
講義「データサイエンス」の演習課題を「Code Interpreter」と解いてみる

ChatGPTの有料プラン「ChatGPT Plus」の新機能「Code Interpreter」を試してみました。Code Interpreterは、ユーザがファイルをアップロードしたり、Pythonプログラムを実行できる機能です。データを読み込ませてPythonで分析できるので、データサイエンスの授業でもこの技術を使いこなすためにはどうしたらいいかを見ていきたいと思います。
そこで、今回はCode Interpreterを用いて、私が勤務する大学で1年生向けに開講している「データサイエンス」の講義で演習に使っている、タイタニック号のデータに関する分析を試みてみました。
データサイエンスの演習課題
データはKaggleというサイトで公開されており、csvデータをダウンロードすることができます。サイトでは機械学習のモデルの精度を比較するために、学習用のデータ(train.csv)とテスト用のデータ(test.csv)という2つのデータがダウンロード可能ですが、学習用のデータ(train.csv)のみをダウンロードしてきて使います。
このデータを利用して講義の演習では、次のような問題を出しています。
タイタニック号の乗客数(クラス別)の棒グラフを作成しなさい。
タイタニック号の生存者(クラス別)の集計表とその帯グラフを作成しなさい。
男性、女性、生存者、非生存者のクロス集計表とオッズ比を求め、男性か女性かで生存に関係があるかを調べよ。
講義では、こうした課題を解くためにMicrosoftのExcelを使った方法を伝えています。データ分析の一番の目的は、こうした質問に答えを出すことですが、授業ではExcelの操作方法を学ぶのに一生懸命になってしまい、分析した結果の考察に注意が払われにくいということを課題に感じていました。
Code Interpreterで演習課題を解く
そこで、早速Code Interpreterを使ってこの課題に答えてもらいました。
まずは、データ(train.csv)をアップロードします。同時に、データに何が含まれているか教えてもらいます。
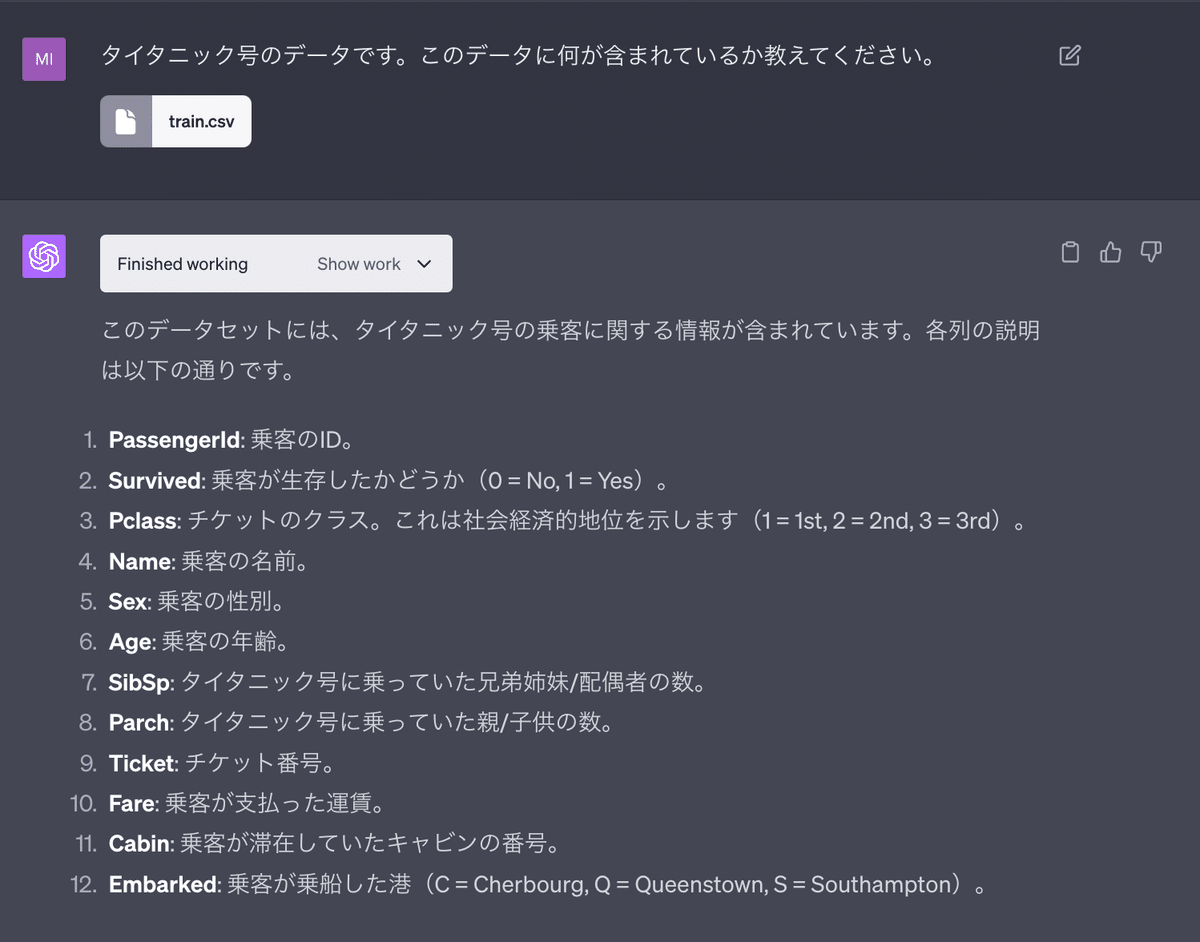
これらの情報はPythonプログラムを実行した結果から生成しています。そしてどんなPythonコードを実行したのかを「Show work」をクリックするとみることができます。たとえば、この場合は次の通りです。
