
【GAS】Googleドキュメントから GASを使ってハイライトした単語をGoogleスプレッドシートへ色別に書き出す

今回は GAS(GoogleAppsScript)ネタです。GASはGoogleスプレッドシートの情報は多いけど、GoogleドキュメントやGoogleスライド のGASの情報は圧倒的に少ないんですよね。
というわけで、今回はGoogleドキュメントのGASにスポットを当ててみました。(といっても内容としては薄口なんで、トップ画像も薄い感じにしてますw)
今回のゴール(最終的に「やりたいこと」)は
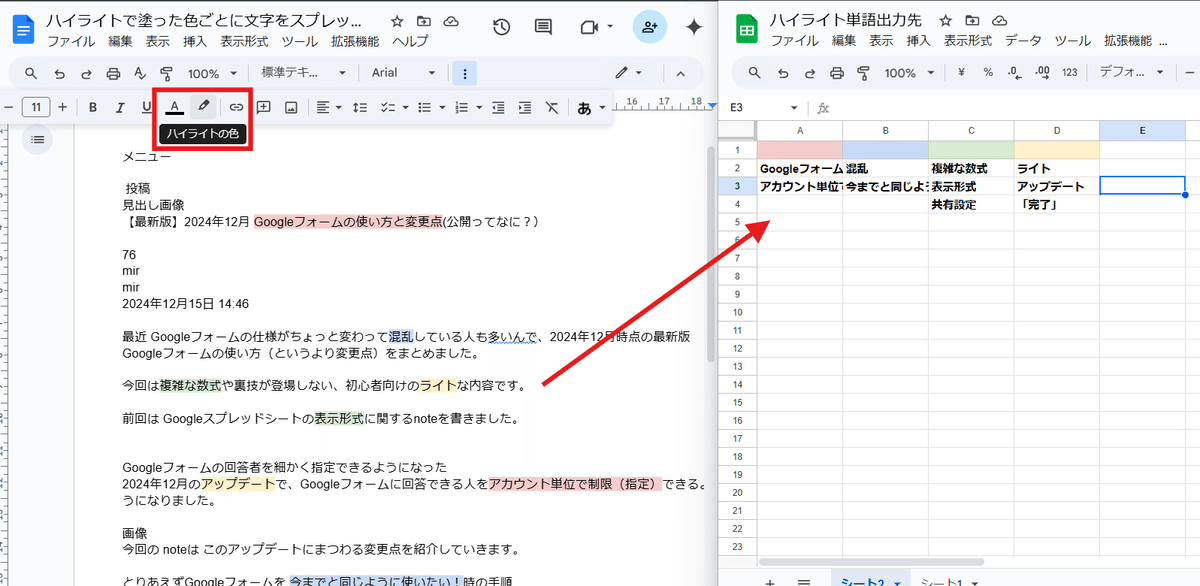
こんな感じで Googleドキュメントのハイライト(蛍光ペンで線を引くような機能)で 色をつけた単語を 色別にGoogleスプレッドシートに出力するというものです。
これは某QAサイトに上がってた質問を元ネタとして作成してみました。
処理としては特別難しいわけではないので、GASのスキルアップをしたい人にちょうどいいお題かもしれません。
先週のnoteはGoogleスプレッドシートのピボットテーブルシリーズ第2回ってことで、計算フィールドを使った累計処理や GETPIVOTDATA関数について書きました。
Googleドキュメントから ハイライトした単語の抽出を Geminiに依頼してみる
今回のお題、まずは自分でコード書かずに処理できないかAIを活用してみましょう。
GoogleドキュメントのGeminiサイドバー(Workspace Labs)を使ってみる
まずは Workspace Labsで mirアカウントのドキュメントでもGeminiが使えるようになったんで、 Geminiのサイドバーに依頼してみました。
サクッと処理できるなら、これが一番楽そうです。

「ハイライトで色を塗った箇所の文字を抜き出して」
「ハイライトで色を塗った文字だけを抜き出して」
「ハイライト箇所の文字だけを全て抜き出して」
「pick up highlight text」
幾つかプロンプトを入れてみましたが、思うような回答が得られません。
うーん条件が文字ではなく、文字の装飾(ハイライト)だと難しいんでしょうか?
いや、でも「太字の文字を抜き出して」は処理できるんですよね。。

