要約筆記ツールと音声認識

■初めに
要約筆記業界ではデファクトスタンダードであろうソフトウェア
「IPtalk」にも、とうとう音声認識機能が搭載されたようです。
(IPtalk9t66)
音声認識は、ここ数年でめまぐるしい成長を遂げました。
クラウドと分散コンピューティング、ディープラーニング等で
多くの計算を瞬時に行うことができるようになったからです。
音声のビッグデータが増えてきて、
推定精度が上がってきたという点も特筆すべき点です。
音声認識というツールが使えるようになってきた今、
この文字情報をどのように応用して、文字支援に活用していくか…
これがとても大事な視点になります。
特に、支援者がすぐに増えない現状と、人口減少の現代では、
「人がすべき仕事」と「機械がすべき仕事」の仕訳が進み、
人の仕事は知的労働、付加価値の高い仕事にシフトしていきます。
であれは、機械が出来る仕事はどんどん機械にシフトさせて、
問題を研究・解決しながら 最終的に最小限の人間介入だけで
成立できるようにしていく、というのが1つの流れになるかと思います。
■新しいIPtalkテストバージョン

IPtalk の最新版は、Google Chromeの新通信方式である
WebSocketと、Googleの最先端機能を用いることによって
音声認識を実現しています。
Google Speech APIをつかうと、ブラウザでも音声認識できるので
この結果をIPtalkに流している、というわけです。
現段階では「先行評価版だ」と作者もコメントしています。
なので、これから改良されていくのかとおもいます。
■情報セキュリティとコストはどうなの?
世の中には、いくつか道具があります。
デファクトスタンダードといっても業界多数が利用しているというだけで
すべての機能を網羅しているわけではありません。
ツールというのは一長一短があるものです。
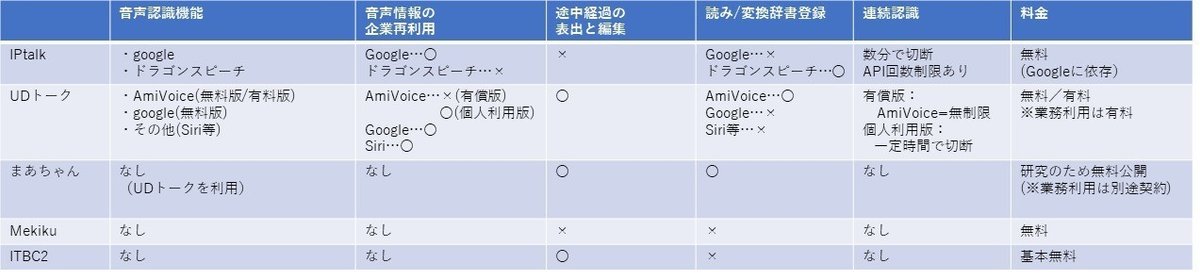
このデータはざっと調べたデータです。
IPtalkの音声認識は、Googleの音声認識をつかっています。
IPtalkの明確なライセンスは 昔から不明確ではあるのですが
フリーソフト扱いです。では、音声認識の条件はなんでしょう?
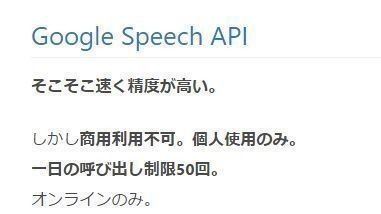
(引用:http://qiita.com/satoshi0212/items/af4928b808b4fbba8091)
まとめてくれている人が居ました。
商用利用不可、ってことは、団体や要約筆記では利用難しそうですね。
ちなみに、法律的には商用利用って言葉の明確な定義がないようです

