
Googleスプレッドシート FILTER関数 超応用例 -3(複数フリーワード検索)

まさか FILTER関数だけで3週も引っ張るとは思いませんでしたが、ようやく今回が最後となります。
新関数とFILTER関数を組み合わせた、超応用例にチャレンジしていきましょう。
前回・前々回を読んでない場合は、先にそちらを見ておくことをお勧めします。
↓ 前回のnote 中級レベルの FILTER関数 チョイ応用例多数掲載
↓ 前々回のnote FILTER関数の基礎から importrangeとの併用を解説
FILTER関数 超応用例 その前に
超応用例の前に 2問ほどFILTER関数の理解を深めるお題を用意しました。前回のチョイ応用例 よりもハードルをあげてます。
まずはこれらを理解した上で、最後(ラスボス)の超応用例に挑戦しましょう。
Q1. FILTER関数で A列 が重複した場合、最後に登場するものだけに絞り込みたい

A2:C を範囲として 発注日が 昇順になっているデータがあります。何回か同じ人が発注していることがあります。(例えば 黄色塗りつぶしの 佐藤 裕子)
このデータを発注者 氏名ごとの 最終発注 のみのデータにしたい。
こんな要件は結構ありますよね。
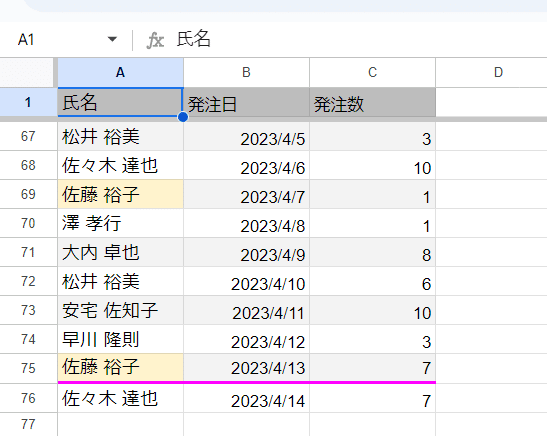
つまり 佐藤 裕子 さんだと、8行目、18行目と 何回か購入履歴がありますが、一番直近(一番下)の 75行目の 2023/4/13 発注数 7 の情報だけ取得したいってことです。
他の方法もありますが、FILTER関数でいけるお題です。まずはチャレンジしてみましょう!
↓↓↓回答
A1. FILTER関数で A列 が重複した場合、最後に登場するものだけに絞り込む
今回はFILTER関数のお題として出しているので、FILTER関数を使うんだろうなと想像できますよね?
でも普通にこんな依頼を受けたら、重複をまとめるってことで UNIQUE関数 をイメージするかもしれません。
しかし残念ながら このようなケースでは UNIQUE関数では処理できません。
UNIQUE関数で絞り込んだ名前を XLOOUPの下から検索で処理することは可能ですが、縦横スピルさせる為にさらに BYROWと組み合わせる必要があり 複雑な式になってしまいます。
他に思いつくのは Query関数の group by 句の利用ですが、これも 日付は max(B) で抽出できても、その日の購入数が取得できません。
というわけで、これは実は FILTER関数を使うのに適したお題なんです。
条件式の部分は 幾つか書き方がありますが、COUNTIFS を使うのがシンプルで良いです。
最後に登場(行番号が最大のもの)という条件の書き方で
