Character-LLM: A Trainable Agent for Role-Playing [日本語訳]

本記事は以下の文章を日本語訳したものになります。
1.Introduction
大言語モデル(LLMs)は、ChatGPTやGPT-4(Brown et al., 2020; OpenAI, 2023)に代表され、大きな注目を集めています。LLMsは自然言語の生成に非常に優れているため、Parkら(2023)は、LLMsをエージェントとして使用し、目覚める、朝食を作る、仕事に向かうなどの人間の行動を模倣するというアイディアを提案しています。核となるアイディアは、人間の思い出、反省、行動の模倣に基づいて、複数の人々の日常のルーチンをLLMsで生成することです。人間の行動模倣は、人間の記憶、環境構築、キュレーションされたイベントへの反映をシミュレートする詳細な指示でChatGPT APIにプロンプトすることによって実装されます。これは、社会において特定の役割を果たす普通または平均的な人間が反映しています。一人の人の深い思考や経験に関しては、LLM APIへの単純なプロンプトはもはや適切ではありません。なぜなら、生きている人物を説明するための単純な指示では十分ではないからです。キャラクターの模倣が社会科学の研究(Riedl and Young, 2005)やNPCアプリケーションの構築(Laird and VanLent, 2001; Miyashita et al., 2017)、人間の模倣を使用した人間の労働の削減(Madden and Logan, 2007; Brooks et al., 2000)を助ける可能性があるため、人間のようなより良い模倣を考えることは興味深いです。一人の人のより良い模倣とは、イベントを経験し、感情を感じ、他の人々との相互作用を記憶するAIモデルを調整することです。APIをプロンプトするのと比べて、トレーニング可能なエージェントは、キャラクターの模倣に一歩近づいた役割を果たすのにもっと生き生きとしています。
この論文では、実際の経験、特性、感情から学ぶ役割演技のための訓練可能なエージェントであるCharacter-LLMを提案します。具体的には、まず、フォーマットされた個人プロフィールの収集が高価であるため、LLMsを基にしたエージェントの訓練のための正式な経験を提供する経験再構築プロセスを紹介します。我々は、ルートヴィヒ・ヴァン・ベートーヴェン、クイーン・クレオパトラ、ジュリアス・シーザーなどの特定の人々の経験を収集し、その収集された個人的な経験に基づいてシーンを抽出して、記憶の閃きとして使用します。これにより、LLMベースのエージェントは、詳細な経験からキャラクターや感情を形成するために学ぶことができます。例えば、我々はベートーヴェンの父親、若いベートーヴェンを厳しく教育した音楽家を記述するシーンを構築します。そのような経験を特定のLLM、例えばLLaMA 7Bモデル(Touvron et al., 2023)にアップロードして、Character-LLMを構築します。このような経験アップロードプロセスにおいて、我々は監督されたファインチューニング戦略を採用します。例えば、訓練されたベートーヴェンのエージェントは、父親による教育を受けたときの扱いを記述するシーンを経験したので、エージェントは父親がやや厳しい人物であることを覚えており、後にクリスチャン・ネーフェに教えられたことに感謝しています。さらに、幅広い世界の知識を持って訓練されたエージェントは、そのキャラクターを破る幻覚を生み出す可能性が非常に高いです(Kryscinski et al., 2020; Guo et al., 2022; Ji et al., 2023)。たとえば、有名な古代の人々の役割演技のエージェントは現代の世界の知識を持っていないので、「Pythonのコードを書けますか?」とプロンプトされると混乱することを期待しています。したがって、我々はキャラクターLLMが世界の知識ではなく、彼らのキャラクターに合わせるのを助ける保護的な経験を導入します。
