
Googleスプレッドシート XMATCH関数 超応用例 2(連続する値の入ったセルをまとめる)

「お題形式」で関数の使い方を理解する 超応用例シリーズ、XMATCHの超応用例を もう1つやってみましょう。
今回は 他の関数との組み合わせを考える必要があり、前回よりも「超」応用といえるかと思います。自信のある人は、是非回答を見る前に自力でチャレンジしてみてください。
前回の平日更新(XMTCHネタから脱線した GASによるジャンプネタ)
シリーズ 前回の記事
スプレッドシートで 連続するセルの値を まとめたい

画像の A列のような 間に空白のある 1列のデータを 空白を挟むまでの連続して値のある セルを 改行区切りでまとめて、連続データの開始行のセルに入れたいってことですね。
こんな需要があるのか?よくわかりませんが、知恵袋のネタなんで、こういう処理をしたい人がいるってことなんでしょう。
もちろんこれを、1つの式で実現したいってことです。
うーん、なかなか難しいお題ですね。
新関数登場前だったら、無理だったかもしれません。
先に肩慣らしで、このお題を 少し簡単にしたものをやってみましょう。
Q. 連続データを改行区切りで 1つのセルにまとめたものを詰めて出力したい
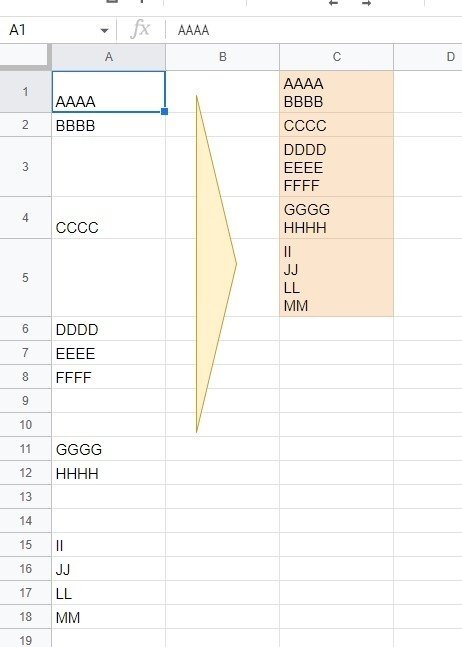
こんな感じ。
A列のような 間に空白のある 1列のデータを 空白を挟むまでの連続して値のある セルを 改行区切りで1つのセルにまとめて、それを上から詰めて出力したい。というお題です。
もちろん式は C1にのみ入れます。こっちはXMATCHは使いません。
これは、これで割と難しいんですが、出来そうでしょうか?
↓↓↓
回答は以下
↓↓↓
A. 連続データを改行区切りで 1つのセルにまとめたものを詰めて出力したい
とりあえず回答です。
=TRANSPOSE(SPLIT(TEXTJOIN(CHAR(10),false,A:A),CHAR(10)&CHAR(10),false))
ExcelのTEXTSPLITでも使ったテクニックですが、空白を詰める・セル配置を再構築するといったお題に対して、一度範囲をTEXTJOINで結合してから再度区切るという 方法が 有効だったりします。
回答の式を分解して、少し解説をしておきましょう。
式の解説
TEXTJOIN で結合の際 第2引数を false とすることで、空白セルの改行を残した状態で一度結合します。
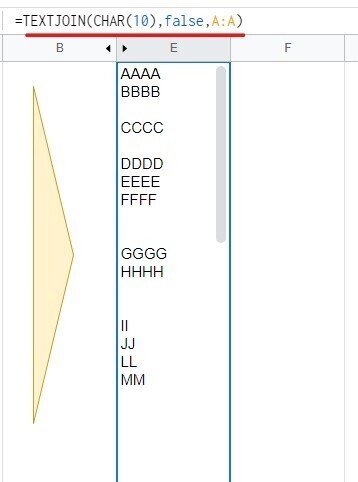
この1つになったデータを SPLITで区切る際に、改行が連続する箇所を区切り位置とすればよいので、
第2引数 区切り文字 CHAR(10)&CHAR(10)
第3引数 各文字での分割 false
とします。こうすることで、

このように 空白セルを区切りとして 連続データを改行で連結したデータが生成されました。あとはこれを TRANSPOSEで 縦横変換すればOK。
途中で TEXTJOINで一つの文字列にしているので、対象セルの文字数に上限はありますが、恐らくこの式が一番シンプルかと思います。
割と簡単ですね。じゃあ本番です。
Q. 連続データを改行区切りで 1つのセルにまとめたものを各連続データの開始行のセルに出力したい

では、これを一つの式で 実現するにはどうしたらよいでしょうか?
