
論文「Self Generated Wargame AI: Double Layer Agent Task Planning Based on Large Language Model」の紹介

目次
本記事の概要
戦略ゲームにおいてChatGPTに意思決定を行わせるAIを提案する論文「Self Generated Wargame AI: Double Layer Agent Task Planning Based on Large Language Model」を紹介する記事となります。
本論文の紹介
論文名
Self Generated Wargame AI: Double Layer Agent Task Planning Based on Large Language Model
著者
Yuxiang Sun
School of Management and Engineering
Nanjing University
Junjie Zhao
School of Management and Engineering
Nanjing University
Checheng Yu
School of Management and Engineering
Nanjing University
Wei Wang
School of Intelligence Science and Technology
Nanjing University
Xianzhong Zhou
School of Management and Engineering
Nanjing University
投稿日時
December 19, 2023
URL
本論文の概要
本論文では、戦略ゲームにおいてChatGPTに意思決定を行わせるゲームAIを提案しています。
具体的には、戦略エージェントと戦術エージェントの2層構造で構成されるAIとなります。
戦略エージェントは、タスクの計画と各戦術エージェントへのタスクの割り当てを行います。
戦術エージェントは、割り当てられたタスクを実行し、戦略エージェントに実行結果をフィードバックします。
赤軍ユニットと青軍ユニットで構成されるウォーゲームシミュレーション環境を構築し、性能比較の実験を行いました。
その結果、提案AIが従来の強化学習型AIやルールベースAIを上回る性能を示すことが判明しました。
提案AIの利点
訓練が不要
従来の強化学習AIは、特定のゲームの環境に対応するために長時間の訓練を必要とします。
一方、LLMを利用する提案AIは、事前学習済みのため追加訓練が不要です。
高性能
提案AIは強化学習AIと比較して、より高い勝率を達成しています。
特に、専門家の知識を組み込んだAIは最も高いパフォーマンスを示しています。
高い解釈可能性
提案AIは、自然言語で意思決定の根拠を説明できるため、その根拠がより理解しやすくなります。
2層エージェントタスクプランニングモデル

上図は本論文で提案されている2層エージェントタスクプランニングモデルによる意思決定のフレームワークとなります。
本モデルは、戦略エージェントと戦術エージェントの2種類のモデルで構成されます。
戦略エージェント
GPT-4のLLMとなります。
観察された状況情報をもとに、暫定行動計画(Preliminary Plan)を生成し、各戦術エージェントに提出します。
状況情報とは、敵と味方の位置や状態(攻撃、防御、移動、隠蔽)などに関する情報になります。
各戦術エージェントからPreliminary Planの修正案を受け取り、それに基づき戦略エージェントが計画を修正します。
修正版を戦術エージェントに再提出し、さらなる修正案を受け取ります。
この作業を修正案が出なくなるまで繰り返し、Preliminary Planの完成版を作成します。
計画生成時に専門家の知識や、メモリ内に保存された過去の行動・行動結果・観察情報を参照する場合があります。
戦術エージェント
複数存在し、戦略ゲーム内の各ユニットに相当します。
すべてGPT-3.5のLLMとなります。
現在の環境を観察し、状況情報を収集し、戦略エージェントに伝達します。
戦争の霧が設定されており、戦術エージェントは自身の周囲の限られた範囲内の情報しか直接観察できません。
戦略エージェントから渡ってきたPreliminary Planに対して修正案を提出します。
完成版のPreliminaryPlanに基づきタスクを実行します。
修正案作成時に、メモリ内に保存された過去の行動・行動結果・観察情報を参照する場合があります。
シミュレーション実験による検証
実験シミュレーション環境
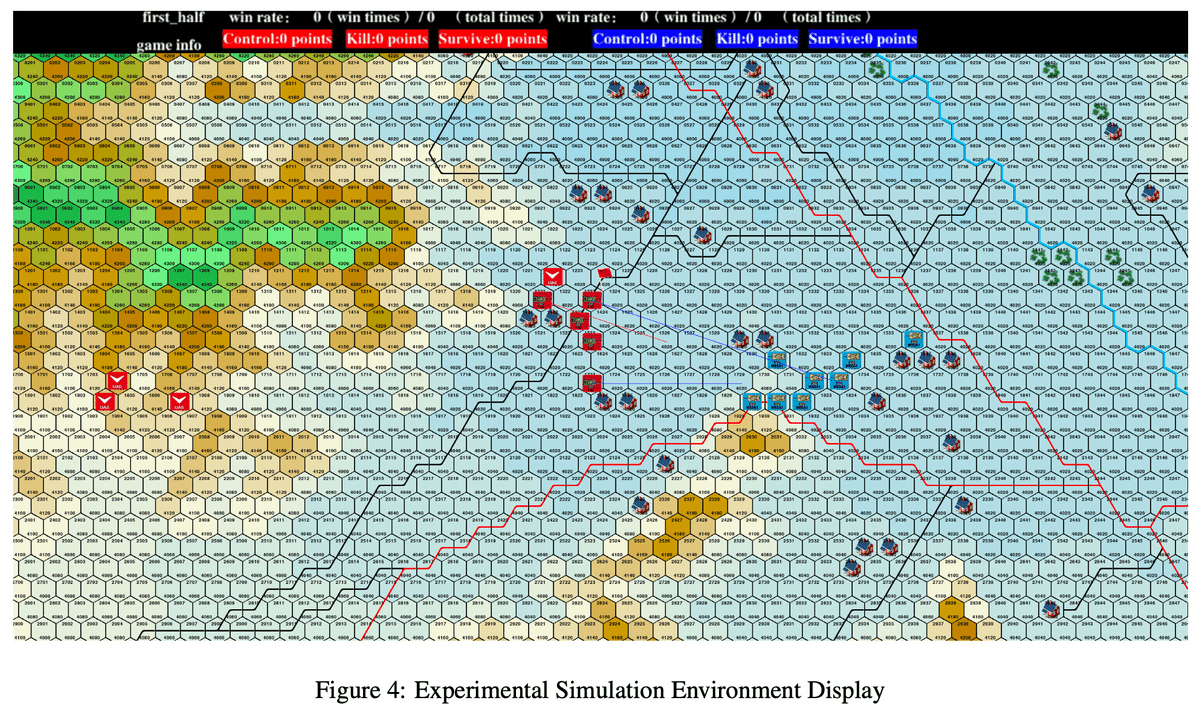
上図は、提案手法の有効性を検証するために構築したウォーゲームシミュレーション環境となります。
この環境下で、提案手法であるGWAおよびGWAE(専門家の知識を追加したGWA)と、従来の強化学習型AIやルールベースAIとの性能比較の実験を行っています。
図における、赤と青のタンクのようなものは、恐らく各陣営のユニットです。
中央の赤旗はおそらく制御ポイントであり、赤軍と青軍はこの制御ポイントを奪い合い、先に制御ポイントに到達した側、または相手を全滅させた側が勝利となります。
地形は、六角形のグリッドで構成され、各グリッド上部の数値は地形番号、下部の数値は地形の種類の番号を恐らく表しています。
図の上部の黒背景の部分はステータスバーであり、win rate, win times, total timesはそれぞれ、勝率、勝利数、ゲームのプレイ回数を恐らく表しています。
Controlは制御ポイントの取得回数、Killは相手ユニットの撃破数、Surviveは自軍ユニットの生存数を恐らく表しています。
使用アルゴリズム
本実験で使用したアルゴリズムは以下の通りです。
GWAE
GWA
RNM-PPO
PPO
PK-DQN
DQN
実験結果