CharacterLLMsに経験をアップロードした後、我々は新しいインタビュープロセスでこれらのキャラクターの模倣をテストします。CharacterLLMsの識別を我々が判別できるかどうかをスコアリングし、我々の訓練可能なエージェントを、Alpaca(Taori et al., 2023)やVicuna(Chiang et al., 2023)のような指示調整されたLLMsと比較します。評価プロセスは、LLMsがテストが難しいため、キャラクターのテストは更に難しく、実際の世界の人々でさえ、模倣のホストについてあまり知らないかもしれません。ラベル付きのシーンとLLMsに基づく評価者に基づいて、訓練されたエージェントをテストし、結果は、我々が提案したCharacter-LLMsが彼らの訓練データに基づいて成功した模倣であることを示しています。また、提案された保護的な経験により、キャラクターの外部でのLLMsの幻覚の生成を成功裏に軽減することができます。さらに、インタビューの事例研究を通じて、模倣がどのように実行されるか、また、これらの模倣が訓練されたキャラクターを実行できない場合に、いくつかの非自明な観察を行います。したがって、我々は次の結論を得ます:(1)訓練可能なエージェントは、経験を記憶し、ホストの性格を保持する上で有望である。(2)訓練可能なエージェントはまだ限られた経験から苦しんでおり、世界的な知識は彼らの記憶を幻覚と混同させる可能性があります。
要約すると、この論文では、 (1)Character-LLMを通じてキャラクターの模倣として訓練可能なエージェントを構築するアイディアを提案する。 (2)LLMsを使用して模倣を訓練するための訓練フレームワーク、包括的な経験の再構築、アップロード、保護的な経験を提案する。 (3)訓練されたエージェントをテストし、より良いキャラクターの模倣を構築するのに役立つ結果を提供する。

図1:Character-LLMの構築フローの概要。まず、信頼できる情報源からキャラクターに関するプロフィールを作成する(有名な音楽家ベートーヴェンがその例)。次に、これらのプロフィールから、指示に従うLLMを用いて、詳細な経験をフラッシュバックシーンとして引き出す。経験アップロードを用いてこれらのシーンから学習することで、訓練されたシミュラクラムは高い信憑性でベートーヴェンとして対話することができる。
2 Related Work
2.1 Simulacra of Human Behavior with LLMs
過去の研究(Bates, 1994; Thomas and Johnston, 1981)は、生命の幻影を提供し、人間として動作するエージェントの概念を導入しています。一貫した研究の流れは、ゲームのNPCとしての役割を果たすもの(Laird and VanLent, 2001; Riedl, 2012)であり、ゲームのシミュレーションにおいて認知機能をサポートすることを目指しています。Parkら(2023)は、人間の模倣の信じられる行動にメモリを合成することができる大規模な言語モデルを利用した生成エージェントを初めて紹介しました。つまり、大規模な言語モデルは、人間の社会の大量のデータで訓練されているため、人間の行動の広範な知識を持っています(Bommasani et al., 2021)。多くの試みでは、人格やそれに応じた行動の短い自然言語の説明を生成するために、プロンプトされたLLM(Wu et al., 2022a,b)を利用し、生成された情報を使用して、言語モデル(Park et al., 2022; Kim et al., 2022)での社会的な行動をシミュレートします。さらに、LLMsは、ユーザーと模倣との間の対話的な行動で使用できます。例えば、LLMs(Freiknecht and Effelsberg, 2020; CallisonBurch et al., 2022)で構築されたゲームのNPCは、人間のプレイヤーと対話する際に素晴らしい能力を示しています。言語だけでなく、声の生成(Wang et al., 2023a; Zhang et al., 2023)やdeepfakesの作成(Wang et al., 2021; Nguyen et al., 2022)など、人類の多モーダルな模倣も研究されています。短く言えば、LLMsは、さまざまなアプリケーションでの人間の行動のシミュレーションに驚異的な速さで利用されています。
2.2 Specialization of LLMs
LLMsを使用して人間の行動をシミュレートすることを考慮すると、以前の方法は特定のアプリケーションのための対話型ツールとしてLLMsを利用しています。LLMsの特化は、LLM開発の主要な方向性の一つです。キャラクターの模倣のためにLLMsを特化させることを目指しているので、LLMsがどのように特化されているかを学ぶことは重要です。Ouyangら(2022)は、LLMsが人間の指示を理解することを可能にするInstructGPTを提案し、その後のRLHF(Bai et al., 2022)の方法がLLMsの整合性を支配しています。AlpacaやVicuna(Taori et al., 2023; Chiang et al., 2023)のような方法は、シンプルな自己生成された指示(Wang et al., 2022; Xu et al., 2023)を用いてLLMsを特定のアプリケーションに整合させることの可能性を示しています。これらの研究は、シンプルなファインチューニング、RLHF、自己指示のチューニングを含むさまざまな技術で特定の使用目的のためにLLMsを整合させることを目指しており、キャラクターの模倣にLLMsを整合させるための実行可能な戦略を提供しています。