タイトルの都合上、XMATCHを使う方法を紹介しますが、実は XMATCH以外の関数を使った方が短い記述だったりします。もちろん別解としてそれらにも触れます。
自信のある人は、是非挑戦してみてください。
↓↓↓
回答は以下
↓↓↓
A1. 連続データを改行区切りで 1つのセルにまとめたものを各連続データの開始行のセルに出力する(xmatch関数を使う方法)
今回は「いきなり答える」ではなく、順を追って式を作っていきましょう。
まず、A列の「範囲の開始セル」という条件を 式にしましょう。
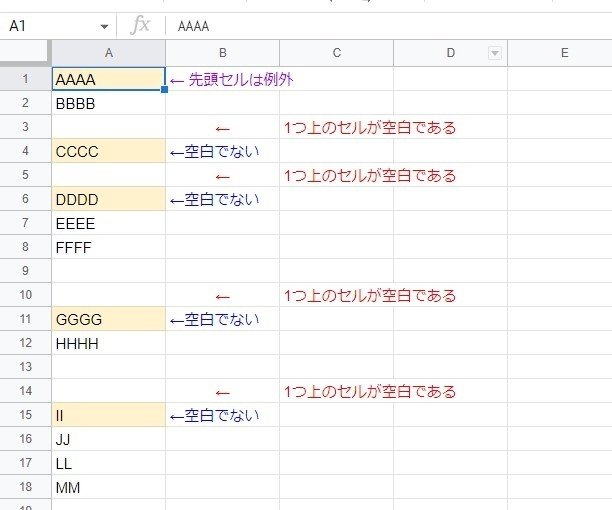
条件は
・空白セルでない
かつ
・1つ上のセルが空白である
こうなります。1行目だけ1つ上のセルが存在しないので例外となりますが、これを式に落とし込んでみましょう。
1つ上のセルの取得は OFFSETが思いつきますが、実は Arrayformula でスピらせた場合は OFFSETが使えません。
Arrayformulaを使う為にOFFSETではなく、対象範囲自体を 一つずらすという方法もありますが、今回は OFFSETが使えるスピル LAMBDA + ヘルパー関数を使って式にしてみましょう。
BYROW もしくは MAP関数で OFFSETをスピらせる
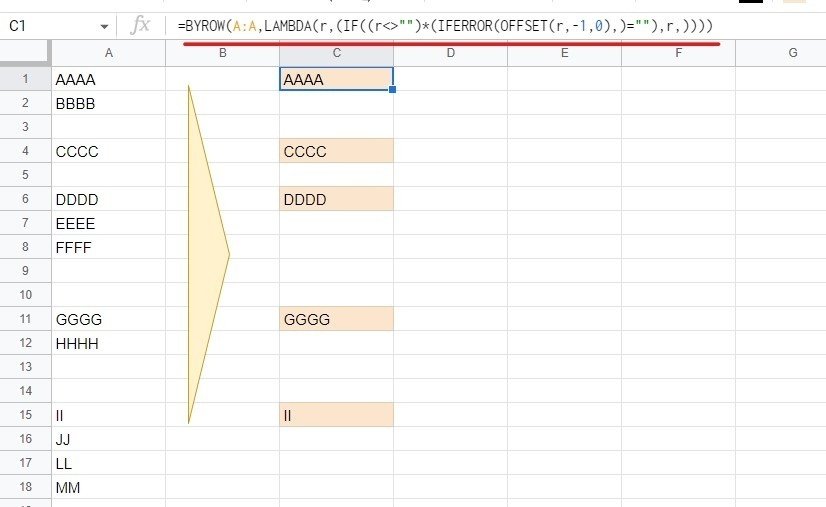
=BYROW(A:A,LAMBDA(r,(IF((r<>"")*(IFERROR(OFFSET(r,-1,0),)=""),r,))))
もしくは
