
大型補強のパドレスは2022年に地区優勝できるのか考えてみた。

こんにちは、みさわです。
今回はデータを使って遊んでみようということで、近年補強を重ねるMLB球団サンディエゴ・パドレスは2022年にナ・リーグ西地区で優勝できるのか簡単な検証をしてみました。
本稿は、私が最近受講したデータサイエンスアカデミーの講座のなかで自主課題として取り組んだ内容を改変したものです。データ分析に関する自身の最初のポートフォリオとして残しておきたいという理由で書いております。
前提知識レベル
前提として私の知識・スキルレベルは以下の通りです。
・知識:統計検定2級、JDLA G検定 合格くらい
・スキル:簡単な機械学習やディープラーニングのコードが書けるくらい
・MLBに関する知識:日本選手の所属チームがギリギリ分かるくらい
最後まで読んで頂ける方は、後半のほうでMLBに関する知識が致命的だったということがお分かり頂けると思います。
サンディエゴ・パドレスを分析対象とした理由
さて、ここから本編的なところに入っていきます。
まずサンディエゴ・パドレスを分析対象とした理由を説明致します。
サンディエゴ・パドレスとは、
・MLB ナ・リーグ西地区に所属する野球チーム(1969年創設)
・本拠地はカリフォルニア州サンディエゴ
・慢性的に資金力が枯渇しており、かつては若手育成を中心としたチームであった
・近年は積極的に大型補強を敢行
・成績は2011年頃~2019年までは地区最下位争いの常連
・2020年はCOVID-19影響により変則日程ではあったが、地区2位に躍進
・2021年シーズンよりダルビッシュ・有投手が移籍
近年思い切った補強を敢行しているということで、果たしてその効果はあるのか検証をしてみます。(2020年に既に地区2位に躍進していますが、試合数が少なかったため2020年成績は参考として捉えています。)
検証の流れ
大きな検証の流れとしては以下の通りです。
最終的には2019年の成績をもとに、2022年の成績を予測していきます。(本検証を開始した当初は未だ2021年シーズンが通常運営されるか不透明であったため2022年の予測とした。)

勝率を予測する「ピタゴラス勝率」は 得点の二乗 ÷ (得点の二乗+失点の二乗)で表される指標で、実際の勝率と強い相関関係にあると言われております。
また選手個人の成績予測はn年の成績をもとにn+3年の成績を単回帰式で予測していきますので、予測項目としては年度相関が高いとされる「本塁打」「四球」「三振」を選択しました。
また、これら3項目は偶然の要素により結果が生じる可能性が低く、選手の能力を適切に評価する項目と考えられており、これらを組み合わせた成績指標も開発されています。
使用データ
「Lahman's Baseball Database」というデータを使用させて頂きました。
1871年~最新年までのMLBの成績などがまとまったデータセットで、素晴らしい点は個人に一意のIDが振られており、表記の揺れや名寄せの対応が不要でテーブル結合等のデータ処理も簡単にできます。
こういったオープンデータが存在するあたりに、(野球に限らず)米国のデータリテラシーの高さを感じます。日本もこういった整備が今後進んでいくのだろうと思います。
さて、いよいよ検証に入っていきます。
勝率、得失点の予測式
・「ピタゴラス勝率」と「実際の勝率」の関係

相関係数 0.939ですので、MLBにおいてもピタゴラス勝率と実際に勝率は非常に強い相関関係にあると考えられます。ピタゴラス勝率をそのまま予測勝率としたいと思います。
・得点を算出する重回帰式

偏回帰係数の正負はイメージ通りですし、決定係数もそれなりに高く、得点を説明できそうです。解釈で注意が必要かなと思うのは定数項の部分で、その他にも説明変数はあると考えられますので、その影響が一律となってしまっていると捉えられます。
・失点を算出する重回帰式