import pandas as pd
# Load the dataset
titanic_data = pd.read_csv('/mnt/data/train.csv')
# Show the first few rows of the dataset
titanic_data.head()自動生成されたコードと出力を見ることで同時にPythonの勉強もできそうですね。
それでは、データを読み込んだのでまず「乗客数のクラス別の棒グラフを表示」してもらいます。すると以下のように1stクラス、2ndクラス、3rdクラスと3つのクラスごとの乗客数をカウントして棒グラフを作成してくれました。
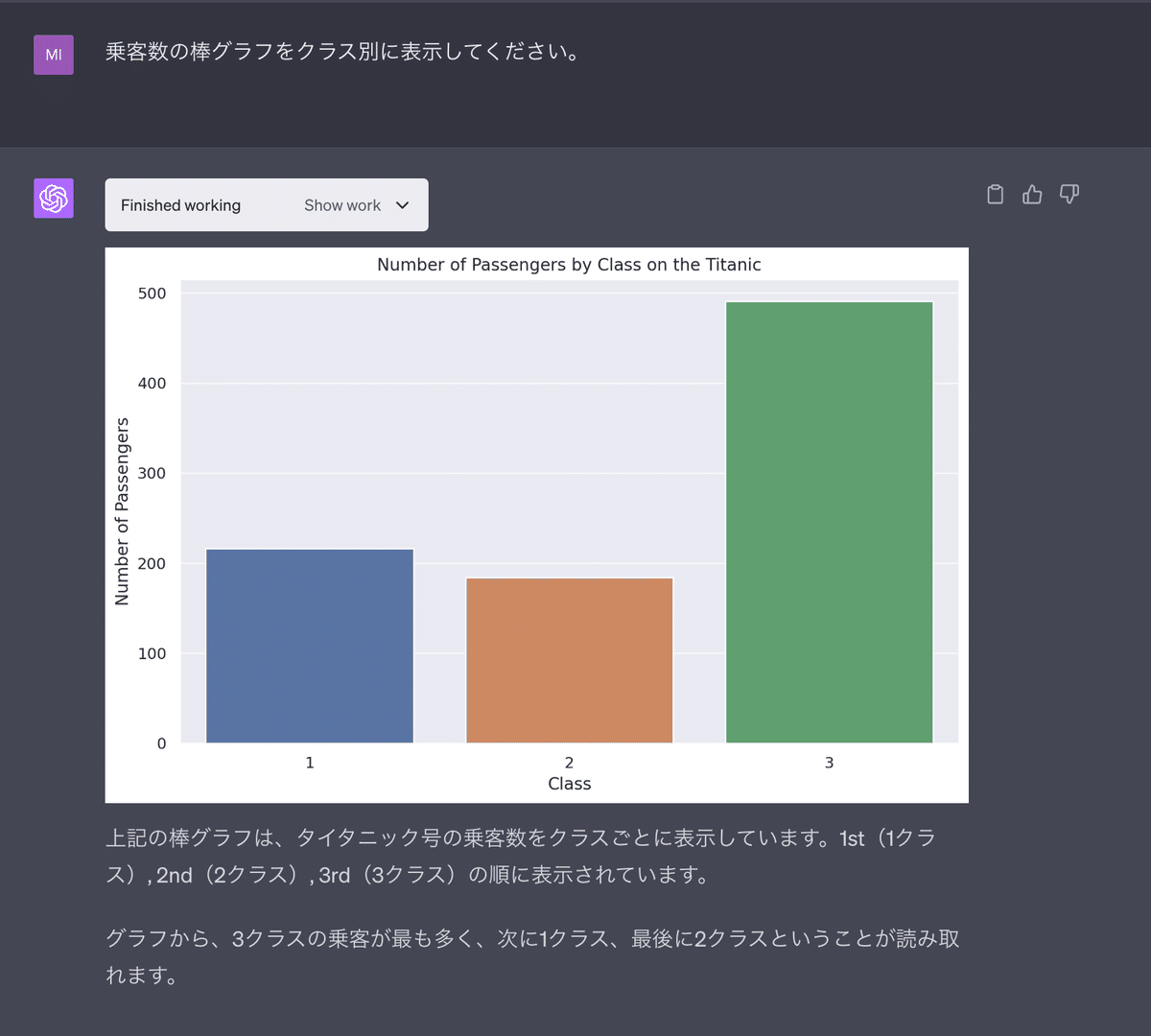
さらに嬉しいのが、グラフに対する解釈も加えてくれていることです。
それでは、次に、「クラス別の生存者の集計表と帯グラフ」を作成してみましょう。こちらも瞬時に作成してくれました。
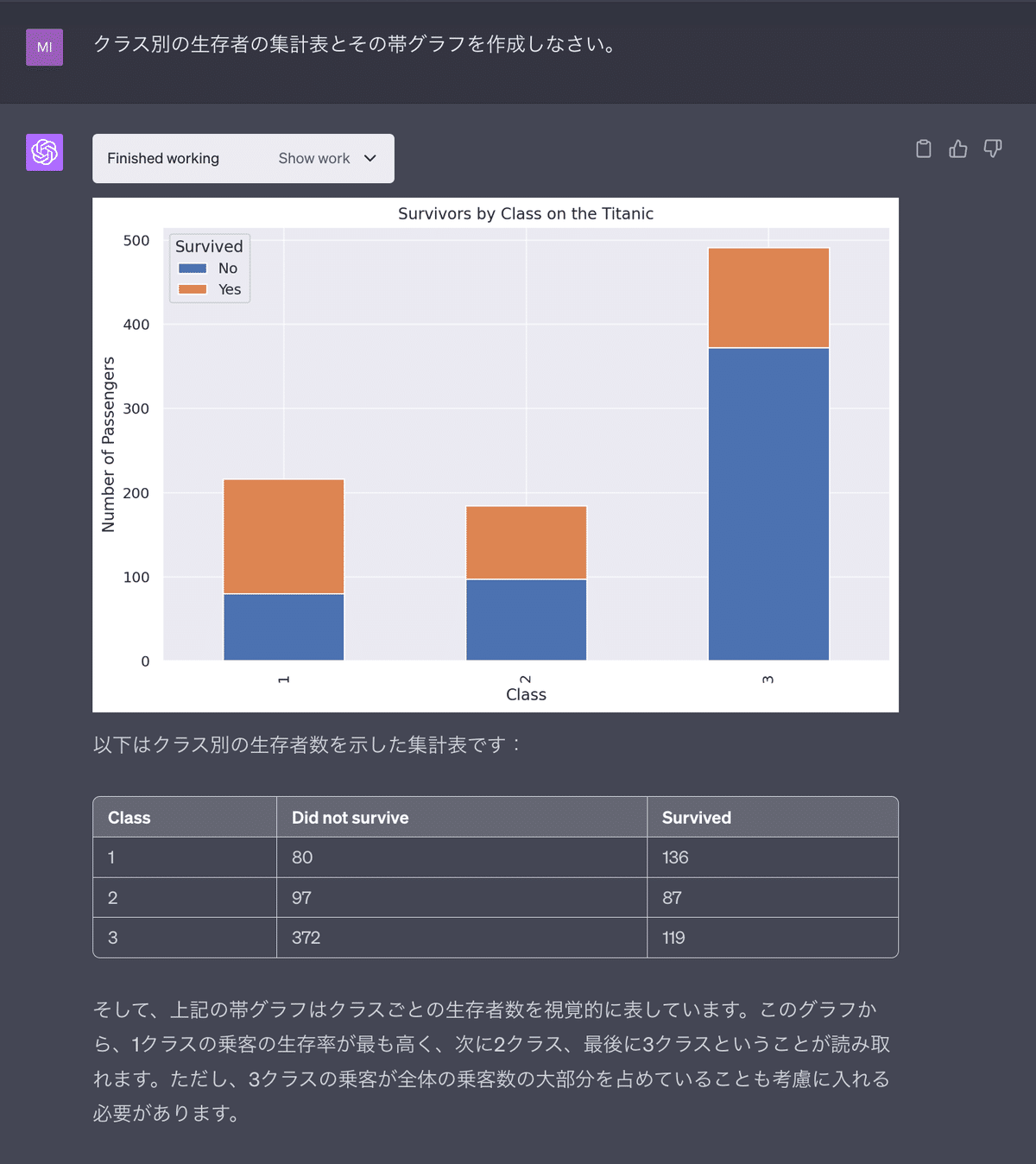