=MAP(A:A,LAMBDA(v,IF(AND(v<>"",IFERROR(OFFSET(v,-1,0),)=""),v,)))
Arrayformulaでは、OFFSET関数同様に AND関数、OR関数も使えません。Arrayformula内で、「かつ」や「または」の条件を使いたい場合は 演算子で代替します。
AND関数の代わりに *(かける)、OR関数の代わりに +(たす)を使う必要があります。
ですが、LAMBDA ヘルパー関数によるスピルでは AND関数、OR関数が使えるので、上のようにどちらを使ってもOKです。
また今回は A列のみが対象なので、BYROW、MAPどちらを使っても同じ結果が得られます。
ポイントとしては、例外的な1行目のケースにシンプルに対処する為の
IFERROR(OFFSET(r,-1,0),)
ここでしょうか。OFFSET(r,-1,0) で1つ上のセルを取得して 空白かどうかを確認したいのですが、1行目の時だけは 1つ上のセルが存在しないので、 OFFSET(r,-1,0) はエラーとなってしまいます。ここを回避する為に IFERRORでエラー時に 空白を返すという処理をしています。
あとは、ここで条件に一致したら r (A列のセル)をそのまま返している部分を、連続セルを改行で結合したものを 生成する式にすれば OKですね。
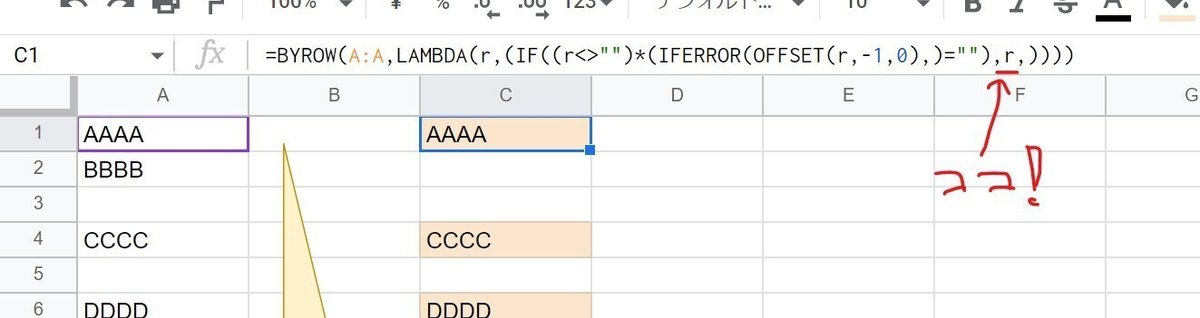
XMATCH 近似値一致大 を応用し 連続するセル区間を取得
ようやく XMATCH関数の出番です。値の入った連続するセル区間を取得するにはどうするか?
