエンコーダーへの入力列の作成方法についてもう少し詳しく知るため、ソースコードの該当箇所をみてみます。一番最初の引数がマスクをする前のエンコーダーへの入力となります。ViTへの入力と同様に、入力画像を縦h横wの大きさのパッチに分割して並べた列です。カーネルサイズとストライドをパッチサイズに設定したConvolutionを適用した後(この時の入力の形は(バッチサイズ, チャンネル数, h, w)となります)、flattenを使用して(バッチサイズ, チャンネル数, hw)に変形します。最後にtransposeを使用して軸を入れ替えると(バッチサイズ, hw, チャンネル数)となります。以降はバッチサイズ=N、hw=L、チャンネル数=Dとして話を進めます。
# https://github.com/huggingface/pytorch-image-models/blob/7501972cd61dde7428164041b0a6dd8fea60c4d4/timm/layers/patch_embed.py#L25
# PatchEmbedクラス
def forward(self, x):
B, C, H, W = x.shape
_assert(H == self.img_size[0], f"Input image height ({H}) doesn't match model ({self.img_size[0]}).")
_assert(W == self.img_size[1], f"Input image width ({W}) doesn't match model ({self.img_size[1]}).")
x = self.proj(x)
if self.flatten:
x = x.flatten(2).transpose(1, 2) # NCHW -> NLC
elif self.output_fmt != Format.NCHW:
x = nchw_to(x, self.output_fmt)
x = self.norm(x)
return x入力列x(位置エンコーディングが施されています)の各要素に対し、[0, 1]の乱数をサンプルした後、小さい値に対応するインデックスint(L * (1 - mask_ratio))個(Lは入力列の長さでmask_ratioはマスクをするパッチの比率です)だけを残します。また、maskはどのパッチがマスクされたかを参照するために使用されます(マスクされたパッチには1、マスクされていないパッチには0が割り当てられます)。さらに、ids_restoreは元の順番に列を並び替えるために使用されます。損失値を計算する際にはマスクされていないパッチは無視されます。
# https://github.com/facebookresearch/mae/blob/main/models_mae.py
# MaskedAutoencoderViTクラス
def random_masking(self, x, mask_ratio):
"""
Perform per-sample random masking by per-sample shuffling.
Per-sample shuffling is done by argsort random noise.
x: [N, L, D], sequence
"""
N, L, D = x.shape # batch, length, dim
len_keep = int(L * (1 - mask_ratio))
noise = torch.rand(N, L, device=x.device) # noise in [0, 1]
# sort noise for each sample
ids_shuffle = torch.argsort(noise, dim=1) # ascend: small is keep, large is remove
ids_restore = torch.argsort(ids_shuffle, dim=1)
# keep the first subset
ids_keep = ids_shuffle[:, :len_keep]
x_masked = torch.gather(x, dim=1, index=ids_keep.unsqueeze(-1).repeat(1, 1, D))
# generate the binary mask: 0 is keep, 1 is remove
mask = torch.ones([N, L], device=x.device)
mask[:, :len_keep] = 0
# unshuffle to get the binary mask
mask = torch.gather(mask, dim=1, index=ids_restore)
return x_masked, mask, ids_restoreナイーブな方法でMAEをCNNに適用すると発生する問題とその解決策
前のセクションで見た通り、MAEのエンコーダーへの入力列からマスクされたパッチは除外されますが、CNNへの入力は画像の形式を保っている必要があるので、この処理をそのままおこなえません。そこで、マスクされたパッチを除外せずにそのままにして、CNNで構成されたMAEのエンコーダー(CNNで構成されるMAEをFCMAE(=Fully Convolutional Masked AutoEncoder)と呼びます)に入力すると何が起こるのかをみてみます。

左がCNNにMAEをそのまま適用した時に得られる、ImageNet-1KのTop-1精度です(ConvNeXt-Baseをエンコーダーに使用)。すると、下流タスクでファインチューニングを行なった時の精度が著しく下がってしまいました!これは、このような方法で得られたFCMAEのエンコーダーは下流タスクで有用な特徴量を学習できていないことを表します。この現象に対し、著者らはCNNで行われる畳み込み処理に着目しました。