=FILTER(A2:C,A2:A<>"",COUNTIFS(A2:A,A2:A,ROW(B2:B),">"&ROW(B2:B))=0)
これが 正解となります。
ちなみに B列の 発注日が 昇順なので、条件を B列にする書き方もありますが、
=FILTER(A2:C,A2:A<>"",COUNTIFS(A2:A,A2:A,B2:B,">"&B2:B)=0)
こちらだと ある人の最後の購入が、同じ日に 2回買っていた場合、重複して出力される恐れがあります。
一意の値である 行番号を条件に使った方がよいです。
条件部分を解説していきましょう。
A2:A<>""
1つ目の条件、ここはいいですね。A列に名前が入っていない行は、まず除外しています。
もう一つの
COUNTIFS(A2:A,A2:A,ROW(B2:B),">"&ROW(B2:B))=0
この部分は COUNTIFSを使った以下の 累計カウントの応用です。
少し話が反れますが、FILTER関数内での COUNTIFSの動きを理解する為に 累計カウントについて 説明します。
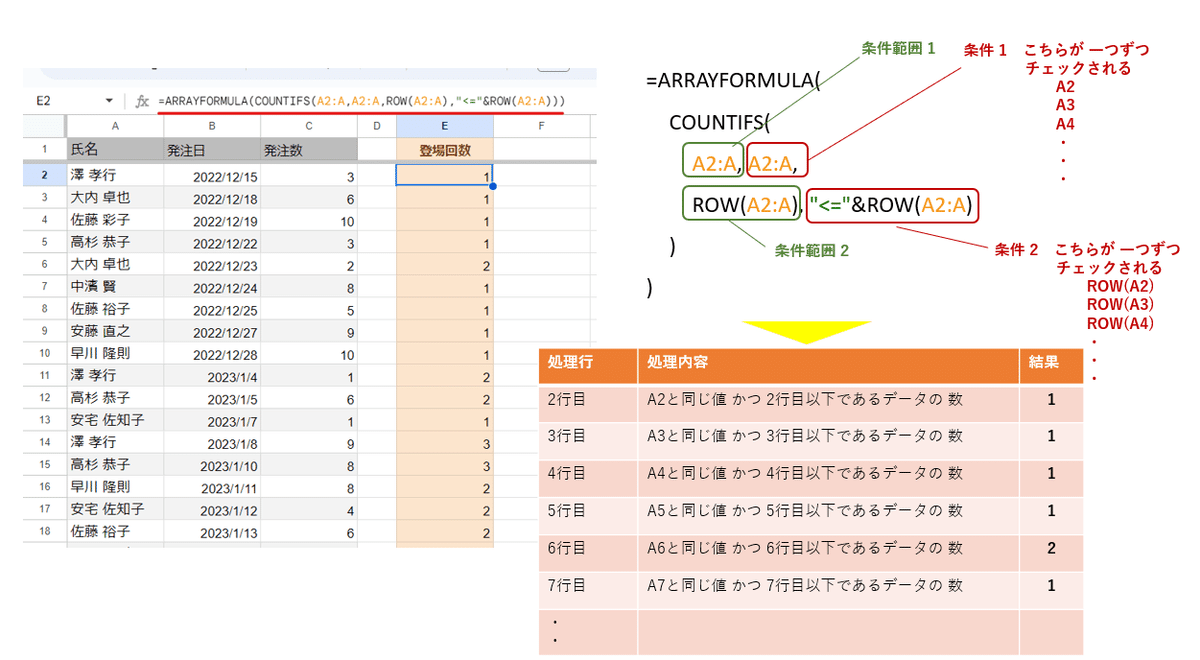
【補足】Arryaformula + COUNTIFS で累計カウントをする
=ARRAYFORMULA(COUNTIFS(A2:A,A2:A,ROW(A2:A),
"<="&ROW(A2:A)))
COUNTIFSでこのような式を作ることで、A列の氏名毎に 上から何回目の登場かを累計カウントすることができます。

これは COUNTIFSの 条件の方(第2引数、第4引数)が Arrayforomula で配列として 一つ一つ処理されています。
この 式の "<=" の部分を ">" として
COUNTIFS(A2:A,A2:A,ROW(B2:B),">"&ROW(B2:B))
とすれば、FILTER関数内で使用しているので Arrayformulaなしで配列として処理されるので、自分の行と A列の値(名前)が同じで かつ 自分の行より 大きい行であるデータの数 が、1列の配列で返ります。
この結果が 0である = 名前が重複するデータで 一番下に登場するもの
と言えるので、上の式で 求めたい結果が得られるわけです。
FILTER関数というより、COUNTIFSの応用例じゃない?って思うかもしれませんが、先週も書いた通り FILTER関数は 条件部分にシート関数がフル活用できる関数です。
つまり 数多くのシート関数を使いこなせることが、FILTER関数を使いこなせることに繋がるってことです。
Q2. FILTER関数で列指定なしで 検索ワードに一致する行を抽出したい
超応用例の簡易版問題です。通常は 検索列を指定する必要がある FILTER関数で、列指定なしに検索はできるんでしょうか?
