
システム間連携機能実装におけるアプリケーション・アーキテクチャ

こんにちは、タケヒロです!
前回は、弊社でのEAI/ETL(以下、EAI)導入にあたり、検討している適用ユースケースをご紹介しました。
その後、PoCを経て、実際にEAI製品(※)を導入、運用を開始したので、今回はEAIでの実装時に気づいたポイントをお伝えしたいと思います。
※ … 弊社では、Magic社のxpiと言う製品を採用しました。数あるEAI製品の中でも、コストパフォーマンスに優れている、と言うのが理由です。本稿は、Magic社xpiを前提に記載しています。
まず、導入した感想ですが、総論としては「とてもいい!」です。
処理実装に際してこれまで使用した機能(アダプタ)は、REST通信、RDB接続(R/W)、ファイル連携(フォルダ/SFTP)、Salesforce、Kintone連携、メール(SMTP/POP)連携ぐらいですが、さすがにデータ連携特化ソリューションなだけあって、この辺りはお手の物で、ノーコードでサクサクと実装できちゃいます。
スクラッチで同等の処理を作るのと比較すると、生産性は5倍ぐらいになる感覚です(あくまでも個人の感想です)。
やりはじめたら想像以上に楽しく、身の回りのいろいろな連携処理をEAIで実装してみました。
そんなEAI、簡単に実装できるのですが、勢いに任せてなんでもかんでもEAIで実装すれば良いのか?と言ったら、そうでもなさそうです。
ひとしきり試してみて、EAIを前提としたアプリケーション・アーキテクチャとしてこんな形が良いのかな、と言うデザインパターンのベストプラクティス的なものが何となく見えて来たので、ご紹介したいと思います。
大小いろいろありますが、全体的なところでは以下の4点かな、と思っています。
1.コンポーネント分割
オブジェクト指向やマイクロサービス・アーキテクチャに基づいたソフトウェア開発に慣れ親しんだ開発者の皆さんにとっては当たり前のことだと思いますが、やはり、開発時には、システム全体を意味のある単位(役割単位)にコンポーネント分割すべきだよね、と言う話です。
EAIなら、GUIを使い、ペインから選択した部品をワークスペースにどんどんドラッグ&ドロップして、部品同士を線でつなげて…、と、マウス操作で処理フローがサクサクと実装できてしまうため、ついつい楽しくなり、気づいたらフローがダラダラと長くなってスパゲッティ状態に…と言う結果に陥ってしまいそうです。
しかし、EAIもプログラミング言語と同じく、処理を実装するための表現手段のひとつなので、やはりそこは基本に忠実に、機能分割すべきです。
弊社での一例ですが、以下の様な業務処理があります。
・提携先の企業システムからデータを取得(E)
・データ変換(T)
・弊社の既存基幹システムに取り込み(L)
正に、Extract → Transform → Loadと言うETLの例題のような業務です。
図で表すと、以下の通りです。

さすがに、「データ取得&変換&基幹システムインポート」の処理をひとつのフローでは実装しません。ゴチャゴチャしますから。
今回は、まず、これを以下の4つのフローで構成しました。

