
Grounded-Segment-Anything(Grounded SAM)をWindows11+WLS2+Anacondaで試す

1.Grounded-Segment-Anythingとは、
テキスト入力に基づいてあらゆる物体を検出し、セグメンテーションを行うことができる視覚AIシステム。
このシステムは、Grounding DINOとSegment Anythingを組み合わせることで、オープンワールドのシナリオにおいて多様な視覚タスクを実行する能力を持っています。
ユーザーがテキストで対象物を指定すると、システムはその物体を画像内で特定し、精密にセグメンテーションを行います。
さらに、このシステムは物体追跡にも対応しており、動画内の対象物を継続的に検出・セグメンテーションすることができます。
2.インストール(Docker)
こちらの方法は試していなのでgitリンクを参考にしてください。
1.レポジトリーをクローンします
2.コンテナを作成・実行する
cd Grounded-Segment-Anything
docker build -t grounded-segment-anything .
docker run -it --gpus all -v ${PWD}:/workspace grounded-segment-anything2'.インストール
1:システム要件
Python 3.8以上
PyTorch 1.7以上
TorchVision 0.8以上
上記システム要件よりpython3.11でanaconda環境を作成しました。
2:Windows側の準備
NVIDIAのWindows Driverをインストール
以下リンク先から対応ドライバーをインストール(Download Type はSD推奨)
WSLのインストール
パワーシェルで以下のコマンドを実行しインストールします。
その後ログインID等を設定し起動します。
wsl --install3:Anaconda環境の準備
上記リンクより最新のLinux-x86_64.shを取得しダウンロード・インストール
インストール時、規約確認はqでスキップできますYes入力でインストールを行ってください。
mkdir download
cd download
wget https://repo.anaconda.com/archive/Anaconda3-2024.06-1-Linux-x86_64.sh
bash Anaconda3-2024.06-1-Linux-x86_64.shCondaのパスを通す
$ echo "export PATH=~/anaconda3/bin:\$PATH" >> ~/.bashrc
$ source ~/.bashrc以下のコードでcondaバージョンを確認できます
$ conda -V仮想環境の作成
conda create -n GSAM python=3.11
conda activate GSAM4:Ubuntu のアップデート
sudo apt update
sudo apt upgrade5:CUDAリポジトリをシステムに追加
$ sudo apt-key del 7fa2af80
$ sudo apt install build-essential
$ wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-wsl-ubuntu.pin
$ sudo mv cuda-wsl-ubuntu.pin /etc/apt/preferences.d/cuda-repository-pin-600https://developer.download.nvidia.com/compute/cuda/12.1.1/local_installers/cuda-repo-wsl-ubuntu-12-1-local_12.1.1-1_amd64.deb
