GRADE approachを勉強した先生がネットワークメタ分析を勉強するにあったっての注意点

「EBMシステマテックレビューの読み方7:ネットワークメタ分析の基礎の基礎(確実性の評価が重要)」の動画(GRADE approachの確実性の紹介)などを参考にすると理解しやすいです ( https://youtu.be/S8FuCj2wzDo )
Y先生のEBM講座:ネット枠メタ分析のエビデンス確実性やRのコマンドなどいろいろあります。
スライド版:動画でないのもある。
実践として、実際の論文を丁寧に読んでみたい方へ:サルコペニアと運動のNMAの論文を読む
(1)用語について
Mixed-treatment comparison・Multiple treatment meta-analysis・comparison of multiple treatments:
もともと、多くの治療法の比較をどうするかという問題で開発が進んできた。その過程で、A-BとA-Cから、B-Cの間接比較を推定することが行われた。しかし、これはあくまでも2つの研究を観察研究のように解析したものにしか過ぎない(ランダム割り付けを直接行っていないので交絡のリスクがある)。その後、直接比較と間接比較を統合して、混合比較へと進んだ。その後、ベイズ統計学の発展もあり、ネットワーク全体を使うネットワークメタ分析へと進化してきた。不思議なことに、その後、ベイズ統計で行わなくても大丈夫ということになったので、最近は、ベイズ以外の解析が増えている。
ポイントは、ネットワークメタ分析は、ネットワークで情報が増えるにも関わらず、バイアスのリスクが高い論文や、直接比較のエビデンスの確実性が低いものがあると、全体としてエビデンスの確実性が低くなることがある。よって、無理にネットワークメタ分析を行うより、直接比較でmultiple treatmentsの比較を行った方が、良い場合もある(GRADEproには、現在も、Multiple-Intervention Comparisons in EtD Frameworkというオプションが有料で用意されている・説明の動画)。ネットワークメタ分析は万能でなく、使う場面を選んで使うことを理解することが重要である。
Study limitations(研究の限界)について:
そもそもコクランでは、risk of bias(RoB)と表現している。CINeMAでは、within-study biasという表現も使用している。
Inconsistency(非一貫性)・Heterogeneity(異質性)について:
Salantiらは、GRADE approachが研究間のバラツキを、inconsistency(非一貫性)と表現しているが、inconsistencyという用語は、特に直接証拠と間接証拠の間の不一致を指すために頻繁に使用されるので、明確にするために、Heterogeneity異質性という用語を同じ比較内の研究の推定値間の不一致を説明するために使用し、異なるソース (直接証拠と間接証拠、または間接証拠の異なるルートなど) からの推定値間の不一致をinconsistencyという用語で説明するとしていた(Inconsistency (differences between direct and indirect evidence in the network))。その後、CINeMAの説明論文では、inconsistency でなく、incoherence(整合性)を直接比較と間接比較の不一致として変更していた。GRADEワーキンググループでも、BMJのNMAの確実性の論文の用語解説で、同じ比較対象を評価した研究間の効果推定値の差をinconsistency でなくheterogeneityとしていた。Salantiらは、両方の概念を一緒に検討することを勧めている。注意:CINeMAを使った論文では、heterogeneity(異質性)・consistency(整合性・直接比較と間接比較の間の一致)とするものが多い。
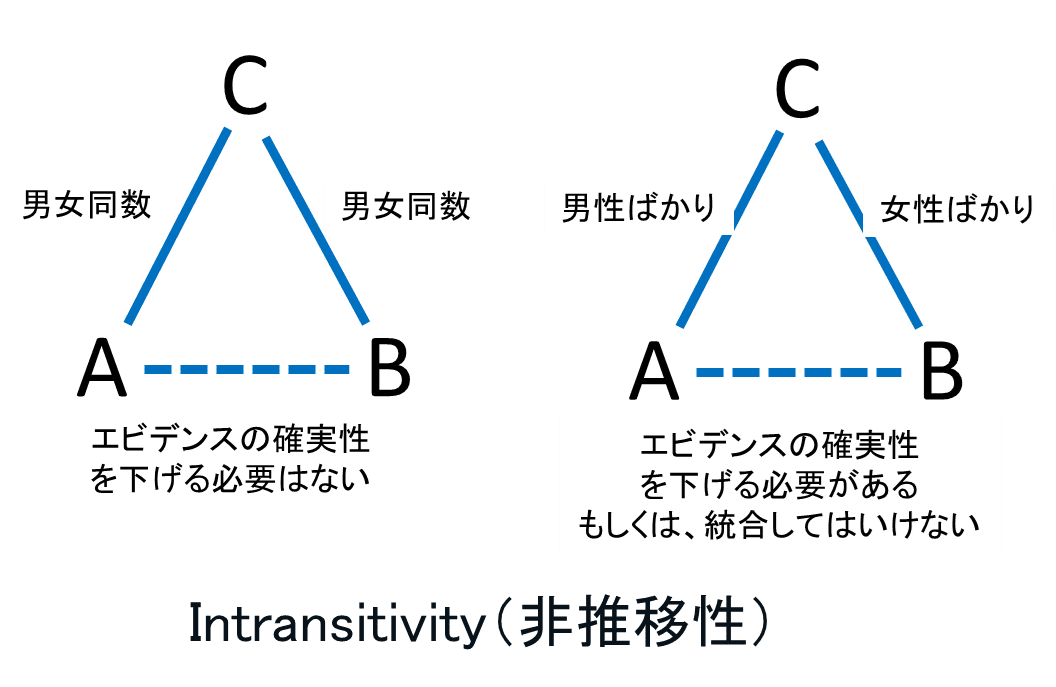
Intransitivity(非推移性)・transitivity(推移性)について:
GRADE approachでは、Indirectnessは2つの意味があり、一つは普通の非直接性の意味であり、もう一つはNMAで用いられる、Intransitivity(非推移性)の意味である。
Intransitivity(非推移性)は、関心のある比較(A対B)の効果の間接推定の基礎となる直接比較(A対C、B対Cなどだが、説明では共通比較のCとされることもある)が、そもそも類似していることだが、この推移性に問題があるとネットワークメタ分析の前提が崩れる。2022年時点では、Intransitivity(非推移性)・transitivity(推移性)のどちらも用いられている。
