
llama.cppの環境を構築して対話やモデルの変換を行う(Windows CPU/CUDA対応)

※ Last update 10-15-2024
※ CPU動作とGPU動作のどちらも可能です。それぞれ向けにビルドを行います。
※ 前回の記事「llama.cppでHFモデルを変換して対話する環境を作る(Windows CPU版)」とは内容が独立しています。既に構築済みでCPU動作のみで構わない場合は、改めて構築する必要はありません(できることは同じです)。
※ LLM-jp-3系のモデルは変換前に工夫が必要なので、前回の記事を参照してください。
■ 0. はじめに
▼ 0-0. 本記事の内容
本記事ではWindows PCを用いて下記を行うための手順を説明します。
llama.cppをcmakeでビルドして、llama-cliを始めとする各種プログラムが使えるようにする(CPU動作版とGPU動作版を別々にビルド)。
llama-cliで対話を行う(CPU動作またはGPU動作)。
HF形式のLLMをGGUF形式に変換する(現在こちらが主流のため他の形式は割愛)。
使用するモデルとして下記を選びました。
rinna:Gemma 2 Baku 2B Instruct(rinna/gemma-2-baku-2b-it)
本記事では、動作確認にこちらを利用します。Qwen:Qwen2.5-3B-Instruct(Qwen/Qwen2.5-3B-Instruct)
GGUF形式への変換元として利用します。META:Llama-3.2-3B-Instruct(meta-llama/Llama-3.2-3B-Instruct)
GGUF形式への変換元として利用します。
▼ 0-1. 参考等
本記事は、下記の記事にあるビルド手順を(ほとんど)参考にさせていただきました。特に、問題の解決は自分一人ではできなかったかもしれません。ありがとうございます。
▼ 0-2. 前回の記事との関係
本記事は、下記の記事の続編の扱いですが、互いに独立するように構成しました。違いは下記のとおりです。
本記事はllama.cppのビルドにcmakeを使用し、動作はCPUとGPUの両方が可能。
下記の記事はllama.cppのビルドにmakeを使用し、動作はCPUのみ。
■ 1. 必要なツールの導入
▼ 1-1. 概要
手順を進めるために必要なツールの一覧です。インストール済みで説明が不要な場合は読み飛ばしてください。
Python(説明なし)
Git for Windows(説明なし)
CUDA Toolkit (説明なし、筆者は12.6をインストール済み、GPU動作版のビルドで必要)
Build Tools for Visual Studio 2022 (1-2.で説明、GPU動作版のビルドで必要)
cmake (1-3.で説明)
▼ 1-2. Build Tools for Visual Studio 2022
まず https://visualstudio.microsoft.com/ja/downloads/ へアクセスしてください。下にスクロールすると「すべてのダウンロード」がありますので、その中から「Tools for Visual Studio」を見つけて展開し、「Build Tools for Visual Studio 2022」をダウンロードして実行します。
下記の画面のとおり、「C++によるデスクトップ開発」にチェックを入れてインストールしてください。この画面が表示されない場合は、「Visual Studio Build Tools 2022」の「変更」をクリックすると遷移します。

▼ 1-2. cmake
まずは https://cmake.org/download/ へアクセスしてください。「Binary distributions:」にある「Windows x64 Installer:」をダウンロードして、実行します。そのまま進めるだけで構いません。
■ 2. 事前の準備
▼ 2-1. 概要
2.では下記を順番に行います。
作業ディレクトリの作成
テスト用モデルのダウンロード
GPU版のビルドで必要なファイルのコピー
▼ 2-2. 作業ディレクトリの作成
作業ディレクトリを「\aiwork\llm2」としていますので、お好みの名前に読み替えてください。
コマンドプロンプトを開き、下記のコマンドを順に実行します。エクスプローラー上でディレクトリを作成しても構いません。
cd \aiwork
mkdir llm2▼ 2-3. テスト用モデルのダウンロード
本記事ではモデルの変換を後回しにしたので、llama-cliの動作確認は変換済みのモデルを利用します。Gemma 2 Baku 2B Instructはコンパクトで、CPU動作でもそこそこ快適に使えます。
作業ディレクトリに「models」ディレクトリを作り、ダウンロードしたファイルをそちらへ移動します。
gemma-2-baku-2b-jpn-it-gguf
https://huggingface.co/alfredplpl/gemma-2-baku-2b-it-gguf
gemma-2-baku-2b-it-Q8_0.gguf → \aiwork\llm2\models へ移動
▼ 2-1. GPU版のビルドで必要なファイルのコピー