ハイライトだと抜き出せない・・・なんでなんだ~。
GeminiでGoogleドキュメントを指定して抽出を依頼してみる
じゃあサイドバーじゃない方のGemini 2.0Flashだったらどうか?
こちらも Googleドキュメントのファイルを指定して
このドキュメントからハイライトした文字だけを抽出してください
と質問をなげかけてみます。

「少々お待ちください」から、しばらく待っても音沙汰無し。

督促したら「完了しました。」と、しかも「スプレッドシートに色ごとに整理してあります。」って、え?そこまでやってくれるの??すごいね。
この「ハイライトされた文字」っていうリンクをクリックすれば良いのか・・・
さてさて、どんな単語が抽出されたかな~

ビズリーチ!!!
だまされました。全然抽出できてないし、スプレッドシートも生成されてません。

そもそも リンクURLはなぜかスプレッドシートのURLをGoogle検索するもので、一回検索結果の画面にとばされます。
で、検索しているスプレッドシートのURLを直接開こうとしたらコレです。
わけがわかりません。ハルシネってますね~。
Geminiに ハイライトした単語を抽出するGASのコードを聞いてみる
仕方ないのでGASを使う前提で、今度はGeminiにGASのコードを聞いてみましょう。

それっぽいコードが返ってきました。
function extractHighlightedText() {
var doc = DocumentApp.getActiveDocument();
var body = doc.getBody();
var numChildren = body.getNumChildren();
var highlightedText = [];
for (var i = 0; i < numChildren; i++) {
var child = body.getChild(i);
if (child.getType() == DocumentApp.ElementType.PARAGRAPH) {
var paragraph = child.asParagraph();
var numParagraphChildren = paragraph.getNumChildren();
for (var j = 0; j < numParagraphChildren; j++) {
var paragraphChild = paragraph.getChild(j);
if (paragraphChild.getType() == DocumentApp.ElementType.TEXT) {
var text = paragraphChild.asText();
if (text.getBackgroundColor()) {
highlightedText.push(text.getText());
}
}
}
}
}
Logger.log(highlightedText); // 抽出されたテキストをログに出力
return highlightedText; // 抽出されたテキストの配列を返す
}しかし、コレを実行してみても

空っぽです・・・。
これの原因は、forループ内の ifの条件としている text.getBackgroundColor() を if の手前で ログに出してみれば、わかりますが

このように全て null、つまり if 内の highlightedText.push(text.getText()) が1回も処理されずに終わっている為です。
ハイライトしているの箇所があるのに なぜ null が返るのか?
これは text.getBackgroundColor() は、textが全て同一色のハイライトでないと nullとなる仕様だからです。
Geminiの返してきたコードは、ドキュメントの body(本文)から Paragraph(段落)を取り出し、その中の子要素(テキストのみなので今回はそのまま段落の文章)を textとしています。
つまり、わかりやすいサンプルで同じコードを実行すると

段落全体が単一色のハイライトでないものは全て null となっているのがわかりますね。
先ほどテストしたドキュメントは、そのような個所は一つも無いため if内の 配列にpushする処理は一度も実行されずに終わったわけです。
そりゃ結果が空っぽになるわけです。
でも、こんなの初心者だとわからないですよね。。困ったもんです。
今回は割愛しますが、ChatGPT、Claude にもコードを聞いてみましたが、どちらも一発では希望するコードを返してはくれませんでした。
やはり スプレッドシートのGASに比べると、GoogleドキュメントのGASはネット上の情報量に比例してAIにも知見が少ないのかもしれません。(プロンプト次第なのかも)
Googleドキュメントからハイライトした単語の抽出をGASで書いてみる
というわけで、AIと何度もやり取りを重ねてもいいんですが、GASに興味がある人、スキルアップしたい人は 自力でコード作成に挑戦してみましょう。
難しすぎると感じる場合はいきなりゴールを目指すのではなく、自分の出来ること(出来そうなこと)と「やりたいこと」を比較し、まずは自分が出来そうなレベルにゴールを落としこむと良いです。
「刻むんだ」(課題・一段を細分化して自分がギリギリ登れるくらいの目標をセットして超えていく)と ワールドトリガーの最新刊(28巻)でヒュースも言ってましたw
今回の場合であれば
色ごとに分けて(難しそう)
スプレッドシートに出力(とりあえず後から考えればよい)
これをまずは取り除いて、
Googleドキュメントのハイライトした文字をログに出力する
を実現するコードに挑戦してみましょう。(もちろん、すぐにゴールのコードがイメージできるレベルの人は不要です)
このように 処理を分解してシンプルにすることで、検索もヒットしやすくなりますし、AIに聞いた時も正しい回答を得られやすくなります。
とりあえず今回は Googleドキュメントのスクリプトエディタに記述するGASとして作成していきます。
Step1. Googleドキュメントから本文のテキストを取得する