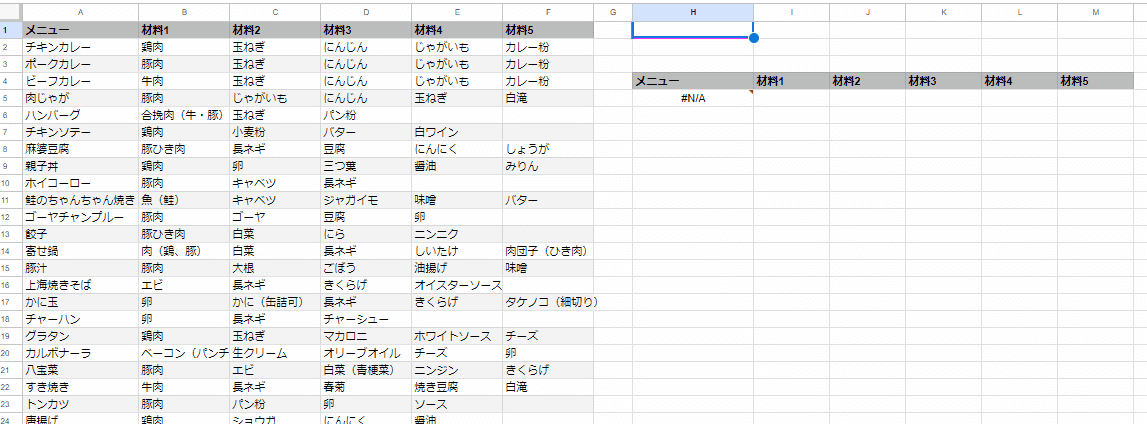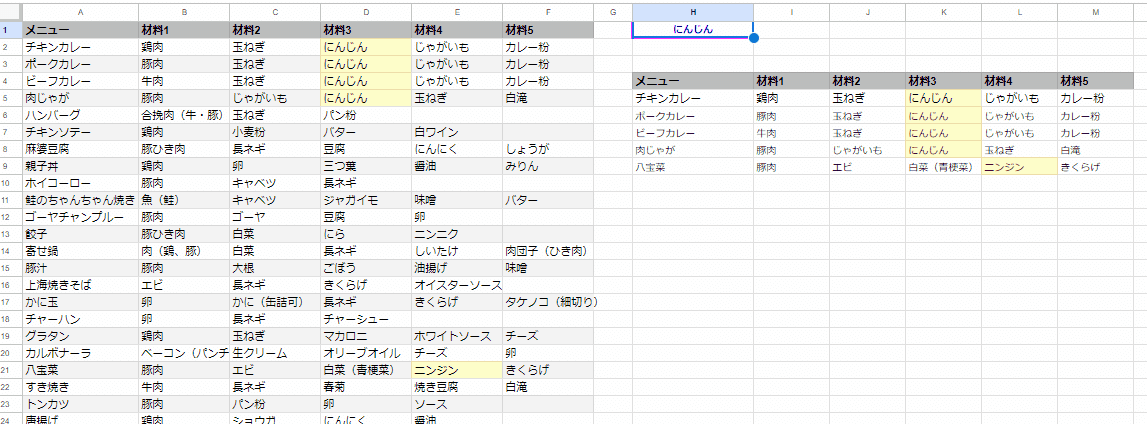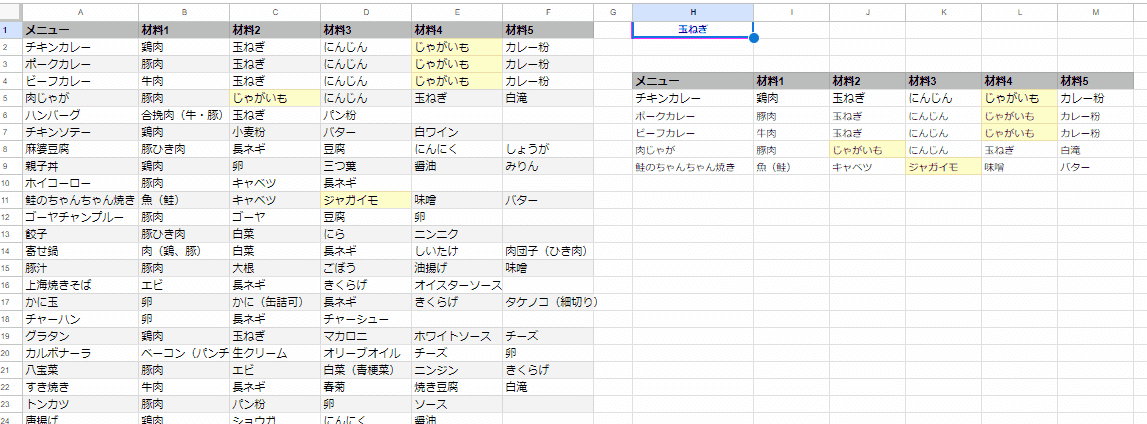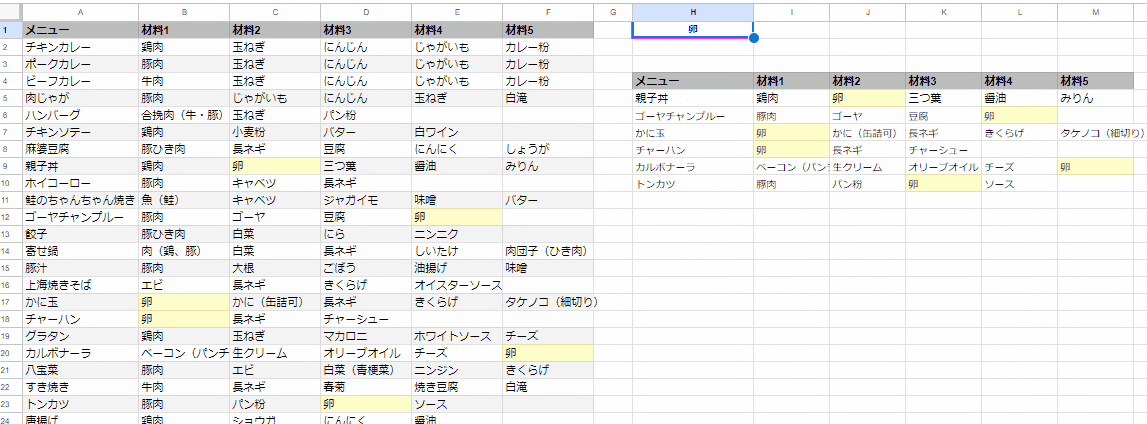
需要としては、こんな感じの B列~F列が 材料1、材料2、材料3… みたいになってたり、担当1、担当2… みたいなケースでしょうか。
A2:Fのデータから
B2:Fのいずれかの列のセルが
H1に入れた検索ワードと一致した行を
抽出したい
要件としてはこんな感じです。
どうでしょう、いけそうでしょうか?