それぞれのフローの役割、処理概要、分割時のポイントは以下の通りです。

このように、処理を分割することで、実装の可読性が高まりますし、コンポーネント(フロー)単位で保守すれば良くなるので、保守性や耐障害性(後述)もぐっと上がります。
更に、同じ様な業務フローを実装する際に、テンプレートとして再利用できる可能性も出てくるのです。
2.依存性の排除
「1.コンポーネント分割」で、フロー単位への分割について書きましたが、処理を分割するということは、当然、フロー同士の連携が必要になってくるわけで、そのI/Fをどう実装するか、と言うのも大切な検討ポイントです。
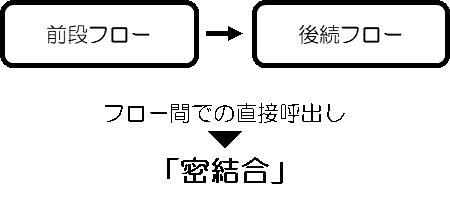
製品の仕様にもよると思いますが、弊社が採用したMagic社のxpiでは、定義したフローから別フローを直接呼び出すことが可能です。
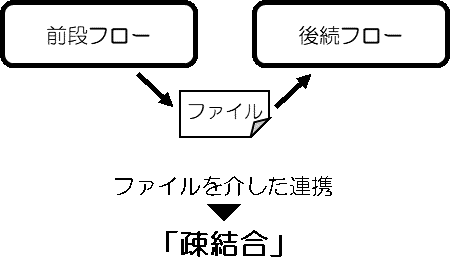
ただ、今回は、あえて直接フローの呼び出しはせずに、フラットファイルやDB(RDB)経由で連携するように実装しました。
フラットファイルの場合、前段のフロー(呼び元)はその結果をファイルに出力し、後続のフロー(呼び先)は、ファイルトリガー機能でファイルを監視し、前段フローの出力ファイルをみつけたら処理を開始します。
こうすることで、それぞれのフローが、データ読込 → 変換 → データ出力と言う独立した小さなETL処理として完結し、フロー間は疎結合となります。その結果、対障害性や保守性、拡張性、再利用性や移植性(ポータビリティ)がさらに増すと考えています。
以下に、疎結合化による主なメリットをピックアップしました。
・対障害性(障害復旧性)
あるフローで障害が発生した際に、障害箇所で処理されたデータをロールバックし、不具合を解消した上で、そのフローを再起動することでリカバリーが可能になります。
フローを分割していない場合、全体の処理の途中で処理が失敗した場合でも、もう一度一番最初から再実行が必要です。また、データリカバリーも煩雑になります。
・拡張性
例えば、データ変換処理のCPU負荷が高い場合、データ変換処理のみを多重化(水平拡張)する、と言うことが可能になります。
フローを分割しなければ、CPU負荷の高くない業務データ抽出機能も無駄に多重化されることになったり、データの順序性を担保する必要のある外部連携機能が多重化されることで、スレッド間で処理タイミングを同期させる考慮が増え、より処理が複雑になったりする可能性もあります。
・移植性
今回のデータ変換処理は、EAIで実装する必要のない(しない方が良い)処理でした。フロー間が疎結合であれば、一旦EAIで実装したとしても、将来的にその部分だけ別のプラットフォームに移植することが可能になります。
移植性については、より詳細に後述します。
3.処理の汎用性確保のためEAIで作らない方がいい場合もある
逆説的なことを書きますが、いかにEAIを使わないで処理を実装するかを考えるのも大切なことだと考えています。
「2.依存性の排除」で、それぞれのコンポーネントが相互に依存しないメリットを記載しましたが、もっと言えば、EAIへの依存性も排除するに越したことはありません。
ひとつの例ですが、メールやSlack通知処理なんかは、EAIの標準機能で比較的簡単に実装できます。ただ、それらは、JavaScriptやPythonで書いてもそれほど大変なわけではありません。
ソースコードを見るのも蕁麻疹が出る。。。と言うほどのアレルギーであれば致し方ありませんが、これらの単体機能に特化した処理であれば、意外と簡単に書けてしまうので、勉強がてらに作ってみるのも良いと思います。
「1.コンポーネント分割」、「2.依存性の排除」に従って実装されたフローは疎結合で、他のフローと相互に影響しないので移植も容易です。
案件の間の箸休めのタイミングで、気分転換がてらに移植してみた内容を紹介します。
弊社の業務処理では、以下の図のように、フローAとフローBで同じ様なメール通知が必要でした。
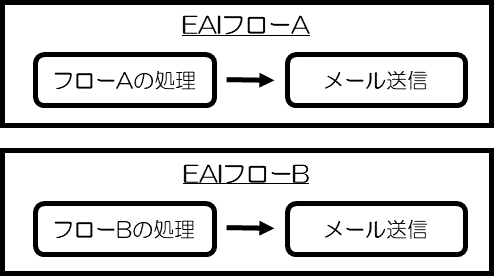
最初は、ふたつのフローそれぞれでメール送信の処理を実装していましたが、以下の図のような共通のメール送信機能を切り出し、それを呼び出す構造に作り変えました。
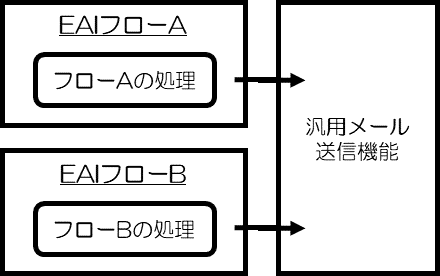
この汎用メール送信機能は、EC2に立ち上げたAmazon Linux上に、JavaScript(Node.js)で実装しています。
Node.jsの選定の理由は特になく、しいて言えば「なんとなく、JSでコードを書きたい気分だったから」と言うぐらいのものです(笑)。
不都合があれば、別の環境・言語で書き直せば良いだけの話です。
弊社ではEmailの一括送信のためにAmazon SESを使っていますが、SESを前提とした各言語のサンプルコードがこちらで公開されており、これを参考にすれば、状況にあった適切な言語で実装できます。
ちなみに、メール送信機能実装にあたり、一番時間をかけて考えたのは、I/F仕様です。いかに外部依存性を排除しかつ汎用的なメール送信機能にできるか、ということを考慮し、I/Fはフラットファイルにしました。また、可読性も考慮して、ファイルフォーマットはkey = valueの形式にしました。
I/F項目には極力メール要素(SMTP要素)は含まない設計にしたので、「メールはやめて、Slackで通知したいんだけど!」と突然の要件変更が発生しても、EAIフロー側の修正は一切不要です。
4.より良いサービスがあれば迷わず使う
OS間でのファイルの受け渡しをEAIで実装しようとすると、FTPやNFS、Samba、AWS S3経由、、といろいろ選択肢はあるものの、どれもそれなりの設定や作り込みが必要になってきます。
世の中には、ファイル連携のクラウドサービスがたくさんありますので、出来合いのサービスを利用するのが簡単です。
弊社では、もともと、ファイル連携用にNextcloudを利用しているので、今回は、メール送信機能へのファイル連携に既存のNextcloudサーバーを流用することにしました。
EAI側のWindowsサーバーにはNextcloudのデスクトップアプリをインストールし、メール送信機能側のLinuxサーバーからは、NextcloudサーバーへWebDAV接続すれば、あとはNextcloudがふたつのOS間のファイルを勝手に同期してくれます。
ファイル連携処理を自分で実装する必要は全くありませんね。
絵に描くと、以下の図の様な感じです。

