
「Googleスプレッドシートから見た!」Excel 14の新関数 -10 TEXTBEFORE / TEXTAFTER

Excelに追加された 14の新関数を Googleスプレッドシートからの視点で検証する記事 10回目です。
14の新関数も 残りは 2つ。シリーズ最後は テキスト操作系の TEXTBEFORE、TEXTAFTER。 2つまとめて検証していきましょう。
TEXTSPLITは、Googleスプレッドシートの SPLIT との比較を中心に、従来とは違う進め方で検証しましたが、今回は このシリーズ従来のスタイル
関数の特徴
Excelでの メリット、デメリット、活用
Googleスプレッドシートの機能、関数との違い
Googleスプレッドシートでは無い機能を どう補うか
この流れで検証したいと思います。
シリーズ前回の記事
EXCEL 14の新関数 TEXTBEFORE / TEXTAFTER
EXCEL14の新関数のうち、この2つはテキスト操作系となります。さらに 前回紹介している TEXTSPLIT の派生系ともいえます。
簡単に言ってしまうと、対象の文字列から 指定した
区切り文字の前を取り出すのが TEXTBEFORE
区切り文字の後を取り出すのが TEXTAFTER
という違いになります。
TEXTBEFORE / TEXTAFTER の特徴
関数の型、引数は どちらも同じで、TEXTSPLITとも重複する部分があります。
=TEXTBEFORE(text,delimiter,[instance_num], [match_mode], [match_end], [if_not_found])
=TEXTAFTER(text,delimiter,[instance_num], [match_mode], [match_end], [if_not_found])
引数は どちらも共通で 6個。 最初の3つは必須
text・・・ 対象のテキスト。通常はセル指定。
delimiter・・・ 区切り文字
instance_num・・・ 何番目の区切りかの指定
(省略は1、マイナス指定で 後ろからカウント)
match_mode ・・・ 大文字と小文字を区別するか?
( 0で区別する。 1で区別しない設定 省略時は 0)
match_end・・・ テキストの終端を区切りとしてカウントするか?
(0でカウントしない。1でカウントする設定 省略時は 0)
if_not_found・・・ 見つからない時の値。省略時は #N/A
6つも 引数がありますね。まずは Excel上での基本の動きを見ていきましょう。
基本の使い方、区切り文字は配列指定可能

まずは基本の使い方。 - を区切り文字として指定。
対象テキスト
abc-de-fg-hij-klm-nop
=TEXTBEFORE(A3,"-")
一つ目の - の前の部分 abc-de-fg-hij-klm-nop → abc を取り出す
=TEXTAFTER(A3,"-")
一つ目の - の後の部分 abc-de-fg-hij-klm-nop → de-fg-hij-klm-nop を取り出す
あくまでも 指定した 区切り文字の前(後ろ) 全てを取り出す関数であるという点に注意しましょう。区切り文字と区切り文字の間を抽出するわけではないです。
区切り文字の指定方法に関してはTEXTSPLITと一緒で、 配列を使って 複数指定が可能です。
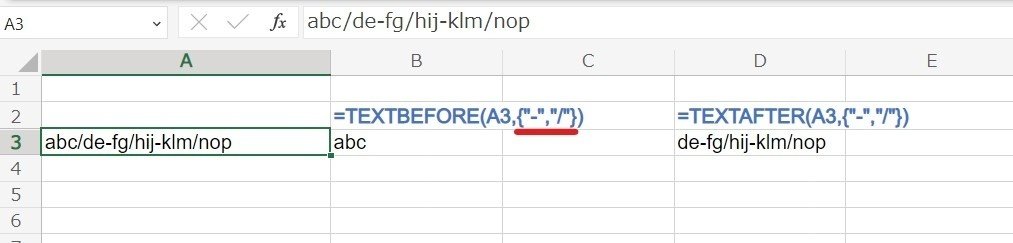
{"-","/"} と区切り文字を複数指定した場合、 文頭から見ていって - か / のどちらか 先に見つかった方で区切った 前(後ろ) を取得します。
区切り文字は、単文字(記号など)だけでなく 文字列(単語など)でも可能、また複数指定の際の配列はセル範囲の参照とすることも可能です。
区切り文字の挙動に関しては、TEXTSPLITと同じという認識でOK。
instance_num 〇番目の区切り文字の 前(後ろ)を取り出す
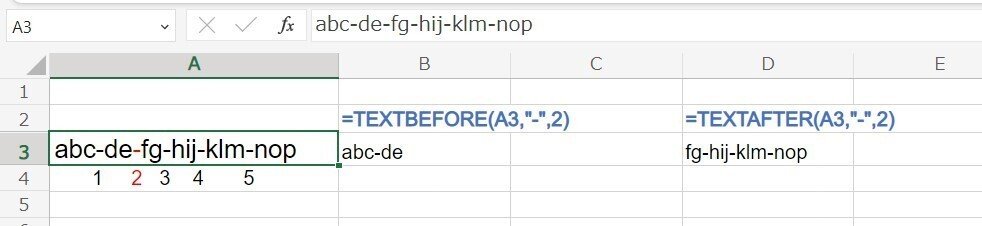
第3引数の instance_num を指定することで、〇番目の区切り文字の前(後ろ)を取り出す、といったことが出来ます。
対象テキスト
abc-de-fg-hij-klm-nop
=TEXTBEFORE(A3,"-",2)
2番目の - の前の部分 abc-de-fg-hij-klm-nop → abc-de
※ de (区切った配列の2番目)を取り出すわけではありません。
=TEXTAFTER(A3,"-",2)
2番目の - の後の部分 abc-de-fg-hij-klm-nop → fg-hij-klm-nop
※同じく fg を取り出すわけではありません。
abc-de-fg-hij-klm-nop の場合 区切り文字 - は 5個 なので、6以上を指定すると #N/A エラーとなります。

