
PaLM 2で自社データを使ったチャットボット開発

前回の記事「ChatGPT+PineconeでSlackbotを作ってみた」では、Pinecone+ChatGPTを使ったSlackBotの構築について書きました。今回は、Google Cloud上のツール群を使ったチャットボットの構築をしてみました。ゴールは、前回よりも一般的な利用シーンを想定できるようなプロトタイプの構築です。スピード重視&トライ&エラーを繰り返しながら作ったため、今後改良・修正が必要な部分もありますが、参考まで(😅)
プロダクトの概要
概念図&フロー
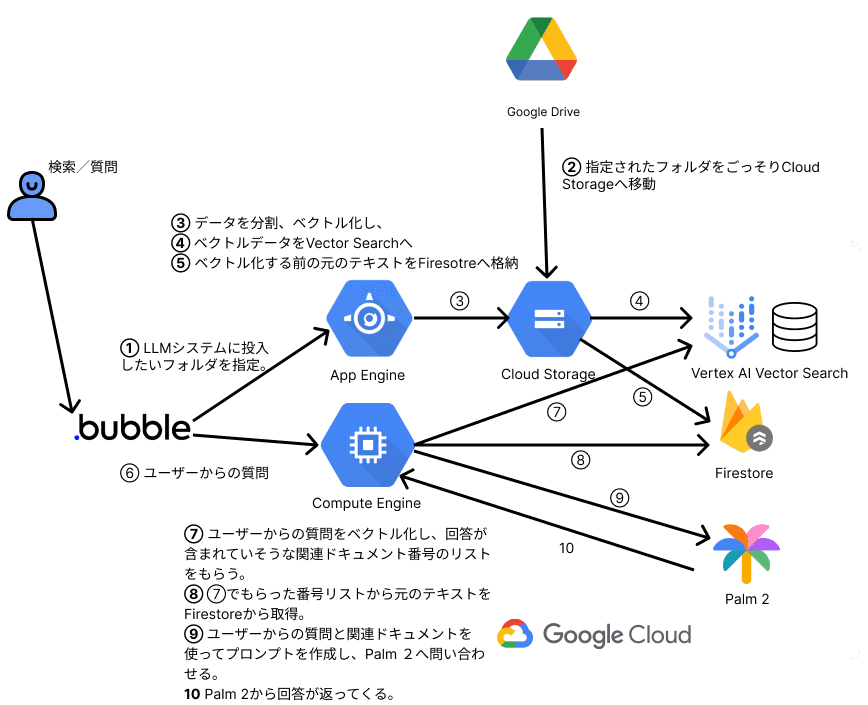
ユーザーインタフェース
以下にBubbleで作成したユーザーインタフェース画面を紹介します。
① Google Driveへの認証とフォルダリストの取得
上記画面のConnect with Googleをクリックすると、Google OAuth2.0のサインイン画面が開きます。サインインが完了すると次のフォルダ選択画面へ移行します。
② フォルダーの選択
Google Drive上でユーザーがアクセス可能なフォルダの一覧が表示されます。フォルダを指定すると、そのフォルダ直下にあるファイル群(今回は、Google Docsのみ対応)の処理がバックグラウンドで開始されます。

③ チャットインタフェース
バックエンドの処理が完了すると、ユーザーからの質問に読み込まれたデータのみを利用して回答を行うチャットの出来上がりです。

使ったツール群
Google Vertex AI Vector Search (元 Vertex AI Matching Engine)
ユーザーからの質問への回答が含まれていそうなドキュメントを検索するためのベクトルデータベースです。
Googleが開発した大規模言語モデル
Google Drive
Vertex AIに投入する元のドキュメントが格納されています。
Google Driveのドキュメントを処理するために一旦ドキュメントを格納します。
元のドキュメントのテキストを格納しておくデータベースです。
ドキュメントやユーザーからの質問の数値化(ベクトル化)に利用しました。
BubbleからAPIで呼び出されるPythonコードを実行。
BubbleからAPIで呼び出されるPythonコードを実行その2。
TensorflowをAppEngine上で動かすことができなかったので、ユーザーからの質問を受けてPaLM 2へリクエストを送信するPythonコードなどをComputeEngine上で実行しました。
ユーザーが利用するWEB画面を作成するに利用。
構築手順
1.Bubbleを使ってUIを作成
2.Bubbleから呼び出すAPIをPythonで開発
Bubbleを使うと、Pythonで書いたAPIプログラムを呼び出してプログラムからの戻り値を画面上に表示するようなワークフローをノーコードで設定することができます。
3.データをチャンキング
今回は、ファイル形式として、Google Docsのみを対象としました。Google DocsをテキストファイルとしてGoogle Cloud Storageへ移動した後、テキストファイルを最適な情報単位にチャンキング(分割)します。
幸い今回処理したファイルの記述が、
タイトル1
・ポイント1
・ポイント2
・….
