Google ColabでLLM(llm-jp-3-instruct、HF形式)をGGUF形式に変換する

※ Last update 10-03-2024
※ (10-3) rinna/gemma-2-baku-2b-it も利用できます。
※ (10-3) 3-3.に、google/gemma-2-2b-jpn-it への対応方法を追加しました。
※ 本記事はHugging Face形式のモデルの変換がメインです。GPUは使用しません。モデルの動作確認もできますが遅いので、特にllm-jp-3-instruct 13bは行わない方が良いでしょう。
※ 記述がややこしくなるため、F16やf16の記述を省いています。こちらが必要な場合はBF16やbf16の部分を読み替えてください。
※ Windows PC版については、別の記事を公開する予定です。
■ 0. はじめに
▼ 0-0. 本記事の内容
本記事の1.では、Google Colabを用いてLLM(Hugging Face形式)をGGUF形式に変換するための手順を説明しています。
llm-jp-3-instructの3.7b/1.8bモデルをBF16またはQ8_0に変換。
BF16からQ8_0以下に変換(オプション、llama.cppのビルドが必要)。
モデルの応答を確かめる(オプション、llama.cppのビルドが必要)。
モデルのダウンロード。
本記事の2.では、同様に下記の手順を説明しています。
無料のGoogle Colab向け:llm-jp-3-instructの13bモデルをQ8_0に変換する。さらに、requantizeでQ4_K_M等に変換(オプション、llama.cppのビルドが必要)。
有料のGoogle Colab Pro向け:同じく13bモデルをBF16に変換する。さらに、Q4_K_M等に変換(オプション、llama.cppのビルドが必要)。
モデルの応答を確かめる(オプション、llama.cppのビルドが必要、時間がかかるので非推奨)。
モデルのダウンロード。
未検証ですが、他のHugging Faceモデルも変換できるかもしれません。お役に立てれば幸いです。
▼ 0-1. 本記事を読み進める前に
あるふ氏が、既に同様のモデルを掲載しています。つまり、それ以外のタイプが必要な方や、自分でやってみたい方が本記事の対象となります。
llm-jp-3-1.8b-instruct-gguf(F16, Q8_0, Q4_K_M, Q4_XS)
https://huggingface.co/alfredplpl/llm-jp-3-1.8b-instruct-ggufllm-jp-3-3.7b-instruct-gguf(Q8_0, Q4_K_M, Q4_XS)
https://huggingface.co/alfredplpl/llm-jp-3-3.7b-instruct-ggufllm-jp-3-13b-instruct-gguf(Q4_K_M, Q4_XS)https://huggingface.co/alfredplpl/llm-jp-3-13b-instruct-gguf
llm-jp/llm-jp-3-1.8b-instructの量子化バージョンをアップロードしました。各自よしなな方法で使ってください。https://t.co/eFgCarYjft
— あるふ (@alfredplpl) September 28, 2024
▼ 0-2. 概要
9-25-2024に、NII(国立情報学研究所)の大規模言語モデル研究開発センター(LLMC)が完全にオープンなモデル「LLM-jp-3(1.8B, 3.7B, 13B)」を公開しました。これは、172BのLLM-jp-3を作る過程での副産物に近いものですが、既にその性能が一定の評価をされているようです。
本記事ではGoogle Colabを利用して、公開されているLLM-jp-3をGGUF形式に変換します。ノートブックの提供は無いので、お手数ですがコピー&ペーストを行いながら順番に実行してみてください。
▼ 0-3. 備考
BF16やQ8_0を除く量子化タイプを作成する場合は、llama.cppのビルドが必要になります。10分程度の追加を見込んでください。
大きいモデルはディスク容量が不足します。元のモデルの容量は、無料のGoogle Colabの場合で50GB程度が限界です。この大きさでは、もはやBF16への変換ができないためQ8_0に変換します。
▼ 0-4. 参考・関連
■ 1. 3.7b(1.8b)モデルを変換してダウンロード
▼ 1-1. 概要
1.の内容は下記のとおりです。
Google Colabを用いてllm-jp-3-instructの3.7b/1.8bモデルをBF16またはQ8_0に変換。
BF16からQ8以下に変換(オプション、llama.cppのビルドが必要)。