は自分の希望バージョンを選択のこと。以下は12.1.1を選択(OSX利用の場合11.8が推奨と思われる)
12.1.1
wget https://developer.download.nvidia.com/compute/cuda/12.1.1/local_installers/cuda-repo-wsl-ubuntu-12-1-local_12.1.1-1_amd64.deb
sudo dpkg -i cuda-repo-wsl-ubuntu-12-1-local_12.1.1-1_amd64.deb
sudo cp /var/cuda-repo-wsl-ubuntu-12-1-local/cuda-*-keyring.gpg /usr/share/keyrings/12.2
# CUDA 12.2 のインストーラをダウンロード
wget https://developer.download.nvidia.com/compute/cuda/12.2.0/local_installers/cuda-repo-wsl-ubuntu-12-2-local_12.2.0-1_amd64.deb
# デビアンパッケージをインストール
sudo dpkg -i cuda-repo-wsl-ubuntu-12-2-local_12.2.0-1_amd64.deb
# キーリングをコピー
sudo cp /var/cuda-repo-wsl-ubuntu-12-2-local/cuda-*-keyring.gpg /usr/share/keyrings/6:CUDAをインストール:
sudo apt update
sudo apt install cudaCudaのインストールを確認する
画像のようにバージョンが表示されればOK
nvcc --version
7:パスの設定
export AM_I_DOCKER=False
export BUILD_WITH_CUDA=True
echo 'export CUDA_HOME=/usr/local/cuda-12.1' >> ~/.bashrc
echo 'export PATH=$PATH:$CUDA_HOME/bin' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$CUDA_HOME/lib64' >> ~/.bashrc
# 設定を反映
source ~/.bashrc
conda activate GSAMパスの確認
echo $CUDA_HOME8:レポジトリのクローン
git clone https://github.com/IDEA-Research/Grounded-Segment-Anything.git
cd Grounded-Segment-Anything9:Pytorchのインストール
上記リンクより、自分のCUDAに対応したCommandをコピーペースト
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia10:各種コンポーネントのインストール
python -m pip install -e segment_anything
pip install --no-build-isolation -e GroundingDINO
pip install --upgrade diffusers[torch]11:OSXのインストール
OSXインストール時、「mmcv-full」が必要となるため事前インストールしてからOSXをインストールする
mmcvのインストール
pip install -U openmim
mim install mmcv-fullpip install mmcv-full
git submodule update --init --recursive