タイトル2
・ポイント1
・ポイント2
・….
といった感じで、情報単位を特定しやすい形式になっていましたので、タイトル+ポイントを1つのチャンクとしました。
4.Vertex Vector Searchでベクトルデータベースを構築
チャンクをベクトル化(embedding)して、Vertex Searchへ格納します。
まずは、indexの作成。大文字の部分は利用する環境によって変わってきます。
from google.cloud import aiplatform
# aiplatformを初期化
aiplatform.init(project=GCP_PROJECT_ID, location=REGION, staging_bucket=BUCKET_NAME)
#インデックスの作成
tree_ah_index = aiplatform.MatchingEngineIndex.create_tree_ah_index(
display_name= DISPANY_NAME,
contents_delta_uri=f"{BUCKET_NAME}/{FOLDER_NAME}",
dimensions=100,
approximate_neighbors_count=150,
distance_measure_type="DOT_PRODUCT_DISTANCE",
leaf_node_embedding_count=500,
leaf_nodes_to_search_percent=7,
description="Glove 100 ANN index",
labels={"label_name": "label_value"},
)
#インデックスのアクセスに利用するエンドポイントの作成
#今回はパブリックで作成
my_index_endpoint = aiplatform.MatchingEngineIndexEndpoint.create(
display_name=f"{DISPLAY_NAME}-endpoint",
public_endpoint_enabled=True,
)この時に注意するポイントは、
① Google Cloud StorageのREGIONは、Vertex AIと同じリージョンである必要がある。私は、us-central1を利用しました。
② 構築する時点で最初に読み込ませるデータを準備しておく必要があり、それをcontents_delta_uriで指定しておく。
データフォーマットは、以下のようなJsonチックな形式です。idはユニークである必要(同じidだと上書きされる)があり、embeddingの値にベクトル化されたデータの配列が続きます。(実際にはベクトル値の配列はかなり長くなります)
{"id": "1001", "embedding": [-0.05698372423648834, 0.013907813467085361, -0.021290313452482224]}③ ベクトルデータベースのベクトル化は、なぜか text-bison@001でembeddingすると読み取り時にエラーが出てしまうので、universal-sentence-encoder-multilingualを利用。
④作成したインデックスへの接続
以下のPROJECT-NAMEは、
projects/PROJECT_NUMBER/locations/REGION/indexEndpoints/INDEXENDPOINT_ID
で作ります。なぜか、indexEndpointsのEは大文字です。。。
from google.cloud.aiplatform.matching_engine.matching_engine_index_endpoint import MatchingEngineIndexEndpoint
my_index_endpoint=MatchingEngineIndexEndpoint(index_endpoint_name=PROJECT_NAME)
⑤インデックスの更新
contents_delta_uriで指定したフォルダに追加・更新したいベクトルデータが入ったファイルを保存しておきます。
tree_ah_index = aiplatform.MatchingEngineIndex(index_name=INDEX_NAME)
tree_ah_index = tree_ah_index.update_embeddings(
contents_delta_uri=f"{BUCKET_NAME}/{DIRECOTRY_NAME}",
)⑥インデックスの作成・更新には30分くらい掛かりました。
5.Firestoreに元のデータを格納