とりあえず先ほどテストで作った 4段落程度のシンプルなドキュメントでテストしながらコードを組んでいきましょう。
ちなみにGoogleドキュメントにおける「段落」は Enterで 区切った塊を指します。
メニューの 表示 > 印刷されない文字を表示 にチェックをつけると わかりやすいんですが

このように Enterしているものは実は 「改段落」で、Shift + Enter を使った「改行」とは別モノです。
Wordでもそうなんですが、コレ意外と知らない人も多いんですよね。
で、今までは GASの DocumentApp は
ドキュメント(ファイル) > ボディ(本文) と取得して、ここから段落を取り出したり表をとりだしたり、リッチテキストや文字列としてのテキストを取り出すってことで、

こんな感じで書けば良かったんですが、現在は ドキュメントの下にタブという概念が追加されています。
タブに触れない上のようなコードでも、自動的にアクティブなタブを対象とするので問題はないんですが、なるべくタブを取得する書き方に慣れておいた方がよいです。
というわけで、 const body = doc.getBody() この部分を
const body = doc.getActiveTab().asDocumentTab().getBody();
このようにします。
function step01() {
const doc = DocumentApp.getActiveDocument();
const body = doc.getActiveTab().asDocumentTab().getBody();
const text = body.editAsText();
const plainText = text.getText();
console.log(text); //これはそのままログに出力しても意味がない
console.log(plainText);
}上のコードですが
アクティブなドキュメントを取得 → doc とする
doc からアクティブなタブを取得してそれをドキュメントタブとして取得しなおして本文を取得する → body とする
body からリッチテキスト(のようなもの)を取得する → textとする
text からプレーンテキスト(文字列)を取得する → planTextとする
こんな処理をしています。

で、editAsText で取得した text の方は 情報の塊のようなものなんで、そのままログに出力しても意味がありません。取得したい文字は、textをさらに getTextした plainTextの方になります。
とりあえず ドキュメントのエディタに記述したコンテナバインドスクリプトで、開いているドキュメントの開いているタブの本文を取得できました。
Step2. getBackgroundColor(offset)で ハイライトを判別する
ハイライトされているかどうか?といったリッチテキストに関する情報は、文字列のplainTextではなく、text から判別する必要があるのですが、
GASを使って「文章全体の中からハイライトされている箇所を見つける」といった「検索」的な処理は出来ません。
実は処理としては1文字ずつ取り出して確認して仕分けしていくという作業になります。
人間がやったら気の遠くなるような作業ですが、そこはコンピューターなんで数千、数万文字でも割と高速で処理されます。
この1文字ずつ取り出して ハイライトを確認するメソッドが
です。
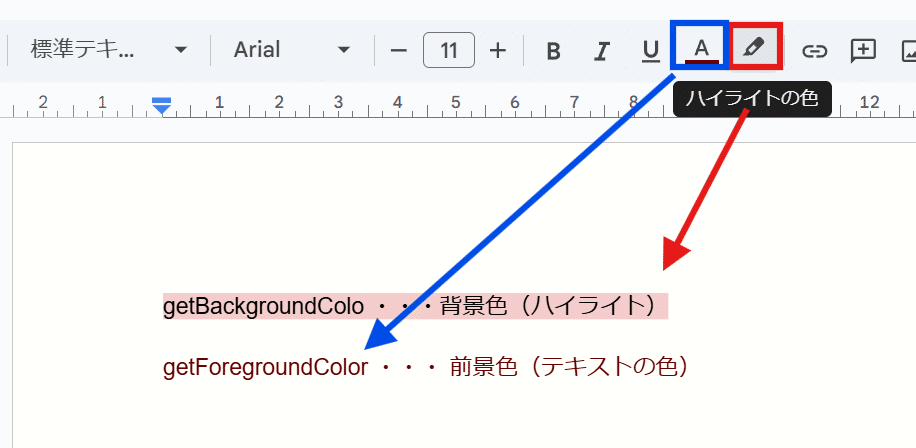
リファレンスには 背景色を取得する getBackgroundColor 以外に 前景色を取得する getForegroundColor というメソッドもあってわかりづらいんですが、