モデルの応答を確かめる(オプション、llama.cppのビルドが必要)。
モデルのダウンロード。
これ以降、3.7bの記述を1.8bに置き換えると1.8b向けになります。13bについては2.をご覧ください。
▼ 1-2. 変換後のモデルの大きさ
参考まで、変換後のファイルサイズを記載しておきます。3.7bは元々の大きさが手頃なので、Q8_0でも使い勝手が良いと思います。1.8bはスマートフォン等で役に立つかもしれません。
7.04GB … llm-jp-3-3.7b-instruct-bf16.gguf
3.74GB … llm-jp-3-3.7b-instruct-q8_0.gguf
3.22GB … llm-jp-3-3.7b-instruct-q6_k.gguf
2.50GB … llm-jp-3-3.7b-instruct-q4_k_m.gguf
2.12GB … llm-jp-3-3.7b-instruct-q3_k_m.gguf
1.75GB … llm-jp-3-3.7b-instruct-q2_k.gguf
3.48GB … llm-jp-3-1.8b-instruct-bf16.gguf
1.84GB … llm-jp-3-1.8b-instruct-q8_0.gguf
1.65GB … llm-jp-3-1.8b-instruct-q6_k.gguf
1.30GB … llm-jp-3-1.8b-instruct-q4_k_m.gguf
1.11GB … llm-jp-3-1.8b-instruct-q3_k_m.gguf
0.97GB … llm-jp-3-1.8b-instruct-q2_k.gguf
▼ 1-3. Google Colabの新規ノートブックを作成
まずは https://colab.research.google.com/ へアクセスします。新規のノートブックを作成してから、以降の説明とともに掲載するコードを順番に貼って実行してください。面倒でも一ヶ所ずつ行うのが確実です。GPUは不要です。
▼ 1-4. パッケージとモデルの準備
まず、必要なパッケージをインストールします。不足する場合は個別にインストールするか、llama.cppを入れた後でrequirements.txtも含めてみてください。
# パッケージのインストール
!pip install transformers accelerate flash-attnオリジナルのllm-jp-3-3.7b-instructをダウンロードします。
# LLMのダウンロード(llm-jp-3-3.7b-instruct)
!git lfs install
!git clone https://huggingface.co/llm-jp/llm-jp-3-3.7b-instruct変換に必要なため、LLM-jp Tokenizerのモデルを「tokenizer.model」のファイル名でダウンロードします。llm-jp-3系以外のモデルには適用しないでください。
# tokenizerモデルのダウンロード(llm-jp-3系以外では実行しないこと)
!wget https://github.com/llm-jp/llm-jp-tokenizer/raw/refs/heads/main/models/ver3.0/llm-jp-tokenizer-100k.ver3.0b1.model -O ./llm-jp-3-3.7b-instruct/tokenizer.model▼ 1-5. llama.cppの準備
llama.cppをクローンします。下記のいずれかを選択してください。
BF16またはQ8_0が必要な場合は、4行目は削除するか行頭に「#」をつけてください。変換したモデルの応答をその場で試したい場合は、こちらを選択しないでください。
再変換でQ8_0以下も必要、または判断が付かない場合はそのままにします。llama.cppのビルドも行うので7~10分程度かかります。次のステップでは「bf16」を選択してください。
# llama.cppのダウンロード
!git clone https://github.com/ggerganov/llama.cpp
# llamaのビルド(7~10分かかる、BF16やQ8への変換のみであれば不要)
!cd llama.cpp && make▼ 1-6. GGUF形式で保存
モデルをGGUF形式に変換しながら保存します。下記のいずれかを選択してください。
Q8_0だけが必要な場合は、そのままにします。
BF16やQ8_0以下が必要な場合は、ここではBF16で保存します。「q8_0」を「bf16」に、「q8_0.gguf」を「bf16.gguf」に、それぞれ書き換えてください。
詳細な使い方は3-1.をご覧いただくか「!python ./llama.cpp/convert_hf_to_gguf.py -h」で確認してください。outtypeは「f32, f16, bf16, q8_0, tq1_0, tq2_0」が指定できるようです。