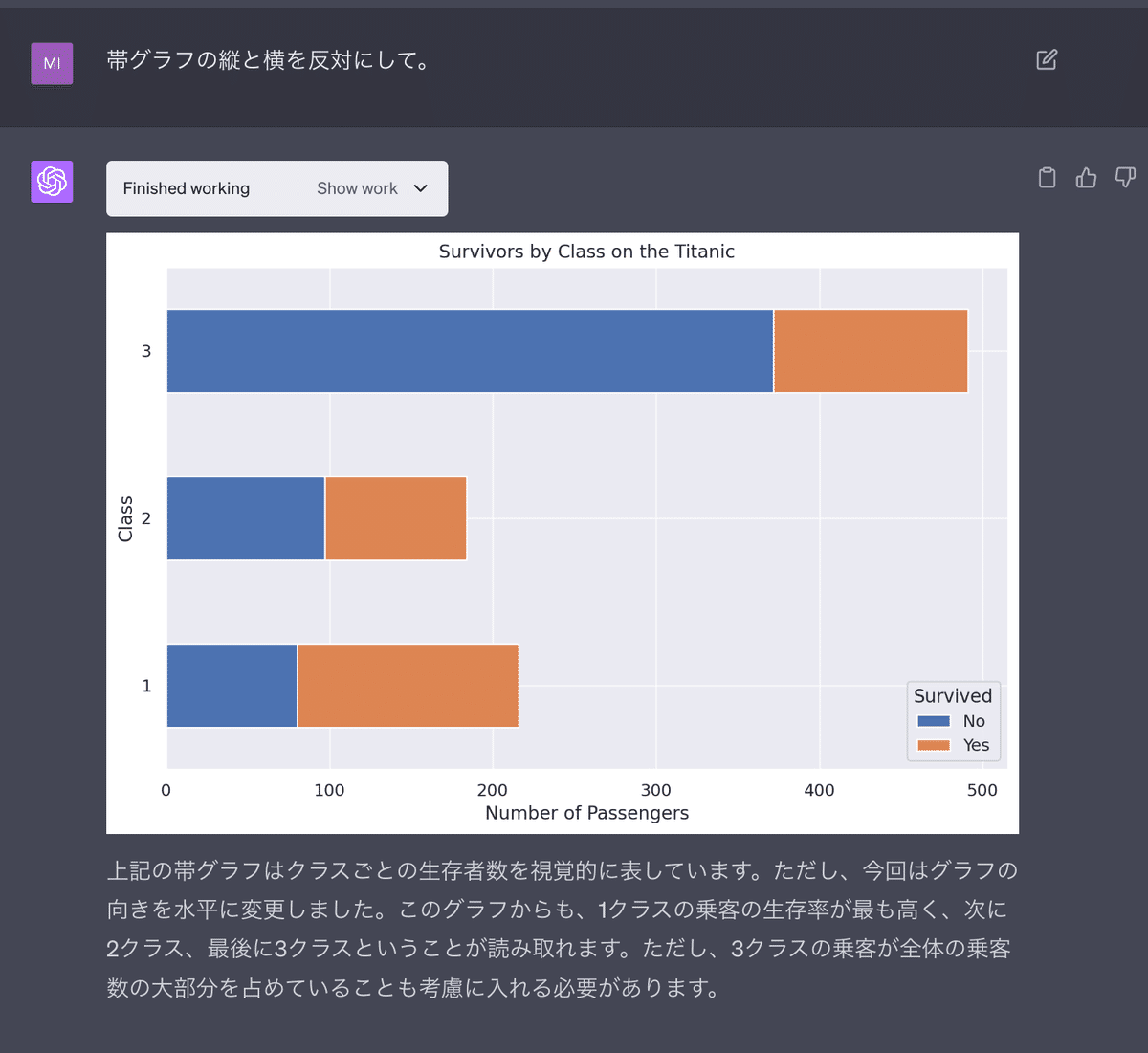
この結果から、解釈にもあるように、1stクラスの乗客の生存率が最も高い事がわかります。
帯グラフは横向きの方が見やすいので、横向きに変更してもらいましょう。
次に、クロス集計表とオッズ比から男性か女性かで生存に関係があるかを調べてもらいます。オッズ比は、2つのグループ間の結果の発生率の比率を示します。分析の結果、女性の方が男性よりも生存の可能性が高いことが分かります。

もちろんここでそもそも「オッズ比」とは何かをChatGPTに聞くこともできます。

そして、どのように計算し、結論に結びつけたのかを詳しく聞くこともできます。

タイタニック号のデータに触れながら、非常に丁寧に説明してくれていて、わかりやすいです。また、p値というデータサイエンスの講義でも後半に扱う内容に関する結果も示されていますが、これもどのように計算したのか、どのような意味なのかといったことを尋ねることで、理解を深めることができます。
データサイエンスの知識や質問力も重要