Incoherence(非整合性・不一致性と訳する先生もいます)について:
直接比較と間接比較の不一致を示すが、同じループでの不一致だけでなく、ABCの結果(A>>C、B>C)なら、A>Bでないと整合性がとれないという意味でも、Incoherenceの用語を使うことがある。注意:CINeMAを使った論文では、heterogeneity(異質性)・consistency(整合性・直接比較と間接比較の間の一致)とするものが多い。しかも、文章の中に、incoherenceもでてきて、論文の著者も混乱しているので、間違いがあるとの認識で文脈から判断するしかない。
ややこしいことに、「If estimates from direct and indirect evidence disagree, transitivity does not hold and there is incoherence within the network. (直接証拠と間接証拠からの推定値が一致しない場合、transitivityは成立せず、ネットワーク内にincoherenceが存在することになります。)」などという文章もある。直接比較と間接比較の不一致でも、transitivityは同じ(A対C、B対Cの背景が同じ)でも良いはずだ。
個人的には、これが、非常に深刻ならば、そもそも、ネットワークメタ分析が成り立ってない気がする。
指標:いろいろな指標があるが、どれも利欠点がある。Bucherアプローチ、CochranのQ統計、ノード分割、および矛盾パラメーターアプローチ、ネットヒートアプローチ。
ネットヒートプロット・ヒートプロット・league heat plot・netheat plot:
直接的な証拠と間接的な証拠が矛盾する場合に発生する不整合は、治療効果と治療コントラストの推定と解釈に問題を引き起こします。 Krahnらは、RCTのネットワーク内の不整合を特定および特定するためのグラフィカルツールとして、ネットヒートアプローチを提案した。しかし、ネットヒートプロットは、矛盾を確実に通知したり、矛盾を引き起こす設計を特定したりしないという論文もある。
直接比較がどれだけネットワーク推定値に依存しているかを灰色の四角で評価する。例えば、左の項目のAとB比較を横に(行でみる)と、縦(列)の上のところでAとBの比較のみが灰色で他に灰色がなければ、AとBのネットワーク推定値は、AとBの直接比較のみとなる。また、BとC比較の灰色もあれば、BとCの比較もAとBのネットワーク推定値に関与するとなるので、間接比較も関与しているなとわかる。そして赤色の方が不整合性が高い事になる。
ところが!、league heat plotは、一般化された線形モデルを使用してベイジアン NMA を実行する「BUGSnet」(導入方法)と呼ばれる R パッケージで出力されるようだが、これは、単にネットワークメタ分析の結果をリーグテーブル(対角線の上も下もネットワーク推定値)であり、それに、有意差で、より有意(理解してないが、雰囲気としてPが0.01より小さいと、より赤と青、Pが0.05ぐらいなら、薄赤と薄青)かどうかで色分けしたものであり、ネットヒートプロットとは異なる。
信用区間(確信)区間 (Credible Interval, CrI)について:
ベイズ統計で95%信頼区間を算出した場合、「信頼区間」と表現せずに「信用区間」と表現する必要がある。
重要なのは、事後分布はあくまでも分布であって、1つの推定「真」値ではないことである。つまり、ベイズ推論の結果であっても確率的であることに変わりはない。また、実際のパラメータ値に対する私たちの信念を表すという意味で、主観的なものでもある。したがって、ベイズ統計学では、推定値の信頼区間を計算するのではなく、信用(確信)区間 (Credible Interval, CrI) を計算するのである。ユーザーとしては、信頼区間と信用区間を同じと考えても許されるだろう。
リーグテーブル(League table)・対比較の推定値表について:
各治療群間の総当たり戦の四角いマス目表。見ての通りだが、対角線の仕方のみで上が階段だったり(この場合はNMA推定値のみ)、対角線の上半分と下半分が、A対BとB対Aと逆になっているだけだったり(NMA推定値のみ)、下半分がNMA推定値で上半分が直接比較の推定値だったり、アウトカムが違っていたり(アウトカムが2つの場合にこのパターンが多いかな)、など、いろいろなパターンが混在している。この表をだすなら、ノード分割法での直接比較・間接比較・ネットワーク比較の3つの推定値を、すべての総当たりで並べた表のが良いと思うが、慣例みたいで、よくでてくる。