この汎用メール送信機能は共通機能として稼働しているので、今後様々な処理をEAIで実装する際にも、メール送信の機能は基本的に実装せず、単にkey = valueのファイルを書き出してあげれば良いだけになります。
今回は、弊社でたまたま使っていたNextcloudを流用しましたが、皆さんが既にお使いのファイル共有サービスがあれば基本的に何でも良く、BoxやDropbox、Google Driveとかでも良いと思います。
以上でご紹介した4つのポイントに従い改善した、外部システムとの連携処理の実装は以下の図の様な感じになりました。

大分細切れになりましたね。でも、いいんです。役割ごとに細分化されていると、個々の実装がシンプルになるので、それぞれのフローで何をやっているのかは設計書がなくても大体理解できます。全体の流れだけ抑えておきましょう。
また、EAIで実装すべき処理、他のプラットフォームで実装すべき処理を分けた結果、EAIで実装した処理(図中青線部分)は半分以下になりました。EAI製品への依存性も低くなっていますね。
まとめ
今回は、主に機能のコンポーネント化や疎結合化といった、連携機能実装時のポイントをご紹介しました。
EAIを用いてシステム間連携を行う際には、どのようなアプリケーション・アーキテクチャ(デザインパターン)にすべきかを意識し、必要に応じてEAI以外のソリューションと組み合わせて実装することで、将来的に長く保守でき、かつ変更に強いシステムを構築することができると思います。
なお、今回の内容は、EAIに限った話ではなく、数十~数百TPSと言うパフォーマンスを求められる企業間大量データ連携や、少しの誤差やダウンタイムも許されないシビアな精度を求められる銀行の決済システムでも採用されているアーキテクチャの基本的な考え方をベースにしています。
ぜひ皆様も、システム間連携機能を構築される際には、ご参考になさってください。
逆に、こんなやり方もあるよ!と言うのがあれば、是非共有いただければ幸いです!
●前回の記事
●次回の記事
三ッ輪ホールディングス株式会社 BTI部 部長 タケヒロ
2002年からSIerにて官公庁や大手銀行、海外系電子決済等、主に大規模系B2Bサービス開発に従事。その後、コンサルティングファームを経て2020年に三ッ輪産業株式会社に入社。現在は、三ッ輪グループ全体のデジタル化や業務効率化、社外向け新規サービスの企画・構築を担当。
得意領域(≒趣味)はスクラッチ開発だが、最近は釣りの分野にも活動領域を広げ、仕掛けづくりの研究開発や新たな釣りものの調査にも日夜努力を重ねている。