instance_num は、これまで登場した 配列操作系新関数の TAKE / DROP や CHOOSEROWS / CHOOSECOLS と同じように、マイナス指定により後ろ(文末尾)から のカウント が可能です。
この〇番目の 指定も 実は配列による複数指定(スピル)が可能なのですが、それについては後ほど触れます。
match_mode で大文字、小文字を区別。(区別しない設定も可)
match_mode に関しては、TEXTSPLITの 第5引数と同じです。区切り文字がアルファベットを含む際に 大文字・小文字を区別したくない場合は 1を設定します。省略時(デフォルト)は0 で区別する設定。
区切り文字の大文字・小文字を 意識する必要があるケースはほぼないので、あまり出番はなさそうです。
この引数もTEXTSPLITにありましたね。でも、ちょっとだけTEXTSPLITと仕様が違います。

TEXTSPLITの場合は、 match_mode で1(大文字・小文字を区別しない)と設定すると、なぜか区切られた文字のアルファベットが 全て 小文字に変換されてしまうという、謎の仕様(バグ?)がありました。
それが TEXTBEFORE / TEXTAFTER では発生しなくなっています。もちろんこっちの方がいいので、TEXTSPLITの方を修正して欲しいもんです。
match_end テキストの最後を区切りとしてカウントするか設定できる 謎の引数
この第5引数の match_end は、いったいどこで使うのか?と話題になった(話題にもならなかった) 謎の引数です。
これは 「テキストの終端を区切りとしてカウントするか?」という設定で、1を指定することで「終端を区切りとしてカウントする」になります。

上の画像のようなケースだと match_end 1指定をすることで、区切り文字が 5個の abc-de-fg-hij-klm-nop の 文末を 6番目の区切位置 という扱いにすることができます。
instance_num マイナス指定時だと逆に、文頭 が 後ろから数えて 6番目 (-6)の区切り位置という扱いなります。
上の画像でも
=TEXTBEFORE(B3,"-",6,,1)
6番目の区切り位置(文末)より前の部分
=TEXTAFTER(B10,"-",-6,,1)
マイナス指定なので 後ろから6個目の区切り位置(文頭)より後ろの部分
となるので、元のテキスト(対象のB3 = B10セルそのまま)
abc-de-fg-hij-klm-nop
が返ってるのがわかりますね。
逆に
=TEXTAFTER(B3,"-",6,,1)
6番目の区切り位置(文末)より後ろの部分
=TEXTBEFORE(B10,"-",-6,,1)
マイナス指定なので 後ろから6個目の区切り位置(文頭)より前の部分
これらは 文末より後ろ、文頭より前は存在しないので 空 が返ります。(エラーにはなりません)
これだけ見ると、「で?」って感じですよねw
オフィス田中さんも、「使いどころがイメージできない」って書かれてます。
が、実はこれ後述する応用例で必要になります。
ただ、上の 大文字・小文字判別と同じく、ほぼ使わないもの という認識でOKです。
if_not_found 見つからない時の値
英語訳そのまんまですねw
XLOOKUPでもおなじみの 見つからなかった時に返す値を 第6引数にもたせることができます。
まさに IFNA関数、IFERROR関数いらず。(#N/A エラー以外のエラーを拾う為の IFERROR関数は必要になることがあります)
通常は "" を指定して 空文字を返すことが多いです。