背景色の getBackgroundColorがハイライトの色で、getForegroundColorで取得できるのは テキストの色(フォント色)です。
前景色って言葉があんま馴染みないですよね・・・
で、getBackgroundColor(offset) このカッコ内の offset に数値を設定することで 〇文字目のハイライト色を 色コードの文字列として取得できるわけです。
1文字ずつということは ループ処理 forの出番です!
文字数を取得するのは プロパティの .length ですが、これは text の方には使えないので String(文字列)になっている plainTextに対して使います。
文字列の番号も 配列と同じで 0からとなります。
0スタートで i番目の文字は plainText[i] という書き方で取り出すことができます。

というわけで 1文字ずつハイライト色をログに出力するコードは
function step02() {
const doc = DocumentApp.getActiveDocument();
const body = doc.getActiveTab().asDocumentTab().getBody();
const text = body.editAsText();
const plainText = text.getText();
for(i=0;i<plainText.length;i++){
console.log(text.getBackgroundColor(i));
}
}こんな感じになります。

実行後のログを確認すると
ハイライトが無い1文字は null を返す
ハイライトがある1文字は 色コードを返す
改行も1文字に含まれる
ハイライトが行末まである場合は、改行もハイライトありと判断
となってるのがわかりますね。
ハイライト無しの null は if で評価した際 false扱いになるので、これを使って true(ハイライトあり)の時だけ plainText[i]を返すコードに改良してみましょう。
function step02() {
const doc = DocumentApp.getActiveDocument();
const body = doc.getActiveTab().asDocumentTab().getBody();
const text = body.editAsText();
const plainText = text.getText();
for(i=0;i<plainText.length;i++){
if(text.getBackgroundColor(i)){
console.log(plainText[i]);
}
}
}
ハイライト部分の文字だけが取得できてますね。
ただ、これだと1文字ずつログに出力しているだけなので、単語毎にまとめる必要があります。
Step3. 文字を繋げる、そしてsplitする
文字を繋げる方法には forの前に 結果を入れる入れ物(result)を用意して、文字列を後ろに足していくという手法を使いましょう。
ついでに後ろに足す文字(v)も forの前で宣言して用意。
let result = "";
let v ="";
とりあえず空の文字列の入れ物(全体を集約する result と ループごとの 1文字を入れる v)を用意しました。
ここは再代入処理になるので const ではなく letを使います。
しかし、このままハイライトの1文字だけを繋げてしまうと、単語毎の切れ目がありません。
というわけで、とりあえずではありますが
ハイライトあり(true)だったら plainText[i] を v
ハイライトなし(false) だったら ,(カンマ)を v
として ループごとに result = result+v で文字を繋げていくコードにしてみましょう。
function step03() {
const doc = DocumentApp.getActiveDocument();
const body = doc.getActiveTab().asDocumentTab().getBody();
const text = body.editAsText();
const plainText = text.getText();
let result = "";
let v ="";
for(i=0;i<plainText.length;i++){
if(text.getBackgroundColor(i)){
v = plainText[i];
}else{
v = ",";
}
result = result + v;
}
console.log(result);
}

無駄に , が多いですが、とりあえず単語ごとに区切れはしました。
forループの中で result = result + v を繰り返すことで、後ろに文字を足していくことができます。
さて、この , の連続する部分、Googleスプレッドシートの関数好きなら SPLIT関数で分割するついでに、無駄な空の部分を削除できるのになー、って思いますよね。
実は JavaScriptの Stringクラスにも split() があります。
この辺りのメソッドは スプレッドシートの関数に似ていて
文字列 ▶ 配列 split()
配列 ▶ 文字列 join()
って感じで、文字列と配列の切り替えに使えます。
split()メソッドには GoogleスプレッドシートのSPLIT関数のような 空の文字を削除する引数はありませんが、区切り文字に 正規表現が使えるという利点があります。
ということは・・・ result.split(/,+/) としちゃえば連続する , を一塊の区切り文字として処理できちゃうってことです!
ついでに単語末尾のハイライトのついてる改行も除去しちゃいましょう。
result.split(/[\n,]+/)
これで 改行(\n)または , の1つ以上の繰り返しを一塊の区切り文字として分割できます。
function step03() {
const doc = DocumentApp.getActiveDocument();
const body = doc.getActiveTab().asDocumentTab().getBody();
const text = body.editAsText();
const plainText = text.getText();
let result = "";
let v ="";
for(i=0;i<plainText.length;i++){
if(text.getBackgroundColor(i)){
v = plainText[i];
}else{
v = ",";
}
result = result + v;
}
let resultArray = result.split(/[\n,]+/);
console.log(resultArray);
}
ハイライトを付けた箇所の文字を 単語ごとに配列として取得できました~。
Step4. 一つ前の文字のハイライトと比較して処理する
Step3の処理方法、 ハイライトがnullの時に , としてひたすら文字連結してから、後から splitして単語ごとに配列化もアリなんですが、最初から単語で分割して配列に入れることはできないでしょうか?
for 内の処理でハイライトされた文字を ハイライト単位で区切る為には、一つ前の文字のハイライト色 と現在の文字のハイライト色を比較する必要があります。