こちらも得点の重回帰式に近しい結果となり、同様に定数項の解釈には注意が必要と考えれます。(ちなみに、実は得失点とも説明変数のVIFが高かったのは内緒の話。)
個人成績予測モデリング
・個人成績予測の方法
各成績項目を打数(野手) or 対戦打者数(投手)で割って規格化し、n+3年の規格化成績を目的変数、n年の規格化成績を説明変数としてn年の年齢別に単回帰式を取得していきます。
・精度評価の方法
得られた単回帰式を用いて、2016年の成績をもとに2019年の成績を予測し、実際の2019年の成績との相関分析により精度評価します。
<野手の3年後成績予測モデル>
・予測モデル

相関係数で0.6~0.8程度、三振は他項目に比べてやや相関が高いです。
・精度検証

訓練用データで得られた相関係数に近しいですが、特に本塁打は年齢によっては相関係数低いです。
<投手の3年後成績予測モデル>
・予測モデル
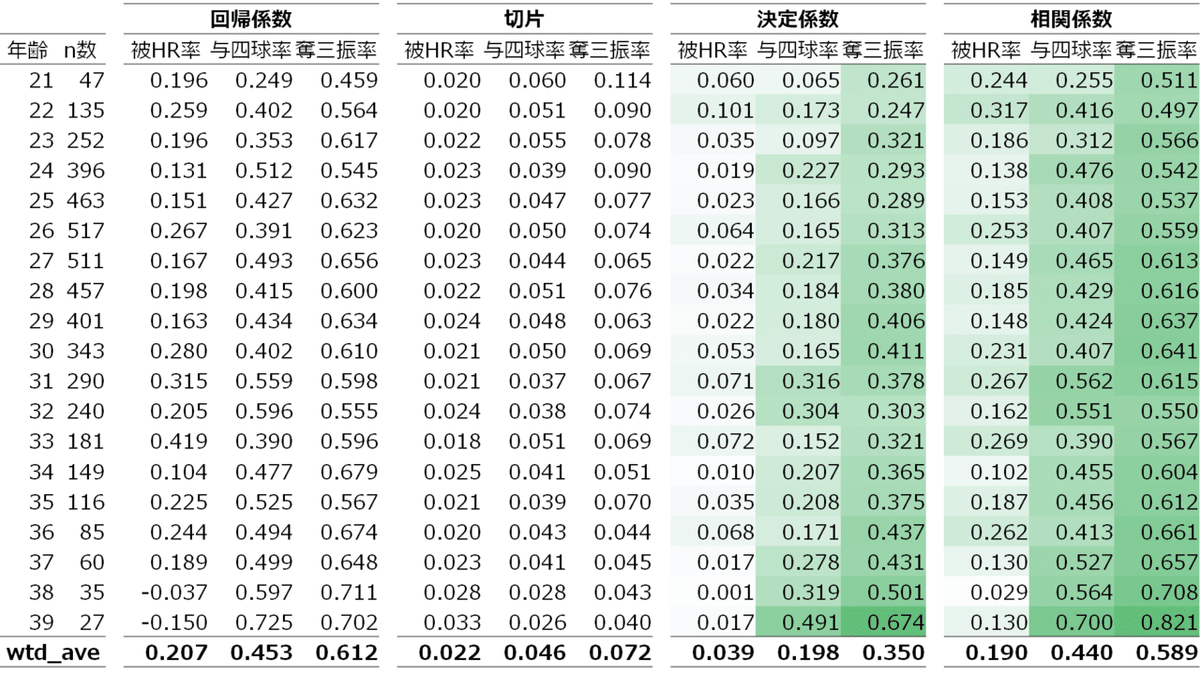
野手のモデルに比べて相関係数が低いです。
・精度検証