見つからなかった時 というのは、指定した 区切り文字 が対象のテキストに含まれていないケースだけでなく、 instance_num で指定した 〇番目が 存在しない時も該当します。
つまり 上の画像のように
■A3セル
abc-de-fg-hij-klm-nop ・・・ 区切り文字が 5個しかない
↓
=TEXTBEFORE(A3,"-",10,,,"")
存在しない 10番目の区切りを指定しているので #N/A エラーだが、
第6引数に "" を入れてるので 空白となる
こんな使い方ができます。
ここまでが各引数の意味と特徴になります。
Excelでの メリット、デメリット、活用
メリットは 対象のテキストから 指定した区切り文字の 前、もしくは後ろを簡単に取り出せるという点ですね。
特に 〇番目といった 指定ができるのが便利です。(マイナス指定による後ろからのカウントも便利)
今まで 同様のことをやろうとした場合、
SUBSTITUTE で 〇番目の 区切り文字を 空白100個(REPTで生成)に置換し、MIDでバッファ見て取り出して TRIMで先頭の不要な 空白除去
なんて ことをやっていたのが 関数一発でいけちゃうわけですから、超便利になりました。

もちろん Power Query(パワク)でいいじゃん。
って意見もあるでしょうが、もしこの分割(部分抽出)作業だけやりたい場合、Power Queryエディターに取り込みってちょっと面倒ですよね。関数でサクッと出来たらという需要はあるかと思います。
そして、もう一つのメリットが TEXTSPLITでは対応できない、複数セル(範囲)を対象とした一括処理。スピル対応です。
TEXTBEFORE / TEXTAFTERは 複数セルを一括処理できる

=TEXTBEFORE(A2:A10,"-",2)
範囲 A2:A10の各セルの 2番目の - より前を取り出す一括処理
=TEXTAFTER(A2:A10,"-",-1)
範囲 A2:A10の各セルの 最後の - より後ろを取り出す一括処理
こんな一括処理が出来るわけです。
ちなみに TEXTSPLITでも 区切った最後の要素を
=CHOOSECOLS(TEXTSPLIT(A2,"-"),-1)
このように取得できましたが、こちらは 1つのセルにしか使えません。TEXTSPLITは、A2:A10のような 範囲を対象にすると正しく 機能しないのです。
TEXTBEFORE / TEXTAFTERは 縦横スピルできる
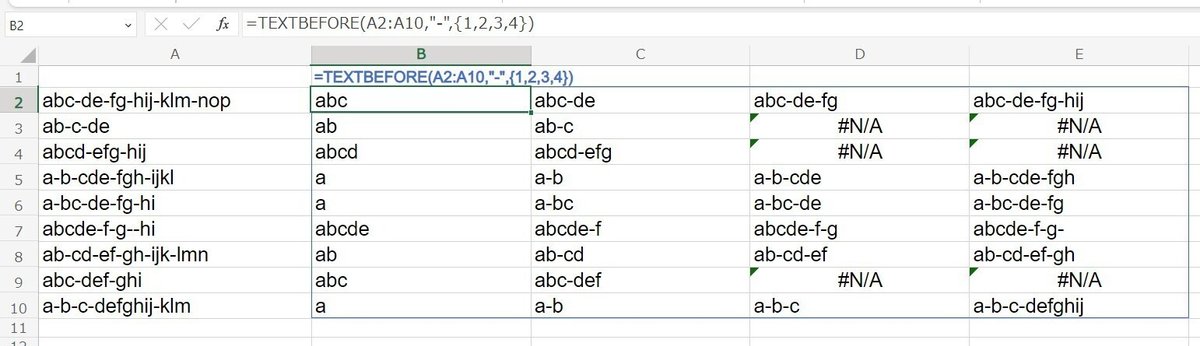
instance_num の説明で少し触れましたが、第3引数の 〇番目という 数値指定は 配列による 複数指定ができます。
これと先ほどの 第1引数の配列対応を組み合わせることで、 縦横スピルができてますね。
=TEXTBEFORE(A2:A10,"-",{1,2,3,4})
としてますが、もちろん {1,2,3,4} は SEQUENCE(1,4) としてしまっても良いです。
※ Excelの場合は SEQUENCE(,4) でもOK。
横に展開させるので、SEQUENCE(4)ではダメです。
ちなみに SEQUENCE(4)だと 縦に展開されるので、横1行のセル範囲に対しての 縦方向一括処理には使えます。
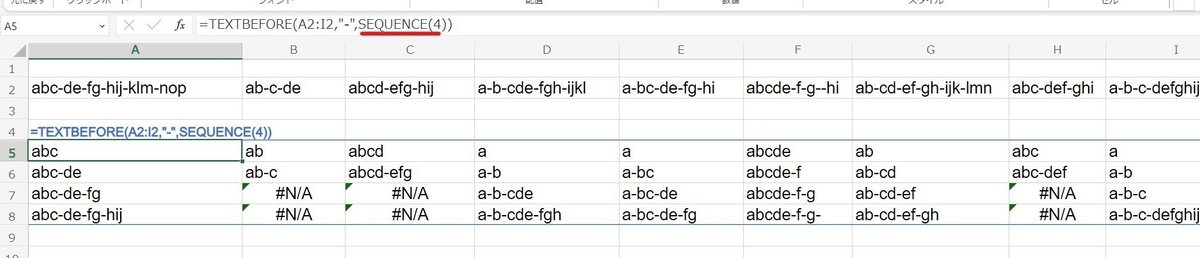
mirの推し関 SEQUENCE がまたまた活躍ですね。
エラー部分は 第6引数を設定すれば解消できますが、3行目の