ということで、Excelを使った演習よりも、Code Interpreterを使い、Pythonコードをチェックしながら分析していく方が、分析の結果の解釈に注意を払うことができて、非常に有益だなという感想を持ちました。まるで隣りに優秀なデータサイエンティストが常に待機してくれて、知りたいことをグラフと共に示してくれるように快適です。
もちろん、ここでデータサイエンスの講義そのものが意味がないと言いたいわけではありません。どのような分析方法があるのか、どのような可視化方法があるのか、統計的に有意な差があるかどうかを調べることは重要である、といった概念を学ぶことは、Code Interpreterという便利なツールがあっても非常に大切です。
そのひとつが、例えば、「欠損値をどのように扱っているのだろう」という疑問を持てることです。欠損値とは、取得できなかったデータのことで、タイタニック号のデータにも存在します。欠損値をどのように扱うかはバリエーションがあり、その扱い方によって結果の解釈が異なります。そのため、欠損値を含む項目に関する分析を行う場合は、欠損値をどのように処理して欲しいのか明確に指示することが重要です。
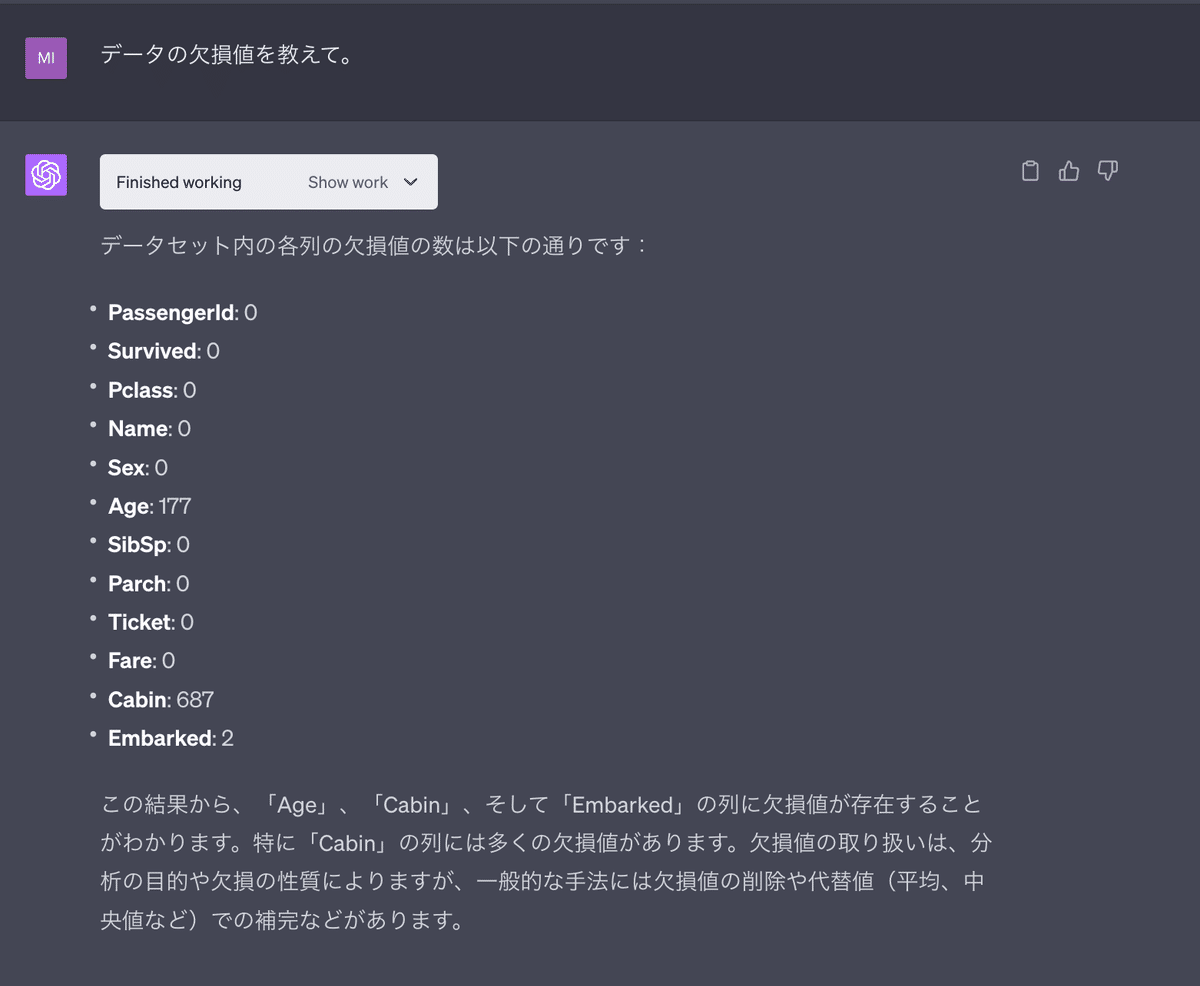
