
PDFからデータ引っこ抜こうぜ!手書き、お前もな!!

みなさま、ご機嫌いかがでしょうか?
自分のご機嫌は自分でとる、No ご機嫌 No Lifeです。
前回はPower Appsネタを書きました。
Power Appsに限らず、エンジニアでなくても出来ることがどんどん増えてきていますね。
新しく覚えることは沢山ありますが、ChatGPTさんもいらっしゃいますし、気楽に新しことにチャレンジしましょう!
今回はPDFからデータを抜き取ってみます。
紙を撲滅して手作業も減らしていこうぜ、がいいですよね。
伝票関係はなんだかんだ手作業が多い
例えば請求書。
デジタル化や電帳法の影響もあってか、PDFでもらうことも多くなっていますよね。
確かにPDFはデータですが、その後の処理は手作業が多くないでしょうか?
発注内容と合っているかチェックして、会社によってはそれを添付してワークフローを回したり(ここで内容や金額を手で転記したり)、その後に経理システムに手で入力したり…データなんだからデジタルで完結したいですよね!
で、そんなときはRPAの出番!
RPAはパソコン内のロボに仕事させるものですよね。
RPAは判断や意思決定は苦手ですが、定型作業は得意ですので、先の例は結構自動化できます。
でも、その中でも一番ネックになりそうなのが「PDFからデータを抽出する」ことですよね。
今回はそこに絞ってみてみます!
ついでに、RPA「Power Automate Desktop」(以後、PAD)を使ってみます。
※PADの詳細な情報はございません、ごめんなさい。
PDFからデータを抽出するパターンは3つ
今回試すものはコチラ!
テキスト情報があるPDFからデータを抽出
テキスト情報がないPDFからOCRでデータを抽出
手書きPDFからAIのチカラをかりてデータを抽出
シナリオ
今回の3パターンを試すにあたり、こんなことをしてみます。
顧客アンケートを実施
顧客からアンケート結果を受領。これがパターンにより異なる
パターン1:PDFで受領(テキスト情報あり)
パターン2:PDFで受領(テキスト情報なし)
パターン3:紙で受領(自分でスキャンしてPDF化)
アンケート結果をRPAで読み込み、Excelに書き出す
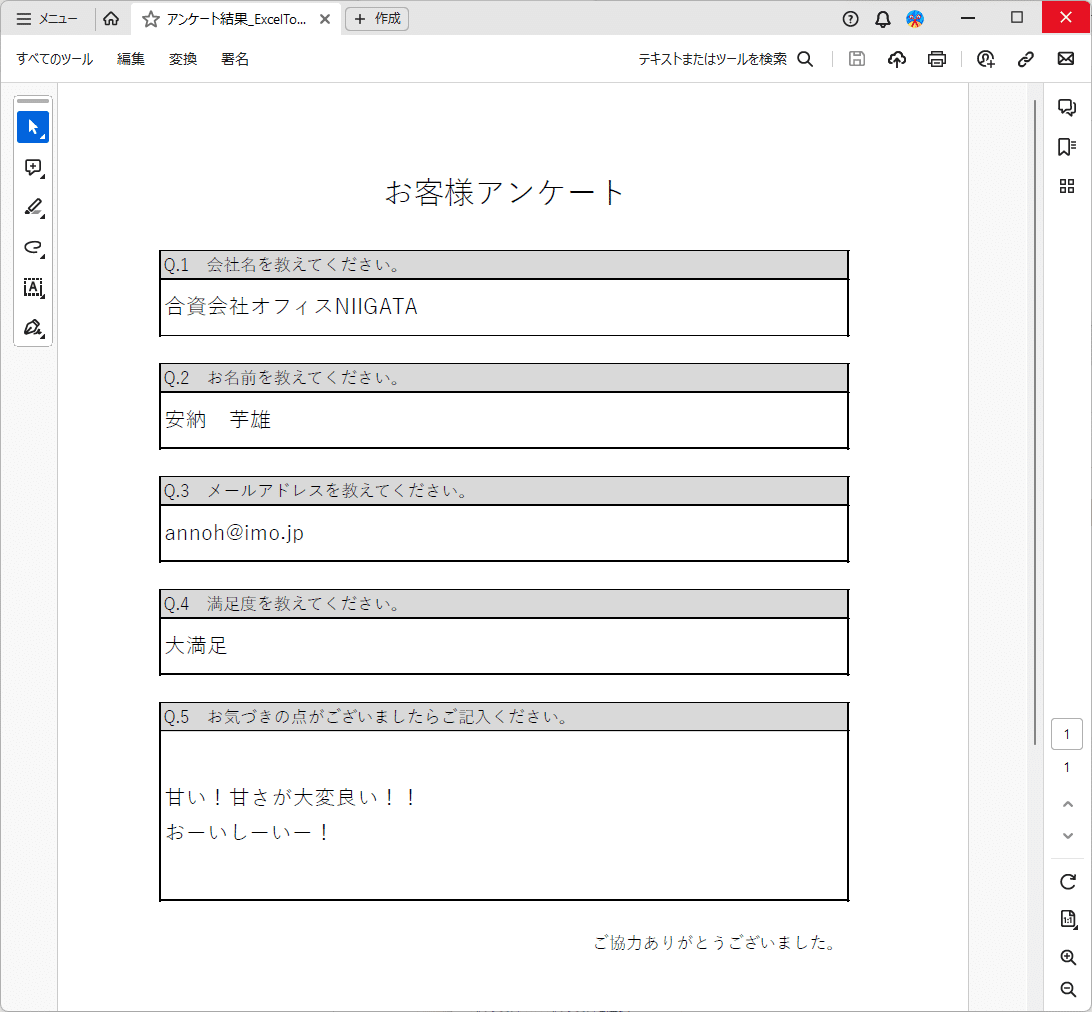
パターン1.テキスト情報があるPDFの場合
これが一番楽ちんなパターン。
PDFを読み込めばデータが取得できちゃう。
ちなみに、ExcelやWordからPDF出力すると標準でテキスト情報が含まれます。
PADの全体像はこちら。