相関係数がマイナスになっている年齢もあり、正直、予測モデルとして使うには無理があると思います。
年度相関が高い項目とはいえ、3年後成績を単回帰で説明するのはやはり無理がありそうです。本来であればここで、少なくとも投手成績については他の説明変数を探して精度を上げていく必要がありますが、今回はこのまま続けさせて頂きたいと思います。(本来はここで立ち止まらないといけないと認識しております。)
サンディエゴ・パドレスの2022年成績予測
上段で得られた単回帰式(本来使えないものも混じっている)を用いて、2019年の個人成績からパドレスの2022年成績を予測していきます。
予測にあたっての前提は以下の通りです。
・移籍情報は把握できた限りで反映
・選手ごとの打席数、対戦打者数はポジション等を考慮して「決め」で設定
(レギュラーはこの人だろう、的なイメージです)
・2022年パドレス勝率予測

2022年は2019年より0.130勝率が上がる予測です。勝率予測のもとになっている、得点と失点を見ていきます。
・2022年パドレス得点予測

得点は2019年に対して76点増える予測です。本塁打は減るものの、四球増と三振減により得点力は向上する見込みです。
・2022年パドレス失点予測

失点は2019年に対して62点減る予測です。特に奪三振数が増えそうです。
次にこれらの得失点の増減が生じる要因を見ていきます。
・ポジション別打撃成績予測

表の見方を説明致します。
得点力を計る指標として、前段の得点重回帰式の偏回帰係数と各成績を掛け合わせた「得点変位予測値」を設定し、ポジション別に2019年と2022年の得点変位予測値の差を見ています。(2019年も上記考え方で算出した値ですので、先ほどの得点差とは一致しません。)
見て頂いて分かる通り、ポジション別の打席数は2019年と同一として設定しています。そのうえで、チーム全体はキャッチャーとショートが牽引して得点力が上がる見込みですが、外野手の得点力は下がる見込みです。
・キャッチャー、ショート、外野手の個人打撃成績予測

ここでMLBに詳しい人が見ると、予測の適当さがバレてしまいそうですね。ただ、変化のポイントとしてはそれほど外してはないかと思っています。(「この起用の考え方はないだろ」というご意見も是非頂ければと思います。)
・先発投手の個人投球成績予測

先ほどの野手同様、ここでMLBに関する知識の無さ、予測の適当さがバレてしまいそうです。このあたりの「決め」の精度はご意見あるところとは思いますが、先発投手陣を大型補強しており、彼らが失点減少を牽引していくという予測自体は皆さん納得ではないでしょうか。
2022年サンディエゴ・パドレス地区優勝可能性検証
いよいよ本編ラスト、先ほどのチーム成績予測をもとに地区優勝可能性を検証していきます。
・過去20年間のナ・リーグ西地区優勝チームとの勝率比較
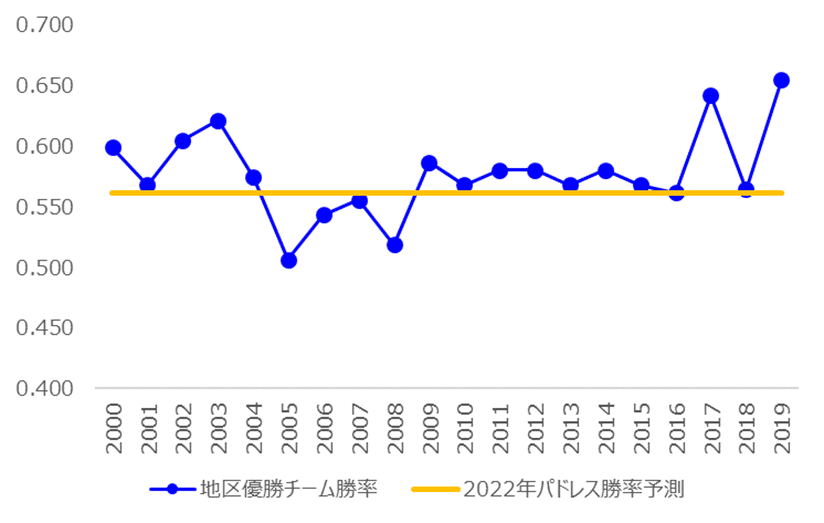
優勝争いはしそうだけど、、、といった感じでしょうか。笑
2017年、2019年はドジャースが圧倒的な成績で地区優勝しており、2022年もドジャースとの勝負になりそうだなという印象です。
・過去20年間のナ・リーグ西地区優勝チームとの得点比較