ab-c-de → ab ab-c #N/A #N/A
の部分、最後の de が拾えてないのがちょっと気になりますね。
区切り文字の前ではないので仕方ないんですが、これを解消するのが 「なんの役に立つのか?」と言われていた引数 match_end です。

=TEXTBEFORE(A2:A10,"-",SEQUENCE(,4),,1,"")
このようにすることで、4番目の区切り文字(文末含む)まで 全て抽出できて、エラーも解消されます。
モブキャラ扱いだったやつが 団体戦で活躍するパターンですね。ヒョロくんですね!
さて、これを応用することで なんかアレできそうじゃないですか?
そう、複数セルを対象とした TEXTSPLITの代替式が出来そうな気がします!
Q. TEXTBEFORE / TEXTAFTERを組み合わせて 複数セルの一括横分割をしたい

というわけで お題です。
上の画像のように A2:A10 セルの文字列を B2に一つの式をいれることで、各セルを - で区切って横方向に展開したい。
■前提条件
TEXTSPLITを使わず、TEXTBEFORE / TEXTAFTER コンビ(組み合わせ)で処理する
どうでしょう、かなり条件を絞り込んだお題で TEXTBEFORE、TEXTAFTER とスピルを理解すれば 作れますが、できそうでしょうか?
まずは考えてみてください。
↓↓↓
回答は以下
↓↓↓
A. TEXTBEFORE / TEXTAFTERを組み合わせて 複数セルの一括横分割
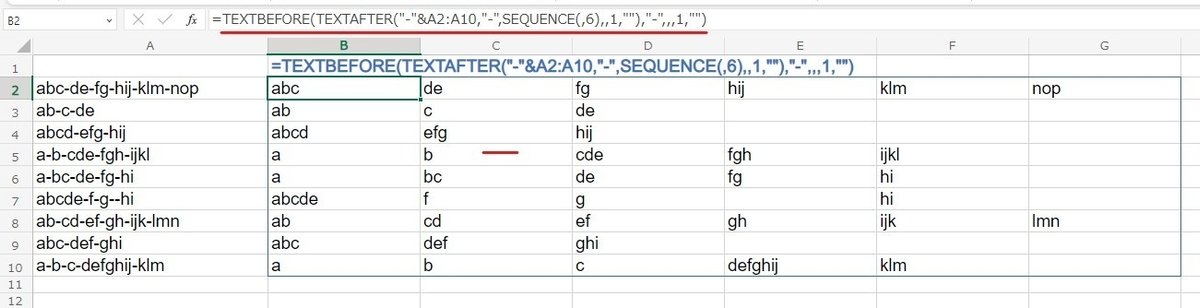
まずは わかりやすい式で 回答します。
=TEXTBEFORE(TEXTAFTER("-"&A2:A10,"-",SEQUENCE(,6),,1,""),"-",,,1,"")