# GGUF形式への変換(Q8_0の場合。BF16の場合はq8_0やq8をbf16にする)
# モデルが異なる場合はファイル名やパスを書き換えること
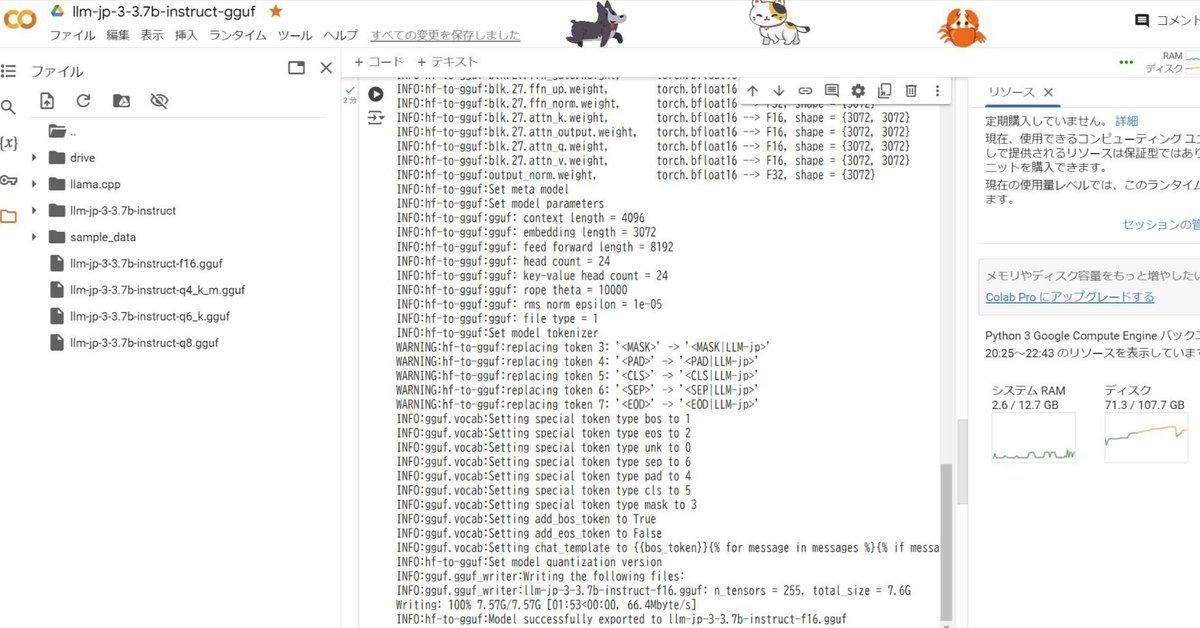
!python ./llama.cpp/convert_hf_to_gguf.py ./llm-jp-3-3.7b-instruct --outtype q8_0 --outfile ./llm-jp-3-3.7b-instruct-q8_0.gguf実行が終わったとき、末尾に「INFO:hf-to-gguf:Model successfully exported to llm-jp-3-3.7b-instruct-q8_0.gguf」のような表示があることを確認してください。
▼ 1-7. 量子化(オプション)
llama.cppをビルドすると「llama-quantize」ができているので、こちらを利用して量子化を行います。下記ではBF16からQ6_Kに変換しています。この処理は若干の時間を要します。
# BF16からQ6_Kへの変換(オプション、要llama.cppのビルド、quantization typesを適宜変更すること)
!./llama.cpp/llama-quantize ./llm-jp-3-3.7b-instruct-bf16.gguf ./llm-jp-3-3.7b-instruct-q6_k.gguf q6_k詳細な使い方は3-2.をご覧いただくか「!./llama.cpp/llama-quantize -h」で確認してください。quantization typesの一覧があるので、参考になると思います。
▼ 1-8. 応答の確認(オプション)
llama.cppがビルド済みの場合、その場でモデルの応答を確かめることができます。下記の例ではQ8_0を指定していますが、応答が終わるまでに1分程度かかりました。小さなモデルの方が応答が早いので、変換後に試してみると良いでしょう。
# 応答の確認(ファイル名は適宜変更すること)
command = """
./llama.cpp/llama-cli -m './llm-jp-3-3.7b-instruct-q8_0.gguf' -p '
## 指示 ##
もし犬が突然しゃべれるようになったら、最初になんて言うと思う?
## 応答 ##
' -n 100
"""
!{command}下記の画面は実行例です。

▼ 1-8. ファイルのダウンロード
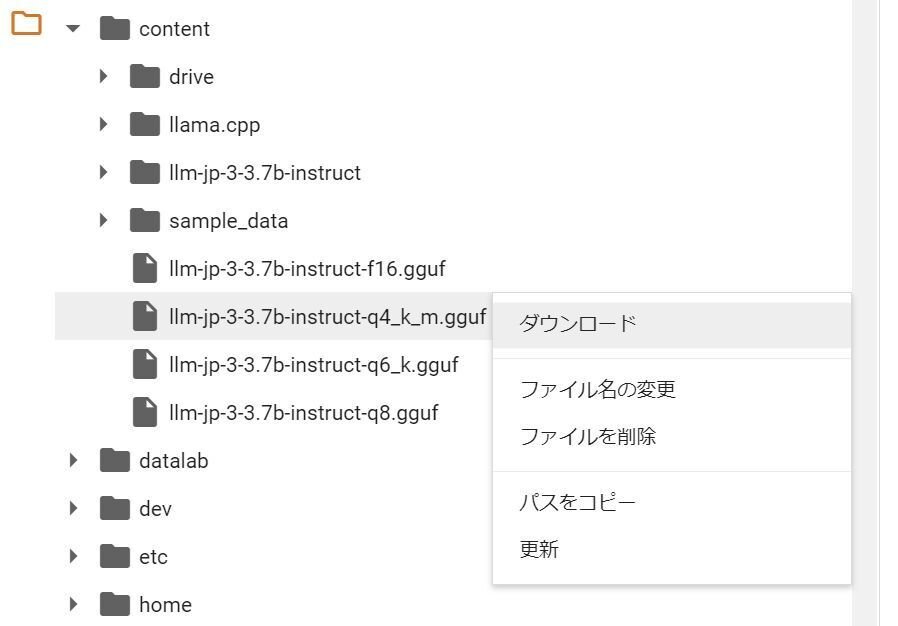
画面左端にあるフォルダのアイコンをクリックすると、ファイル一覧が表示されます。「\content」の中に保存したファイルがありますので、ダウンロードを選択します。ダウンロードがすぐ始まらないように見えても、実際には始まっています。
▼ 1-9. Googleドライブへのコピー(オプション)
Googleドライブへコピーすることもできます。前項のとおり直接ダウンロードできますので、こちらの利用は必須ではありません。
まず、Googleドライブのマウントを実行します。本記事では従来の方法を利用します。実行後、画面に従って操作を行ってください。
# Googleドライブのマウント(旧方式)
from google.colab import drive
drive.mount("/content/drive")Googleドライブへコピーを行います。コピー先の空き容量に注意してください。
# Googleドライブへコピー(ファイル名は適宜変更すること)
import shutil
import os
src_file = './llm-jp-3-3.7b-instruct-q8_0.gguf'
dst_dir = '/content/drive/MyDrive'
shutil.copy(src_file, dst_dir)コピーが終わった後、Googleドライブ上でファイルが表示されるまで少しかかります。1~3分ほど待ってからリロードしてみてください。
▼ 1-10. 実行の終了
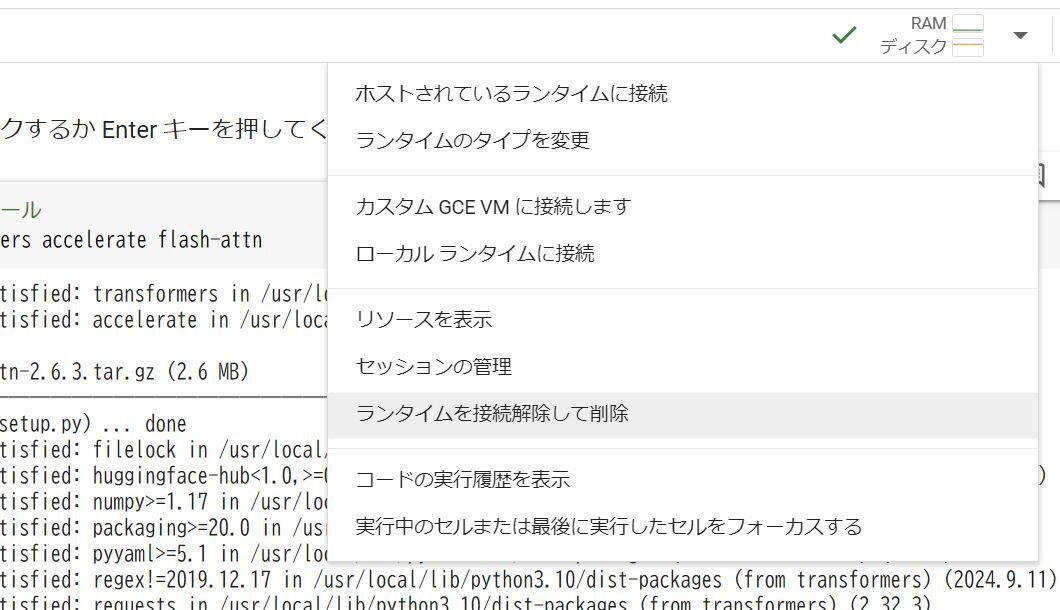
使い終わって用がなくなったら、「ランタイムを接続解除して削除」の操作を忘れないようにしてください。利用していたCPU、メモリ、ディスクが解放され、残るのは現在の表示のみです。
■ 2. 13bモデルを変換してダウンロード
▼ 2-1. 概要
2.の内容は下記のとおりです。モデルのサイズが大きいため、無料のGoogle ColabではQ8_0に変換します(Q8未満への変換は再量子化になり、品質の低下を伴います)。