これは畳み込み処理を可視化した図です(こちらを参照しました)。この図のように畳み込み層のストライドが1の場合、処理間で参照する領域が重なってしまいます。すると、FCMAEのエンコーダーはマスクされたパッチを再構成する際にマスクされていないパッチを"コピー"するようになるので下流タスクで有用な特徴量が学習できないのではないかと考えられました。この仮説を検証するため、著者らは点群処理で使用されるSparse Convolutionを用いてマスクされているパッチとマスクされていないパッチが重ならないように畳み込むことを考えました。すると、先程のテーブルの右列で示されるように、下流タスクでの精度が大幅に向上することがわかりました。この仮説が正しいかはともかく、Sparse ConvolutionはFCMAEの問題に対する解決策になりそうです。さらに、ファインチューニングを行う際にはSparse Convolutionを通常のConvolutionに置き換えてそのまま使用することができます。パラメーター自体は同じなので、Sparse Convolutionの値で初期化をおこなうだけです。
☕ 入力画像に対する前処理(おまけ)
前のセクションで見た、MAEのエンコーダーへの入力に対する前処理に対して、FCMAEのエンコーダーへの入力に対する前処理をソースコードを通して確認してみましょう。maskの計算方法は同じですが、入力列xからマスクされたパッチを除外する処理がなくなっています。その代わりに、FCMAEのエンコーダーに画像を入力した後にmaskをかけてパッチをマスクします。
# https://github.com/facebookresearch/ConvNeXt-V2/blob/main/models/fcmae.py
# FCMAEクラス
def gen_random_mask(self, x, mask_ratio):
N = x.shape[0]
L = (x.shape[2] // self.patch_size) ** 2
len_keep = int(L * (1 - mask_ratio))
noise = torch.randn(N, L, device=x.device)
# sort noise for each sample
ids_shuffle = torch.argsort(noise, dim=1)
ids_restore = torch.argsort(ids_shuffle, dim=1)
# generate the binary mask: 0 is keep 1 is remove
mask = torch.ones([N, L], device=x.device)
mask[:, :len_keep] = 0
# unshuffle to get the binary mask
mask = torch.gather(mask, dim=1, index=ids_restore)
return mask上で計算されたmaskと入力画像(まだパッチのマスクが行われていないことに注意してください)はFCMAEのエンコーダーに入力されます。入力後にどのように入力画像にmaskが適用されるのかを確認してみましょう。
# https://github.com/facebookresearch/ConvNeXt-V2/blob/main/models/convnextv2_sparse.py
# SparseConvNeXtV2クラス
def upsample_mask(self, mask, scale):
assert len(mask.shape) == 2
p = int(mask.shape[1] ** .5)
return mask.reshape(-1, p, p).\
repeat_interleave(scale, axis=1).\
repeat_interleave(scale, axis=2)
def forward(self, x, mask):
num_stages = len(self.stages)
mask = self.upsample_mask(mask, 2**(num_stages-1))
mask = mask.unsqueeze(1).type_as(x)
# patch embedding
x = self.downsample_layers[0](x)
x *= (1.-mask)
# sparse encoding
x = to_sparse(x)
for i in range(4):
x = self.downsample_layers[i](x) if i > 0 else x
x = self.stages[i](x)
# densify
x = x.dense()[0]
return xforwardメソッドを見てみると、入力画像にマスクを直接適用するのではなく、Stem(ここではself.downsample_layers[0]です)を適用して入力画像の解像度を4分の1にした後に適用していることがわかります。パッチサイズは32、ステージ数は4がデフォルトなのでupsample_maskをマスクに適用する際にマスクに対応する列(バッチ数 x パッチ数 x トークンベクトルの次元数)を画像(バッチ数 x 縦 x 横)に変換して、PyTorchで定義されるrepeat_interleaveメソッドを使用してマスク画像の解像度を4分の1に変更しています。その後はマスクされた入力画像を疎な表現に変換してからSparse Covolutionを適用します。最後に再び密な表現に変換してからエンコーダーの出力が返されます。各ステージを構成するブロックの内容を確認してみます。
class Block(nn.Module):
""" Sparse ConvNeXtV2 Block.
Args:
dim (int): Number of input channels.
drop_path (float): Stochastic depth rate. Default: 0.0
layer_scale_init_value (float): Init value for Layer Scale. Default: 1e-6.
"""
def __init__(self, dim, drop_path=0., D=3):
super().__init__()
self.dwconv = MinkowskiDepthwiseConvolution(dim, kernel_size=7, bias=True, dimension=D)
self.norm = MinkowskiLayerNorm(dim, 1e-6)
self.pwconv1 = MinkowskiLinear(dim, 4 * dim)
self.act = MinkowskiGELU()
self.pwconv2 = MinkowskiLinear(4 * dim, dim)
self.grn = MinkowskiGRN(4 * dim)
self.drop_path = MinkowskiDropPath(drop_path)
def forward(self, x):
input = x
x = self.dwconv(x)
x = self.norm(x)
x = self.pwconv1(x)
x = self.act(x)
x = self.grn(x)
x = self.pwconv2(x)
x = input + self.drop_path(x)
return xGRNが追加されている理由については次のセクションで説明します。それ以外に気になる点としては、各処理を表す名前にMinkowskiがついている点が挙げられます。これはMinkowskiEngineという疎なテンソルを処理するためのライブラリからきている処理だということを表しています(元のMinkowskiEngineにDepth-wise ConvolutionのCUDAカーネルを追加したライブラリです)。各処理に対して、MinkowskiEngineで定義された処理に置き換えることでブロックを定義しています。下流タスクでファインチューニングを行う際のアーキテクチャも確認してみます。
# https://github.com/facebookresearch/ConvNeXt-V2/blob/main/models/convnextv2.py
class Block(nn.Module):
""" ConvNeXtV2 Block.
Args:
dim (int): Number of input channels.
drop_path (float): Stochastic depth rate. Default: 0.0
"""
def __init__(self, dim, drop_path=0.):
super().__init__()
self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim) # depthwise conv
self.norm = LayerNorm(dim, eps=1e-6)
self.pwconv1 = nn.Linear(dim, 4 * dim) # pointwise/1x1 convs, implemented with linear layers
self.act = nn.GELU()
self.grn = GRN(4 * dim)
self.pwconv2 = nn.Linear(4 * dim, dim)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
input = x
x = self.dwconv(x)
x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)
x = self.norm(x)
x = self.pwconv1(x)
x = self.act(x)
x = self.grn(x)
x = self.pwconv2(x)
x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
x = input + self.drop_path(x)
return xFCMAEのエンコーダーのアーキテクチャと比較したところ、疎なテンソル上で行われる処理が密なテンソル上で行われる処理に置き換わった以外は全く同じなので、事前学習時のパラメーターの値で初期化してそのままファインチューニングできることがわかります。
このセクションのまとめ
MAEをそのままCNNに適用すると「リーク」が発生して下流タスクでの精度が大幅に下がる
Sparse Convolutionに置き換えることでその問題を解決できる
アーキテクチャの改善により特徴量マップの崩壊を防ぐ
このセクションでは、前のセクションで得られたFCMAEを細かく分析することで明らかになった問題とその解決方法を紹介します。そもそもなぜその分析が必要となったのでしょうか?その部分から説明します。
VS 「より強いConvNeXt-V1ベースライン」
無事にMAEをCNNに適用できそうだということがわかりましたが、まだ完全に問題が解決されたわけではありません。次のテーブルを見てください。