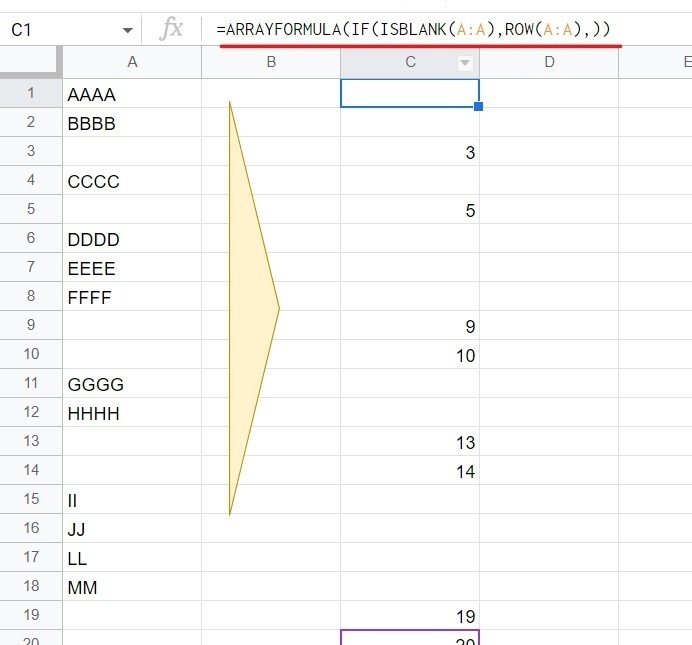
=ARRAYFORMULA(IF(ISBLANK(A:A),ROW(A:A),))
こんな感じで A列が 空白セルなら 行番号、空白でなければ空白という 1列のバーチャルな配列を生成します。
XMATCH で 連続するセル範囲の先頭の行番号を 検索値として、この配列を 対象として 近似値一致 大を することで、連続するセル範囲の終点の一つ下の行番号を取得することができます。
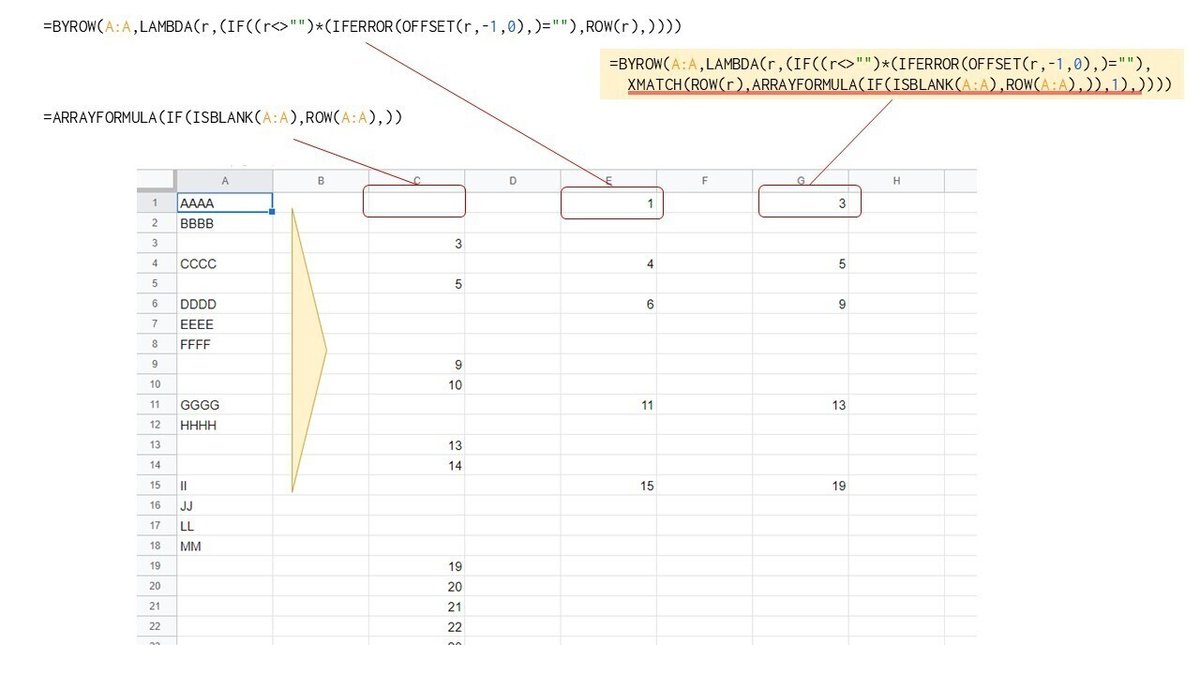
このように、連続データの 開始行、そして 終了行の一つ下の行番号を取得出来ました。
これをOFFSETと組み合わせて連続データ範囲を取得し、TEXTJOINで改行で連結することで欲しかった結果が得られそうです。
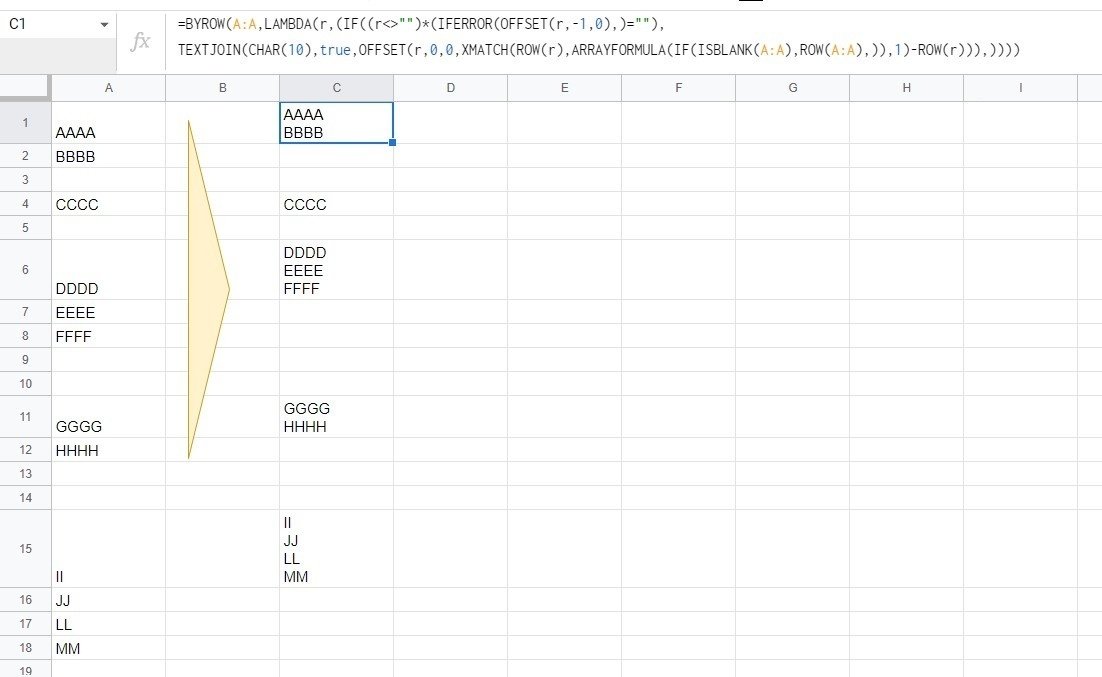
=BYROW(A:A,LAMBDA(r,(IF((r<>"")*(IFERROR(OFFSET(r,-1,0),)=""),
TEXTJOIN(CHAR(10),true,OFFSET(r,0,0,XMATCH(ROW(r),ARRAYFORMULA(IF(ISBLANK(A:A),ROW(A:A),)),1)-ROW(r))),))))
ここでポイントとなるのは、LAMBDAヘルパー関数(今回の場合は BYROW)で、セル範囲を対象としたとき、取り出す一つ一つの要素はセル参照であるってことです。
BYROW(A:A,LAMBDA(r,
r ・・・ はA1,A2,A3 というセル参照
セル参照なので OFFSETが使えます。
※OFFSETは残念ながら 配列には使えません。
OFFSET(r,0,0,XMATCH(ROW(r),num_array,1)-ROW(r))
これで r を起点として そこから 下に
rより下の最初の空白セルの行番号 - rの行番号
(つまり rから 値のある行範囲)
を取得することができます。これを TEXTJOIINで CHAR(10) ※改行 で連結して結合すれば、求めていた結果が得られます。
これで終わりでもいいんですが、もう少し式を工夫しておきましょう。