新関数の活用もイメージして、いけそうな人は自力でまずは作成してみましょう!
↓↓↓回答
A2a. FILTER関数で列指定なしで 検索ワードに一致する行を抽出する
ぶっちゃけ 新関数(LAMBDAヘルパー関数)が使えれば 割と簡単だったりします。
行単位で 一致するセルがあるか?見ていけばよいので、行毎の処理ができる BYROWの出番です。
=FILTER(A2:F,BYROW(B2:F,LAMBDA(r,COUNTIF(r,H1))))
BYROW(B2:F,LAMBDA(r,COUNTIF(r,H1))
条件式のこの部分で、B2:Fの範囲を行毎(B2:F2, B3:F3, B4F4… ) に見て、その行(r) に H1と一致するセルが幾つあるか? をCOUNTIFで計算しています。

このように行毎の H1と一致するセルの数が 1列の配列で返ります。
0以外の数値は TRUE扱いとなるので、これがそのまま条件に使えるわけです。
A2b. FILTER関数で列指定なしで 検索ワードに一致する行を抽出する (新関数登場前の方法)
じゃあ LAMBDAヘルパー関数登場前は対応できなかったのか?というと、そんなこともなくて 既存関数を工夫すれば対応できたんです。
=FILTER(A2:F,COUNTIF(IF(B2:F=H1,ROW(B2:F)),ROW(B2:B)))
COUNTIFの中でさらにIF関数で配列処理をしています。
IF(B2:F=H1,ROW(B2:F))
この部分で何をやっているか?
H1に一致したセルを行番号に置き換え、それ以外をFALSEとしています。
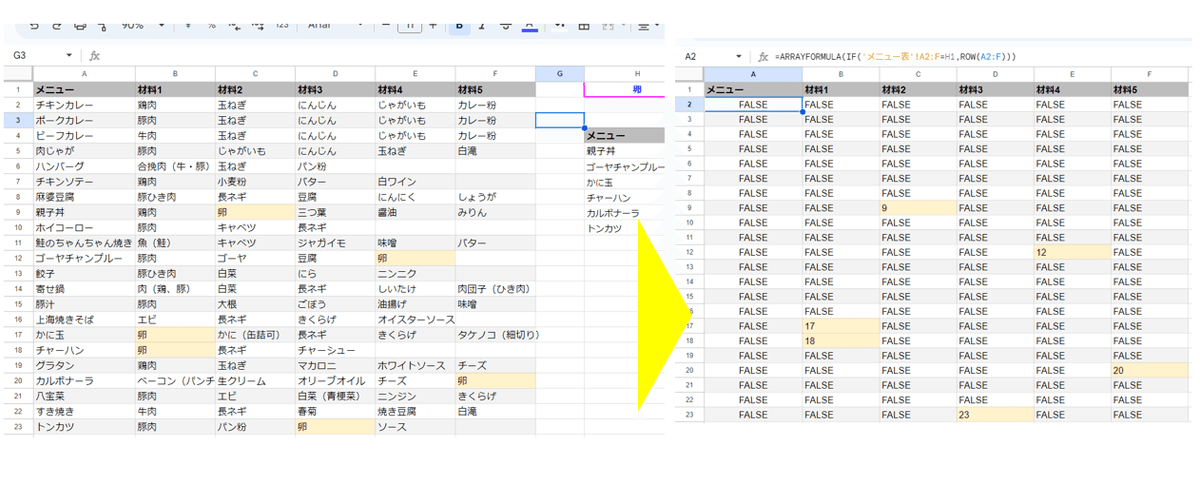
この結果を COUNTIF の検索対象範囲として、 検索値を ROW(B2:B) と行番号の連番にすることで、H1に一致した行(行番号が存在する行)は COUNTIFの結果で 1以上が返り FILTER関数で抽出できるという仕組みです。
本当はこっちの方がドヤれる式なんですが、LAMBDAヘルパー関数登場で簡単に出来るようになっちゃったんですよね。。
まあ、古いやり方にこだわる必要はないので参考程度にw
【補足】FILTER関数で列指定なしで 検索ワードを「含む」行を抽出する
では、列指定で一致ではなく「含む」だとどうか?