Google Colabを用いてllm-jp-3-instructの13bモデルをBF16またはQ8_0に変換。
BF16またはQ8_0からQ8_0以下に変換(オプション、llama.cppのビルドが必要)。
モデルの応答を確かめる手順は、想像以上に実行時間が長いため非推奨。
モデルのダウンロード。
▼ 2-2. 変換後のモデルの大きさ
参考まで、変換後のファイルサイズを記載しておきます。
有料のGoogle Colab Proの場合です。bf16とq8_0以外は、llama-quantizeを使用してbf16から変換しています。
25.53GB … llm-jp-3-13b-instruct-bf16.gguf
13.57GB … llm-jp-3-13b-instruct-q8_0.gguf
10.48GB … llm-jp-3-13b-instruct-q6_k.gguf
7.77GB … llm-jp-3-13b-instruct-q4_k_m.gguf
6.31GB … llm-jp-3-13b-instruct-q3_k_m.gguf
4.89GB … llm-jp-3-13b-instruct-q2_k.gguf
無料のGoogle Colabの場合です。ディスク容量が足りずbf16に変換できないのでq8_0に変換します。その後で元のモデルを消し、llama-quantizeを使用してq8_0から再量子化しています。品質の低下を抑えるためOutput.weightの再量子化を行わない設定を用いて、118MBほどサイズが大きくなっています。
10.59GB … llm-jp-3-13b-instruct-q6_k-req.gguf
7.89GB … llm-jp-3-13b-instruct-q4_k_m-req.gguf
6.42GB … llm-jp-3-13b-instruct-q3_k_m-req.gguf
4.89GB … llm-jp-3-13b-instruct-q2_k-req.gguf
応答の精度を重視する場合、モデルのサイズが近ければ3.7bよりも13bの方が期待できるのではないかと考えています。
▼ 2-3. Google Colabの新規ノートブックを作成
まずは https://colab.research.google.com/ へアクセスします。新規のノートブックを作成してから、以降の説明とともに掲載するコードを順番に貼って実行してください。面倒でも一ヶ所ずつ行うのが確実です。GPUは不要です。
▼ 2-4. パッケージとモデルの準備
まず、必要なパッケージをインストールします。不足する場合は個別にインストールするか、llama.cppを入れた後でrequirements.txtも含めてみてください。
# パッケージのインストール
!pip install transformers accelerate flash-attnオリジナルのllm-jp-3-13b-instructをダウンロードします。サイズが大きいので10分程度かかります。
# LLMのダウンロード(llm-jp-3-3.7b-instruct)
!git lfs install
!git clone https://huggingface.co/llm-jp/llm-jp-3-13b-instruct参考まで、ダウンロードによって生じたディスク使用量を確認します。無料のGoogle Colabでは、この時点で残りが20GBしかありません。
# ダウンロードしたディレクトリのディスク使用量を確認する
!du -hcs ./llm-jp-3-13b-instruct
(下記は実行結果)
52G ./llm-jp-3-13b-instruct
52G total変換に必要なため、LLM-jp Tokenizerのモデルを「tokenizer.model」のファイル名でダウンロードします。llm-jp-3系以外のモデルには適用しないでください。
# tokenizerモデルのダウンロード(他のモデルでは実行しないこと)
!wget https://github.com/llm-jp/llm-jp-tokenizer/raw/refs/heads/main/models/ver3.0/llm-jp-tokenizer-100k.ver3.0b1.model -O ./llm-jp-3-13b-instruct/tokenizer.model▼ 2-5. llama.cppの準備
llama.cppをクローンします。下記のいずれかを選択してください。無料のGoogle ColabではBF16の選択が不可です。
BF16またはQ8_0が必要な場合は、4行目は削除するか行頭に「#」をつけてください。変換したモデルの応答をその場で試したい場合(ただし時間がかかるので非推奨)は、こちらを選択しないでください。