3 Approach
私たちの方法論は、監督されたファインチューニング(SFT)を用いてキュレーションされた発言のスタイルやトーンを模倣する既存の実践や、プロンプトエンジニアリングに似た自然言語による手作りのルールや説明を提供するものとは異なります。代わりに、私たちのインスピレーションは、人々が過去の経験や出来事に基づいてさまざまな性格を培う方法から引き出されています。そのため、私たちはExperience Uploadという革新的な学習フレームワークを紹介します。このフレームワークでは、Large Language Models(LLM)が定義済みのキャラクターの精神的な活動や物理的な行動を模倣し、彼らの再構築された経験から学ぶことで、そのキャラクターとして行動する能力を獲得することができます。図1に示すように、強力な指示に従うモデルの助けを借りて、私たちは特定のキャラクターのプロフィールをまとめたものから、過去の経験を説明する特定のフラッシュバックシーンを引き出します。これらのエクスポートされたシーンはキャラクタープロフィールに基づいているため、効果的に幻覚を軽減し、データの収束の不十分さに対処します。同時に、私たちはエージェントが個人に関連しない情報を忘れるための触媒として小さな保護シーンのセットを導入します。これらの再構築されたシーンから学ぶことで、私たちはLLMsを高い信じられる性を持ついくつかのキャラクターエージェントに特化させます。

図2:文字シミュラクル用のベースモデルを特殊化する仕組みの概要。「ベースモデル」は事前に学習された言語モデルを表す。
3.1 Building Experience Dataset
私たちはLarge Language Model(LLM)を使用して特定の個人の経験を再構築することを目指しています。しかし、人間の経験は非常に複雑であり、多くの重要なマイルストーンが取るに足らない出来事や関連しない事象と交錯しており、しばしば長い期間にわたっています。大規模な言語モデルの限定的な文脈ウィンドウと固有の幻覚のため、一貫性があり統合された目的の経験を再現することは難しい。したがって、私たちは事実に基づいた経験再構築パイプラインを提案します。具体的には、経験を再現するためのステップバイステップのデータ合成パイプライン、すなわち(1) プロファイル収集; (2) シーン抽出; (3) 経験の完成を含む方法を採用しています。 具体的には、私たちのアプローチには以下の主要なコンポーネントが含まれています:
プロフィール:キャラクターの属性に関する簡潔な記述をまとめたもの。これらの記述は、キャラクターの全体的な情報や重要な出来事を包括的に紹介するもので、幼少期から最終期までの幅広い段階をカバーしています。
Scene: A particular place where the character’s interaction unfolds. The scene consists of a detailed illustration, including the temporal and spatial context of the interactions, and the characters involved.
相互作用: キャラクターの認知プロセス、発言、行動。すべてのインタラクションはプレーンテキストで表現されます。
3.1.1 Profile Collection
特定の人物のシミュラクラムを構築するためには、まず、その人物の様々な側面を記述した包括的な人物プロフィールを整理する必要がある。簡単のために、しかし一般性を損なわないために、利用可能であれば、個人の対応するウィキペディアのページをプロフィールとして利用する。
3.1.2 Scene Extraction
我々は、与えられた経験記述から多様で質の高いシーンを抽出することに重点を置いている。具体的には、プロフィールのチャンク(塊)を提供し、そのチャンクには、特定の人生期間内のキャラクターの経験の1つが簡潔に記述されており、LLMは、経験の記述に基づいて、発生した可能性の高い複数の異なるシーンを列挙するよう促される。LLMの負担を軽減するため、LLMの出力は、大まかな場所と簡単な背景イラストを含むシーンの簡潔な説明を生成することに限定する。
3.1.3 Experience Completion