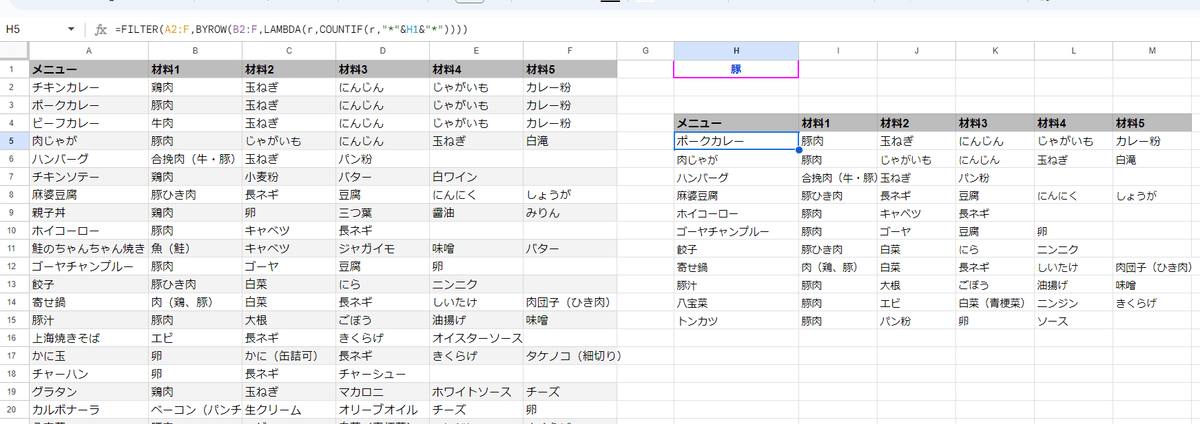
=FILTER(A2:F,BYROW(B2:F,LAMBDA(r,COUNTIF(r,"*"&H1&"*"))))
せっかく COUNTIFを使ってるんで、
"*"&H1&"*"
として、ワイルドカードで H1の前後を挟むようにするのが簡単ですね。
FINDやREGEXMATCHを使っても出来ますが、それだと 行毎に 1つに集約する為の関数をもう一つ使う必要が出てきます。(SUMPRODUCTあたり)
今回のようなケースは COUNTIF + ワイルドカード がベストでしょう。
超応用例の 解法が少し見えてきたんじゃないでしょうか?
FILTER関数 超応用例にチャレンジ
ようやく本題です。FILTER関数シリーズの第1回に登場した 下の フリーワード複数条件検索。こちらの式を考えてみましょう。

エンターで確定しての検索なので、インクリメタルサーチとは言えませんが、列にとらわれず スペース区切りで複数フリーワード検索ができる & ヒット件数が表示されるのは、Web検索(Googleでの検索)に近い操作感と言えるんじゃないでしょうか?
一見 GAS(プログラミング)が必要そうな 処理ですが、シート関数の組み合わせで 1つの式で可能です。
それではいってみましょう。
Q3. FILTER関数で 一つのセルに スペース区切りで入れた 複数ワードで、列指定なしの「含む」条件のAND検索をしたい
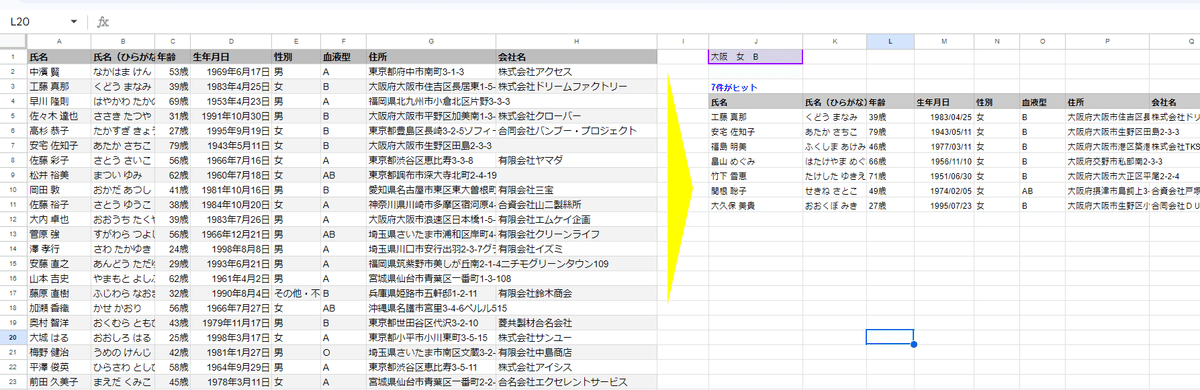
イメージは 画像の通りです。
・対象データの範囲はA2:H
・J1に入れた スペース区切りの複数ワードで 絞り込み検索ができること
(複数ワードは何個までという指定はなし)
・区切りのスペースは 半角、全角どちらにも対応すること
・ワードを「含む」で検索できること
・列を指定せず 検索できること(どこかのセルに含んでる行を抽出)
・生年月日も検索できること
・タイトル行も出力すること
・タイトル行の上にヒット件数を表示すること
・J3セルに入れた 一つの式で処理すること
もちろん、この方式だと
住所の「千葉」で絞り込むつもりが 名前が「千葉」さん の人も抽出
氏名の「中島」を抽出するつもりが 会社名の「中島商店」も抽出
年齢「16」で絞り込むつもりが 16日生まれや 住所に16が入る人も抽出
といった誤抽出が発生しますが、その点は許容することにしましょう。
ちなみに元データ 無いと困るよーという方は、以下のようなテストデータ生成サイトが便利です。(Chat-GPTもダミーデータ生成してくれます)