(引用:http://www.dynacw.co.jp/support/support_faq_detail.aspx?qid=490&fcid=224)
フォント業界などでみると、「対価の支払いを受けない」=非商用なので、要約筆記派遣とかは仕事になりますね。大学のノートテイクもアウト。(個人で見たらグレーだけど、大学が雇用しているのだから、大学という法人の業務。なので商用利用ですね。)こういうライセンスは導入のときにしっかり検討しておきましょう。
さて、音声認識の話に戻りましょう。
Google音声認識はいくつか認識させる手段があるのですが、
Google Speech API を契約して使うと、それなりのお金がかかります。
(このブラウザ方式だと、現段階ではお金がかからないらしい)
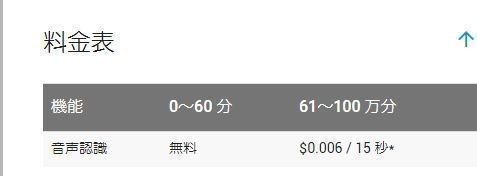
(引用元:https://cloud.google.com/speech/pricing?hl=ja)
これはGoogleの価格表を引用したものですが、
60分を超えると発話時間単位でお金がかかります。
5/3現在のレートで考えると、0.67円/15秒…2.7円/分 ってところですね。
1時間で160円。1日8時間で1,280円、20日稼働で25,600円ですね。
(実際には、運用台数が増えると この数字が台数分増えることになります)
まぁ、これはブラウザをつかえば現段階ではお金がかかりませんが
それは 音声データをGoogleが取得しているところの対価、
という感じじゃないですかね。

(引用元:https://www.google.com/intl/ja/policies/privacy/)
googleのプライバシーポリシーでは、「サービスの改善のために利用する」
と書かれています。なので、個人が特定されないように配慮されるとはいっても、この情報はどこかで再利用されている、ということになります。これは無料版だから、というわけではないようですね。(課金すれば再利用しないとはどこにも書いていない。)
UDトークは、AmiVoiceをつかっています。このサービスでは有料版にすると音声再利用をしないことを明確にライセンス明記しています。

(引用元:http://udtalk.jp/license/)
入力者の負担を避けるとは言っても、実際の所は利用者の利益を最大化し不利益を最小化しなければならないわけですから、利用者の総意・合意がないかぎりは、情報の安全性を担保しているシステムを使うべきでしょう。
(特に、守秘義務がある現場では、致命的になります。)
UDトークの法人向けスタンダードプランは¥24,000/月とのことなので、
先ほどのGoogleと比べてもさほど遜色ない値段ですね。
(月額一定なので、台数がふえてもこのコストで抑えられます)
ちなみに、音声認識が「無料」で使えるのは、これによって得られる
音声データが手に入るからです。データから得られるものは
沢山あります。音声認識に限らず、いわゆる「ビッグデータ」として
解析すればいろんな情報を得ることができます。そのデータが対価で、
結果的に「無料」となっていることを忘れてはいけません。
(少なくとも支援者が勝手に他人のデータを対価に出してはいけません)
そういう点で、AmiVoiceのライセンス内容って、
結構こういうジャンルの仕事には適用しやすいものだったりするんです。
(そして、それを採用しているUDトーク🄬も。)
■実装の仕組みは?

新しいIPtalkではこういう認識プロセスで音声認識をうごかしているようです。それ以外にもAPIを使う方法も用意されていましたね。(APIのほうは、別のアプリを中継してSpeech APIへデータをおくり、音声文字情報を受け取っている仕組みになっています)
Googleの音声認識APIの仕組み上、Google Chromeの通信技術が必要で、
結果的にChromeを仲介するプログラムをつかって認識させている、という感じでしょう。
■で、実際の使い勝手は?
現段階のIPtalkは、音声入力するとブラウザで認識されて、
認識結果は即座に確定結果として表出されるようです。
現段階では訂正パレット送信もできなかったので
誤字を直す、といったことは訂正Wで行うことになるようです。
(ただ、同じような言葉がたくさんあると直しづらく、
修正位置指定ミスにより新たな誤字を生むこともありますが…)
UDトークやまあちゃんは、音声認識単位で固有のIDをもっていて
「この文章をなおす」とピンポイントで指定できる仕組みがあるので
このあたりの問題はクリアしています。