データにどのような欠損値があるかを聞いてみると、「年齢」「キャビン」「乗客が乗船した港」に欠損値があり、それぞれいくつかあるかを教えてくれます。
欠損値の扱い方の一例として、「最近傍法」という手法を用いてみましょう。最近傍法とは、欠損値を持つデータの最も近くに他のデータを用いて値を補う方法です。
欠損値を最近傍法(K-Nearest Neighbors)を用いて補完し、
性別と年齢による生存率の違いをswarmplotと箱ひげ図を重ねて可視化してください。
swarmplotでは、marker='o'を利用してください。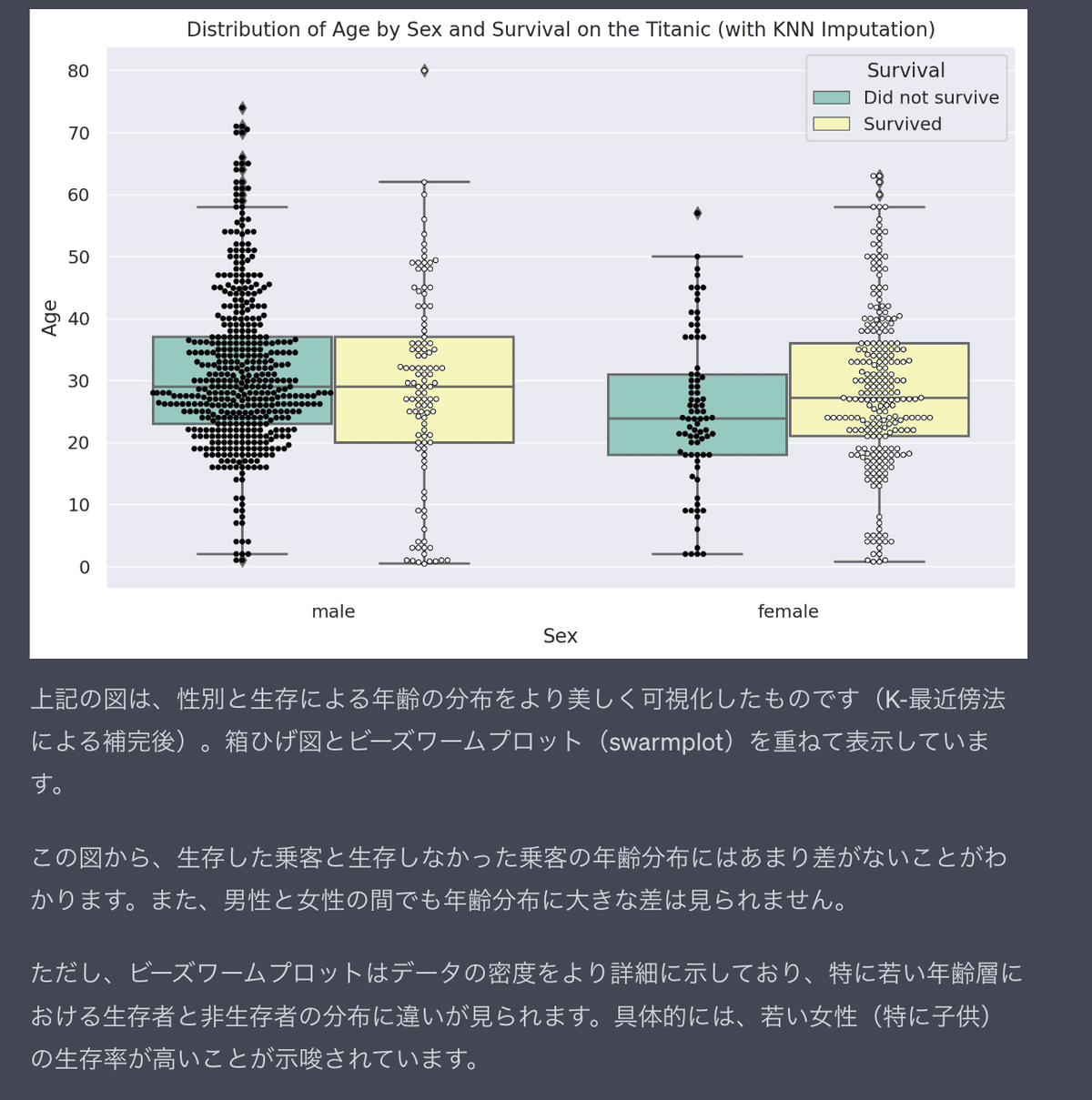
最近傍法を用いて欠損値を補完したデータを使ったswarmplot(一人ひとりの年齢のデータを表示)という可視化方法と、中央値や最小値、最大値などを示してくれる箱ひげ図を重ねた可視化方法で出してくれました。
この結果から、若い女性の生存率が高いことがみてとれますし、男性でも若い年齢層は生存者の割合が少し高いかもしれません。
Code Interpreterの利点とその利用
このように、データから知りたいことを言葉で指示するだけでさまざまな分析結果を示してくれるCode Interpreterは、分析結果の解釈に注力することができ、非常に有益なツールです。特に、Excelを使うよりも、Pythonコードをチェックしながら分析していく方が効果的であると感じました。
分析のプロセスがPythonコードで明示的に示され、具体的なコードの操作がどのような分析結果に直接つながっているのかを理解しやすいからです。慣れもあるかもしれませんが、Excelでは処理と結果の直接的な関連性が見えにくいことがあります。Pythonコードとの具体的な操作と結果の関連を確認しながら、結果を見ることで、分析の透明性が高まり、より深い理解と洞察につながると思います。
一方で、Code Interpreterのような便利なツールが存在する現代において、データサイエンスの基本的な概念を理解することの重要性も改めて認識する必要があります。どのような分析方法があるのか、どのような可視化方法があるのか、統計的に有意な差があるとはどういうことなのか。こうした知識を踏まえることが、質問力にもつながると言えます。そして、新しい技術を使いこなすことで、さらに深い洞察を引き出すことができるようになることは間違いありません。