GRADEアプローチでは、これらの表に関して、いかに見やすくて理解しやすい表がよいかの議論が行われていて(下記の、ランキン後の指標について:にも少し記載した)、今後、変わる可能性は高い、というか変わって欲しい。
Node-splitting methodについて:
ネットワークグラフだけで、間接比較 のデータが用いられているかを判断するのは不可能と考える。そこで、自動的にそれを判定し、ネットワーク メタアナリシスの推定値、直接比較の推定値、間接比較の推定値(それらの有意差検定なども)を各ペア比較について分割して提示する方法として、Node-splitting methodが開発された。これによって、ネットワークメタ分析モデルの不整合を診断することが可能となる。
netmetaでは、nettableとして、「1つ以上のネットワークメタアナリシスからネットワーク推定値、直接推定値、間接推定値で表を構築する。この表は、ネットワークメタアナリシスのGRADE表の統計部分と非常によく似ている(Puhan et al.、2014)。」と記載されている。
(2)アームベースとコントラストベースについて(arm-Based contrast-based method model)
アームベースとコントラストベースは、下図のように単に表記法の違いではなく、以下のような文章からわかるように解析方法が異なるようです。
「現在、ネットワークメタアナリシスで最も広く使用されている方法はコントラストベースであり、各研究でベースライン治療を指定する必要があり、分析は相対的な治療効果(通常は対数オッズ比)のモデリングに焦点を当てています。ただし、絶対リスクなどの母集団平均の治療固有のパラメーターは、外部データ ソースまたは参照治療用の別のモデルがなければ、この方法では推定できません。最近では、アームベースのネットワーク メタ分析手法が提案されており、R パッケージ pcnetmeta は、その実装のためのユーザー フレンドリーな機能を提供します。このパッケージは、絶対効果と相対効果の両方を推定し、バイナリを処理できます。」URLはここ

従来のメタアナリシスあるいはネットワークメタアナリシスでは 「コントラストべースモデル(contrast-based model)が用いられ、これは相対的効果指標を統合するモデルであった。一方、アームベースモデルは、各治療群のイベント率や平均値が統合され、それから相対的効果指標を算出するモデルであるらしい。MindsマニュアルのNMAところに書いてありますが、基本的なマニュアルのはずだが、たぶん、誰も理解できないでしょう。
(3)エビデンスの確実性について:
2つの確実性の評価について:
コクランのワーキンググループによるSalantiらのフレームワークに基づいたCINeMAというオープンのサイトを利用した方法(ネットワーク全体を評価する感じ・ネットワーク全体のが情報が多い)と、GRADE approachによる方法(直接比較を検討後、一次ループごとに評価する感じ・ネットワーク全体は確実性の高い直接比較の情報が薄まるので、確実性の高い直接比較の情報から評価した方がよいとする感じ)の2つがあり、考え方がまったく異なっている(今後、統一されることがないほどだ)。
その他、Phillippoら、Dumvilleらの方法もあるようだ。細かな事を書くと、Salantiらは、GRADE approachの考えに従って評価法を開発したとしていた。その後、Salanti先生でない方が中心でCINeMAが開発された。このCINeMA論文は、割とGRADE approachとの違いを明確にしている。その後、Salanti先生もCINeMAの説明の動画をだしている。
Noori A, Sadeghirad B, Thabane L, Bhandari M, Guyatt GH, Busse JW. The GRADE Working Group and CINeMA approaches provided inconsistent certainty of evidence ratings for a network meta-analysis of opioids for chronic noncancer pain. J Clin Epidemiol. 2024 Feb 8:111276. doi: 10.1016/j.jclinepi.2024.111276. Epub ahead of print. PMID: 38341047.