ここで、前述の表をもう一度出してみてみます。
音声認識では、間違いやすい言葉、発音があるので
機械がよく間違える読みを登録し、認識動作を修正できることが
正しい表記をするための1アクションになります。
しかし、Google音声認識ではそれができないのが欠点です。
また、連続発話認識をさせようと思っても、現段階では
無料で完全にできる手段がないという点も、特筆すべき点です。
講演とかでは音声を連続認識させる必要があるため、
ぶちぶち認識が切れてしまうのでは、使い勝手が悪いわけです。
IPtalkで行う現段階の利点は、教育コスト、という点でしょう。
すでに導入している場所では、バージョンアップして実施するだけなので
特に教え込まなくても表出はできるという点はあります。
ツールを新たに入れることに抵抗がある人・組織にとっては
短期的な視点では大きなメリットだとおもいます。
音声認識を併用することを前提につくられているUDトークと、
入力と音声をフレキシブルに使うことを前提に設計したまあちゃんは
最初使い方を数時間学ぶという「投資」は必要です。
ただし、認識率が高い音声認識システムを採用できることや、
「連続発話認識」を長時間継続できるメリットは大きい事でしょう。

■で、結局どれがいいの?
現段階では、情報保障につかうためには、
①すべて人力でカバー
②情報安全性が確保されたものを契約してつかう
③他社に情報がわたることを理解したうえで、無料のものをつかう
という3選択肢があり、これを選ぶことになります。
①はIPtalk(従来)あるいは他のツール、
②はUDトーク(法人版)か、
認識率を犠牲にしたうえでPC版音声認識をつかう
③はIPtalk 音声認識版か、個人利用版のUDトーク
という解決方法になるでしょう。
これらを考えて使い分けていく必要があります。
(逆に、利用者に説明できないまま③を選んではいけません。)
また、音声認識を用いたいと言っている方の話をざっとまとめると
・話している内容をしっかりトレースしたい
・できるだけ早く内容をつかみたい
・誤字の修正は早いほうがいいが、それより情報を先に。
・読みがなもしっかり振ってほしい
という声も多いです。
なので、認識途中がしっかり表示され、ルビ振りも
自動でできるというのは大切な視点/仕様かと思います。
■今後は…
「音声から文字データを起こし、情報保障をしていく」プロセスをつかう手法が確立され、音声認識のUDトークを導入している学校、自治体、企業がどんどん増えてきています。
逆に、音声認識を使わず、従来通り、IPtalkを採用している団体、企業もあります。
また、UDトークとIPtalkを併用するために、まあちゃんを適用している団体も増えてきました。
文字支援では、これらのシステムをうまく使い分けながら利用者さんを支援する必要があります。当然、省人力、省コスト、安全性は両立したうえで。
また、背反としては、IPtalkが(この音声システムを実験とはいえ)導入したことにより、利用者側から文字を見た場合に「音声で出した文字なのか分からない」現象がおきつつあります。現段階でgoogle音声認識しか選択肢のないIPtalkでは、利用者側から「意図せず音声認識を使われた」ことを認識できない、という課題は残ります。このあたりは変換プロセスから音声をつかっているかどうか判断できる「UDトーク」と大きな違いがあると言っていいと思います。
ともあれ、研究段階なので、課題がでて当然。
あとはどうしていくか、です。温かく見守るのがいいのでしょうかね。
(福祉分野は手をつなぐのが下手なので、ツールチェーンとしてつながるほうがメリットが大きい気がするのだけど・・・このあたりはどうなんでしょうね。)
今後、システムの使い分けなども、研究していくのがよいでしょう。
ぜひ、大学で卒業研究を始めたひとがいたら、このあたりにも
目を向けてみたら面白いかと思います。
■補足
最後にコメントですが、筆者は まあちゃんを製作しているので、
他のシステムに関して 視点が偏っている可能性があります。特にIPtalkに対してどうこういうものではありませんのであしからず。一考察としてお受け取りください。(なるべく偏らないようにはしておりますが、システムとして先行しているアプリ・機材を触ってしまっているので、視点がどうしても偏っている可能性はあります。)その点を踏まえてお読みいただければ幸いです。
開発したり研究したりするのに時間と費用がとてもかかるので、頂いたお気持ちはその費用に補填させていただきます。