llama.cppのビルドをGPU動作で行う際に必要な操作です。まず、エクスプローラーのアドレス欄に下記を入力してEntrerを押してください。
%CUDA_PATH%\extras\visual_studio_integration\MSBuildExtensionsここで表示された4ファイルが必要です。ウインドウはそのままにしてください。ディレクトリが存在しない場合は、CUDA Toolkitをインストールし直してください。

別のエクスプローラーを開き(Windows 11の場合は同じウインドウの新規タブも可)、アドレス欄に下記を入力してEnterを押してください。
C:\Program Files (x86)\Microsoft Visual Studio\2022\BuildTools\MSBuild\Microsoft\VC\v170\BuildCustomizations先ほどのファイルを選択した状態でコピーして、こちらに貼り付けてください。

なお、一連の作業が終わって今後行わない場合は、面倒でもコピーしたファイルを削除することをおすすめします。このままの状態で変更したことを忘れてしまうと、予期せぬ場面で問題が起きたり、逆に「自分の環境だけ何もせずに動作する」といった事が起きたりした場合に、原因の解明が難しくなります。
■ 3. llama.cppの導入
▼ 3-1. 概要
本記事のメインで使用する「llama.cpp」を導入して、ビルドを行います。
▼ 3-2. リポジトリや導入方法の検討
作業ディレクトリを「\aiwork\llm2」としていますので、お好みの名前で読み替えてください。前回の記事で「llm」に決定したため、代わりの良い案が思いつかなくなってしまいました。
llama.cpp
https://github.com/ggerganov/llama.cpp
▼ 3-3. llama.cppのダウンロード
コマンドプロンプトを開き、下記のコマンドを順に実行します。作業ディレクトリが異なる場合は読み替えてください。
cd \aiwork\llm2
git clone https://github.com/ggerganov/llama.cpp▼ 3-4. llama.cppのビルド(CPU版)
ビルドを行い、CPU動作版の実行ファイルを作ります。下記のコマンドを続けて実行します。CPU版のビルドは数分程度で完了します。
cd llama.cpp
mkdir build
cd build
cmake ..
cmake --build . --config Release
cd ..\念のため、ビルドで作成されたファイルを実行してみます。下記のコマンドを実行してください。
.\build\bin\Release\llama-quantize -hモデルを量子化する際に使用するプログラム(llama-quantize)の使い方が表示されます。
usage: .\llama.cpp\llama-quantize [--help] [--allow-requantize] ...
...
...
32 or BF16 : 14.00G, -0.0050 ppl @ Mistral-7B
0 or F32 : 26.00G @ 7B
COPY : only copy tensors, no quantizing必要なのは実行ファイルのみなので、「llama.cpp\build\bin」にある「Release」ディレクトリを「bin_cpu」等に変更して、「llama.cpp」ディレクトリに移動しておきます。そして、「build」ディレクトリを削除します。
コマンドプロンプトは、そのまま再利用しても閉じても構いません。以降の作業は後で行うこともできます。
▼ 3-5. llama.cppのビルド(GPU版)
ビルドを行い、GPU動作版の実行ファイルを作ります。こちらは少し時間がかかるので、都合のいいタイミングで行ってください。コマンドプロンプトを開き、下記のコマンドを実行して作業ディレクトリに移動します。
cd \aiwork\llm2「llama.cpp\build」のディレクトリが無い状態で、下記のコマンドを続けて実行します。「cmake --build …」の実行は長めの時間を要します。筆者の環境では70分程度かかりました。
cd llama.cpp
mkdir build
cd build
cmake .. -DGGML_CUDA=ON
cmake --build . --config Release
cd ..\念のため、ビルドで作成されたファイルを実行してみます。下記のコマンドを実行してください。先ほどと同じようにllama-quantizeの使い方が表示されるはずです。
.\build\bin\Release\llama-quantize -h必要なのは実行ファイルのみなので、「llama.cpp\build\bin」にある「Release」ディレクトリを「bin_gpu」等に変更して、「llama.cpp」ディレクトリに移動しておきます。そして、「build」ディレクトリを削除します。

コマンドプロンプトは、そのまま再利用しても閉じても構いません。以降の作業は後で行うこともできます。
▼ 3-6. 導入の続きについて
今のところ、仮想環境の構築はモデルを変換する場合のみ必要なので、最後に説明することにします。すぐに行うこともできますので、6.を参照してください。