https://pubmed.ncbi.nlm.nih.gov/38341047/
CINeMAについて:
CINeMAの紹介論文より以下の点が指摘されていた。
ネットワークに含まれるすべての研究の特徴を考慮する。各直接比較の重みが合計され、パーセンテージとして再表現されて、ネットワーク全体に対する各直接比較の寄与率を計算した値(キーがcontribution matrix とある)を使って、ネットワーク推定値の確実性を評価する方法を用いている。また、間接的な証拠の選択的な使用を避けていると論文に記載があった。直接あるいは間接(あるいは複合)エビデンスを提示するかどうかを決定するために信頼性の評価を用いていない(CINeMAの紹介論文の記載だが、Salantiの論文はには、これと違って用いているような参考文献の記載であり不思議なのだが、元論文をみても詳細は不明であった) 。CINeMAは、再現性の評価までは行っておらず再現性が乏しい可能性はあるが、それよりも透明性が重要だと考えている。直接推定量と間接推定量を別々に考慮することなく、相対的な治療効果を評価する。
そして、「GRADE approachは、ネットワークの一部しか用いてないので、寄与率行列に基づき、ネットワークに含まれるすべての研究の影響を考慮するCINeMAアプローチの方が望ましい」との記載もあった。
私の感想としては、ネットワーク全体の評価のため、基本的に、直接エビデンスの確実性が高いことを前提としないと、どこで問題かが不明となる可能性があるのではないか。
CINeMAのImprecisionとImprecisionについて:
コクランの、CD014682より。
Imprecision(直接証拠と間接証拠を組み合わせたNMAの精度):関連治療効果は、臨床的に重要な最小限の差(MCID)を表すものが定義され、臨床的同等性の範囲が示されます(MCIDの値は効果のない線の両側にあります)。CINeMAは、95%信頼区間に含まれる治療効果を臨床的同等性の範囲と比較します。治療効果の95%信頼区間が臨床的同等性の範囲を超える場合、Imprecision不精確さの重大な懸念があると見なされます。治療効果の95%信頼区間が同等性の範囲の一方だけを超える場合、不精確さの懸念はありません。
Incoherence(直接証拠と間接証拠の結果の一致):ネットワーク内の直接証拠と間接証拠のばらつきであり、transitivityの評価でもある。CINeMAは、直接推定と間接推定の推定値の95%CIを比較します。これらの推定値がともに臨床的同等性の範囲の同じ側にある場合、incoherenceに関する懸念はありません
GRADE approachについて:
2023年6月追加:ステップをわかりやすく解説した論文がでました。補足ファイル3は、これまでにないもので(基本は同じで文章で説明されていたが)、このアルゴリズムは必読です。
A guide and pragmatic considerations for applying GRADE to network meta-analysis
https://www.bmj.com/content/381/bmj-2022-074495
何とかまとめてみました:
NMAのGRADEエビデンスの確実性の評価のステップまとめ(さすがに動画も見ないとわからないと思います)
動画 https://youtu.be/f89kZpVdO9Q
スライド https://www.docswell.com/s/MXE05064/ZXY292-2023-08-27-084103

間接推定値が直接推定値と組み合わせるのに十分な確実性を持っているかどうかを決定するプロセスを提案している。
まず、一つの比較に対して、一次ループを選択する。複数ある場合は、その一次ループの中でより信頼区間が狭いものを優勢一次ループとして、それを使いながら、エビデンスの確実性を評価する。
