
【AIコールセンター自作】ElevenLabsとTwilioで、通話可能なエージェントを簡単に作る方法【AIフレンド自作】

最近はどこもかしこもAIエージェントの話ばかりですが、多言語TTSモデルで有名なElevenLabsからも、エージェントを自作する機能が登場し、Twilioの電話番号さえあれば、電話による通話も可能となったようです。
これにより、誰でも簡単なAIコールセンターや、AIの通話可能な友達を自作することができるようになりました。
今回は、その基本的な使い方について解説します。
ElevenLabsのエージェントへのアクセス方法
ElevenLabsにログインすると、画面左側に「Agents」という項目が表示されます。
こちらにアクセスすると、AI Agents作成画面へと遷移できます。

エージェントを追加する
ElevenLabsによって、エージェントのテンプレートが4種類用意されております。

ご自身で最初から作りたい場合はBlank Templateを、既にある程度設定されているものがよければそれ以外の3つ(サポート、数学、ゲームキャラ)を選ぶことで、エージェントを追加することができます。
エージェントをカスタマイズする
作成したエージェントは、各種項目の設定を変更することで、カスタマイズすることが可能です。
順番に見ていきましょう。
Agentタブ
Agentタブは、Agentの基本的な設定を行えるタブです。


以下の各種項目があり、設定することが可能です。
Agent Language
エージェントのデフォルト応答言語です。
日本語、英語を含む多言語に対応しています。
基本的には多言語音声モデルであるため、ユーザーの会話言語次第で、この言語から外れた応答に切り替わることもあります。First Message
通話を開始した際のメッセージです。これは定型文ですが、読み上げ音声は毎回生成されているようです。System Prompt
システムプロンプトです。ここもカスタマイズできるため、例えばキャラやペルソナもセットすることが可能です。LLM
LLMの種類を選べます。
Gemini、GPT、Claudeの三大モデルに対応しているものの、o1やGemini 2.0などはリストにないため、やや設定が古いようです。
また、Custom LLMはOpenAIと同一形式のAPIがあるものに絞られるようです。
ただ、OpenAIと互換性があるとされるGroqで試してみたところ、通話が切れて応答がなかったので、現実的に使えるかは不明です。


Temperature
LLMのランダムさや創造性を制御する変数です。Limit token usage
長すぎる応答などを防ぐためのもので、デフォルトでは制限はかかっていません(-1)。
正の値が入ると、それが最大トークン長を決定するようです。Knowledge base
ファイル、URL、テキストから情報を取得できる、RAGの一種だと考えられます。
テキストの場合は、タイトルと中身が必要です。
情報を自律的に更新する機能はないので、その点は注意です。

Tools
WebhookとClientの二種類があり、条件を満たした場合に、設定された処理を行うことが可能です。
例えばDiscordやSlackとの連携も、(少なくとも理論上は)できると考えられます。