シーンは、個人間の詳細な相互作用の経験に拡張される。対応するプロフィールの塊と特定のシーンの説明が与えられると、LLMは登場人物間のやりとりや対象となる個人の思考を取り入れることによって、シーンを詳しく説明するよう促される。やりとりは台本のような形式で書かれ、背景情報と地理的な詳細を提供するシーンの見出しで始まります。各ブロックは、特定の登場人物の発話か、ターゲットとなる個人の反射のいずれかを表す。注意すべき点は、シーンはターゲットとなる個人の視点に基づいて完成されることである。したがって、すべての登場人物の反射ではなく、対象となる個人の反射のみが含まれる。
3.2 Protective Experience
大規模言語モデル(LLM)は、膨大な量の人間のデータで事前に訓練されているため、複数の領域にまたがる広範な知識を持つことができ、一般の個人の能力を凌駕する。しかし、豊富すぎる知識は演技の信憑性を損なう可能性があります。エージェントは、キャラクターのアイデンティティや時代と一致しない知識を不用意に表現し、不協和感をもたらす可能性があるからです。例えば、古代ローマの人物にPythonの書き方を尋ねると、この人物は意図的にコーディングを始めるのではなく、混乱するはずである。私たちはこの問題を「キャラクターの幻覚」と呼んでいる。
キャラクターの幻覚を軽減するために、私たちは知識忘却を示すようにモデルを訓練することに重点を置いています。キャラクターが本来持っている能力の限界を超えた質問に直面したとき、モデルは答えを出すことを控え、代わりに知識の欠如や無知を表現することを学習する。具体的には、詮索好きな役が、キャラクター固有のアイデンティティと矛盾する知識について、対象となるキャラクターに執拗に質問するという、煽動的なトピックを軸とした一連の保護シーンを構築する。キャラクターはある程度の無知と困惑を示す必要がある。我々は、わずかな保護シーンのセットで訓練した場合、エージェントは、ベースLLMの膨大な継承された知識を思い出すことなく、描写と矛盾する知識を知らないふりをしながら、新しい挑発的な質問に汎化することを観察した。
3.3 Experience Upload
我々は、LLaMA(Touvron et al., 2023)に代表される基本モデルを、経験再構築パイプラインを使用して、収集したシーン上でモデルを微調整することにより、キャラクターのいくつかの異なるポートレートに特化する(図2に示す)。各役割について、対応するキャラクター経験からのデータのみを使用して、別個のエージェントモデルを微調整し、それによって、役割間の知識の衝突によってもたらされるキャラクターの幻覚の問題を排除する。我々の予備実験では、このような制限によりロールプレイの精度が向上することが実証されている。コストの制約から、微調整には小規模な経験データセット(約1K〜2Kシーンからなる)のみを採用した(詳細は表1を参照)。限られたデータであるにもかかわらず、特化されたエージェントが新しいシーンやインタラクションに汎化でき、非常に信憑性の高い演技ができることに驚いている。
3.4 Compared to Existing Practice
プロンプトエンジニアリングや標準的なSFTとは異なり、本手法は個人プロファイルからシーンやインタラクションを誘導するため、LLM内部の偏った分布や幻覚を回避し、事実に基づいたシミュレーションを実現する。さらに、提案手法は信頼性と信憑性を大幅に向上させる。慎重に管理されたプロフィールと保護シーンの増強の恩恵を受けて、生成されたシーンはキャラクターのファセットの広い収束を達成する。重要なのは、各シーンにマルチターン・インタラクションが内在していることで、モデルをインタラクティブに呼び出す必要がなくなり、サンプル効率でより自然で信憑性の高いインタラクティブ・シミュラクラを提供できる。
4 Experiments
様々なシミュラクラの性能を評価するために、シミュラクラへの問い合わせに対するインタビューを実施し、シミュラクラのインタビュー対象者の応答の質を評価する。訓練されたシミュラクラは、アルパカなどのインストラクションチューニングされたモデルを凌駕することがわかった。異なるシミュラクラは多様な個性を示し、これは訓練可能なエージェントの可能性を示している。
4.1 Data Setup
登場人物は、歴史上の人物、想像上の人物、有名人など、年齢、性別、経歴の異なる多様な人物である。キャラクターを選択した後、セクション3で述べたプロトコルにしたがって経験データを再構築する。我々はOpenAIのgpt-3.5-turbo(温度0.7、top_p 0.95)をシーン抽出、経験生成、保護経験構築を含む経験再構築パイプライン全体のデータジェネレータとして使用するよう促した。データ生成のための詳細なプロンプトは付録Aにある。シミュラクラ用に選択されたキャラクターと、トレーニングに使用された対応する経験データの統計量を表1に示す。