(注意:優勢一次ループよりエビデンスの確実性だけでなく、間接比較とネットワーク比較の効果推定値も算出するという専門家もいます(追記)が、基本は、エビデンスの確実性の評価に優勢一次ループを使う。)
その後、直接推定値、間接推定値、ネットワーク推定値のエビデンスの確実性をすべて評価する。そうなると、例えば、ネットワーク推定値のエビデンスの確実性より、直接推定値のエビデンスの確実性が高いこともあるかもしれない。そのため、これらを使って直接推定値、間接推定値、ネットワーク推定値のどれを使うかを決定することになる。
よって、欠点もあり、各治療効果について最も影響力のある1段階ループ(優勢一次ループ)の研究内バイアスを考慮するため、多くの情報が破棄され、大規模ネットワークへの適用が困難となる(CINeMAの論文より)。また、多量の一次ループのみの評価を繰り返すことになり、実施困難な可能性がある(これに関しては、より簡便化するたエクセルファイルなどの開発が進んでいる)。
利点としては、直接比較を十分に検討するので、直接比較で確実性が非常に低い組み合わせが、他の組み合わせのネットワーク推定値などに、どのように影響しているかが理解できる。これは、かなり重要で、この理解することが大切である。
優勢一次ループの決め方が、該当する複数の1次ループの間接比較の分散推定値(信頼区間でもよい)の小さいものとすると論文にあるが、以下の動画の説明では、ネットワーク図をみて、症例数と研究数の多いループを視覚的に選んでいた。確かにこちらのが、簡便だ。
Webinar: Network Meta-Analysis and GRADE

Imprecision(不精確さ)について:
Salantiらは、標準的な GRADE approachでは、適切なサンプルサイズを検討するための経験則が提案されているが、ネットワークのメタ分析では、効果サイズの推定にはさまざまな証拠源が複雑に寄与しているため、サンプル サイズを考慮するための便利な経験則は現在利用できないので、信頼区間に注目することを勧めている。そのため、CINeMAでも、信頼区間が閾値をまたぎ効果ありからなしにまたぐことなどで評価し、症例数の計算は行わない。GRADE approachでは、直接比較は、一般のメタ分析に準じたエビデンスの確実性のグレーディングを行い、不精確さについても同様の基準となっている。
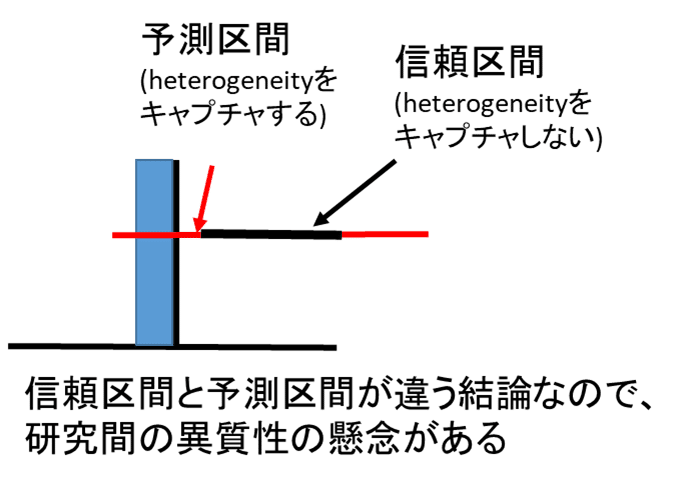
Heterogeneity(異質性・不均一性)について:
CINeMAでは、治療効果の分布の分散(τ2)は、異質性の大きさの尺度として予測区間(prediction intervals)を設定(一般的に信頼区間より広い)。その上で、信頼区間にと予測区間の上下限が、閾値に対して異なる意思決定となる場合、異質性があるとしている。すなわち、論文間のばらつき(分散)によって判断が異なるならばらつきが大きいと評価。ただし、試行回数が非常に少ない場合、異質性の量の推定は不十分であり、予測間隔は信頼できないとされている。GRADE approachでは、直接比較のinconsistency(非一貫性)を従来の通りに評価して、それを間接比較にも一次ループを通じて適応している。
(4)ランキング・順位について
ランキン後の指標について:
SUCRA score(ベイズ的)とP-score(頻度論的)の2つが有名である(最近では、どちらでもというか、頻度でもSUCRAとかかな)(2017年当時のランキングの論文では、確実性もありややこしいので、誤解しないようになどの記載もある)。
Surface under the cumulative ranking (SUCRA) score:Salanti Gらが開発。各治療について1 位からの順位の確率を累積値としてグラフ化するもの。よって、より横線の左の1から他の治療より上でかつ面積が大きいものが良い。