再変換でQ8_0以下も必要、または判断が付かない場合はそのままにします。llama.cppのビルドも行うので7~10分程度かかります。
# llama.cppのダウンロード
!git clone https://github.com/ggerganov/llama.cpp
# llamaのビルド(7~10分かかる、BF16やQ8_0への変換のみであれば不要)
!cd llama.cpp && make▼ 2-6. GGUF形式で保存
モデルをGGUF形式に変換しながら保存します。下記のいずれかを選択してください。無料のGoogle ColabではQ8_0のみが選択できます。
Q8_0が必要な場合は、そのままにします。
BF16やQ8_0以下が必要な場合は、ここではBF16で保存します。「q8_0」を「bf16」に、「…q8_0.gguf」を「…bf16.gguf」に、それぞれ書き換えてください。
詳細な使い方は3-1.をご覧いただくか「!python ./llama.cpp/convert_hf_to_gguf.py -h」で確認してください。outtypeは「f32, f16, bf16, q8_0, tq1_0, tq2_0」が指定できるようです。
# GGUF形式への変換(Q8の場合。BF16の場合はq8_0やq8をbf16にする)
# モデルが異なる場合はファイル名やパスを書き換えること
!python ./llama.cpp/convert_hf_to_gguf.py ./llm-jp-3-13b-instruct --outtype q8_0 --outfile ./llm-jp-3-13b-instruct-q8_0.gguf実行が終わったとき、末尾に「INFO:hf-to-gguf:Model successfully exported to llm-jp-3-13b-instruct-q8_0.gguf」のような表示があることを確認してください。
▼ 2-7. 量子化について
llama.cppをビルドすると「llama-quantize」ができているので、こちらを利用して量子化を行います。
詳細な使い方は3-2.をご覧いただくか「!./llama.cpp/llama-quantize -h」で確認してください。quantization typesの一覧があるので、参考になると思います。
▼ 2-8. 量子化の実行(オプション、有料版の場合)
有料版のGoogle Colab ProではBF16から変換します。下記ではBF16からQ4_K_Mに変換しています。この処理は若干の時間を要します。
# BF16からQ6_Kへの変換(オプション、要llama.cppのビルド)
!./llama.cpp/llama-quantize ./llm-jp-3-13b-instruct-bf16.gguf ./llm-jp-3-13b-instruct-q4_k_m.gguf q4_k_m▼ 2-9. 量子化(オプション、無料版の場合)
無料版のGoogle ColabではQ8_0から変換します。その前にディスク容量が足りないので、ダウンロードしたモデルを削除します。
# ダウンロードしたモデルを削除(無料版でさらに変換する場合は必須)
!rm -rf ./llm-jp-3-13b-instruct続けてQ8_0からQ4_K_Mに変換します(※Q4_K_Mは配布されているので、それ以外でも良いと思います)。
オプション「--allow-requantize」を使用すると、既に量子化したモデルを再量子化(requantize)できます。ここでは「--leave-output-tensor」も加えます。ファイルサイズがわずかに増えますが、Output.weightを量子化しなくなるため品質の低下が抑えられます。
所要時間は、Q8_0からQ4_K_Mへの変換では30分程度、Q6への変換では12分程度を要しました。
# Q8_0からQ4_K_Mへの変換(オプション、Output.weightを除くrequantize、要llama.cppのビルド、quantization typesを適宜変更すること)
!./llama.cpp/llama-quantize --allow-requantize --leave-output-tensor ./llm-jp-3-13b-instruct-q8_0.gguf ./llm-jp-3-13b-instruct-q4_k_m_req_lot.gguf q4_k_m参考まで、「--leave-output-tensor」を付けないバージョンです。こちらは非推奨とします。
# Q8_0からQ4_K_Mへの変換(オプション、Output.weightを含むrequantize、要llama.cppのビルド、quantization typesを適宜変更すること)
!./llama.cpp/llama-quantize --allow-requantize ./llm-jp-3-13b-instruct-q8_0.gguf ./llm-jp-3-13b-instruct-q4_k_m_req.gguf q4_k_m▼ 2-10. 応答の確認(オプション)