cd grounded-sam-osx && bash install.shしかし、Cudaバージョンによっては、以下のようなエラーが発生するようです。私の環境では、OSXはインストールできませんでした。

参考
12: RAM & Tag2Textのインストール
git clone https://github.com/xinyu1205/recognize-anything.git
pip install -r ./recognize-anything/requirements.txt
pip install -e ./recognize-anything/以下のようなエラーが発生する場合、

以下のコードを実行してsetuptoolsをインストールしてください
pip install --upgrade setuptools13:その他必要パッケージインストール
pip install opencv-python pycocotools matplotlib onnxruntime onnx ipykernel3.Grounding DINO デモを実行
1:重みのダウンロード
cd Grounded-Segment-Anything
wget https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth2:Demoの実行
python grounding_dino_demo.py実行すると、「annotated_image.jpg」の認識画像が生成されます。

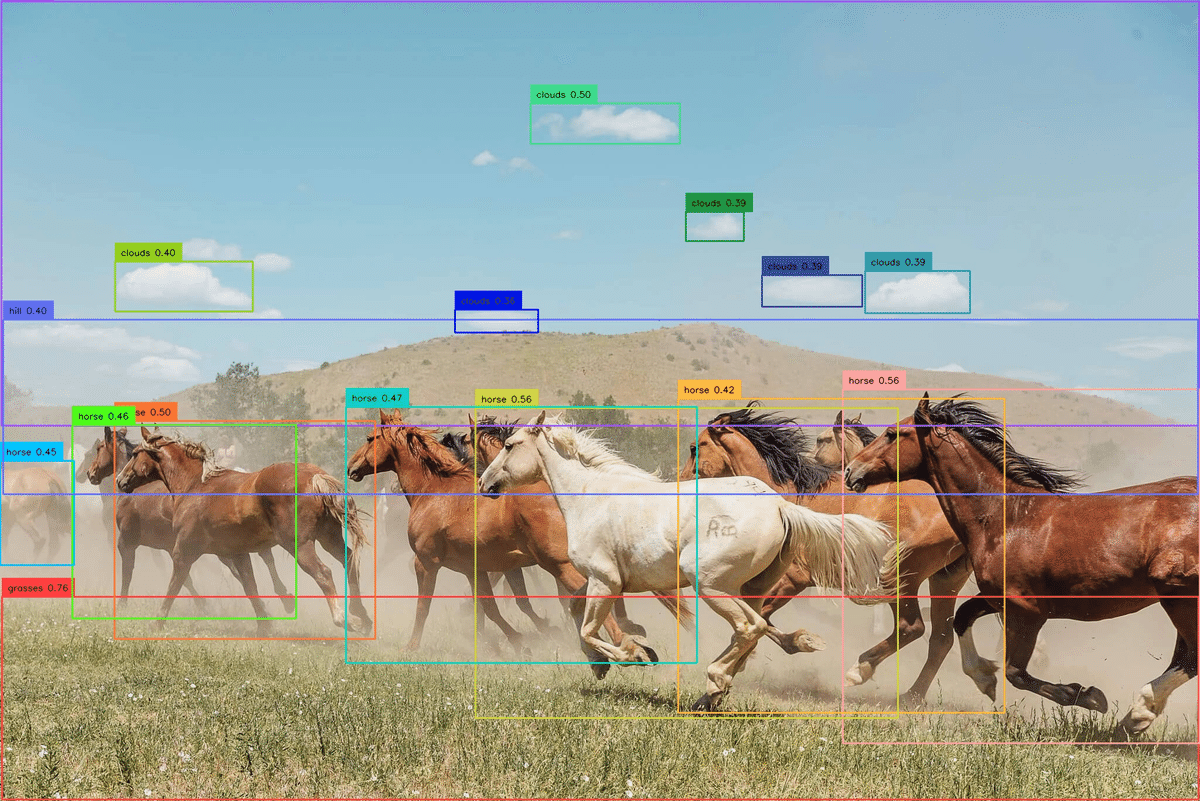
エラー対処:
もし以下のエラーが表示される場合、
Traceback (most recent call last):
File "/home/hahaha/codes/Grounded-Segment-Anything/grounding_dino_demo.py", line 30, in <module>
annotated_frame = annotate(image_source=image_source, boxes=boxes, logits=logits, phrases=phrases)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/hahaha/codes/Grounded-Segment-Anything/GroundingDINO/groundingdino/util/inference.py", line 102, in annotate
annotated_frame = box_annotator.annotate(scene=annotated_frame, detections=detections, labels=labels)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/hahaha/anaconda3/envs/GSAM/lib/python3.11/site-packages/supervision/utils/conversion.py", line 23, in wrapper
return annotate_func(self, scene, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
TypeError: BoxAnnotator.annotate() got an unexpected keyword argument 'labels'以下を実行してください。
pip install supervision==0.21.04.Grounded-SAMの実行
1:重みのダウンロード