P-score:ある治療が他の治療よりも優れているという確実性を、すべての競合する治療に対して平均して測定するものである。
P-スコアとSUCRA スコアは同等であるとする研究結果があるようだ。SUCRA や P-score などの指標は、私たちのネットワークにおいて、どのタイプの治療が最も効果的であるかを調べるために使用することが可能である。しかし、意思決定プロセスに不確実性を組み込むことも重要である。異なる治療法の信頼区間は重なり合うこともよくあるので、1つの形式が他のすべての形式より本当に優れているかどうかは、あまり明確ではない。
GRADEアプローチでは、ランキングに従うのではなく、各比較のエビデンスの確実性を考えながら、理解しやすい表作りをしながら、総合的に判断するという感じである。これについてのスライドを作ったので、参考にして欲しい。<すいません、このスライドは、色分け前までです。実際の色分けした図は、以下にリンク先を紹介している、ネットワークメタ分析の論文の図表の理解しよう第2弾:2型糖尿病の薬物療法 のスライド47となります。
スライド:ネットワークメタ分析の結果より、介入の順位を考える
一方、CINeMAのSalanti G先生は、ランキングの確実性について、メイン論文に記載があり、かつ、CINeMAでは実装がまだとある。
SUCRAのランキングについて:SUCRAアプローチでは、効果の点推定値にのみ着目し、SUCRAスコア間の差を偶然で説明できる可能性(推定値の精度)、順位間の絶対差の大きさ、そして最も重要なのは、エビデンスの確実性を考慮しないため、SUCRAスコアのみに依存して、治療の有効性や有害性に関する結論を出すことは誤解を招く恐れがあります。
NMAの論文(この論文のエビデンスの確実性が、ちょっと信頼が・・・不明)に、「ペアごとの比較で有意差が見つからなかったため、研究結果の誤解につながる可能性があるため、SUCRA 値は計算されませんでした。SUCRA は、治療間の違いが検出された場合にのみ、価値のある情報を提供します」の記述がありました。
GRADEアプローチでは、ランキングでなく、エビデンスの確実性と絶対効果の大きさを色分けした表を推奨しています。上の「ネットワークメタ分析の結果より、介入の順位を考える」を色分けしたものとなる。
ネットワークメタ分析の論文の図表の理解しよう第2弾:2型糖尿病の薬物療法 (スライド47は、GRADEアプローチでの最終的な見やすい表(ランキングの代わりになっている)
https://www.docswell.com/s/MXE05064/5DEJ96-2023-05-12-222233
ランキングの確実性について:
Salantiらは、効果量の信頼性と治療のランキングの信頼性を分けて評価している。ランキングの信頼性についてCINeMAでは、まだ実装されてなく開発中とのこと。GRADE approachでは、統計学的なランキングの確実性を評価するのではなく、統計学的なランキングや個々のペアの確実性・推定値の大きさなどから総合的に判断している(よって、確実性や点推定値の大きさで表を作って判断する)。ランキングの確実性を別に評価する理由は、ランキング測定には、証拠のネットワーク全体に関する推論が含まれるが、ペアワイズ効果サイズは、直接的および間接的な証拠の特定のソースの複雑な加重平均から導き出され、直接的な証拠は通常、より多くの重みを与える。AB のエビデンスの確実性は高く、BC と AC のエビデンスの確実性が低い単純な三角ネットワークを考えてみる。効果サイズ AB には高い信頼度を与えることができるかもしれないが、全体的な治療ランキングには低い信頼度しか与えられない。
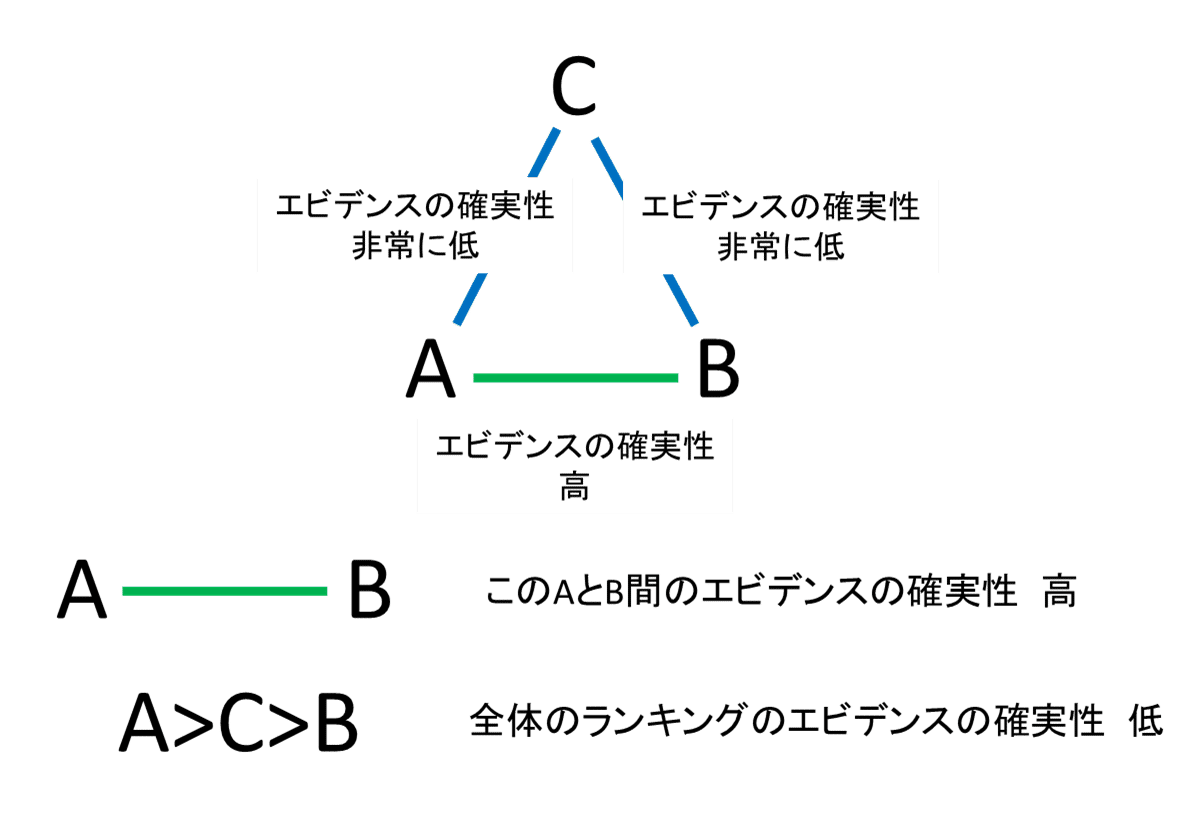