↑ この式で 画像のように 縦横にスピル 一括 分割が出来ます。
処理の流れとしては、まずは 先に TEXTAFTER と SEQUENCEで 区切り文字 "-" の1番目から 順に 区切り文字の後ろ を 横方向にスピらせて出力したいんですが
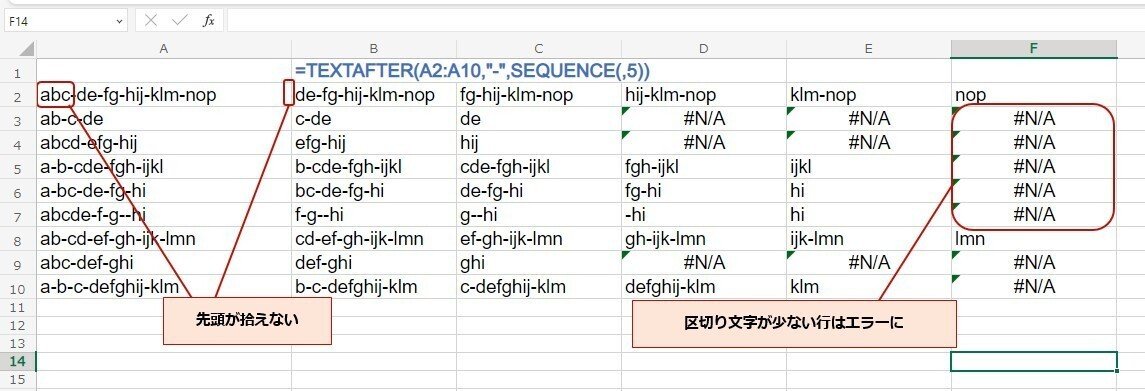
単純に このようにすると 文字列の先頭部分が取れず、さらに 区切り文字が少ない行は 右の方がエラーとなってしまいます。
これを TEXTAFTER で 先頭部分を取得し、後ろのエラーを解消する為に

このように 頭に 区切り文字を結合して、SEQUENCEの数を +1(追加した頭の区切り文字分) 、見つからない時の値 を"" で空文字設定 しています。
これで文頭から 順に出力できました。あとはこの出力結果から 一つ目の -(区切り文字) で区切った前の部分を取得すればよいわけです。
TEXTBEFORE の出番ですね。

こちらも ただ、TEXTBEFORE を使っただけでは 文字列の一番最後の部分が撮れませんし、エラーが残ってしまいます。
ここで match_end を1指定 の出番がやってきました!
文字列の最後を区切り文字とみなすことで、TEXTBEFOREで 最後の分割部分を取得することが出来るのです。
あとは 見つからない時の値に空文字を設定してあげれば完成です。
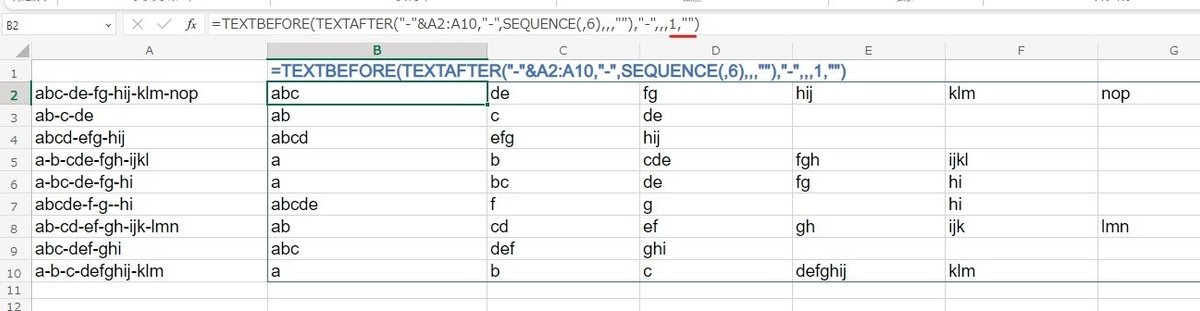
TEXTBEFORE / TEXTAFTERを使った 一つの式で、複数セルの一括分割ができました!
注意点:instance_num の省略と1は少し動きが違う