Secrets
機密情報です。一度アップロードすると、本人も中身を確認できなくなります。
APIキーなどを格納する場所です。

Voiceタブ
Voiceタブは、主に声の詳細設定を行うタブです。

voice
声を選択できます。利用できるのは、自作したモデルと、ElevenLabsで公開されているデフォルトモデル、Proモデルで、通常のtext-to-speechと同様です。Use Flash
より高速なv 2.5モデルを使うかを切り替えます。TTS output format
フォーマットと、サンプリング周波数を選べます。サンプリング周波数が大きいほど、自然な音声に聞こえる代わりに、音声データの容量が大きくなります。Pronunciation Dictionaries
発音の辞書です。詳しい使い方は以下にあります。
具体的なフォーマットは、以下のようなxml形式になっております。
<?xml version="1.0" encoding="UTF-8"?>
<lexicon version="1.0"
xmlns="http://www.w3.org/2005/01/pronunciation-lexicon"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.w3.org/2005/01/pronunciation-lexicon
http://www.w3.org/TR/2007/CR-pronunciation-lexicon-20071212/pls.xsd"
alphabet="ipa" xml:lang="en-US">
<lexeme>
<grapheme>tomato</grapheme>
<phoneme>/tə'meɪtoʊ/</phoneme>
</lexeme>
<lexeme>
<grapheme>Tomato</grapheme>
<phoneme>/tə'meɪtoʊ/</phoneme>
</lexeme>
</lexicon>lexemeで単語、graphemeでスペル、phonemeで発音記号・アクセントを記述します。
実際には、専門的になるのでLLMに代筆させた方がいいかもしれません。
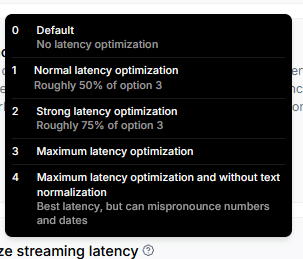
Optimize streaming latency
品質とのトレードオフで、反応を高速化できます。0~4までの5段階ですが、4は発音ミスなどが起こりうるので、それを回避できる最高の段階は3だとされています。
Stability
声の安定性です。上げるほど安定する代わりに、感情表現が乏しくなるというトレードオフ関係にあります。Similarity
声を、モデルの元データにどこまで似せるかです。より似せると忠実になる代わりに、元データのノイズなども入り込む可能性があるため、バランスを調整することが望ましいです。
Analysisタブ
会話履歴から、結果の成否や、収拾したいデータの基準を調整するためのタブです。

Evaluation criteria
Name (基準名), Prompt (評価命令), Success criteria (成功基準)の三弾構成で記述します。これにより、Status(Success, Failure, Unknown)の会話ステータス評価を、より精密に規定することが可能となります。
内容は英語で記述してください。
サンプルとして、以下のようなものがあります。
Name: menu_explanation
Prompt: Evaluate if the assistant properly explained menu options when asked.
Success criteria:
- Mentioned available pierogi varieties
- Provided prices when relevant
- Explained portion sizes (dozens)
Return "unknown" if menu items were not discussed.Data collection
データ収集基準です。Data Type(string固定)、Identifier (情報の識別名)、Description(説明)の3つで、Descriptionでは、該当する条件を"Should be one of:"として箇条書きするのが典型的な書き方のようです。
これも英語で記述してください。
Identifier: ordered_items
Description: List all pierogi varieties and quantities ordered in the format: "item: quantity".
Should be one of:
- completed_order
- abandoned_order
- menu_inquiry
- general_inquiry
If no order was placed, return "none"より詳細な情報は、以下の公式ドキュメントから確認できます。
Securityタブ
このタブでは、エージェントのセキュリティ上の設定を行うことが可能です。

Enable authentication
ユーザーに認証を求めるものです。
有効化すると、認証なしではエージェントにアクセスできなくなります。Allowlist
許可するホストのリストを設定するものです。設定されると、許可されたホスト以外はエージェントにアクセスできなくなります。Enable overrides
Agentタブの各項目について、上書きを許可するかです。デフォルトではオフになっています。
Advancedタブ
より細かい設定を行うためのタブです。


Turn Timeout
ユーザーが黙ってから、エージェントのターンになるまでの時間設定です(秒単位)。Max conversation duration
デフォルトは300秒、5分です。ElevenLabsのトークンは話し続ける限り減っていくので、その対策として、最大ラインがセットされています。
目的に応じて、長電話したい場合などはもう少し伸ばしてもいいかもしれません。Keywords
カンマ区切りで、予測精度を上げたいキーワードを設定します。User input audio format
ユーザー音声の入力フォーマットです。性質はvoiceの出力と同様です。Client Events
クライエントへ送信されるべきイベントです。音声(audio)と、割り込み(interruption)は必ず有効で、ユーザー発言の文字起こし(user_transcript)や、他にエージェントの応答(agent_response)やその修正結果(agent_response_correction)なども拾うように設定することが可能です。