PADはやりたいこと=「アクション」を選んでポチポチとマウスやキーボードで設定。
ざっくりこんな流れ。
PDFからテキストのかたまりを抽出して
テキストを行ごとに分割して
行から情報を取り出して
Excel開いて
空いている行(最終行)を探して
Excelにデータを書き込む
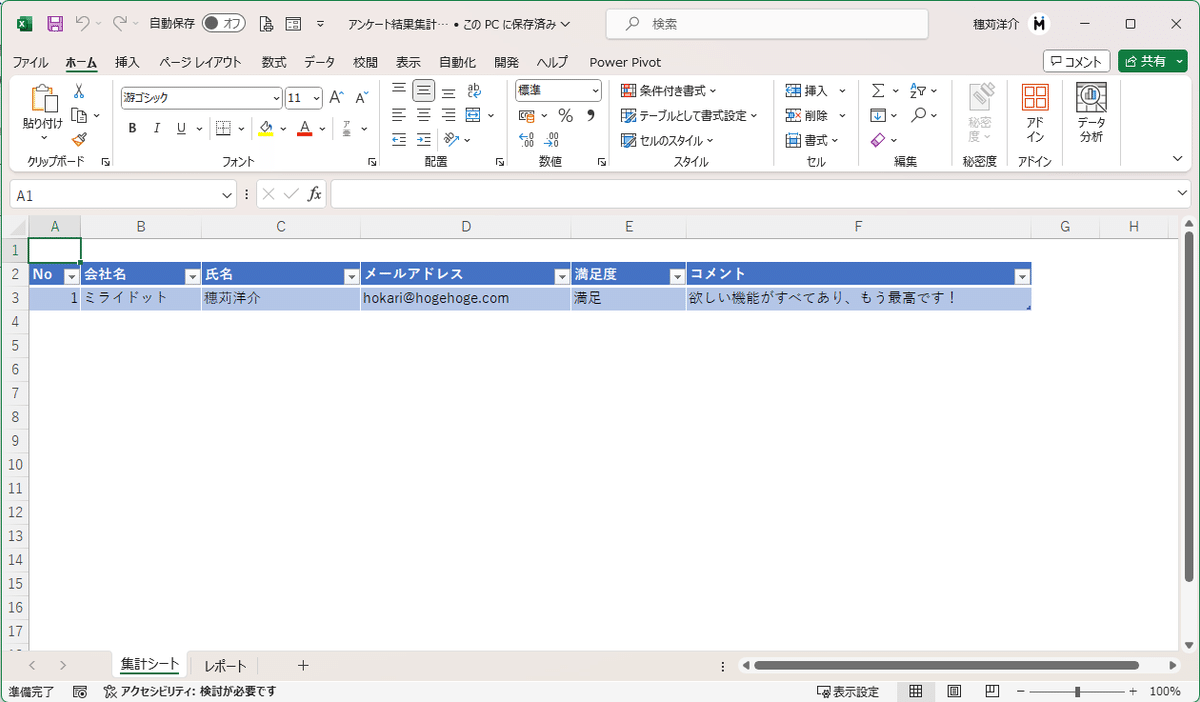
1つ目の「PDFからテキストを抽出」アクションをすると、次のようにデータが取得できます。