処理としてはこんなイメージ。
一つ前の文字のハイライト色と現在の文字のハイライト色が一致しているなら連続する単語、そうでない場合は 別単語として処理をしています。
連続する単語の場合は、配列の最後の要素 array[array.length-1] の文字列 ハイライトの1文字 plainText[i] を追加する(文字の結合)処理となるので
array[array.length-1] = array[array.length-1] + plainText[i]
こうなります。
連続しない単語と判断した場合は、配列の最後に新しい要素として ハイライトの1文字を追加する処理なので
array.push(plainText[i])
配列 pushですね。
これをまとめると
function step04() {
const doc = DocumentApp.getActiveDocument();
const body = doc.getActiveTab().asDocumentTab().getBody();
const text = body.editAsText();
const plainText = text.getText();
let array = []; //ハイライトの文字を入れる為の配列
let pc = ""; // previousColor 一つ前のハイライト 初期値は空白としておく
for(i=0;i<plainText.length;i++){
const cc = text.getBackgroundColor(i);
if(cc){ //ハイライトが設定されていたら
if(pc === cc){ //一つ前の文字のハイライトと同じ場合
array[array.length-1] = array[array.length-1] + plainText[i]; //配列の最後の要素の文字に追加
}else{
array.push(plainText[i]); //配列に新しい要素として追加
}
}
pc = cc; //現在のハイライトをpcとして次へ
}
console.log(array);
}このようになります。

forループで直接ハイライトした単語を分割できましたね。
最後(次のループ前)に pc = cc として、現在のカラー(current color)を 一つ前のカラー (previous color)としてセットする箇所が大事です。これだけは if関係なく毎ループ実施するので ifの外側に記述しています。
これを忘れると、ずーっと pcが初期値のまま ""で ccと全て一致しないで終わります。
まずは一つ目の階段クリアですね。
Mapを使って色ごとにハイライトした単語を分類する
とりあえずハイライトされた文字をハイライト単位で配列として抽出することは出来ました。
それでは次の階段「ハイライトの色ごとに」を実現するにはどうすればよいか?
ここで登場するのが連想配列と呼ばれるものです。連想配列とは key とそれに紐づく valueで 構成された配列です。
今回の場合は key が ハイライトの色コード、valueが そのハイライト色で塗られた文字の配列ですね。