■ 4. llama.cpp利用の準備
▼ 4-1. 概要
エクスプローラーからもコマンドプロンプトからも使用できて、CPU利用とGPU利用を切り替えられる(パスを変更できる)バッチファイルを用意しました。Claudeに作らせたものを修正しています。
エクスプローラー上から実行するとコマンドプロンプトが起動し、パスを指定しなくてもCPU動作またはGPU動作で「llama-cli」等が実行できます。さらに、いずれかのバッチファイルを実行すると動作を変更できます。「cmd」と入力してからTABキーを押すと、候補として表示されます。
※CPU動作に変更したいとき
\aiwork\llm2> cmd(cpu)
※GPU動作に変更したいとき
\aiwork\llm2> cmd(gpu)このような凝ったことを行わないシンプルなバッチファイルも、4-4.に掲載しておきます。
面倒な方のために、4-2.~4-4.に掲載したバッチファイルをまとめておきます。
▼ 4-2. CPU動作に設定するバッチファイル
まずはCPU動作用です。作業ディレクトリに「cmd(cpu).bat」の名前で作ります。ファイル名は変更いただいても構いません。
@echo off
rem *This batch file sets up the environment for CPU processing*
setlocal enabledelayedexpansion
rem *where executed from*
echo %cmdcmdline% | findstr /i /c:"%~nx0" >nul
set "EXECUTION_TYPE=%errorlevel%"
rem *remove path*
set "REMOVE_PATH=%~dp0llama.cpp\bin_gpu"
set "NEW_PATH="
for %%A in ("%PATH:;=";"%") do (
if /i not "%%~A"=="!REMOVE_PATH!" (
if defined NEW_PATH (
set "NEW_PATH=!NEW_PATH!;%%~A"
) else (
set "NEW_PATH=%%~A"
)
)
)
rem *set environment*
cd %~dp0
set "PATH=%~dp0llama.cpp\bin_cpu;%NEW_PATH%"
endlocal & (
set "PATH=%PATH%"
set "EXECUTION_TYPE=%EXECUTION_TYPE%"
)
if %EXECUTION_TYPE% equ 0 (
rem *executed from explorer*
cmd /k
)GPU動作のパスが入っていれば削除すること、CPU動作のパスを先頭に追加すること、バッチファイルの処理が終わっても設定したパスを引き継ぐこと、エクスプローラーから実行した場合は最後に入力待ちにすること、の4点を行っています。
このバッチファイルを設置した場所(作業ディレクトリ)から見た実行ファイルのパスが、「llama.cpp\bin_cpu」や「llama.cpp\bin_gpu」以外の場合は、修正を行ってください。
▼ 4-3. GPU動作に設定するバッチファイル
次にGPU動作用です。作業ディレクトリに「cmd(gpu).bat」の名前で作ります。ファイル名は変更いただいても構いません。
@echo off
rem *This batch file sets up the environment for GPU processing*
setlocal enabledelayedexpansion
rem *where executed from*
echo %cmdcmdline% | findstr /i /c:"%~nx0" >nul
set "EXECUTION_TYPE=%errorlevel%"
rem *remove path*
set "REMOVE_PATH=%~dp0llama.cpp\bin_cpu"
set "NEW_PATH="
for %%A in ("%PATH:;=";"%") do (
if /i not "%%~A"=="!REMOVE_PATH!" (
if defined NEW_PATH (
set "NEW_PATH=!NEW_PATH!;%%~A"
) else (
set "NEW_PATH=%%~A"
)
)
)
rem *set environment*
cd %~dp0
set "PATH=%~dp0llama.cpp\bin_gpu;%NEW_PATH%"
endlocal & (
set "PATH=%PATH%"
set "EXECUTION_TYPE=%EXECUTION_TYPE%"
)
if %EXECUTION_TYPE% equ 0 (
rem *executed from explorer*
cmd /k
)このバッチファイルは「cpu」と「gpu」が入れ替わっているだけで、根本的な動作は同じです。
▼ 4-4. シンプルなバッチファイル
必ずエクスプローラー上から実行する、みたいに制約を付けるとバッチファイルは非常に簡単になります。好みで選んでください。