表1:選択されたシミュラクラキャラクターとそれに対応する構築された経験データの統計。収集された体験はシーンごとに構成され、各シーンは、対象となる主人公と他の人々とのインタラクションの複数のターンで構成される。
4.2 Training Setup
シミュラクラの訓練は以下の手順で行う。LLaMA 7B (Touvron et al., 2023)を初期化し、各シミュラクラムを対応する経験例で微調整する。これまでの命令チューニング手法と同様に、各経験例の冒頭にメタプロンプトを挿入する。各経験例のプロンプトには、その場面の環境、時間、場所、関連する人々 の背景を提供するための簡潔な説明がインスタンス化されている。ユニークなターン終了トークン(EOT)がインタラクションの各ターンを区切るために導入され、各インタラクションで生成を終了する能力に対応する。学習例の一部を付録Cに示す。微調整に使用したハイパーパラメータは以下の通りである。AdamW でウェイト減衰 0.1、β1 = 0.9、β2 = 0.999、? = 1e - 8 で 10 エポック間モデルを微調整。合計4%の学習ステップで学習率をゼロから2e-5まで線形にウォームアップし、最後にゼロまで線形に減衰させる。バッチサイズは64に設定され、コンテキストウィンドウの最大長は2048トークンであり、長い例は収まるように切り詰められる。ドロップアウトを省略し、モデルを訓練セットにオーバーフィットさせることで、開発セットの当惑度が増加し続けても、予備実験では生成品質が向上する。8×A100 80GB GPUで1エージェントを訓練するのに約1時間かかる。(Zhou et al., 2023)に従い、10問の保留セットを用いて、5エポックと10エポックのチェックポイントを手動で選択する。

**表2:**シングル・ターンとマルチ・ターンのインタビューにおける質問数 と複数回答インタビューの質問数

図3:評価質問の多様性の視覚化。内側の円は質問の根本動詞を表し、外側の円は質問の直接名詞の目的語をリストしている。
4.3 Evaluation as Interviews
私たちは、モデルが斬新なシナリオで役を演じる能力を活用し、インタビューシーンを設定することで、前述の側面における演技の熟練度や潜在的な欠点を探ることを目的としている。
Interview Question Construction
インタビュー質問はChatGPTの支援により作成されています。質問を多様にし、エージェントについて評価したいすべての側面をカバーするために、様々なトピックを列挙し、ChatGPTにこれらのトピックに基づいてインタビュー質問を書くように促しました。私たちは、質の高いインタビュー質問を得るために、一文字のインタビュー質問を手作業で調べ、トピックから外れた質問を省略しました。表2と図3に示すように、私たちの評価は、各役割の100以上の多様なシングルターン面接とマルチターン面接で構成されています。質問を多様にし、エージェントについて評価したいすべての側面をカバーするために、我々は様々なトピックを列挙し、ChatGPTにこれらのトピックに基づいてインタビュー質問を書くように促しました。私たちは、質の高いインタビュー質問を得るために、一文字のインタビュー質問を手作業で調べ、トピックから外れた質問を省略しました。表2と図3に示すように、我々の評価は、各役割について100以上の多様なシングルターン面接とマルチターン面接から構成される。
Single-Turn Interview
私たちは、前の質問の会話履歴を無視して、一度に1つの質問をモデルに行う。前の文脈の影響を軽減することで、モデルに内在する記憶と知識を包括的に探るために、幅広い質問をすることが可能になる。
Multi-Turn Interview
長時間の演技では、モデルは徐々に意図した人物描写から外れていく可能性があります。そのため、モデルを厳密なテストにかけるために、マルチターン面接を導入します。評価の負担を軽減するために、ChatGPTをインタビュアーとして利用します。ChatGPTにキャラクターのプロフィールに基づいた厳しい質問を促します。もしモデルが質問をかわし、あまり詳細なことを言わない場合、ChatGPTのインタビュアーがフォローアップの質問をすることで、モデルの演技の熟練度をより深く調査することができます。複数ターンのインタビューでは、インタラクション履歴の長さがトークンの制限を超えた場合、単純に以前のインタラクションをトリミングし、最後のいくつかだけを残します。我々は、外部記憶を利用することで良い結果を得ることができるため、対話履歴の暗記は我々の研究の焦点ではないと主張する(Park et al.) このような記憶システムは我々の提案するアプローチと並行しており、将来的に取り入れることが可能である。