テキストが取得できれば勝ったも同然!
あとはこれをちょちょいのちょいっとやって、Excelに書き込むだけ。
実際に動いている動画を用意していませんが…こんな感じでちゃんと動きます。

パターン2.テキスト情報がないPDFの場合
次はテキスト情報を持たないPDFの場合。
たとえば、請求書を紙で受け取り、それを自前でスキャンした場合などですね。
PADの全体像はこちら。
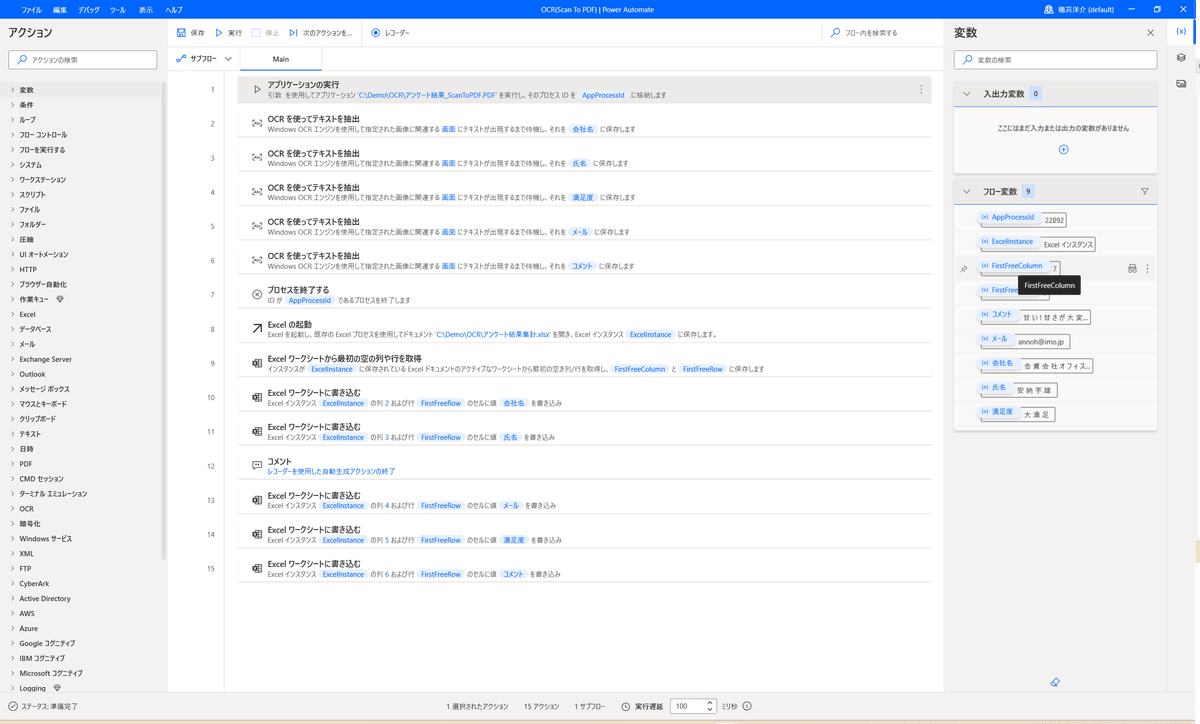
ざっくりこんな流れ。
パターン1と似てます。
PDFを開いて
位置を指定して画像からテキストを抽出して
Excel開いて
空いている行(最終行)を探して
Excelにデータを書き込む
パターン1と違うのが「OCRを使ってテキストを抽出」アクションです。
これは、目印となる場所を指定しておいて、そこから相対位置で文字を探し出してOCRする流れ。
ちなみにOCR=「Optical Character Recognition」、光学的文字認識といって、画像から文字をパターン認識している感じです。
設定値はこんな感じです。
個別に設定しようとすると大変なので、PADの「レコーダー」という機能を使ってやるとらくちんです。
ちなみに、「Windows OCR エンジン」を使うと、日本語を指定して簡単に読み込めます。
もうひとつの「Tesseract エンジン」でも日本語が可能ですが、設定が必要です。

