
Windows環境で、Llama.cppを用いてローカルLLMを動作させてみた

本記事は、2024年1/27にて行われた配信にて、視聴者様とともに試行錯誤しながら、Llama.cppを実行した手段をまとめた記事となります。
下記配信は雑談ベースでローカルLLMの話をしていますので是非視聴してみてください。
配信内容:
「AITuberについて」
「なぜか自作PCの話」
「Janってどうなの?」
「実際にJanを動かしてみる」
「LLama.cppってどうなの?」
「実際にLlama.cppを動かしてみる」
1.概要
この記事では、Llama.cppを用いて、ローカルLLM(Large Language Model)を実行する方法について紹介します。
Llama.cppは、自然言語処理に特化した高性能なライブラリであり、ユーザーが簡単に大規模な言語モデルを利用できるように設計されています。
このプロセスは比較的簡単で、複雑な設定や長いコマンドラインの操作は不要です。以下のステップに従って、視覚的なインターフェース(GUI)を通じてLlama.cppのserver.exeを実行し、ローカルLLMを活用する方法を説明します。

2.インストール
2A.環境整備
2A-1.Cuda ToolKitがインストールされているか確認する。
PowerShell等で、「nvcc --version」を実行し、自分のPCにCudaがインストールされているか、インストールされている場合バージョンが何かを確認します。

2A-1A. Cudaがインストールされていない場合、
「nvcc --version」にて、バージョン情報が表示されない場合、対応Cudaバージョン(12.2.0 or 11.7.1)をインストールしてください。(2024年1月29日時点)
cu12.2.0の場合
cu11.7.1の場合
なお、最新の12.3でも動作しました。
2A-1B. Cudaがインストールされている場合、
バージョン情報を確認してください。

バージョンが、12.2.0 または11.7.1ではない場合(12.3でも動作しました)、上記Cudaリンクよりダウンロードインストールしてください。
2B.llama.cppをインストールする
以下リンクより、対応したzipファイルをダウンロードします。
現行の最新バージョンは、b1988です。(2024年1月29日時点)
Cuda12.2.0の場合、「llama-b1988-bin-win-cublas-cu12.2.0-x64.zip」を、Cuda11.7.1の場合、「llama-b1988-bin-win-cublas-cu11.7.1-x64.zip」をダウンロードしてください。
ダウンロード後、解凍しておきます。
3.Llama.cppを動作させる
https://github.com/ggerganov/llama.cpp/blob/master/examples/server/README.md
3A.LLMローカルモデルを準備する
サイバーエージェント社が配布している、Calm2にてテストを行います。
LLama.CPPを動作させるには、ggufモデルを準備する必要があるため、Calm2をGGUFに変換したモデルをダウンロードします。
TheBlokeさんが配布しているggufモデルをダウンロードします。
今回は、「calm2-7b-chat.Q4_0.gguf」をダウンロードしました。
ダウンロードした、ggufは、先ほど解凍したLlama.cppのzipファイル内に移動させておきます。
3B.Server.exeを動作させる
Server.exeを動作させるには、コマンドラインにて入力する必要があります。解凍したZipディレクトリ内にて、PowerShellやコマンドプロンプトを起動させ、以下のコマンドを入力します。("calm2-7b-chat.Q5_0.gguf"は、ダウンロードしたggufファイル名を設定します)
.\server.exe --model "calm2-7b-chat.Q5_0.gguf" -ngl 99
上記コマンドを入力し、Enterを押します。
その際、DLLエラーが表示される場合は、Cudaが正しくインストールされていないまたは、正しいバージョンがインストールされていない可能性があります。
問題なく起動すれば以下のように表示されます。
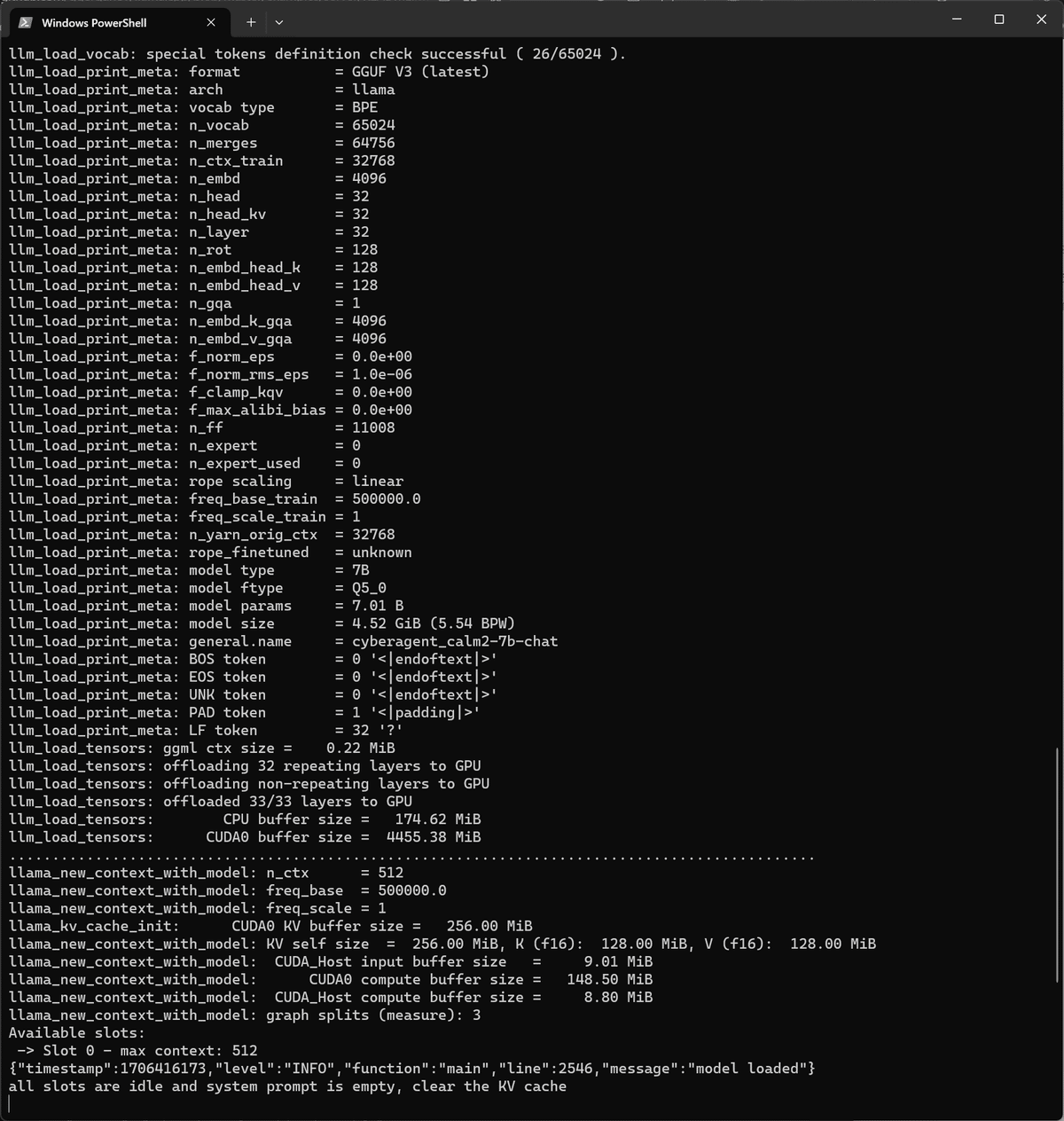
GUIにアクセスします。
デフォルトURLは、「http://127.0.0.1:8080/」であり、ブラウザを起動して該当URLを入力してGUIを表示させます。
問題がなければ以下のように表示されます。