↓今回はこちらを使わせていただきました
どうでしょうか、式が作れそうなら是非チャレンジしてみてください。
↓↓↓回答
A3. FILTER関数で 一つのセルに スペース区切りで入れた 複数ワードで、列指定なしの「含む」条件のAND検索をする
いきなり答えではなく、順を追って回答までいきます。
いままでの応用例を活用しよう
まず今までやったことを振り返り、出来ることを整理しましょう。
・ワードを「含む」で検索できること
・列を指定せず 検索できること(どこかのセルに含んでる行を抽出)
まずこの2つは、今回 のQ2 のお題の 補足の式を使えば対処できますね。
結果範囲も検索範囲も A2:H、検索ワードは J1なので
=FILTER(A2:H,BYROW(A2:H,LAMBDA(r,COUNTIF(r,"*"&J1&"*"))))
このように書けます。
さらに
・生年月日も検索できること
こちらは 前回の Q6. FILTER関数で 〇年生まれや〇月生まれを抽出 の解法が使えますね。
TO_TEXT関数で 生年月日の日付データ他、範囲すべてを文字列化しておきましょう。
=FILTER(A2:H,BYROW(TO_TEXT(A2:H),
LAMBDA(r,COUNTIF(r,"*"&J1&"*"))))
そして
・タイトル行も出力すること
こちらは 第1回で QUERY関数との比較で登場した処理です。
解法の中でも 汎用性の高い SEQUENCE(ROWS(data))=1 を使いましょう。
範囲にタイトル行も含める必要があるので、A2:Hを A:Hに変えて
=FILTER(A:H,BYROW(TO_TEXT(A:H),
LAMBDA(r,COUNTIF(r,"*"&J1&"*")))
+(SEQUENCE(ROWS(A:H))=1) )
このようにします。A:Hが複数回出てくるので LETしておきましょう。
=LET(data,A:H,FILTER(data,BYROW(TO_TEXT(data),
LAMBDA(r,COUNTIF(r,"*"&J1&"*")))
+(SEQUENCE(ROWS(data))=1) ))
この段階で一旦動作を確認。
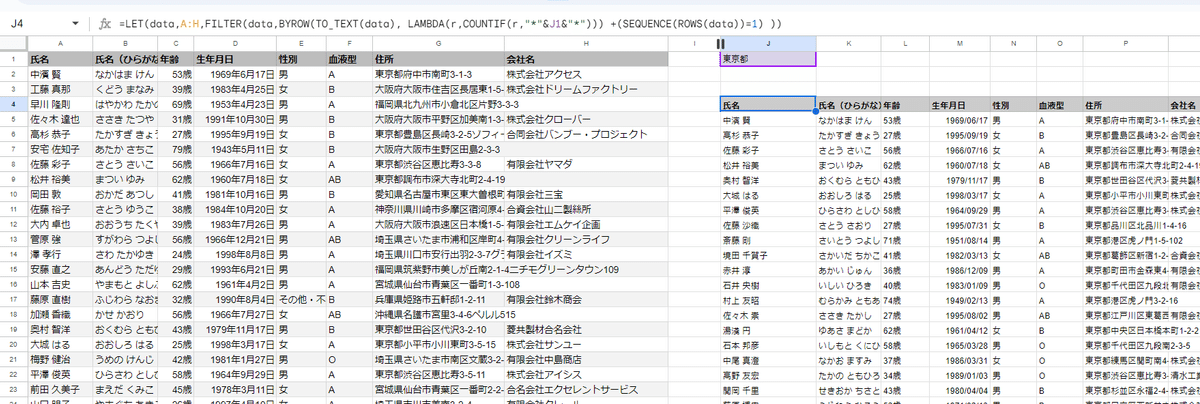

ここまでは問題なさそうです。
LET関数と配列操作新関数 で 結果 から 検索ヒット数を取得し結果と結合
タイトル行は 出ましたが、
・タイトル行の上にヒット件数を表示すること
これはどうすればよいか?