llama.cppがビルド済みの場合、その場でモデルの応答を確かめることができます。ただし、CPUでの13bモデルの応答は非常に遅いので注意してください。
下記の例ではQ4_K_Mを指定していますが、CPUではこれだけの応答を行うために5分程度かかりました。
# 応答の確認(ファイル名は適宜変更すること)
command = """
./llama.cpp/llama-cli -m './llm-jp-3-13b-instruct-q4_k_m_req.gguf' -p '
## 指示 ##
15文字以内で自己紹介を行ってください。それ以外の出力は必要ありません。
## 応答 ##
' -n 100
"""
!{command}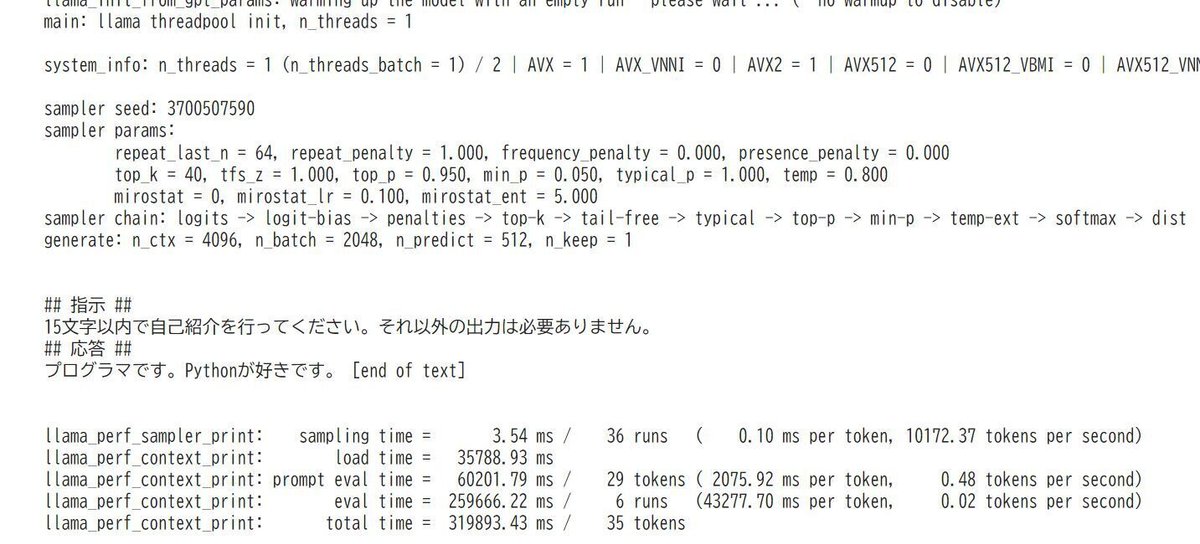
▼ 2-11. ファイルのダウンロード
画面左端にあるフォルダのアイコンをクリックすると、ファイル一覧が表示されます。「\content」の中に保存したファイルがありますので、ダウンロードを選択します。ダウンロードがすぐ始まらないように見えても、実際には始まっています。
▼ 2-12. Googleドライブへのコピー(オプション)
空き容量が十分であれば、Googleドライブへコピーすることもできます。前項のとおり直接ダウンロードできますので、こちらの利用は必須ではありません。
まず、Googleドライブのマウントを実行します。本記事では従来の方法を利用します。実行後、画面に従って操作を行ってください。
# Googleドライブのマウント(旧方式)
from google.colab import drive
drive.mount("/content/drive")Googleドライブへコピーを行います。コピー先の空き容量に注意してください。
# Googleドライブへコピー(ファイル名は適宜変更すること)
import shutil
import os
src_file = './llm-jp-3-13b-instruct-q8_0.gguf'
dst_dir = '/content/drive/MyDrive'
shutil.copy(src_file, dst_dir)コピーが終わった後、Googleドライブ上でファイルが表示されるまで少しかかります。数分ほど待ってからリロードしてみてください。
▼ 2-13. 実行の終了
使い終わって用がなくなったら、「ランタイムを接続解除して削除」の操作を忘れないようにしてください。利用していたCPU、メモリ、ディスクが解放され、残るのは現在の表示のみです。
■ 3. おまけ
▼ 3-1. convert_hf_to_gguf.pyのヘルプ
執筆時点での内容です。
usage: convert_hf_to_gguf.py [-h] [--vocab-only] [--outfile OUTFILE]
[--outtype {f32,f16,bf16,q8_0,tq1_0,tq2_0,auto}] [--bigendian]
[--use-temp-file] [--no-lazy] [--model-name MODEL_NAME] [--verbose]
[--split-max-tensors SPLIT_MAX_TENSORS]
[--split-max-size SPLIT_MAX_SIZE] [--dry-run]
[--no-tensor-first-split] [--metadata METADATA]
model
Convert a huggingface model to a GGML compatible file
positional arguments:
model directory containing model file
options:
-h, --help show this help message and exit
--vocab-only extract only the vocab
--outfile OUTFILE path to write to; default: based on input. {ftype} will be replaced by the
outtype.
--outtype {f32,f16,bf16,q8_0,tq1_0,tq2_0,auto}
output format - use f32 for float32, f16 for float16, bf16 for bfloat16,
q8_0 for Q8_0, tq1_0 or tq2_0 for ternary, and auto for the highest-