ConvNeXt-V1をレシピ通りに学習したベースライン(エポック数=100)の精度は上回ることができたものの、エポック数を300に増やしたところ精度がやや下回ってしまうことがわかりました。これでは、FCMAEが有効であると示されたかといえば"グレー"となりそうです。
ここで、自己教師あり学習は下流タスクに有用な特徴量を学習できるという触れ込みだったので、下流タスクでファインチューニング後に学習した特徴量を詳細に分析することで本当に有用な特徴量を学習できていたかを確認してみるのがよさそうです。著者らは特徴量マップのチャンネル間の類似性という考え方を通してこの分析を行いました。次で説明します。
特徴量マップの崩壊
改善後のFCMAEにより得られたConvNeXt-V1(以降、ConvNeXt-V1 FCMAEと呼びます)を下流タスクでファインチューニングした後、その特徴量マップを分析すると、チャンネル間で類似していたり、値が大きくなり過ぎている傾向が見られることがわかりました。何かしらの原因によって有用な特徴量の学習が妨げられている可能性がありそうです。
ちなみに、この現象はConvNeXt-V1 FCMAEの各ブロックにおける、MLP部分で主に発生していることがわかりました。デフォルトの設定ではMLPの第一層目でチャンネル数を4倍にするのでこのような重複が発生しやすい可能性があります。