ともかく、ランキングは、鵜呑みにしないように。Salanti先生も著者の一人である、以下の論文でも、 「臨床医は、単純なランキングではなく、効果の大きさに常に関心を持つ必要があります。」と記載がある。さらに、以下のCPGでは、「パネルメンバーは、介入のランキングのみに依存するのではなく、ペアごとの効果推定値にも依存する必要があることを特に認識させられました。」とある。
Common pitfalls and mistakes in the set-up, analysis and interpretation of results in network meta-analysis: what clinicians should look for in a published article
EAES Rapid Guideline: Systematic review, network meta-analysis, CINeMA and GRADE assessment, and European consensus on bariatric surgery – Extension 2022
追記1:GRADE approachでの間接推定値とネットワーク推定値
メールの文章の公開の許可をもらってないので、自分ののみしっかりと書きました。たぶん、先方の文章を誤解して読んでいることはないと思うのですが。
自分:私は、普通にネットワークメタ分析を行なった場合の間接比較の推定値を使うが、エビデンスの確実性の評価は優勢1次ループのみから評価すると思っていました。私は、普通にネットワークメタ分析を行なった場合の間接比較の推定値を使うが、エビデンスの確実性の評価は優勢1次ループのみから評価すると思っていました。
専門家の先生:GRADE NMAシリーズ論文にdominant first loopを利用すると明記してある。通常のNMAを実施しての間接エビデンスを利用したいならば、CINeMAを採用する。GRADEは従来のNMA推定値を完全に無視するのではなく、SUCRAなどのランキングなどを参考に最終判断する。
そこで、英語が苦手なので、これまた伝わっているか不明ですがGyuatt先生にメールをしたら、丁寧に返事が来ました。
自分:I understand that in the GRADE approach, the certainty of evidence for the indirect estimates is derived from the certainty of evidence for the two direct comparisons of the mos dominant first loops. I understand this indirect estimate is the indirect estimate that you calculated by calculating the NMA in the usual way and by node splitting. (A) My colleague said that this indirect estimate is obtained from only the estimates of the two direct comparisons, using the Bucher method 1),2). (B) If the answer is (A), then you may not understand what (B) means. This is because method (B) is not a network meta-analysis because it uses only most dominant first-order loop. Therefore, I believe (A), but I want to confirm this. The example in your paper3) is calculated with (A).