計算結果に LETで 名前をつけて 計算を減らす
ここでGoogleスプレッドシートに追加された最新関数 LETを使ってみましょう。
今回の式は
ARRAYFORMULA(IF(ISBLANK(A:A),ROW(A:A),)),1)
この式が BYROW内に記述されているので、何度もこの計算処理を繰り返していると思われます。
これをBYROWの外にだして、結果を適当な変数(定数)に置くことで不要な計算処理を削減し動きを軽くしようってことです。
もちろん LAMBDAでも出来ますが、可読性の高いLET関数でいってみましょう。ついでに 何度も登場する A:A もLETで定数化しちゃいましょう。
=LET(array,A:A,num_array,ARRAYFORMULA(IF(ISBLANK(array),ROW(array),)),BYROW(array,LAMBDA(r,IF((r<>"")*(IFERROR(OFFSET(r,-1,0),)=""),TEXTJOIN(CHAR(10),true,OFFSET(r,0,0,XMATCH(ROW(r),num_array,1)-ROW(r))),))))
これが XMATCHを使った 回答になります。
前半部分、LET関数で
A:A ・・・ arrayと置く
↓ arrayを使って
ARRAYFORMULA(IF(ISBLANK(array),ROW(array),))・・・num_array と置く
このようにしています。
これによって BYROWの式で 同じ計算を無駄に 何度もやる処理を削減し、対象とする範囲 A:Aを変える際も 一か所だけ変更すれば済むようにしています。
結構 面倒な式でしたね。
ちなみに 知恵袋での回答は、ここまで精査できてないです。
知恵袋は質問が解決済みになると、後から修正できないのよね。。
A2. 連続データを改行区切りで 1つのセルにまとめたものを各連続データの開始行のセルに出力する(xlookup関数を使う方法)
さて、上のxmatch関数を使う式でもいいんですが、連続する値の入ったセル範囲を取得するのに
xmatchでそのセルから 見た最初の空白行の行番号を取得
↓