これを実行すると、こんな感じで変数にセットされます。

もちろん、ちゃんとExcelに書き込める。

パターン3.手書きPDFの場合
使うぜ、Azure「Document Intelligence」!!
そして最後、手書き。
手書きはPADを使わずに、AI-OCRを使います。
MicrosoftのAzureで提供されるAI関連サービスの一つ、「Docunent Intelligence」。
一般的に「AI-OCR」と呼ばれるもの。
どんなことに使うのかというと、紙で受け取った請求書などを読み込んでAIに分析してもらい、そこに書かれているデータを抽出できます。
今回はこれを使っていきます。
Document Intelligenceの画面
こんな感じの画面です。
学習データを最低5件読み込ませまして、そこから文字を認識させて、その文字が何なのか「ラベル」(カラフルな色がついているもの)をつけることによって文字認識します。

これは学習時の画面ですが、右側にちゃんと日本語で認識された文字が表示されていますね。
よしよし。
今回はPAD使わない
すみません、使いません。
今回はMicrosoftの事例に則ってAzureの「Logic Apps」を使って構築していきます。
雑に言うと、Logic Appsで「PDF読み込んでAIで文字認識させてExcelに書き込む」を、PADを使わずに実装します。
Logic Appsの画面はこちら。

今回はクラウドで全完結。
流れは次の通り。
Logic AppsがOneDriveの特定フォルダを監視
特定フォルダにPDFを入れる