一か所だけ気を付けるポイントがあって、上のように TEXTBEFOREの 第3引数 で 1を指定しちゃうと 空白にしたい箇所が エラーとなります。
instance_num で1を指定してはダメってことです。

このように TEXTが空白の時、instance_numを指定してしまうと、最後の見つからない時の値を ""で設定しても エラー が残ってしまいます。
省略と1指定は 同じようで、ちょっと違うみたいです。注意しましょう。
複数セル一括分割式を 汎用性のある式にできるのか?
=TEXTBEFORE(TEXTAFTER("-"&A2:A10,"-",SEQUENCE(,6),,1,""),"-",,,1,"")
この式で 複数セルの一括分割できると書きましたが、
SEQUENCE(,6) の 6 はどっから来たんだ?
え?目視で 一番多い区切り文字を数えるの? とお叱りを受けそうですね。
本題である TEXTBEFORE / TEXTAFTER での 複数セル一括分割を わかりやすくする為に、先にシンプルな例を回答しましたが、もちろんこの部分を汎用性のある形にする必要があります。
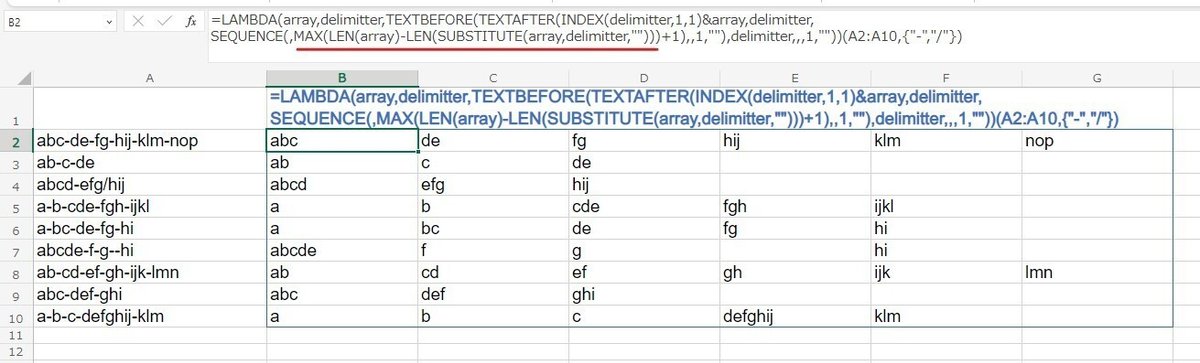
=LAMBDA(array,delimitter,
TEXTBEFORE(TEXTAFTER(INDEX(delimitter,1,1)&array,delimitter,
SEQUENCE(,MAX(LEN(array)-LEN(SUBSTITUTE(array,delimitter,"")))+1),
,1,""),delimitter,,,1,""))(A2:A10,{"-","/"})
なんか一気にゴテゴテした クールじゃない式になりましたw
A2:A10 セルの 区切り文字の最大値を求めるのに、
MAX(LEN(A2:A10)-LEN(SUBSTITUTE(A2:A10,"-","")))
結局このような古典的な手法を使っています。
一応 LAMBDAで 引数である 対象範囲 array と 区切り文字 delimitter を外だししたんで、このまま名前付き関数化も可能です。
でも、これなら 大量データじゃなきゃ TEXTJOIN + TEXTSPLIT 使った方がよさそうですね。
その他の応用・活用例
例によって「いきなり答える備忘録」さんが、色々検証されています。
TEXTBEFORE 活用例
TEXTAFTER 活用例
文字列末尾の空白だけ除去とか、クロス結合、逆にクロス表 → リスト表などで活用されてますね。
カッコ内の文字抽出というお題は、「Excelの神髄」さんも 取り上げています。
つづきは次週
さて、TEXTBEFORE / TEXTAFTER も強力な 文字列操作系関数だけあって、特徴の紹介と メリット・デメリット・活用例で だいぶ長くなってしまったので、続きは次週とします。
ここまで書いて気づきましたが
あれ?今回 Excelばっかいじってて、Googleスプレッドシート 1回も登場してない!?
次回 TEXTBEFORE / TEXTAFTER の後半で、Googleスプレッドシート視点の検証をしていきます。次こそExcel14の新関数のラスト!
この記事が気に入ったらサポートをしてみませんか?