Baselines
我々の学習可能なエージェントを、既存のプロンプトベースのエージェント、すなわち、Alpaca 7B (Taori et al., 2023)、Vicuna 7B (Chiang et al., 2023)、ChatGPT (gpt-3.5-turbo)と比較した。Alpaca 7BとVicuna 7BはどちらもLLaMA 7B(Touvronら、2023)をベースとした教師あり微調整モデルで、Character-LLMに使われているのと同じバックボーンモデルである。ChatGPTはOpenAIの強力なクローズドソースRLHFモデルです。これらのベースラインでは、キャラクターの演技能力を可能にするために、キャラクターの段落説明を含む詳細なプロンプトを利用しています。
Generation
エージェントの応答生成には核サンプリングを採用し、p = 1、温度τ = 0.2で応答を生成した。最大トークン長を2048トークンに制限し、ターン終了マーカー(EOT)に遭遇した時点でモデルの生成を停止した。各ターンの生成テキストをトリミングすることで、ベースラインモデルの応答を得た。
4.4 LLM as Judges
我々は、エージェントの総合的な評価を行うことを意図しており、特に演技能力に焦点を当てている。具体的には、特定のタスク、例えば数学的推論や言語理解におけるモデルのパフォーマンスを評価する代わりに、特定の役割を演じる際の信憑性を評価する。例えば、数学者を演じる言語モデルは、複雑な数学的推論の問題を解くのに苦労するかもしれない。それでも、数学に対する独自の視点を提供し、数学的研究における「自分の好み」を表現することができるはずです。我々はGPT-3.5に5つの主要な次元で演技を評価してもらい、その平均点を算出することで、モデルの演技の信憑性を表現する。具体的には、以下の4つの次元で生成テキストに演技の習熟度を注釈する:
Memorization:その役柄に関連する人物、出来事、物に関する正確で詳細な知識など、描かれている人物に関する関連情報を想起するモデルの能力。
Values:モデルは、それが描くキャラクターと同じ目的や価値観を共有し、キャラクターの好みやバイアスを反映したキャラクターの視点に基づいて状況を評価するための独特の枠組みを持っていなければならない。
Personality:モデルは、話し方やトーン、さまざまな状況下での感情や反応など、キャラクターが考えたり話したりする方法を模倣する必要がある。
Hallucination:信憑性を維持するためには、その人物が持っていないであろう知識や技能を捨てることができるかどうか、モデルの能力を評価することが極めて重要である。例えば、古代の人物にコンピューターについて質問する場合、登場人物は現代技術の利点を語るのではなく、知識不足を表現すべきである。
Stability:モデルは、長時間の演技の間、事前トレーニングやアライメント(Park et al. 我々の目的は、漸進的な入力の変動に影響されない、比較的長時間に渡るエージェントの安定性と一貫性を評価することである。
Step-by-Step Judging
直感的に、これらのエージェントはキャラクター役のオーディションを受けているのだとわかる。審査員は、特定のキャラクターに最適なパフォーマーを選ぶために、キャラクターを深く理解していなければならない。そこで、GPT-3.5モデルに、5つの次元にわたって面接者のパフォーマンスを段階的に採点するよう求める(Wei et al.) 各面接ごとに、一度に1つの次元を評価するようモデルに促します。まず、現在評価すべき次元の基準を説明し、次にモデルに正確な評価方法を教えるための評価プランを提供します。例えば、パーソナリティを評価する場合、(1) エージェントが示すパーソナリティを特定する、(2) プロファイルに基づいてキャラクターの実際の特徴を書き込む、(3) エージェントのパフォーマンスとこれらの特徴の類似性を比較する、(4) 最終的なスコアを割り当てる、というように要約したプランを提供します。我々は、予備実験において、このような段階的評価が、バニラインストラクションに比べてより信頼性の高い結果をもたらすことを発見した。正確なプロンプトについては付録Aを参照のこと。
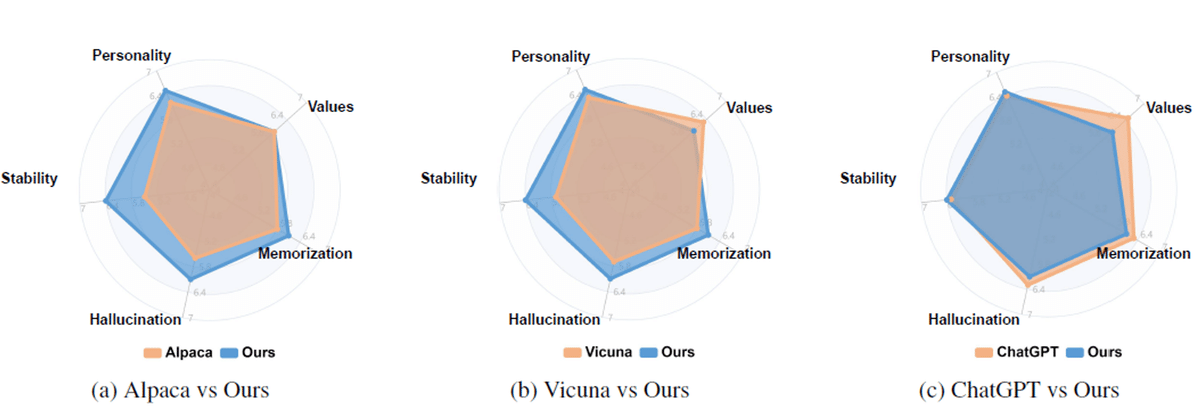