ドキュメントの格納単位(チャンク)は、Vector Searchと同一にしておく必要があります。例えば、「私の名前は安田です」という一行だけのチャンクがあった場合、これをベクトル化し番号("id")を付与します。それと同じ番号を付けて元のテキストをFirestoreに格納します。
Vertex Search内のデータは小数点の数字となりますので、関連のあるチャンクの元テキストが必要なときは、Firestoreから取得できます。
6.ユーザーの質問に回答するPythonコードを開発
コードの手順は、
① ユーザーからの質問をベクトル化してVector Searchへ問い合わせ。
② 関連のあるチャンク番号を取得。
③ ②のチャンクのテキストデータをFirestoreから取得。
④ ③の関連テキスト群とユーザーの質問からプロンプトを作成してPaLM 2へ問い合わせ。
⑤ ④の結果をユーザー(BubbleのUI)へ返す。
#各種初期化処理
module_url = "https://tfhub.dev/google/universal-sentence-encoder-multilingual/3"
model = hub.load(module_url)
db = firestore.Client(project=GCP_PROJECT_ID)
#PaLM 2のパラメーターの設定
parameters = {"temperature": 0.3, "max_output_tokens": 1024, "top_p": 0.95, "top_k": 40}
#ユーザーからの質問をベクトル化
question = request.args.get("q")
embeddings = model([question])
query = [[float(x) for x in list(embeddings.numpy()[0])]]
#質問の内容に近いチャンクをVector Searchで検索
neighbors = my_index_endpoint.find_neighbors(
deployed_index_id=INDEX_ID',
queries=query,
num_neighbors=5
)
#Vector Searchからの戻り値であるID番号のテキストをFirebaseから取得
ids = [item.id for sublist in neighbors for item in sublist]
chunks = ''
for id in ids:
doc_ref = db.collection(COLLECTION_NAME).document(id)
doc = doc_ref.get()
if (doc.exists):
content = doc.to_dict()
chunks = chunks + content.get(CONTENT)
get_keyword_prompt = f"""以下のドキュメントから質問に回答してください:
質問:
{question}
ドキュメント:
{chunks}
"""
answer = model2.predict(get_keyword_prompt, **parameters)
r={
"return":{
"answer": answer.text
}
}
return jsonify(r)What's next?
① 今回やってみて改めて思ったのは、ちゃんとしたプロダクトを作る難しさです。今はまだプロトタイプで社内で使っているだけですが、誰でも使えるプロダクトまで昇華させるためには、セキュリティや例外処理に加えて、データベースとの接続などの初期化処理の最適化、そしてユーザーのドキュメントの種類・内容にベストなチャンキング方法の自動選択、プロンプトのカスタイマイズなどなど、考えないといけないことが山ほどありますね。
② PaLM 2 -> 専用LLM
今回のように自社のデータを使ってLLMを使う上で一番気になる点は、プロンプトに自社のデータが入ってしまうので、オープンなLLMではなく、自社専用のLLMを使いたいというものです。今後、クラウド上にオープンソースLLMをインストールするシステムも検討したいと思います。
③ 取り込める情報元の多様化
前回はAirtable、今回は、Google Drive上のGoogle Docsの読み込みを行いましたが、他のSaaSやファイル形式への対応は必須ですね。今、Confluenceのデータ取得をやってみています。
④ データパイプライン
実は、今回のシステムでは、インデックスの作成と更新は、Colabからマニュアルでやっています。ユーザーのSaaSやクラウドストレージからのデータの取り込み、インデックスの作成と元データに更新・追加・削除があった場合のインデックスとFirestoreの更新の自動化を行なっていくには、データパイプラインを構築しないとですね。
今回のレポートは以上となります!