このヒット件数というのは、上の FILTER関数で返った行数 マイナス 1(タイトル行を除いた行数)と言えます。

これは FILTER関数の結果を result と置いた場合
ROWS(result)-1
で取得できます。これをちょっと加工して
ROWS(result)-1&"件がヒット"
と出力すれば良いですね。
これをタイトル行の上に表示させるには、FILTER関数の結果 result と縦結合が必要です。
サイズが違うので 中カッコの結合 ではなく ここは
VSTACK+IFERROR
の出番です。
これを先ほどの式に加えると、以下のようになります。
=LET(data,A:H,
result,FILTER(data,BYROW(TO_TEXT(data),
LAMBDA(r,COUNTIF(r,"*"&J1&"*")))
+(SEQUENCE(ROWS(data))=1)),
IFERROR(VSTACK(ROWS(result)-1&"件がヒット",result)))

タイトル行の上にヒット件数表示ができました。
もちろん、どこにも含まれないワードを入れると 0件表示になります。

だいぶ 近づいてきたんじゃないでしょうか。
でも複数ワードでの絞り込みという、最難関の壁が残っています。
1つのセルに入った複数ワードを SPLITする
・J1に入れた スペース区切りの複数ワードで 絞り込み検索ができること
(複数ワードは何個までという指定はなし)
・区切りのスペースは 半角、全角どちらにも対応すること
まず 先に J1に入れた スペース区切りの キーワードを 配列化して扱いやすくしましょう。
「区切り」という文字が出てるのでピンとくる方もいるかと思いますが、ここは SPLIT関数 を使って 文字列 → 配列 の変換をします。
SPLIT(テキスト, 区切り文字, [各文字での分割], [空のテキストを削除])
Googleスプレッドシートの SPLIT関数は 第2引数の区切り文字に複数文字を入れた場合は、第3引数で false を指定しなければ 自動で個々の文字で区切ってくれる仕様です。
よって今回の場合は 半角スペース、全角スペース どちらにも対応すればよいので、以下の式になります。
=SPLIT(J1," ")

この分割した配列も扱いやすいように LETで keywords と置きましょう。
では、この配列でどうやって AND検索をかけるか?
しかも配列の数(検索ワードの数)は1つだったり 5つだったりと 数が可変となってます。
複雑に考えがちですが、実はもうほぼ正解の一歩手前まできています!
FILTERの配列処理が適用されるので、あとは演算子をPRODUCT関数にするだけ!
ほぼ正解の一歩手前とはどういうことか?
まずは 先に 作成した FILTER + BYROWの式に、SPLIT関数で 得た 検索ワードの配列 keywords を入れたときの挙動をみてみましょう。
FILTER関数の 配列効果は FILTER内で使用している BYROW 内の LAMBDA内の COUNTIF の中にも適用されます。
つまり J2 に
=LET(keywords,SPLIT($J$1," "),
ARRAYFORMULA(COUNTIF(A2:H2,"*"&keywords&"*")))
こんな式を入れて 下にフィルしたものが 挙動イメージです。

J1に入れた "男 東京都" が 分割され
J列が各行の 「男」を含むセルの数
K列が各行の「東京都」を含む セルの数
となっています。
自動で横へスピる配列処理となってますね。
AND条件としたいので 両方1(0が無い)行、つまり オレンジ網掛けの行が「男 かつ 東京都 を含む」抽出対象となります。
このAND条件を得る方法として、演算子(乗算) * を使う方法があることは、FILTER関数シリーズの初回で触れました。
しかし、今回はキーワード数によって 配列が 2つだったり、4つだったりと変わります。
*(演算子) を使って 可変対応した式を書くのは厳しそう・・・。
というわけで PRODUCT関数 の出番です。
使ったことない人も多いかと思いますが、PRODUCT関数は SUM関数 の掛け算版と思ってください。

こんな感じで 範囲や配列を全部掛けた数を取得できます。
さきほどの 挙動を確認する 式に PRODCUTを追記すると

このようになり、FILTERの条件として使える 1列の 結果を得ることができました! これを先ほど作ったFILTER式に入れてみましょう。
=LET(data,A:H,
result,FILTER(data,BYROW(TO_TEXT(data),
LAMBDA(r,COUNTIF(r,"*"&J1&"*")))
+(SEQUENCE(ROWS(data))=1)),
IFERROR(VSTACK(ROWS(result)-1&"件がヒット",result)))
↓ SPLITした 配列を kewords と置いて PRODUCT関数で括ると
=LET(data,A:H,
keywords,SPLIT(J1," "),
result,FILTER(data,BYROW(TO_TEXT(data),
LAMBDA(r,PRODUCT(COUNTIF(r,"*"&keywords&"*"))))
+(SEQUENCE(ROWS(data))=1)),
IFERROR(VSTACK(ROWS(result)-1&"件がヒット",result)))
こんな式になりました。これが 回答となります。
まとめに入りましょう。
【回答】一つのセルに スペース区切りで入れた 複数ワードで、列指定なしの「含む」条件のAND検索をする式
回答の式 ↓
=LET(data,A:H,
keywords,SPLIT(J1," "),
result,FILTER(data,BYROW(TO_TEXT(data),
LAMBDA(r,PRODUCT(COUNTIF(r,"*"&keywords&"*"))))
+(SEQUENCE(ROWS(data))=1)),
IFERROR(VSTACK(ROWS(result)-1&"件がヒット",result)))
=LET(data,A:H,
keywords,SPLIT(J1," "),
result,FILTER(data,BYROW(TO_TEXT(data),
LAMBDA(r,PRODUCT(COUNTIF(r,"*"&keywords&"*"))))
+(SEQUENCE(ROWS(data))=1)
),
IFERROR(VSTACK(ROWS(result)-1&"件がヒット",result))
)
gif動画で動きを見てみましょう。

複数ワードで絞り込み出来てますね!!