4.LLMモデルに問合せを行う
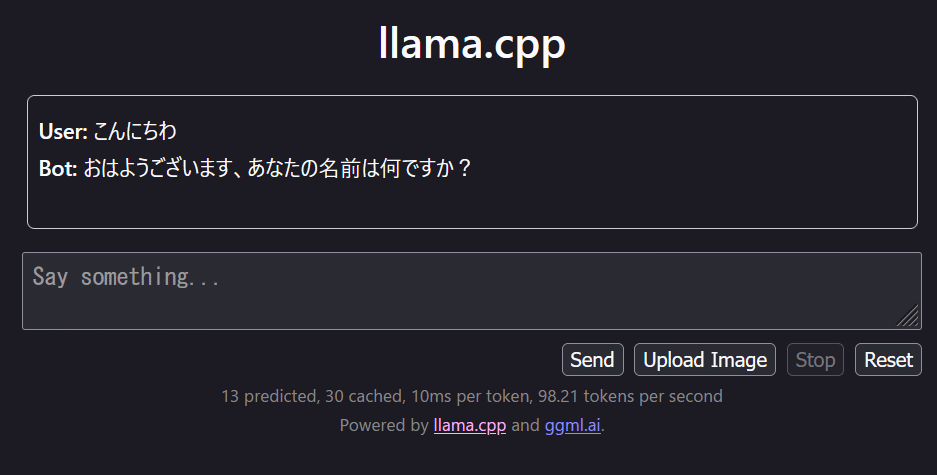
表示されているGUIに問合せ情報を入力します。以下のような適当なデータを入力しましょう。
GUIおけるPromptは、GPTにおけるSystemPromptを指し、GPTにおけるUserPromptは Say something..の部分に入力を行います。

入力後、Sendを行うことでChatが始まります。
Llama.cppを用いたローカルモデル動作手段は以上です。
導入したローカルモデルと対話して遊びましょう!