得点力は過去の優勝チームと比較しても高いと言えそうです。
・過去20年間のナ・リーグ西地区優勝チームとの失点比較

一方で、失点は過去の優勝チームと比較して高くなりそうです。あれだけ強力な先発投手陣を補強しても足りないということでしょうか。
個人的には投手陣はかなり補強したなという印象なので、この先、外野手の再編に入るのではという気がしております。
2020年は地区2位であったパドレスが2021年シーズンはブレイク・スネル投手やダルビッシュ・有投手を補強し、ドジャースを中心とした強敵揃いのナ・リーグ西地区においてどんな成績を収めるのか、また2022年に向けてはどんな編成をしていくのか、今後注目していきたいと思います。
本編は以上になります。ここまで読んで頂いた方、ありがとうございました。
余談:私がデータ分析を学ぶ理由と学習ステップ
ここから先は本編とは関係なく、私がデータサイエンスを学んでいる理由と、その学習ステップを書こうと思います。データサイエンス学んでみようかなと思っている人に少しでも参考になればいいなと思っております。
・データサイエンスを学ぶ理由
私自身はデータサイエンティストを目指しているわけではありません。なぜならその道の凄腕の方たちと勝負できる気は全くしないからです。ただ、実際のビジネスの現場ではそのビジネスに関するドメイン知識とデータサイエンスの掛け合わせがより良い成果につながると考えているので、ビジネスとデータサイエンスをつなげられる機能を持った人間になりたいと思っています。
そのうえで、ビジネスのドメイン知識はその業界で能動的に働いていれば自ずと身につくと考えているので、データサイエンスのほうを自分で時間を割いて学んでいます。
本稿を書いた理由は、最初のポートフォリオとして残しておきたかったからでありますが、その背景には実務チャンスを掴みたいとい気持ちがあります。データ活用やその組織の重要性は高まっており、企業も優秀な人材を獲得しようとしますが専門性の高い人材は高単価で奪い合いの状態です。従い、内製で育てる方向に動きだす企業が今後増えてくると予想しています。こういった投稿を残しておくことは、内製での育成を前提とした人材募集に応募する際のアピール材料になると思っています。
データサイエンスを学ぶには実務経験を積むのが一番手っ取り早いと思いますが、未経験者は実務を担当させてもらうまでが大変なので、その過程の参考になればと考えています。
・データサイエンスを学んでいるステップ
①統計検定2級、G検定で基礎知識を学ぶ
統計検定は統計の基礎、G検定は機械学習やディープラーニングの概念が掴めます。また、統計検定2級をとっていると社内で「統計分析、少しならできます!」と声を上げやすい気がします。
②書籍、webサービスでコーディングの基礎を学ぶ
このあたりに関しては、私は中川伸一さんのnoteをとても参考にさせて頂きました。
③スクールで実践に近い部分を学ぶ
書籍やwebサービスがいくら充実しているといっても、メンターもつけずに完全独学では限界があると思います。私は冒頭にも書いた通り、データサイエンスアカデミーで実際のデータ分析のプロセスを学びました。
高額ですが専門実践教育訓練給付金を使うと20万円程度で受講できます。この分野、政府も今後の重要分野と位置づけていますので、ほかにも給付金のある講座は沢山あります。
データ分析領域で投稿するのは専門性の高い人が多く敷居が高い感じがしますが、同じくらい(初心者に毛が生えるか生えないかくらい)のレベルの方の投稿が増えると良いなと思っております。
以上、本当に最後までお読み頂いた皆様、誠にありがとうございました。