表の構成によっては便利に使えるんじゃないでしょうか?
順を追って説明しながら 回答にたどり着きましたが、引っ張ったわりには 最後の部分(ラスボス)が 思ったより弱くて拍子抜けだったでしょうか?
実は mirも以前 は下に記述する別解の REDUCEの式でやってたんですが、色々試しているうちに
「別にREDUCEでループ処理いらなくね?」
って気づいたんですよね。
もちろん REDUCEを使う式でも出来ますが、処理の負荷と式の複雑さがグッと上がります。関数を知りすぎてるゆえにハマる罠と言えるかもしれませんw
【別解】REDUCE で FILTER結果を再度FILTERという処理を繰り返す
=LET(data,A:H,
keywords,SPLIT(J1," "),
result,REDUCE(data,keywords,
LAMBDA(pv,cv,
FILTER(pv,(SEQUENCE(ROWS(pv))=1)
+BYROW(pv,LAMBDA(r,COUNTIF(TO_TEXT(r),"*"&cv&"*")))))),
IFERROR(VSTACK(ROWS(result)-1&"件がヒット",result)))
REDUCE関数登場で、色々と式を試している時に思いついた式です。
何をやっているかというと、REDUCEのループ処理で keywords の配列分 FILTERを何度も繰り返すことで、AND条件として絞り込みをかけているわけです。
例えば "男 東京都 B" を入れた場合
1回目: A:H(pv) を "男"(cv) で絞り込み
↓
2回目: 1回目のFILTER結果(pv) を "東京都"(cv) で絞り込み
↓
3回目: 2回目のFILTER結果(pv) を "B"(cv) で絞り込み
こんな処理をやってます。 REDUCEの活用としては面白い事例なんですが、今回のケースではちょっと無駄が多いです。REDUCE内でさらにBYROWしてるわけなんで結構な処理回数かと。
自力の回答で こちらにたどり着いた人もいるかもしれませんね。
どうしても LAMBDAヘルパー関数が 便利すぎて(というか、ほぼそれで解決できるんで)、ついつい頼ってしまいがちですが、ケースによっては複雑化してしまいます。注意しましょう。
QUERYもいいけど FILTERもね!
全3回にわたって FILTER関数を取り上げてきました。
少年誌の展開っぽく、最初弱かった主人公が 徐々に修行や 強敵(ギリ倒せる)と戦い レベルを上げ、ラスボス(超応用問題)に挑む、みたいな構成にしてみましたが、いかがだったでしょうか?
もしかしたら、ちょっとした FILTER関数のお題だったら「止まってみえるぜ」と言えるくらいレベルアップしたかもしれませんねw (もしくは、「きかぬ、きかぬのだ」と涙を流しちゃうかも)
今回は FILTER関数 推しで 話を進めましたが、もちろん QUERY関数も最強なんで そのうち取り上げたいと思っています。
ただ ネット上は QUERY関数 推しのページが多くて、FILTER関数 の方がちょっと寂しい感じ。なんか 某グループの握手会の行列格差みたいな印象だったんで、マイノリティー好きの mirとしては 先にFILTER関数を取り上げてみました。
もしかすると 今後 FILTER関数に脚光があたったら、「FILTER関数も人気出て方向性変わっちゃったよねー。」と ウザい古参みたいなことを言い出すかもしれませんww
とりあえず FILTER関数の可能性を感じていただければ幸いです。
ケースに応じて QUERY関数と 使い分けできるようになりましょう!
さて、次回は 変化球的な 軽めのネタを挟んでから、その次は FILTERつながりで Googleスプレッドシートの フィルタ表示 機能 について書きたいと思います。
といいつつ、新機能の登場 や気分で 予定は変わるかもしれませんw
いいなと思ったら応援しよう!