これはConvNeXt-V1 FCMAEの特徴量マップを可視化した図です。ConvNeXt-V2 FCMAE(以降で説明する改善をConvNeXt-V1 FCMAEに適用したモデルです)と比較してバリエーションが少なくなっていることがみて取れます。
このような重複が発生している原因を探る前に、特徴量マップにおける重複の度合いを数値化する方法を紹介します。数値化を通して他のモデルと比較することでこの問題をより正確に理解できそうです。

$${X_{i}}$$はある層の特徴量マップのうち、i番目のチャンネルをベクトルに変換した値です。また、$${C}$$はチャンネル数です。ペア間コサイン距離は[0.0, 0.5]の値を取り、値が低ければ低いほど、チャンネル間で重複が発生している「よくない特徴量マップ」であることを表します。ここで、ImageNet-1Kのバリデーションデータセットから1000枚の画像を選択し、画像ごとにペア間コサイン距離を計算して平均した値を計算してみます。これを各層ごとに行なった結果をプロットします。

各層の特徴量マップのペア間コサイン距離のグラフです。横軸が層のインデックスを0-1の値に正規化した値、縦軸が上の式で計算される特徴量マップのペア間コサイン距離です。
ConvNeXt V1 Sup(=「より強いConvNeXt V1ベースライン」)とConvNeXt-V1 FCMAEに注目してみましょう。層が深くなるにつれて両方の値は下がる傾向があるものの、ConvNeXt-V1 FCMAEの方が総じて値は低いことがわかります。著者らは、各層の特徴量マップのペア間コサイン距離を大きくすることでConvNeXt-V1 FCMAEの精度をさらに向上させることができると考えました。ペア間コサイン類似度の値を大きくするために著者らが提案した手法を次のセクションで説明します。
Global Response Normalization(GRN)
特徴量マップにおいて、チャンネル間の多様性を高めるためにはResponse Normalizationが有効であることが知られています。Response Normalizationは「側方抑制」と呼ばれる、刺激に対して脳内の隣接するニューロンの活性化を素(例:あるニューロンが活性化した場合、その隣のニューロンは活性化しない)にして活性化のパターンを多様化させるための仕組みを実装した処理です。前のセクションで説明した「特徴量マップの崩壊」が起こっていることで精度が低下しているなら、このモジュールを導入することでさらに精度を改善できそうです。そこで、著者らはResponse Normalizationを改善したGlobal Response Normalization(GRN)と名付けられたモジュールをConvNeXt-V1 FCMAEの各ブロックのMLP層に配置しました。GRNの具体的な処理手順は以下で説明されます。
(1) ある特徴量マップの1..C番目の各チャンネルについて、空間次元方向の値を要約したベクトル$${(gx_{1}, gx_{2}, ..., gx_{C}) \in \mathbb{R}^{C}}$$を計算します
(2) (1)で計算したベクトルの各要素をこのベクトルの要素の平均値で割ることでスケーリングを行います
(3) (2)で得られた値を使って特徴量マップのキャリブレーションを行います
(1)において空間次元方向の値をまとめる方法としてはL2ノルムが用いられます。(3)で行われるキャリブレーションは、(2)で計算された値を入力された特徴量マップにかけることで各チャンネルの「重要度」を反映させる目的で行われます。この処理により得られた特徴量マップはチャンネル間の重複が少なく、より多様性を持ったものになります。GRNの疑似コードを通してさらに理解を深めましょう。

GRNの疑似コードです。gammaとbetaはGRNにおける学習可能なパラメーターです。X * nxが手順(3)における核となる箇所です。各行が(1)、(2)、(3)と対応しています。(3)において上の説明と異なるのはgammaとbetaという学習可能なパラメーターが追加されていることです。Batch Normalizationの場合と同じく表現力を向上させるためのパラメーターだと解釈できます。
ConvNeXt-V2の完成

このモジュールを追加するとConvNeXt-V2 FCMAEの完成です。追加後のブロックの構造は「おまけ」セクションを参照してください。ConvNeXt-V2 FCMAEの特徴量マップが改善しているか確認するため、もう一度ベースラインとの比較を行なっているテーブルを見てみましょう。このモジュールを加えたことにより、「より強いConvNeXt V1ベースライン」のスコアをも上回ることができました!
このセクションのまとめ
MAEをCNNにそのまま適用すると、特徴量マップの多様性が失われて精度が下がってしまう
GRNを導入することでこの問題を解決できる
まとめ
以上がConvNeXt-V2(ConvNeXt-V2 FCMAE)の改善点となります。要点としては、(1)事前学習時にはSparse Convolutionを使用することと、(2)GRNをConvNeXtブロックのMLP層に入れることの2点です。得られた結果としては、ViTに対してしか用いることができなかったMAEをCNNにも適用できるということがわかりました。
参考文献
ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders ↩
Momentum Contrast for Unsupervised Visual Representation Learning ↩
Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles ↩
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale ↩
ImageNet Classification with Deep Convolutional Neural Networks ↩