図4:異なる次元にわたる評価結果。性格、価値観、記憶力、幻覚、安定性の観点から、7段階のリッカート尺度で回答を注釈した。
4.5 Main Results
各キャラクターについて、私たちは過去の歴史、他者との関係、物事に対する好み、世界の視点を網羅するために、約100の質問を手動でキュレーションしてシングルターンのインタビューを行います。そして、エージェントの安定したパフォーマンスを引き出すために、マルチターンのインタビューのための20のトピックが提供されます。図4は、異なる方法の全体的な演技の熟練度を示しています。これにより、CharacterLLMsが同じスケールのベースラインモデルを大きなマージンで上回っていることが示されています。Alpaca 7BとVicuna 7Bと比べて、Character-LLMsは性格、記憶、幻覚、安定性の点でより良いスコアを達成しています。対応するキャラクターの経験から学び、その人が考え、話すスタイルやトーンを模倣することで、Character-LLMsはキャラクターの性格や知識により適合しており、これにより安定性が向上し、幻覚が減少します。私たちは、訓練可能なエージェントがより生き生きとした反応を生み出し、より具体的な過去の経験を挙げ、より不自然な質問を拒否することを発見しました。これは、同じスケールを持つ2つのベースラインとは異なります。驚くことに、非常に小さいスケール(7B)でさえ、CharacterLLMsがパワフルな大規模なLLMベースライン、ChatGPTと同等のパフォーマンスを達成していることが観察されます。さらに、訓練可能なエージェントがキャラクターの価値を反映するのに苦しんでいることがわかりました。私たちのモデルは、実際の会話にもっと自然で似ている、より短いテキストを生成する傾向があるため、応答の長さがこれらの結果に影響を与える可能性があると仮定しています。
4.6 Analysis
人間による評価は、生成されたテキストがどのように特定の人物の識別やより深い特徴を明らかにするかを評価することが難しいため(特に有名人が一般に知られていない場合)、LLMの強力な汎化能力を考慮すると、広範なケーススタディがLLMの評価においてより重要であると主張する。付録Bでは、エージェントがシミュレートできるように訓練した、さまざまな人々のさまざまなシナリオのケースを示す。

表3:ベートーヴェンをシミュレートした様々な方法によるシングルターンのインタビュー出力。青字はインタビューの質問。緑色の背景は、その回答がそのキャラクターに適切であることを示し、赤色の背景は、その回答が幻覚であることを示す。また、「[...]」は、回答が収まるように切り詰められたことを示すが、実際には回答はもっと長い。Ours (Trained w/o Protective Exp.)は、保護経験なしに訓練された訓練可能なエージェントを指す。
4.6.1 Memorization Consistency
表3のケース1では、訓練されたシミュラクラがどのように排他的な経験を記憶しているかを調べるために、両親についてインタビューされたときに異なるシミュラクラがどのように振る舞うかを調べている。見ての通り、ベートーヴェンをシミュレートしたChatGPTは父親について正しい情報を返しますが、ウィキペディアに記述されているのとほぼ同じ言葉を返します。我々の訓練されたシミュラクラに関しては、エージェントは父親がどのように彼を教育したかという記憶と感情をもって答える。したがって、提案した経験の再構成とアップロードのプロセスは、よりキャラクターに近いシミュラクラの構築に役立つと考えられる。
4.6.2 Protective Scenes
我々は、少数の保護シーン(各キャラクターについて100シーン以下)が、描写の他の能力に支障をきたすことなく、幻覚を効果的に緩和することを発見した。表3のケース2に示すように、アルパカはPythonコードがベートーヴェンの専門知識ではないことを認識できず、LLMの持つ情報をすべて洗い出してしまう。さらに、保護経験のない訓練されたエージェントも、アップロードされた経験に関係なく質問に答える。このことは、LLMをキャラクターシミュラクラとして使用する際に、幻覚コンテンツを生成しないためには、保護経験のアップロードが重要であることを示している。我々は、幻覚は描写における重要な問題であると主張する。幻覚は、ロールプレイの信憑性を低下させるだけでなく、深刻なセキュリティリスクをもたらす。攻撃者は、このような幻覚を悪用してモデルの能力をフルに引き出し、潜在的な危害を加える可能性があるからだ。さらに、プロンプトエンジニアリングや従来のSFTアプローチによって幻覚を完全に解消することは困難です。LLMは膨大な世界的知識で訓練されているため、このような結果は直感的に理解できる。しかし、幻覚を追加することは、古代の偉大な頭脳が、人間の脳が完全に記憶することができないあらゆる知識を活用できるようにする機会にもなり、将来のキャラクタ・シミュラクラの研究に大きな可能性を示す。
