
深層強化学習(DQN)でBTC FXのデモトレード!

#強化学習 #深層強化学習 #機械学習 #DQN #投資 FX #自動取引 #TensorFlow #python #仮想通貨 #暗号資産
1. 目的
今回深層強化学習を使ってデモトレードをする目的は、BTCの過去の価格データを学習して未来の価格を予測することではない。日々刻々とランダムに変化する価格の中で深層強化学習を使ってトレードを行い、いかにして資産を守りながら増やしていくかという事を目標としている。つまり、「資産管理」を深層強化学習で学習させる事である。
2. 概要
今回は深層強化学習の中でも最も一般的なDeep Q Netwok(DQN)を使って学習を行う。また、学習の安定化のために以下の5つを追加している。
Ⅰ. experience replay(経験再生)
Ⅱ. reward clipping
Ⅲ. double network(Double DQN)
Ⅳ. 状態(state)の特徴量エンジニアリング(データの標準化)
Ⅴ. 損切りラインの設定
環境(environment):BTCFXの取引を想定。10分に1回のペースで売買する(デモトレード)。レバレッジは1倍まででロングとショートも可。1回の売買を1 step として1 episode は1000 steps 若しくは損切りラインに達するまでとする。また、各episodeの開始時の資産額は10万円とする。
方策(policy):ε-greedy法。
状態(state):円の資産、BTCの資産、移動平均値の3次元データ。
行動(action):[-2, -1, 0, 1, 2]の5種類の売買パターン。"-2"の行動はロングの建玉がある際は全決済、それ以外はエラーを返す。"-1"の行動は建玉無しではレバレッジ1倍のショート、それ以外はエラーを返す。"0"はいかなる状態でも何もしない。"1"は建玉無しでレバレッジ1倍のロング、それ以外はエラーを返す。"2"はショートの建玉があれば全決済、それ以外はエラーを返す。
報酬(reward):基本的には[行動前の全資産]ー[行動後の全資産]が報酬となるが、修正して-0.3〜3の間の値をとる。ただし、エラーの場合の報酬は-10とする。
BTCの価格path(chart):ブラック・ショールズモデルにおける株価過程
![]()
に「伊藤の公式」を適用することにより、時点における株価は、

と表すことができる。これを、BTCの価格pathに適用する。以下の図は、上の数式を使い算出したあるBTCの価格pathの例である。縦軸はBTCの価格(100万円スタート)。横軸はstep数。1 step の間隔は10分を想定。
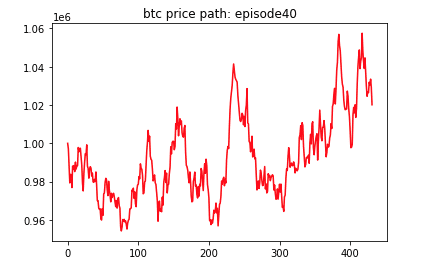
さて、このモデルによる「価格」が現実の価格とどれくらい似ているのか判断しかねる、というのが正直なところではないだろうか。実際、これはあくまで仮定である。とはいえ、この価格モデルはオプション理論やポートフォリオ理論のベースであり、実際に広く用いられている。また、数多くの実証研究がこのモデルを直接的、または間接的にサポートしている。したがって、このモデルは妥当な価格プロセスのモデルといえよう。("モンテカルロ法によるリアル・オプション分析"より抜粋)
3. デモトレードの内容
上記のモデルにて作成した価格pathを使いデモトレードを行う。売買の際にスリッページや手数料を考慮したプログラムを組んで行っている。方策(policy)から提案された上記の行動(action)の選択肢の中からのみ売買を行う。デモトレードと同時にDQNで学習を実施し、学習が進むにつれて資産がどのように変化していくのかを見ていく。
1 episode の初期投資金額は日本円で10万円スタート。資産が初期投資金額から1.5%減ったら損切りとする。10分毎にactionを起こす仕様とし、1,000 actions(1000 steps)又は損切りラインを割ったら1 episode終了とする。これを約4,000 episodes 行い学習させていく。
4. 結果
基本株価プロセス(上記)のモデルで作った価格pathの環境下で行ったデモトレードに対してDouble DQNによる学習を行った。資産を増やす為の行動価値関数がうまく学習できているかを評価する為に、以下の4つの指標を監視する。
・平均報酬
・損失(loss)
・TD誤差
・各 episodede 最終時の資産価値(円換算)
基本的には、得られる報酬の値が大きくなることを目的にしているため、1エピソード最終時の資産を見ることで、どれほど上手く学習しているかがわかる。
以下に1 episodeごとにこれら4つの指標を記録したものを示す。


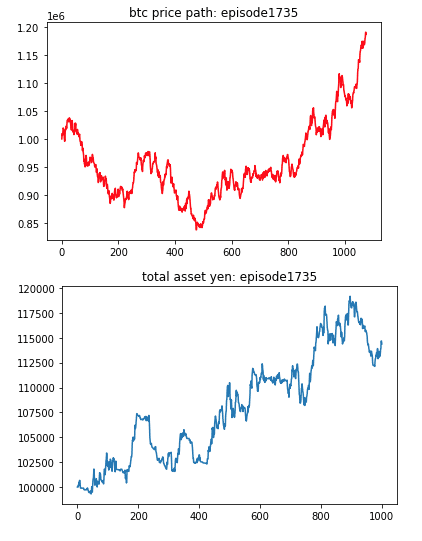
また、学習が進むに連れてのBTCの価格pathと資産推移をいくつか抜粋して以下の図に示す。





5. 考察
last asset のグラフを見てみると、学習が進むにつれて損切りされる回数が減っていき、報酬額も多くなっていることが伺える。特に3,500 episodesを超えたあたりから急激に損切り回数が減少している。また、学習が進むにつれて取引回数が減っているのは面白い。今回はGoogle Colaboを使ったため制限時間があった(24時間程度)が、今後dockerを使いさらに長い間学習させることでどのように資産が変化して行くか確認したい。また、学習させる際に与える状態(state)は今回は資産と移動平均値を使用したが、色々なテクニカル指標を入れて試してみても面白い結果が出た。結果は今回は省略する。その他には、初めは損切りラインを設定せずに学習を行なっていたが、学習が進むにつれ利益が大きくなるが、損失も大きくなっていったため(考えてみれば当たり前かもしれないが)、損切りラインを設定して対応した。また、DQNだけでなくactor-critic法を用いたデモトレードも行なったので今後記事にしていきたい。また、今後は損切りの設定値も強化学習によって決定できたら更に良いものができるのではないかと考えている。
総評として、今回の実験は成功といえよう。
6. 参考文献




7. 最後に
今回のデモトレードで使用したコードを公開しようかかなり迷いました。
別の記事で公開しようと思います。
お楽しみに。