99.おまけ
99A.Server.exeコマンドライン一覧
この例では、簡単なHTTP APIサーバーと、llama.cppと対話するためのシンプルなWebフロントエンドを示しています。
コマンドライン一覧:
--threads N, -t N: 生成中に使用するスレッドの数を設定します。
-tb N, --threads-batch N: バッチ処理およびプロンプト処理に使用するスレッドの数を設定します。指定されていない場合、スレッド数は生成用に使用されるスレッド数に設定されます。
-m FNAME, --model FNAME: LLaMAモデルファイルへのパスを指定します(例: models/7B/ggml-model.gguf)。
-a ALIAS, --alias ALIAS: モデルのエイリアスを設定します。このエイリアスはAPIレスポンスで返されます。
-c N, --ctx-size N: プロンプトコンテキストのサイズを設定します。デフォルトは512ですが、LLaMAモデルは2048のコンテキストで構築されており、これにより長い入力/推論に対してより良い結果が得られます。他のモデルではサイズが異なる場合があります。例えば、baichuanモデルは4096のコンテキストで構築されています。
-ngl N, --n-gpu-layers N: 適切なサポート(現在はCLBlastまたはcuBLAS)でコンパイルされている場合、このオプションを使うことで、いくつかのレイヤーをGPUにオフロードして計算させることができます。一般的にパフォーマンスが向上します。
-mg i, --main-gpu i: 複数のGPUを使用する場合、このオプションでどのGPUを使用するかを制御します。これは、計算をすべてのGPUで分割するオーバーヘッドが割に合わない小さなテンソル用です。該当するGPUは一時的な結果用のスクラッチバッファを保存するために少し多くのVRAMを使用します。デフォルトではGPU 0が使用されます。cuBLASが必要です。
-ts SPLIT, --tensor-split SPLIT: 複数のGPUを使用する場合、このオプションで大きなテンソルをすべてのGPUでどのように分割するかを制御します。SPLITはコンマで区切られた非負の値のリストで、それぞれのGPUがどの比率でデータを受け取るかを順番に指定します。例えば、「3,2」はデータの60%をGPU 0に、40%をGPU 1に割り当てます。デフォルトではデータはVRAMに比例して分割されますが、これがパフォーマンスにとって最適とは限りません。cuBLASが必要です。
-b N, --batch-size N: プロンプト処理のバッチサイズを設定します。デフォルト: 512。
--memory-f32: メモリキー+値のために16ビットの浮動小数点数の代わりに32ビットの浮動小数点数を使用します。推奨されません。
--mlock: モデルをメモリにロックし、メモリマップされたときにスワップアウトされるのを防ぎます。
--no-mmap: モデルをメモリマップしないでください。デフォルトでは、モデルはメモリにマップされ、システムは必要に応じてモデルの必要な部分のみをロードします。
--numa: 一部のNUMAシステムで役立つ最適化を試みます。
--lora FNAME: モデルにLoRA(Low-Rank Adaptation)アダプターを適用します(--no-mmapを暗示)。これにより、事前トレーニングされたモデルを特定のタスクやドメインに適応させることができます。
--lora-base FNAME: LoRAアダプターで修正されたレイヤーのベースとして使用するオプショナルモデル。このフラグは--loraフラグと連動して使用され、適応のためのベースモデルを指定します。
-to N, --timeout N: サーバーの読み書きタイムアウト(秒)。デフォルト600。
--host: リッスンするホスト名またはIPアドレスを設定します。デフォルトは127.0.0.1。
--port: リッスンするポートを設定します。デフォルト: 8080。
--path: 静的ファイルを提供するパス(デフォルトはexamples/server/public)
--api-key: リクエスト認証のためのAPIキーを設定します。デフォルトでは、サーバーはすべてのリクエストに応答します。APIキーを設定すると、リクエストにはAPIキーをBearerトークンとして設定したAuthorizationヘッダーが必要になります。複数の有効なキーを有効にするために複数回使用することができます。
--api-key-file: 改行で区切られたAPIキーが含まれるファイルへのパス。設定されている場合、リクエストにはアクセスのためのキーのいずれかが含まれている必要があります。--api-keyと併用することができます。
--embedding: 埋め込み抽出を有効にする。デフォルト:disabled
-np N, --parallel N: リクエストの処理スロットの数を設定します(デフォルト: 1)
-cb, --cont-batching: 連続バッチング(別名動的バッチング)を有効にする(デフォルト:無効)
-spf FNAME, --system-prompt-file FNAME: 「システムプロンプト(すべてのスロットの初期プロンプト)」を読み込むためのファイルを設定します。これは、チャットアプリケーションなどで便利です。詳細はこちら
--mmproj MMPROJ_FILE: LLaVA用のマルチモーダルプロジェクターファイルへのパス。
--grp-attn-n: セルフエクステンド(デフォルト:1=無効)によってコンテキストのサイズを拡張するグループアテンションファクターを設定する。 --grp-attn-w
--grp-attn-w: 自己拡張(デフォルト: 512)によってコンテキストのサイズを拡張するために、グループ注目幅を設定する。--grp-attn-n