GAS(JavaScript)では、一般的に連想配列というと Object(オブジェクト)を指すことが多く、ネット上のコードも Objectを使ったものが多いです。
ただ Mapも 連想配列の一つであり、こちらを使う方法もあります。
スプレッドシートの getVlaues(),setValues()で読み書きする際の二次元配列は Mapと相性がいいこともあり、mirは結構 Map を使います。(ObjectはJSONとの相性がいいです。)
Object の回答も後で触れますが、今回は Mapでやってみましょう。(そこまで Mapの優位性があるケースではありませんが・・・)
Step5. 処理の流れをイメージする
それでは、このMapを使ってどう処理をすればよいか?
先ほどの Step4の処理をベースに考えてみましょう。
■Step4で作成した ハイライト単位で文字を配列に格納する処理
ハイライトされた文字を入れる空の配列[] array を用意しておく。
現在の文字にハイライトカラー が 存在する? → No:処理しない
↓ Yes:
一つ前のハイライトカラー pc と 現在のハイライトカラーcc が一致する?
↓ No → Yes:arrya の最後の要素の文字列の末尾に文字を追加
↓ array[array.length-1] = array[array.length-1] + plaintext[i]
↓
array に新しい要素として文字列を追加
array.push(plaintext[i]) する
最後に pc を cc に置き換える
👆これを 👇こう変更すると考えます
■Mapで ハイライトの色ごとに文字を配列に格納する処理
ハイライトされた文字を入れる Map を用意しておく。
現在の文字にハイライトカラー が 存在する? → No:処理しない
↓ Yes:
一つ前のハイライトカラー pc と 現在のハイライトカラーcc が一致する?
↓ No → Yes: Mapから キーが cc の value(配列)を取得
↓ そのvalue(配列) の最後の要素の文字列の末尾に文字を追加
↓ array[array.length-1] = array[array.length-1] + plaintext[i]
↓
Map内に キーが ccの要素が存在する?
↓No → Yes: 既存の要素の value 配列に 追加
↓
Mapに新しい要素として追加
最後に pc を cc に置き換える
つまり
cc(現在のハイライトカラー)がnullではないか?
pc と cc は同じか?
キーがccの要素は Mapに既に存在するか?
この3つを確認しながら処理を回していくことになります。
Step6. Mapを使った ハイライトの色ごと文字を取得するコード
これをコードにすると
function getHighlightedText() {
const doc = DocumentApp.getActiveDocument();
const body = doc.getActiveTab().asDocumentTab().getBody();
const text = body.editAsText();
const planeText = text.getText();
const colorMap = new Map(); // Mapを用意
let pc = ''; //一つ前の色
for(i=0;i<planeText.length;i++){
const cc = text.getBackgroundColor(i);
if(cc){ // ccがnullではない
if(pc===cc){ // pcとccが一致 前の文字の続きである
const value = colorMap.get(cc);
value[value.length-1] = value[value.length-1] + planeText[i];
}else if(colorMap.has(cc)){ //キーがccの要素は Mapに既に存在する
const value = colorMap.get(cc);
value.push(planeText[i]); //Mapから取得したvalue配列に要素として追加
}else{ //初めて登場する色のケース
colorMap.set(cc,[planeText[i]]); //Mapに新しい要素としてを追加
}
}
pc= cc;
}
colorMap.forEach((value, key) => {
console.log(`${key} = ${value}`);
});
}このようになります。実行してログを確認すると

正しく色コード毎に文字が取得できているのがわかりますね。
中身を解説すると
1.cc(現在のハイライトカラー)がnullではないか?
まず if(cc) がtrueでなければ、ハイライトなしの文字なので何もせずに pc=cc だけして次のループ(次の文字)に行きます。trueの場合は 2へ
2.pc と cc は同じか?
本来 Mapは、colorMap.has(cc) で cc(現在のカラーのカラーコード文字列)が colorMapに存在するか?を評価してから、trueだったら colorMap.get(cc) でvalue を取り出すのが基本ですが、今回のケースは ccがnullでなくて、pc===cc であると判別された段階で、Map内に ccは存在するキーであることは確定しているので すぐに colorMap.get(cc) でvalueを取り出して
value[value.length-1] = value[value.length-1] + planeText[i]
value(配列)の最後の要素の文字列を 最後の要素の文字列の後ろに今回のハイライト位置の1文字planeText[i] を連結した文字列に差し替えとしています。
3.キーがccの要素は Mapに既に存在するか?
もし pcとccが一致しなかった場合は、ccは 既に過去に登場したMapに存在する色コードか、新しく登場する色コードかによって処理を変える必要があるので、if(colorMap.has(cc)) で評価した結果が
trueなら
Mapからgetでvalue を取り出し value.push(planeText[i]) で、配列に新しい要素として追加する
falseなら
keyとvalueの組み合わせを colorMap.set(cc,[planeText[i]]) でMapに追加する
※ valueは配列としておく必要がるので [planeText[i]] としている
となります。
ログの確認
最後にログで確認する際は、Mapはそのままログとして見れないので、forEachで順番に keyとvalueをログに出力しています。
オブジェクトは forEachでは処理できませんが、Mapは forEachで処理が可能なんですよね。
でも、forEachで1ペアずつ 取り出す際の引数は key,value の順じゃなくて colorMap.forEach((value, key) と valueが先ってのがわかりにくい。
for (・・・of・・・) を使う方法もあり、こちらの方がしっくりくるって人もいます。
for (let [key, value] of colorMap) {
console.log(`${key} = ${value}`);
}Step7. Objectを使った ハイライトの色ごと文字を取得するコード
一応 オブジェクトで出力するコードも書いておきます。
同じif文を書いても面白くないので三項演算子で記述してみましたが、このケースだと可読性が悪くなるんでおススメしませんw
function getHighlightedText2() {
const doc = DocumentApp.getActiveDocument();
const body = doc.getActiveTab().asDocumentTab().getBody();
const text = body.editAsText();
const planeText = text.getText();
const colorObj = {}; // オブジェクトを用意
let pc = ''; //一つ前の色
for(i=0;i<planeText.length;i++){
const cc = text.getBackgroundColor(i);
if(cc){ // ccがnullではない
const value = colorObj[cc];
value?
pc===cc?
value[value.length-1] = value[value.length-1] + planeText[i] :
value.push(planeText[i]):
colorObj[cc] = [planeText[i]];
}
pc= cc;
}
console.log(colorObj);
}オブジェクトだとそのままログが出力できるのは楽ですね。