Privacy Settings
通話音声を記録するか、切り替えることができます。
Widgetタブ
Widgetタブでは、Webサイトへの埋め込み用のWidgetについて、各項目を設定することができます。


Embed code
埋め込みコードです。これを埋め込むことで、エージェントの通話用のWidgetが表示されます。

Feedback collection
フィードバックの収集を行うか、設定できます。しない、通話中、通話終了後の3つのオプションがあります。

Appearance
見た目の設定が可能です。基本的な形や色、丸長方形の丸みの半径を設定することができます。Avatar
アイコンをセットすることが可能です。デフォルトは抽象的なオーブ模様ですが、画像のアップロードや、リンクによる設定も可能です。Text Contents
ウィジェット内の各項目を設定できます。未記入だと、デフォルトの英語項目がセットされます。Shareable Pages
共有リンクでシェアしたときの説明を変更することが可能です。
電話番号の連携
次は、電話番号の連携について、説明します。
電話番号は、Twilioで取得したものを使うことができます。
Twilioの登録と、最初の一つのアメリカ番号の取得は無料です。
この番号を、ElevenLabsと連携させます。
Twilio側で、必要情報を確認する
ElevenLabs側では、以下の4つの情報が必要です。

このうち、任意の名称でいいLabel以外が、Twilio側から必要となる情報です。
Twilioでは、初回登録時にフローでこの情報が表示されているので、通常はコピペすれば終わりです。
が、その流れを逃した場合の方法を説明します。
コンソールで、対称の電話番号の情報を出す
以下のコンソールにアクセスします。
スクロールすると、Account Infoというものが出てくるので、そこのAccount SID、Auth Token、My Twilio phone numberをコピーします。

ElevenLabsに各種情報をペーストする
ElevenLabsの左側にPhone Numbersがあるのでこれをクリックし、「+」を押すと、必要項目の画面(上述)が出てくるので、それを入力してImportします。


エージェントと連携する
インポートした番号に、Inbound callsで呼び出されるエージェントを選択すると、以降この電話に掛けた際にはこのエージェントが呼び出されます。