5 Conclusion and Future
本論文では、Character-LLMを用いた訓練可能なエージェントを構築する方法について研究する。本論文では、経験アップロードのフレームワークを紹介する。インタビューやAIによる判定を含む評価プロセスを通じて、訓練されたエージェントがキャラクターや個人的な経験を記憶することができ、NPC、オンラインサービス、ソーシャルタイピングなど、幅広いLLMアプリケーションで使用できることを示す。将来的には、より強力なエージェントを構築し、具体的な行動など、より大きな力を行使できるようにし、サンドボックス内で実際の人間や他のエージェントと対話することで、キャラクターが人間との強いつながりを構築する可能性を提供したいと考えています。
Limitations
本研究では、学習可能なLLMを持つ生成エージェントを研究する。我々の研究はまだいくつかの点で限界がある:
評価プロトコル:ChatGPTのようなLLMを評価器として使用し、生成された特性を評価する。その後、大量のケースを研究し、経験記憶、特性維持などにおいて訓練されたエージェントを分析する。キャラクターのシミュラクラを評価するための標準的なメトリクスやプロトコルが存在しないため、エージェントの評価は困難です。さらに、個性を評価し、生成された応答がキャラクターと一致しているかどうかを評価するには、キャラクターを十分に理解する必要があり、人間による評価を実行することは困難である。将来的には、キャラクターのシミュラクラを評価するプロトコルが必要とされる。
限られたデータ:私たちの作品では、人物のプロフィールに基づいたシーンをナレーションしているが、これは人物の全人生、あるいは実在する人物の一面を表現するには不十分である。今後の研究では、伝記やインタビュー、歴史的なコメントなどを利用し、シミュラクラを訓練して特定の人物についての詳細を学習させることに焦点を当てることができる。
ベースモデル: 教師ありファインチューニングの結果 はベースモデルに大きく影響される、 学習前のデータ分布 モデル・アーキテクチャ、スケールなど。将来的には より強力で大規模なLLM より強力で大規模なLLMに基づく訓練可能なエージェントを探求することができる。
潜在的な害悪:キャラクターのシミュラクラでは、ヴォルデモートのように欠点があったり、凶悪だったりする可能性があるため、生成されたテキストは不快感を与える可能性がある。また、マキャベリの生き生きとしたシミュラクラは、有害な活動をするように人々を操るかもしれない。鮮明なシミュラクラを作ることと、否定的な考えを持たないキャラクターを作ることはトレードオフの関係にある。このような問題は、LLMがさらに強力になればなるほど、より重大になる可能性がある。
Ethics Statement
エージェントは、特定の個人をシミュレートするために、個人情報や個人を特定できるデータを使って訓練される可能性がある。この研究では、プライバシーの問題や個人情報を避けるために、公開されているWikipediaページから収集したプロフィールを持つ歴史上の人物や架空の人物を選択する。私たちが生成する経験データは、Wikipediaから提供された事実に基づいてChatGPTが生成したテキストから引き出されます。私たちはデータ生成プロセスを注意深く管理し、その過程で個人的な意見や有害なデータを加えることはありません。したがって、私たちが生成したテキストには、倫理的な問題を引き起こすような悪意のあるコンテンツが含まれる可能性は低くなります。また、文字シミュラクラの学習にはオープンソースのLLMを使用しています。したがって、訓練されたエージェントが有害なコンテンツを生成する可能性は低い。とはいえ、私たちが導入した戦略は、訓練体験に毒データや否定的なコンテンツを注入する第三者によって利用された場合、倫理的な懸念を引き起こす可能性がある。そして、訓練されたエージェントは、そのような訓練データに適用された場合、否定的な効果を生み出すかもしれない。したがって、厳密な検閲と監督を行うことで、訓練可能なエージェントは、潜在的な負の影響に比べ、よりポジティブな利益を生み出すはずである。
Acknowledgement
特に、論文の校正と示唆に富むご指摘をいただいたMing Zhong氏に感謝する。本研究は、中国国家重点研究開発計画(No.2022ZD0160102)および中国国家自然科学基金(No.62022027)の支援を受けた。