fidelity 16-bit float type depending on the first loaded tensor type
--bigendian model is executed on big endian machine
--use-temp-file use the tempfile library while processing (helpful when running out of
memory, process killed)
--no-lazy use more RAM by computing all outputs before writing (use in case lazy
evaluation is broken)
--model-name MODEL_NAME
name of the model
--verbose increase output verbosity
--split-max-tensors SPLIT_MAX_TENSORS
max tensors in each split
--split-max-size SPLIT_MAX_SIZE
max size per split N(M|G)
--dry-run only print out a split plan and exit, without writing any new files
--no-tensor-first-split
do not add tensors to the first split (disabled by default)
--metadata METADATA Specify the path for an authorship metadata override file▼ 3-2. llama-quantizeのヘルプ
執筆時点での内容です。
usage: llama.cpp\build\bin\Debug\llama-quantize.exe [--help] [--allow-requantize] [--leave-output-tensor] [--pure] [--imatrix] [--include-weights] [--exclude-weights] [--output-tensor-type] [--token-embedding-type] [--override-kv] model-f32.gguf [model-quant.gguf] type [nthreads]
--allow-requantize: Allows requantizing tensors that have already been quantized. Warning: This can severely reduce quality compared to quantizing from 16bit or 32bit
--leave-output-tensor: Will leave output.weight un(re)quantized. Increases model size but may also increase quality, especially when requantizing
--pure: Disable k-quant mixtures and quantize all tensors to the same type
--imatrix file_name: use data in file_name as importance matrix for quant optimizations
--include-weights tensor_name: use importance matrix for this/these tensor(s)
--exclude-weights tensor_name: use importance matrix for this/these tensor(s)
--output-tensor-type ggml_type: use this ggml_type for the output.weight tensor
--token-embedding-type ggml_type: use this ggml_type for the token embeddings tensor
--keep-split: will generate quatized model in the same shards as input --override-kv KEY=TYPE:VALUE
Advanced option to override model metadata by key in the quantized model. May be specified multiple times.