そのセルの行番号を引くことで 範囲の長さ(高さ)を取得
↓
その結果を使ってOFFSETで範囲を取得
という流れが、なんか煩雑だなーと感じますね。
実はこれを解決するのに XLOOKUP関数が使えます。
XLOOKUPの結果は セル参照である ⇒ 参照演算子が使える
ここでポイントとなるのが、XLOOKUPの結果は LAMBDAヘルパー関数と同様にセル参照であるという点です。
つまり XLOOKUPの式(の結果)は、そのまんま 範囲参照 に使える、つまり :でつないで範囲を取得できる ってことです。
これを応用することで、先ほどのXMATCHの式が 簡略化できます。
XLOOKUPを使った回答式
大部分の考え方は ほぼ一緒なので、いきなり回答です。
=LET(array,A:A,num_array,ARRAYFORMULA(IF(ISBLANK(array),ROW(array),)),MAP(array,LAMBDA(v,IF((v="")+(IFERROR(OFFSET(v,-1,0),)<>""),,TEXTJOIN(CHAR(10),true,v:XLOOKUP(ROW(v),num_array,array,,1))))))
BYROW(5文字)より MAP(3文字)の方が 短いんで、ついでにMAPに置き換えてみました。
XMATCHの式との変更点は
OFFSET(r,0,0,XMATCH(ROW(r),num_array,1)-ROW(r))
↓
v:XLOOKUP(ROW(v),num_array,array,,1)
ここです。
XLOOKUPの第5引数(一致モード)を 1とすることで、XMATCH同様に 近似値一致 大を使っているのは一緒です。
ここではXLOOKUPで num_array(空白行の行番号)を そのセルの行番号で検索し、最も近い検索値以上の値(行番号)を見つけたら array(A列)を返すという処理をしています。
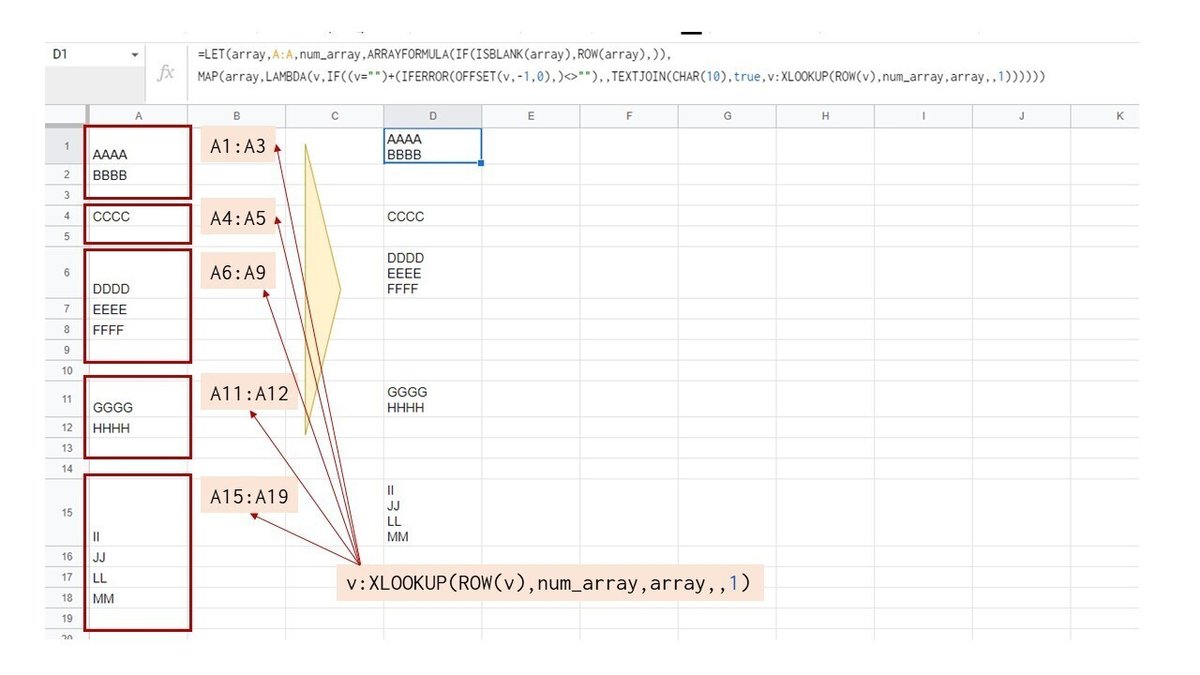
XMATCHと違って 取得した各範囲は、一番下に空白セルを1つ含みますが、これはTEXTJOIN の第2引数 をTRUEとしているので、文字列として 改行で結合する際に 消えます。