Gyuatt先生:「間接推定値の点推定値および信頼区間は、ノード分割を用いたNMAによるものです(オプションA)。」とDeepLで翻訳できるような文章でした。
2) Tobías 2014; Development of an Excel Spreadsheet for Meta-Analysis of Indirect and Mixed Treatment Comparisons https://www.scielosp.org/article/resp/2014.v88n1/5-15/
専門の先生によると、このエクセルの結果、SMDの95%信頼区間が間違っているとのこと。
3) Comparative effectiveness and safety of interventions for acute diarrhea and gastroenteritis in children: A systematic review and network meta-analysis

追記2:果たしてNMAの推定方法(メタ分析におけるCIの評価など)は正しいのか?
2023年にコクランで動画が公開された(参考論文は2018年)。これによると、5研究以下などの研究数が少ない場合のメタ分析の方法が解説されている。
動画:Performing meta-analyses in the case of very few studies
参考論文:Methods for evidence synthesis in the case of very few studies
これによると、2研究なら固定効果モデル、3研究以上ならランダム効果モデルだが、分散で補正する方法と比較。さらに異質性が多い場合は定性的な統合とも比較したりするとされている。
これが、NMAで行われているかというと行われていないし、直接比較のみ、これらの方法で比較してもネットワーク推定値に反映はできない。やはり問題は大きいと言わざる負えない。
追記3:NMAというか、Multiple-Intervention Comparisonsについて
どうも、これまでMultiple-Intervention Comparisonsの場合、Pairwise Comparisonsを並べるという意味だったような気がするが(正確には知らない)、どうも近年では、NMAか、Pairwise Comparisonsを並べるのかなどを選択するという段階があり、NMAとPairwise Comparisonsを並べるものの両方を含んで、Multiple-Intervention Comparisonsとするようである。
また、この場合、参照介入を適確に選ぶことも必要とされており、単に総当たりが最も良いという事ではないようだ。
GRADEproを開発しているEvidence Primeの動画にいろいろ紹介されているので拝聴して欲しい。参考論文以降の開発状況(GRADE guidanceという手順)が少し説明されている。
動画:Evidence Prime Webinar: GRADE for Multiple-Intervention Comparisons in EtD Framework
参考論文:Using GRADE evidence to decision frameworks to choose from multiple interventions
EtDs for Multiple Interventions: GRADE guidame(動画より)
1) Planning & Priority Setting: PICO Question, NMA VS M-As, health care context, transitivity
2) Evidence synthesis: Summary of Table
3) EtD framework: Judgments for each intervention
4) Rating: MC Matrix (Summary of Judgments)
5) Recommendations: For all interventions (order of preference)
1) Planning &Priority Setting
・Consider all possible interventions
・Assess the potential conduction of a network meta-analysis
・Assess transitivity
・Selection of a common reference to present results
・Health care context and decision thresholds
・多重介入のためのEtDs。プランニングと優先順位設定
・可能性のあるすべての介入を検討する
・ネットワークメタ解析の実施の可能性を評価する
・相互作用の評価
・結果を提示するための共通参照文献の選択
・医療の背景と意思決定のしきい値
さらに追加:しきい値の設定について
さらに追加:いろいろなグラフツールなどが開発中
参考文献:Graphical tools for visualizing the results of network meta-analysis of multicomponent interventions
さらに追加:NMAの一般的な問題点の説明と総当たり数
Is Network Meta-analysis a Revolutionary Statistical Tool for Improving the Reliability of Clinical Trial Results? A Brief Overview and Emerging Issues Arising
https://iv.iiarjournals.org/content/37/3/972.long
A simple formula for enumerating comparisons in trials and network meta-analysis
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6402080/
スライドで説明
https://www.docswell.com/s/MXE05064/K8G2JQ-2023-05-05-223059
参考文献
Salantiら:Evaluating the Quality of Evidence from a Network Meta-Analysis
https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0099682
CINeMA::An approach for assessing confidence in the results of a network meta-analysis
https://journals.plos.org/plosmedicine/article?id=10.1371/journal.pmed.1003082
GRADE approach:Puhan MA, Guyatt GH, Murad MH, Li T, Salanti G, et al.. (2013) Selection of the best available evidence from an evidence network of treatment comparisons: An approach to rate the quality of direct, indirect and pooled evidence. Presented to GRADE meeting in Rome and available from gradepro.org/Rome2013/13aNMA.doc. (GRADEアプローチのこの論文、実は、Salanti先生も参加しているので、ややこしい)。