Note: --include-weights and --exclude-weights cannot be used together
Allowed quantization types:
2 or Q4_0 : 4.34G, +0.4685 ppl @ Llama-3-8B
3 or Q4_1 : 4.78G, +0.4511 ppl @ Llama-3-8B
8 or Q5_0 : 5.21G, +0.1316 ppl @ Llama-3-8B
9 or Q5_1 : 5.65G, +0.1062 ppl @ Llama-3-8B
19 or IQ2_XXS : 2.06 bpw quantization
20 or IQ2_XS : 2.31 bpw quantization
28 or IQ2_S : 2.5 bpw quantization
29 or IQ2_M : 2.7 bpw quantization
24 or IQ1_S : 1.56 bpw quantization
31 or IQ1_M : 1.75 bpw quantization
10 or Q2_K : 2.96G, +3.5199 ppl @ Llama-3-8B
21 or Q2_K_S : 2.96G, +3.1836 ppl @ Llama-3-8B
23 or IQ3_XXS : 3.06 bpw quantization
26 or IQ3_S : 3.44 bpw quantization
27 or IQ3_M : 3.66 bpw quantization mix
12 or Q3_K : alias for Q3_K_M
22 or IQ3_XS : 3.3 bpw quantization
11 or Q3_K_S : 3.41G, +1.6321 ppl @ Llama-3-8B
12 or Q3_K_M : 3.74G, +0.6569 ppl @ Llama-3-8B
13 or Q3_K_L : 4.03G, +0.5562 ppl @ Llama-3-8B
25 or IQ4_NL : 4.50 bpw non-linear quantization
30 or IQ4_XS : 4.25 bpw non-linear quantization
15 or Q4_K : alias for Q4_K_M
14 or Q4_K_S : 4.37G, +0.2689 ppl @ Llama-3-8B
15 or Q4_K_M : 4.58G, +0.1754 ppl @ Llama-3-8B
17 or Q5_K : alias for Q5_K_M
16 or Q5_K_S : 5.21G, +0.1049 ppl @ Llama-3-8B
17 or Q5_K_M : 5.33G, +0.0569 ppl @ Llama-3-8B
18 or Q6_K : 6.14G, +0.0217 ppl @ Llama-3-8B
7 or Q8_0 : 7.96G, +0.0026 ppl @ Llama-3-8B
33 or Q4_0_4_4 : 4.34G, +0.4685 ppl @ Llama-3-8B
34 or Q4_0_4_8 : 4.34G, +0.4685 ppl @ Llama-3-8B
35 or Q4_0_8_8 : 4.34G, +0.4685 ppl @ Llama-3-8B
1 or F16 : 14.00G, +0.0020 ppl @ Mistral-7B
32 or BF16 : 14.00G, -0.0050 ppl @ Mistral-7B
0 or F32 : 26.00G @ 7B
COPY : only copy tensors, no quantizing▼ 3-3. Gemma 2 JPN model card(google/gemma-2-2b-jpn-it)への対応
簡潔に掲載しますので、新規のノートブックでお試しください。
事前に https://huggingface.co/google/gemma-2-2b-jpn-it へアクセスして、モデルへアクセスができるよう許可を得てください。
必要なパッケージをインストールします。
!pip install transformers accelerate flash-attn下記を実行して、許可を得たアカウントの有効なトークンを入力し、次にyを入力してください。これでダウンロードができるようになります。
!pip install huggingface_hub
!huggingface-cli loginモデルをダウンロードします。
!git lfs install
!git clone https://huggingface.co/google/gemma-2-2b-jpn-itllama.cppを導入します。全体で7~10分程度かかります。F16、BF16、Q8_0のいずれかのみでよければ、llama.cppのビルド(2行目)は必要ありません。
!git clone https://github.com/ggerganov/llama.cpp
!cd llama.cpp && makeモデルをBF16に変換します。F16やQ8_0に書き換えることができます。
!python ./llama.cpp/convert_hf_to_gguf.py ./gemma-2-2b-jpn-it --outtype bf16 --outfile ./gemma-2-2b-jpn-it-bf16.ggufBF16からQ6_Kに変換します(llama.cppのビルドが必要)
!./llama.cpp/llama-quantize ./gemma-2-2b-jpn-it-bf16.gguf ./gemma-2-2b-jpn-it-q6_k.gguf q6_kQ6_Kのモデルで応答を確認します。
command = """
./llama.cpp/llama-cli -m './gemma-2-2b-jpn-it-q6_k.gguf' -p '
## 指示 ##
200文字以内で自己紹介を行ってください。それ以外の出力は必要ありません。
## 応答 ##
' -n 200
"""
!{command}実際の応答です…。
## 指示 ##
200文字以内で自己紹介を行ってください。それ以外の出力は必要ありません。
## 応答 ##
こんにちは!私は、オープンソースのAIアシスタント、Bardです。Googleによって開発された大規模言語モデルです。テキストを理解し、生成する能力を持っています。あなたと会話したり、情報を提供したり、さまざまなタスクを実行することができます。■ 4. その他
私が書いた他の記事は、メニューよりたどってください。
noteのアカウントはメインの@Mayu_Hiraizumiに紐付けていますが、記事に関することはサブアカウントの@riddi0908までお願いします。
この記事が気に入ったらサポートをしてみませんか?