cd Grounded-Segment-Anything
wget https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth
# 3.を実行していれば不要
wget https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth2:デモの実行
# GPU IDの設定
export CUDA_VISIBLE_DEVICES=0
# Demoの実行
python grounded_sam_demo.py \
--config GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py \
--grounded_checkpoint groundingdino_swint_ogc.pth \
--sam_checkpoint sam_vit_h_4b8939.pth \
--input_image assets/demo1.jpg \
--output_dir "outputs" \
--box_threshold 0.3 \
--text_threshold 0.25 \
--text_prompt "bear" \
--device "cuda"元画像:

結果:

Mask:
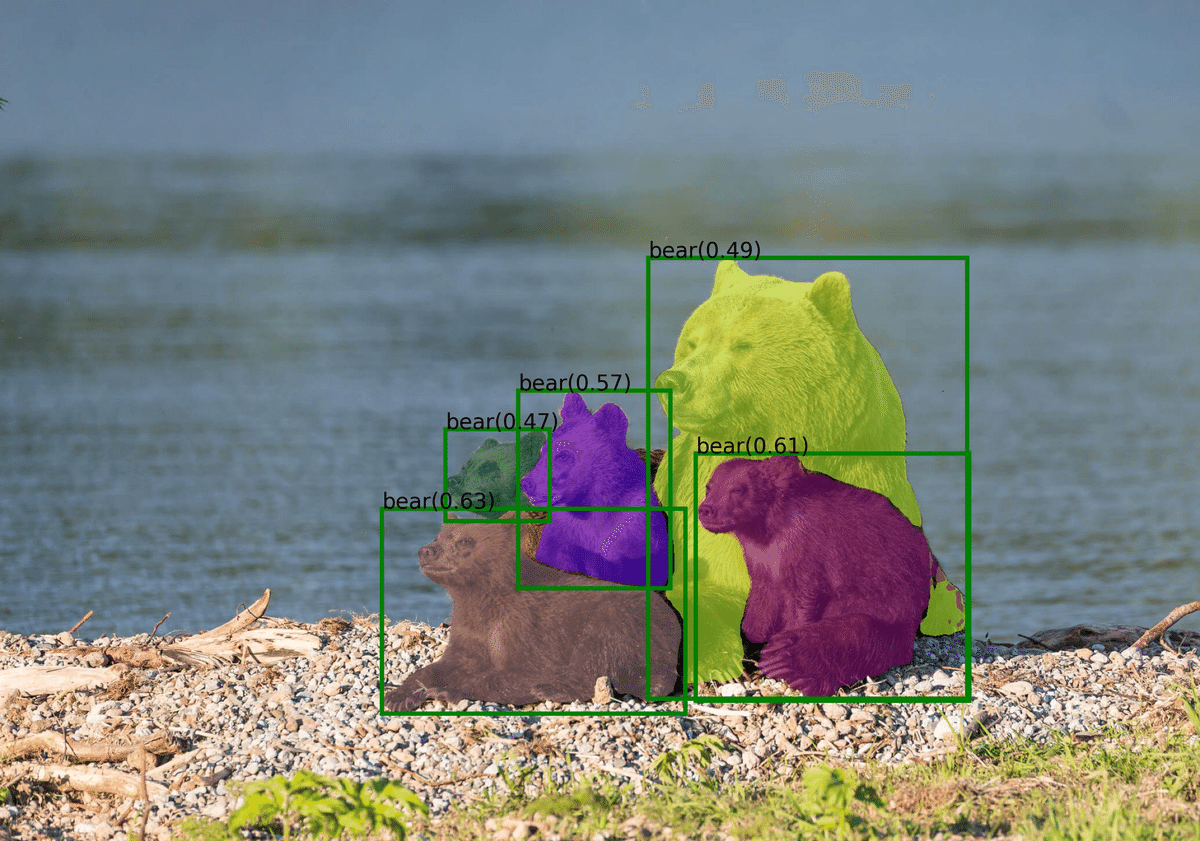
Json:
[{"value": 0, "label": "background"}, {"value": 1, "label": "bear", "logit": 0.63, "box": [658.0548095703125, 876.804443359375, 1180.429931640625, 1230.0576171875]}, {"value": 2, "label": "bear", "logit": 0.49, "box": [1116.954833984375, 444.0500183105469, 1666.6407470703125, 1204.35546875]}, {"value": 3, "label": "bear", "logit": 0.57, "box": [892.4771118164062, 672.7130126953125, 1154.7783203125, 1014.0478515625]}, {"value": 4, "label": "bear", "logit": 0.61, "box": [1198.39697265625, 781.3726806640625, 1669.74609375, 1207.311767578125]}, {"value": 5, "label": "bear", "logit": 0.47, "box": [767.03173828125, 739.934814453125, 946.5293579101562, 897.6659545898438]}]5.最後に
以上、GSAMを動作させるまでをまとめました。
GSAMは複数のパッケージを利用する都合上、パッケージごとにpytorch等のバージョン確認をする必要がありインストールが非常に難解です。
(本家Gitのissueを見ればわかりますが、導入が難解すぎて、沢山のスレッドが作成されています)
pytorchの問題以外にも、導入時引っかかる点が多々あるため、今回、noteとしてまとめた次第です。
(最初はWindowsにインストールしようとして半日沼りました。)
日本では、LLMの影であまり注目されない画像認識技術ですが、Segment Anythingの登場で、新しいステージに進化していると私は認識しており、是非試していただければ幸いです!
この記事が気に入ったらサポートをしてみませんか?