このグラフは、各アルゴリズムの累積勝率の推移を示しています。
横軸はエピソード数を、縦軸は累積勝率を表しています。
エピソードや累積勝率の定義については触れられていないようですが、エピソードの定義としては、例えば、以下のようなものが考えられます。
1つのゲームの開始から終了までの期間
一定回数のゲームプレイを1エピソードとするような期間
累積勝率の定義としては、以下のようなものが考えられます。
現在までの全エピソードにおける合計勝利回数 / 現在までの全エピソードにおける合計プレイ回数
現在のエピソード内での合計勝利回数 / 現在のエピソード内での合計プレイ回数
GWAEとGWAは、他の強化学習アルゴリズム(RNM-PPO、PPO、PK-DQN、DQN)よりも高い勝率を示しています。
特に、専門家の知識を組み込んだGWAEは最も高い勝率を達成しています。

このグラフは各アルゴリズムの勝率の分布を示すバイオリンプロットです。
バイオリンプロットとは、データの分布を示すグラフであり、横幅の広さはその位置のデータが多いことを示します。
GWAEとGWAは、他のアルゴリズムよりも高い位置にデータが集中しており、より高い勝率を多く達成していることがわかります。
所感
ChatGPTなどのLLMをゲームAIの開発に応用するのは面白い試みだと思います。
LLMを利用した開発は、従来の適切な報酬設計と膨大な訓練が必要になる強化学習型AIの開発に比べて、開発難易度が低いかもしれません。
そのため、将来的には、高性能かつ開発難易度の低いLLM型ゲームAIが主流になるかもしれません。
一方、LLM型AIが推論の際に消費する膨大な計算資源は課題であるかもしれません。
強化学習型ゲームAIの場合は、一般的に推論時に必要となる計算資源は少ない傾向にあると思います。
なぜなら、LLMは、さまざまなタスクで利用できるよう何十億ものパラメータを持つのが一般的です。
それに対し、強化学習型ゲームAIはゲーム内の特定のタスクを最適化するために設計されており、シンプルでパラメータ数も小さくなる傾向にあるからです。
例えば、本記事著者が開発したこちらの3色鬼ごっこゲームの強化学習型AIモデルは、その容量がわずか1.3MB程度であり、低スペックのモバイル端末上でもリアルタイムにスムーズに推論することが可能です。
あるいは、低スペック向けのゲームでは強化学習型AI、それ以外ではLLM型AIというように、ゲームの特徴に応じて適切な開発手法を選択することが重要になるかもしれません。
LLMを用いたゲームAIの研究は、まだ初期段階にあり、今後、さまざまなジャンルのゲームへの応用事例が増えていくことで、LLMの可能性と限界が明らかになると思います。
その限界を克服し、ゲームAIが更なる進化を遂げることに期待しています。
使用AI技術
Claude 3.5 Sonnet
本論文の要約と、本記事の添削に使用しました。
GPT-4o
本論文の要約と、本記事の添削に使用しました。
DALL-E3
本記事の表紙画像生成に使用しました。
Adobe Firefly
本記事の表紙画像の中央の旗の生成に使用しました。
使用画像
「2層エージェントタスクプランニングモデル」、「シミュレーション実験による検証」の項目に掲載した画像
全て本論文に掲載されている画像となります。