Twilioの電話番号の注意点
デフォルトのアメリカ番号は、通話可能だが、無料版ではSMSの利用不可
Twilioでは、無料で米国番号が一つもらえますが、SMSは利用できません。
A2P 10DLC registrationというものが必要で、これは無料版ではアメリカとカナダでしか設定できないようです。
アップグレードする(個人情報と、初期の費用の入金を行う)と、日本からもできるようです。
日本番号は、法人しか利用できず、書類の提出が必須
日本番号の取得には、アップグレードに加えて、以下の提出が必須です。
マイナンバー(個人の身元証明)
履歴事項全部証明書(法人の身元証明+代表者の証明)
Regulatory Bundle(規制情報)の申請書
他の身分証明書などの代替選択肢はあるものの、法人しか利用できない点が、大きな注意点です。
上記以外で利用可能な身分証明書等については、以下から確認できます。
現状の弱点
ここまでElevenLabsのAgentsの機能を見てきましたが、誰でも作れる、ということもあって、弱点もないわけではありません。
実際に通話してみて、確認した弱点を挙げてみます。
日本語がやや不安定で弱い
ElevenLabsで作った音声は、全体的日本語の性能がStyle Bert Vits 2などに比べると今一つで、読み間違いなども目立ちます。
今日のSoracupに参加したこちらの作品でも、佐藤がサトゥーになるなど、話として通じはしますが、ところどころ変です。
声のモデルが同じである以上、エージェントとしてのElevenLabsも、潜在的に同じ弱点を抱えています。
反面、英語はほぼ完璧なので、国際対応か、多少日本語としてなまっていても問題ないケースなどでは利用の余地はあるでしょう。
Geminiモデルの場合、safety_settingsが有効化されている
デフォルトのモデルであるGemini 1.5 flashを使用した場合、ほぼリアルタイムで返答し、まるで人間のような応答速度です。
ただし、Geminiの悪名高き検閲機能が有効化されていると考えられ、応答が途中で止まってしまうことが時折あります。
Claude 3.5 Sonnetの場合、多少はラグがある
反面、そのような検閲が行われないClaude 3.5 Sonnetの場合は、応答開始までに数秒程度のタイムラグが発生します。
そのことで、通話性能が落ちる可能性があります。
時折謎に通話が切れる
現在は、LLMの利用料は課金されません。
これは、恐らくこの機能がまだ試験中だからだと考えられます。
そのためなのか、少なくともウィジェット版では時折理由もなく通話が切れてしまうことがあります。
実際に体験してみた限りでは、最大時間制限によるタイムアウトだとわかるケースもあるものの、別の理由で会話がつながらなくなって切れることも時折確認されました。
主な用途
さて、このElevenLabsのAgentですが、いくつかの主な用途が考えられます。
自分自身と対話する
Proモデルで、自分自身の声のモデルを作成した場合、このモデルを用い、プロフィールや知識、記憶も共有してあげれば、自分自身と対話することができるようになると思われます。
亡くなった人と対話する
例えば亡くなった誰かの音声データがある場合、そのデータでモデルを作成し、プロフィールや知識、記憶を共有することで、その人との対話を再現できるかもしれません。
死者との対話は、世界的にニーズのある領域なので、ここに個人として手出しすることは必ずしも否定しません。
ただし、倫理的には賛否が分かれる領域でもあるので、これはあくまでも自己責任でやり、公開範囲などもよく考えた方がいいでしょう。
生きている他者と再現で対話し、よりよい関係を気付く足掛かりとする
友人や恋人などとよりよい関係構築を目指すために、練習の場として対話する、あるいはもっと話したい側と、そこまで話さなくてもいいと思っている側で、話したい側が使うことでバランスをとるような使い方もありうるでしょう。
性格などはプロンプトと知識で再現したうえで、モデルについても、音声データを持っていれば音声まで再現してもいいと思います。
ただし、個人利用にとどめ、公開することは控えた方がいいでしょう。
あなたが作ったのは、あくまでもあなたから見たお相手でしかない、ということに注意するべきです。
架空のAIの友人やパートナーと対話する
架空のプロフィールなどを設定してあげれば、架空のAIの友人を生み出すことも可能です。
このケースは、実在の他者を巻き込まないので、比較的健全な使い方でしょう。
AITuberなどのAIキャラとのコールサービス
AIキャラとのコールサービスを構築することも可能でしょう。
電話できるAITuberには、ユーザーも親近感を抱いて、伸びる可能性があります。
有名人や偉人の再現と対話する
これは、許可さえ取れていればビジネスになる可能性もある領域です。
ここまで挙げてきた再現される人物が有名人になった時、その人が認めているなら、公式サービスとして売ることが可能だからです。
一方で、許可なしでやることは推奨されません。
実際には、非公開で個人的にやるのは止めようがないですが、やるとしてもそこまでにしておいた方が無難だと思います。
コールセンターの代替
ビジネス的には、電話番号と簡単に連携できるので、コールセンターの代替も間違いなく一案となるでしょう。
国内のほかの企業に頼めば数十万、数百万と飛んでいく可能性もある以上、そこまでの質がなくても回せるケースでは、有力案の一つになると思います。
ただし、日本語はまだ多少怪しいので、本格運用は、モデルの日本語性能が改善されてからの方がいいかもしれません。
一方で、英語圏向けコールセンターとしてであれば、実用的な水準に達しつつあると思います。
まとめ:民主化されるAI通話サービス
現状では、殆どのAIコールセンターはビジネス向け、殆どのAIと通話してみた系個人ポストは趣味の領域にとどまっており、個人レベルでのAI通話サービスはまだまだ普及していません。
ただ、技術は拡散され、陳腐化していき、そして普及する。
この歴史はこれまでも繰り返されてきたものです。
ElevenLabsのAgentには、これからそうなっていく可能性を感じました。
一度試してみる価値はあると思います。