それにしても
v:XLOOKUP(ROW(v),num_array,array,,1)
で、セル範囲を参照できてるってのが面白いですね。
アルファベット一文字だと、V列?って混同しそうですが。
A3. 連続データを改行区切りで 1つのセルにまとめたものを各連続データの開始行のセルに出力する(REGEXEXTRACT関数で切り出す方法)
=LET(array,A:A,MAP(array,LAMBDA(v,IF((v="")+(IFERROR(OFFSET(v,-1,0),)<>""),,REGEXEXTRACT(TEXTJOIN(CHAR(10),false,v:INDEX(array,ROWS(array),)),"(?s)^(.+?)\n\n")))))
ちょっと荒っぽいやり方ですが、連続データの開始行から その下のセルを全部 TEXTJOINで改行つなぎで結合した上で、文頭から 連続改行までを REGEXEXTRACT関数で取り出すって方法もあります。
これが一番式としては短いですが、対象データのセル数、文字数によってはTEXTJOINでの結合の上限を超えてエラーとなるので注意。
こちらの式のポイントは2点あります。
式の結果を使った 範囲演算子 は 終点を指定しないと機能しない
Excelと違って Googleスプレッドシートの 良い点に、列のお尻(終点)を決めずに範囲指定できるってのがあります。
Excelは A:A のように 列全体を選択はできますが、開始行だけ指定したい時に A3:A といった 範囲指定は出来ません。
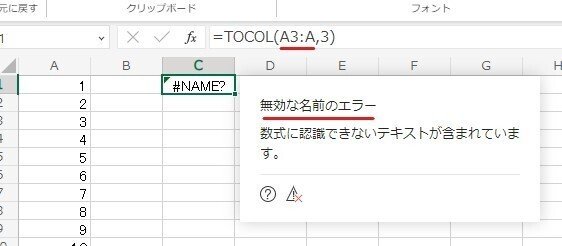
A3:Aとするとセル範囲と認識されずエラーになります。
一方 Googleスプレッドシートは A3:Aという指定がアリです。
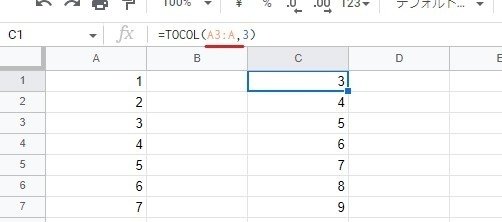
終点を決めず、A列の3行目下全てといった指定が出来るのです。
ただ、これが 式の結果と 範囲演算子 : を組み合わせた方法だとうまくいきません。
v:A
とすると エラーとなるため
v:INDEX(array,ROWS(array),)