Mapに格納した色ごとの単語をスプレッドシートに縦(列方向)に出力する
最後に Mapに格納した 色ごとの単語配列を 縦並びに指定したスプレッドシートに出力する 処理を別関数で用意しましょう。
イメージとしては

ハイライト単語というシートがあれば、そこに上書き記入
ハイライト単語というシートがなければ新しくシートを 一番左に挿入
1行目は色コードでセルをその色に塗りつぶし
その色でハイライトされた単語を列毎に2行目から下に展開
ついでに不要な単語末尾にある改行を削除
👆こんな感じの処理です。
Step8. 指定した名前のシートがあるか?判断してなければ生成
//Mapを指定したスプレッドシートに書き出し
function ssOutput(mapobj){
ssId ='書き出し先のスプレッドシートのID';
const ss = SpreadsheetApp.openById(ssId);
const sheet = ss.getSheetByName("ハイライト単語") || ss.insertSheet("ハイライト単語", 0);
}スプレッドシートへの出力用に ssOutput(mapobj)という関数を用意しましょう。
Mapオブジェクトを引数としてとり、ssIdで 指定したスプレッドシートに書き出します。
※ssId ='書き出し先のスプレッドシートのID'
👆自分の書き出し先として用意したスプレッドシートのIDを入れます
ここで書き出し先のシート「ハイライト単語」が既にあればそこに上書き、なければ一番左側に新規作成する処理を
const sheet = ss.getSheetByName("ハイライト単語") || ss.insertSheet("ハイライト単語", 0);
このように|| で 短絡評価を使って記述しています。
insertSheet(sheetName, sheetIndex, options) メソッドは、シート挿入の際に、シート名、挿入するシートの位置(0が一番左)、オプション(コピー元のシートを指定可能)が出来るんで便利ですね。
これで出力するシートの準備が出来ました。
Step9. MapをforEachで順番に処理
Mapを処理する部分はログを出力した時と同じように
mapobj.forEach((value,key) =>
として、forEachでペア単位で 取り出して処理を回していくんですが、これをスプレッドシートに1列ずつ出力していく部分をどうするか?
ここは forEachの前で let i= 1 を宣言して、forEacheの処理内で最後に i++とすることで、1列ずつ ズラしてgetRange() で範囲を取得 をしていくのが良いでしょう。
//Mapを指定したスプレッドシートに書き出し
function ssOutput(mapobj){
ssId ='書き出し先のスプレッドシートのID';
const ss = SpreadsheetApp.openById(ssId);
const sheet = ss.getSheetByName("ハイライト単語") || ss.insertSheet("ハイライト単語", 0);
let i =1;
mapobj.forEach((value,key) => {
sheet.getRange(1,i).setBackground(key); //1行目のセルを塗りつぶし
value = value.map(v=>[v.replace(/\n$/,'')]); //値を二次元配列化、合わせて末尾の改行を削除
sheet.getRange(2,i,value.length,1).setValues(value);
i++;
});
}ポイントは 引数 colorMapの valueは 一次元配列となっているので、map(こちらは配列メソッドの方)で v => [v] として スプレッドシートに setValues() で書き込める 二次元配列化(縦並び化)。
さらに ついでに、正規表現とreplaceで 末尾に 改行 /\n$/ があったら 空白に置換(削除)という処理をしている点。
この map 処理で 配列の成形と 余計な改行の削除を処理しています。
スプレッドシートに出力する関数も完成しました。
Googleドキュメントから ハイライトした単語をGoogleスプレッドシートへ色別に書き出す GASコード完成版
最後に Step9で作成した関数 ssOutput を Step6で作成した関数 getHighlightedText の最後に記述すれば完成です。
function getHighlightedText() {
const doc = DocumentApp.getActiveDocument();
const body = doc.getActiveTab().asDocumentTab().getBody();
const text = body.editAsText();
const planeText = text.getText();
const colorMap = new Map(); // Mapを用意
let pc = ''; //一つ前の色
for(i=0;i<planeText.length;i++){
const cc = text.getBackgroundColor(i);
if(cc){ // ccがnullではない
if(pc===cc){ // pcとccが一致 前の文字の続きである
const value = colorMap.get(cc);
value[value.length-1] = value[value.length-1] + planeText[i];
}else if(colorMap.has(cc)){ //キーがccの要素は Mapに既に存在する
const value = colorMap.get(cc);
value.push(planeText[i]); //Mapから取得したvalue配列に要素として追加
}else{ //初めて登場する色のケース
colorMap.set(cc,[planeText[i]]); //Mapに新しい要素としてを追加
}
}
pc= cc;
}
colorMap.forEach((value, key) => {
console.log(`${key} = ${value}`);
});
ssOutput(colorMap); //スプレッドシートに出力
}
//Mapを指定したスプレッドシートに書き出し
function ssOutput(mapobj){
ssId ='書き出し先のスプレッドシートのID';
const ss = SpreadsheetApp.openById(ssId);
const sheet = ss.getSheetByName("ハイライト単語") || ss.insertSheet("ハイライト単語", 0);
let i =1;
mapobj.forEach((value,key) => {
sheet.getRange(1,i).setBackground(key); //1行目のセルを塗りつぶし
value = value.map(v=>[v.replace(/\n$/,'')]); //値を二次元配列化、合わせて末尾の改行を削除
sheet.getRange(2,i,value.length,1).setValues(value);
i++;
});
}ssOutput(colorMap); //スプレッドシートに出力
👆この部分で colorMapを ssOutput関数に渡して書き出し処理をしています。
動かしてみましょう。