Logic AppsがPDFをDocument Intelligenceに渡す
Document Intelligenceが結果を返す
Logic AppsがExcelに書き込む
動かしてみる
まず、特定フォルダ(OneDrive)にファイルを入れる
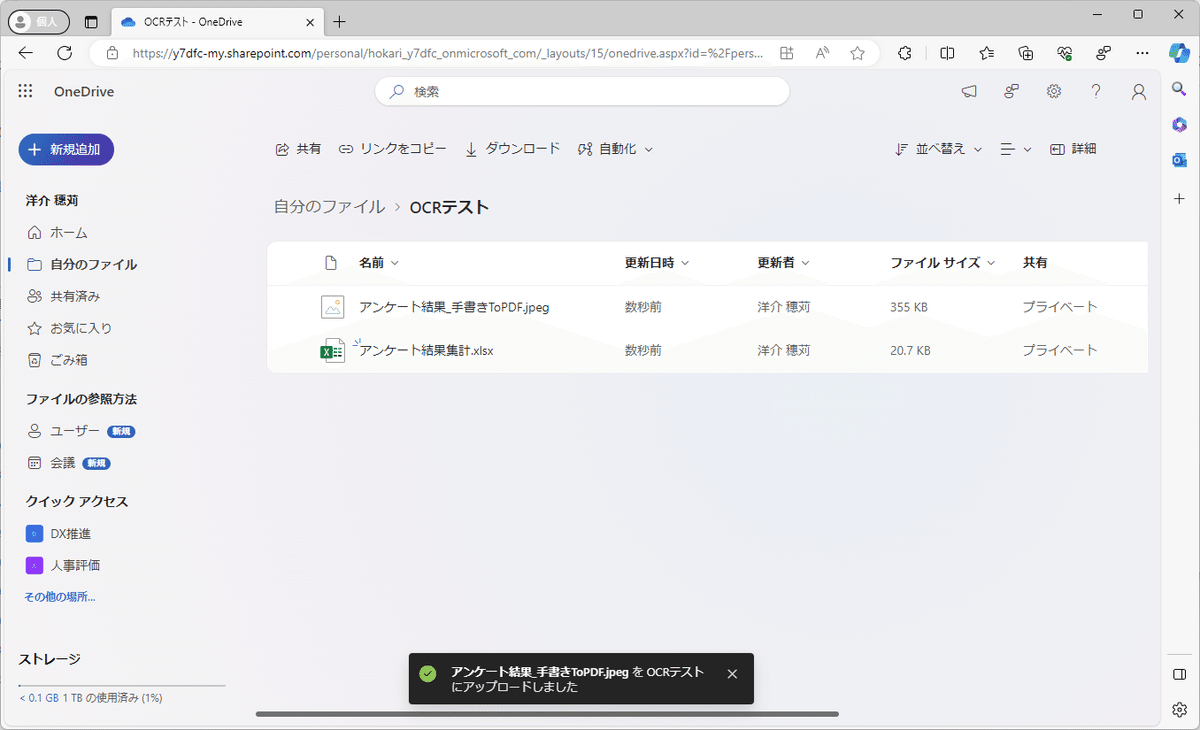
そして、ちょっと待つ。
1件当たり数秒程度?
そして、Excelを開くと…
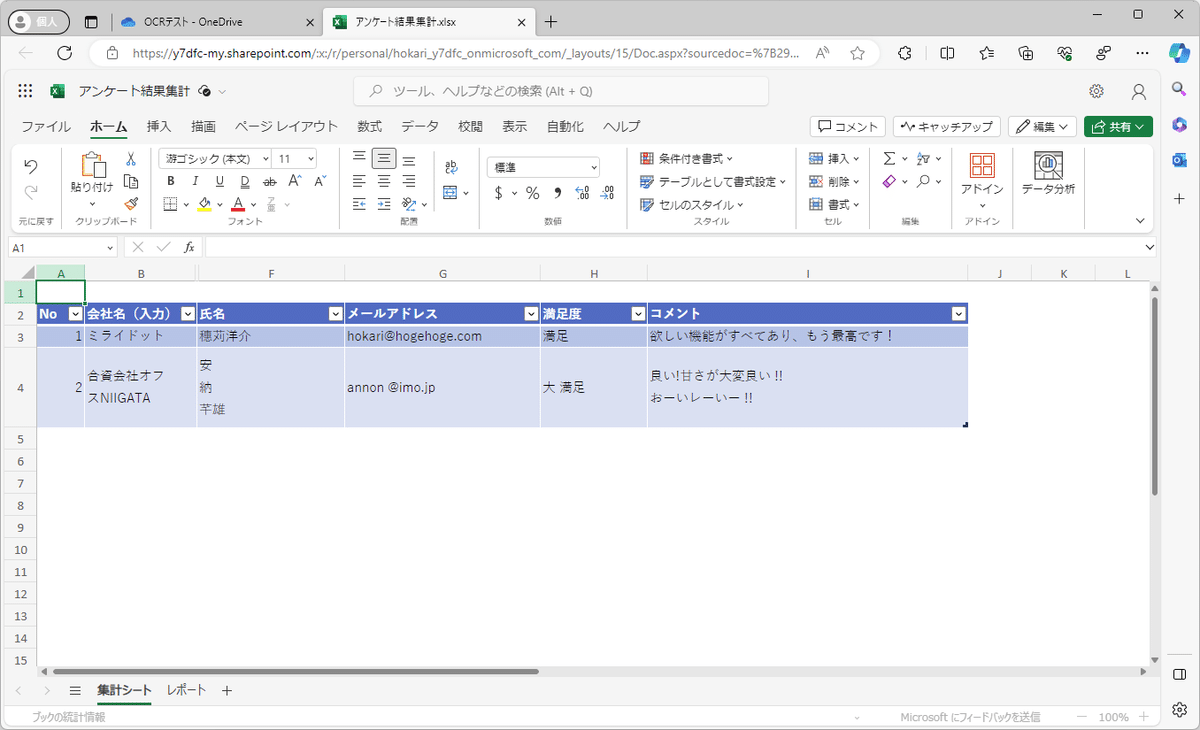
それっぽい!!
けど、所々残念!
途中で改行やスペースが入っていますね。
「し」が「レ」になっていたり…
まぁ、難しいことをしないでもこんな感じでとれるのって、すごくないです!?
結構大変だった…&まとめ
3パターン、いかがでしたでしょうか?
PADを使うパターンは比較的らくちんでしたが、AzureのAIを使うパターンはつまづくことが多くてちょっと大変でした…けど楽しかった!
PDFからデータを抽出するのは難易度が高い感じがしますが、実はAIを使わずとも結構なことができることがわかりました。
まずはパターン1or2から始めてみませんか!
あと、今回のパターン3は実際に運用するにはAzure AIを使うための費用が掛かりますので、それも踏まえてどのパターンを採用するか決めなければですね。
ちなみに、費用は紙1枚当たり数円程度でしょうか。(ストレージ利用料も掛かるし違ったらごめんなさい、実際に使う前に試算を!!)
今回はDocument IntelligenceとLogic Appsの詳細は端折りましたが、気が向いたらnoteに書いてみます。