このように INDEX(array,ROWS(array),) で array(A:A)の終点をINDEXで取得して v(MAPで上から順番に取得したセル参照) と範囲演算子を組み合わせて、範囲を取得しています。
Googleスプレッドシートの関数は フラグで ドットオールモードが使える
もう一つのポイントは REGEXEXTRACT関数での正規表現です。
REGEXEXTRACT(TEXTJOIN(CHAR(10),false,v:INDEX(array,ROWS(array),)),"(?s)^(.+?)\n\n")))))
"(?s)^(.+?)\n\n" ← この部分
MAPとTEXTJOINを組み合わせることで、条件を満たした 行のセルから 下までを全部 改行で 繋いで 一つの文字列にしてから、先頭から改行が2回続く手前までの部分を正規表現で取得する という式なんですが、
単に ^(.+?)\n\n としてしまうと、欲しい箇所が取得出来ません。
理由は 正規表現の .(ドット)は、(なんでもよい)任意の一文字を意味しますが、この「なんでもよい」の中に 改行 が含まれない為です。
なので、改行を含む文字列に対して 正規表現を使う場合は 記述に工夫が必要なのですが、これを簡単にするのが
(?s)
この部分、シングルラインモードとか sフラグ、ドットオールモードと呼ばれる ものです。
これを先頭につけることで、改行を含む全ての文字を ドットで拾えるようになります。
これで 改行が2連続する手前までの、改行を含む文字列を取得しているのです。
このドットオールモード(シングルラインモード)を使った 応用例は色々あるので、機会があれば紹介したいと思います。(そもそも、ちゃんとに正規表現を 説明した noteをまだ1個も書いてないけどw)
まぁ、こんな式でも出来るよって参考程度に読んでおいてください。
次回は 他の関数の超応用を
XMATCHの超応用例と書きつつ、今回は XLOOKUPの方が目立ってたかも?
使う機会は多くないかもしれませんが、式の結果を : で連結して 範囲取得できるのは面白いですね。
平日更新は、もう少し単発の関数ネタを掲載していきたいと思います。
いいなと思ったら応援しよう!