希望する処理が出来ました~。
でもコレ少ない文字数だからサクッと完了したけど、本当に 1文字ずつで処理時間は大丈夫なの?と思うかもしれませんが


1万1千文字以上で、ハイライト3色 11単語ピックアップして出力という処理が 16秒程度ですから、多少は待ちますが十分実用に耐えうるスピードかと思います。
今回はGoogleドキュメントのGASの処理を通じて、forループ処理やMapの活用を学びました。
次回も、もう1回別ネタで GAS回を予定。
【有料コンテンツ】ハイライトした単語をスプレッドシートに書き出せる GAS仕込みGoogleドキュメントを用意しました。
最後に コードのコピペすら 面倒だからコピーしてすぐ使えるドキュメントが欲しい!って人向けに、
有料コンテンツとして今回の ハイライトした単語をGoogleスプレッドシートに書き出せる GASを仕込んだGoogleドキュメント を配布いたします。
解説は全て無料 部分に記載しているので、有料コンテンツに さらなる追加情報は ありません。
面倒だから 出来上がったファイルをすぐに使いたいって人
単に mir を応援したいんで 課金しますという足ながおじさんな人
無料部分の記事が参考になった、面白かったんで 支援しますって人
こんな方だけ 有料コンテンツをご利用ください。
多少なりとも 有料コンテンツ利用者がいると、モチベーションにもつながりますし、執筆にも力が入りますので感謝感謝です。
ちなみに この程度のコードを有料コンテンツとしているのは、自分なりの考え方として GASのコードを 有料サービスとして ココナラやクラウドワークスで提供して生業としている方々への配慮という面もあります。
なお、有料コンテンツで配布する Googleドキュメントはエディタを開かず即ツールとして使えるように
✅onOpenで ハイライト出力用の カスタムメニューを追加
✅スプレッドシートの選択不要で自動で ドキュメントを保存しているフォルダに「ドキュメントのファイル名_ハイライト」という名前の出力スプレッドシートを生成
✅モーダルダイアログでJavaScriptを実行させて生成したスプレッドシートを自動で開く
という機能を実装しています。
👇こんな感じで動きます(初回はスクリプトの承認が必要)

自動で生成したスプレッドシートのURLを開く動作は 👇コレの応用です。
よろしければ 是非課金してゲットしてください!
↓以下、有料コンテンツです。
【有料】ハイライトした単語をスプレッドシートに書き出せる GAS仕込みGoogleドキュメント
ここから先は
¥ 400
チップ大歓迎です。やる気がアップしますw