
「近似」、なんと美しい言葉か

・1300字強
・最近、JSで #形態素解析 をする必要があったので、JSで形態素解析をする方法について調べていたら、 #TinySegmenter というライブラリが出て来た。コードを斜め読みしてみたけど、これは美しいコードだよ。
・形態素解析とは、文章を、品詞やその活用といった最小単位に分割する作業のことだ。
・「お待ちしております。」という文章を形態素解析すると、こうなる。
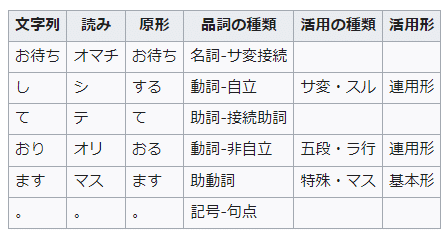
・これが何の役に立つかと言えば、「色々」としか言いようがない。
・例えば、「from:@mogugu_umauma クリスマス」で検索すると私の日記が10個ほどヒットするけど、「クリスマス」を「クリスマ」にするだけで、この記事しかヒットしなくなる。「クリスマス」の中には「クリスマ」という文字列が含まれているのに関わらずである!
noteのサーバ中では、記事を形態素解析することで検索速度を上げているのだろうと予測できる。
・コンピュータに形態素解析をさせると、複雑なアルゴリズムとでかい辞書が必要になるために、プログラムのサイズが大きくなる上に処理も重くなる。
・Tinysegmenterの作者が作ったもっと本格的な形態素解析ソフトの一つにMeCabというものがあるが、そちらは本体8MB+日本語辞書52MBくらいのでかさである。
・が、TinySegmenterはそれを僅か24KBほどのプログラム(辞書は内包)でそれを実装している! 厳密さを捨てて、いいかげんに分割するだけでソフトのサイズが2500倍ほど小さくなるのだ……
・24KBがどれくらい小さいかというと、めっちゃ大雑把に言うとIphoneで撮った写真一枚より100倍くらい小さいサイズなのだ。
・厳密に言うとTinySegmenterは品詞付与を行わないので形態素解析ではなくただの分割なのだけど、「品詞の種類はわからなくていいからとにかく文章を最小単位にまで分割したい」というときはこれでいいのだ。
・Tinysegmenterのコードを見て見ると、その泥臭い美しさがわかる。

・こんなんがズーッと続いている。
・プログラミングに触れたことのない人も、この泥臭さだけは伝わるのではなかろうか。日本語の切れ目に頻出するフレーズを列挙して、それを根拠に、分割すべき部分を推定しているのだ。本来はでっかい日本語辞書を用意しないと分割できないはずなのに、Tinysegmenterはちいちゃい辞書しか使っていない。
・そのちいちゃい辞書も、プログラマの勘で作ったのでなく、ちゃんとデータから学習してモデルを作ってるのだとサイトに書いてある。
・ #近似 、なんと美しい言葉か……
・正確性を欠くことでデータを著しく軽くできる上に速度を著しく向上させられることができることがあるのだ。
・近似、人間もよくやっていると思う。本来はもっと記憶をして思考を巡らせればより合理的な判断ができるのに、そうしなくても見かけ上は妥当な振る舞いができるアルゴリズムが存在するために、そちらで満足することによって、思考プロセス量や記憶容量を節約するのだ。認知バイアスの多くは、近似の弊害だと思う。
次回はその一例について書きます。
・おわり