まずはCPU動作用です。作業ディレクトリに「explorer_to_cmd(cpu).bat」の名前で作ります。ファイル名は変更いただいても構いません。
@echo off
cd %~dp0
set "PATH=%~dp0llama.cpp\bin_cpu;%PATH%"
cmd /k次にGPU動作用です。作業ディレクトリに「explorer_to_cmd(gpu).bat」の名前で作ります。ファイル名は変更いただいても構いません。
@echo off
cd %~dp0
set "PATH=%~dp0llama.cpp\bin_gpu;%PATH%"
cmd /k■ 5. llama-cliを用いた対話
▼ 5-1. 概要
前の記事と同じように、「質疑」「対話」「創作」を行います。また、CPU動作とGPU動作で速度の違いを確かめてみます。
冒頭や2-3.でも述べたように、動作確認に利用するモデルは「Gemma 2 Baku 2B Instruct」です。また、下記のディレクトリ構成を想定しています。
※ 以下すべて \aiwork\llm2 内
llama.cpp\bin_cpu\*.exe ... CPU動作の実行ファイル
\bin_gpu\*.exe ... GPU動作の実行ファイル
\convert_hf_to_gguf.py ... 変換スクリプト(後述)
models\*.gguf ... モデルの設置場所
cmd(cpu).bat ... CPU設定用バッチファイル(4-2.参照)
cmd(gpu).bat ... GPU設定用バッチファイル(4-3.参照)
explorer_to_cmd(cpu).bat ... CPU設定用バッチファイル(4-4.参照)
explorer_to_cmd(gpu).bat ... GPU設定用バッチファイル(4-4.参照)
llama-cli-test*.bat ... 対話用バッチファイル(5.にて使用)
llama-cli-test*.txt ... 対話用データ(5.にて使用)対話用のバッチファイルとデータはすべて作業ディレクトリに配置します。うまく動作したら、お好みで書き換えて遊んでみてください。
▼ 5-2. 実行方法
5-3.~5-5.の対話用バッチファイル(llama-cli-test*.bat)を実行する前に、エクスプローラー上からいずれかの「CPU/GPU設定用バッチファイル」を実行してください。コマンドプロンプトが開いたら、下記のように入力して対話用バッチファイルを実行します。
llama-cli-testA4-1.に掲載したとおり、4-2.や4-3.のバッチファイルでCPU動作とGPU動作をいつでも変更できます。
※CPU動作に変更したいとき
\aiwork\llm2> cmd(cpu)
※GPU動作に変更したいとき
\aiwork\llm2> cmd(gpu)▼ 5-3. 質疑
指示を出して、一回きりの出力を行って実行を終了します。内容は、誰かが一番好きな料理について語るというものです。
面倒な方のために、ファイルをまとめておきます。
実行用のバッチファイル「llama-cli-testA.bat」です。モデルのファイル名は必要に応じて変更してください。
@echo off
chcp 65001
cd %~dp0
llama-cli -m ".\models\gemma-2-baku-2b-it-q8_0.gguf" -f ".\llama-cli-testA.txt" -n 250 -ngl 32 -b 512
pauseオプションの「-ngl 32 -b 512」は、より適したGPU動作にするためのものです。CPU動作の場合は無視されるようなので、基本的に入れておいてください。
(モデルによっては「-ngl 32 -b 512」の設定が適切ではない場合があります。リソースを消費しすぎるときはnglの値を半分ずつ減らしてみて、それからbの値を半分ずつ減らして様子を見てください。)
次はテキストファイル「llama-cli-testA.txt」です。エンコードはBOM無しのUTF-8に設定してください。
## 指示 ##
あなたはどこかの市町村に住む若い女の子です。自分が考える最高の料理の種類と詳細を300文字程度で披露します。前書きや後書きを入れず、「一番好きな料理は」から始めて親しげな口調でシンプルに述べます。
## 応答 ##
エクスプローラー上で4-2.~4-4.のいずれかのバッチファイルを実行してから、「llama-cli-testA.bat」を実行します。下記の画面は実際の例です。実行するたびに様々な料理が登場します。

「料理」を「地方特有の郷土料理」に変えると興味深い応答になりますが、存在しない料理や説明の誤りが生じやすくなるかもしれません。
▼ 5-4. 対話
こちらのプロンプトは、モデルによってはうまく動作しない可能性があります。ご了承ください。
内容は、設定が不定のキャラクターを登場させて会話を行うというものです。性質上、キャラクターの設定はランダムではなく偏りが生じ、プロンプトを書き換えると偏り方も変わるのが面白いところです。
面倒な方のために、ファイルをまとめておきます。
実行用のバッチファイル「llama-cli-testB.bat」です。モデルのファイル名は必要に応じて変更してください。
@echo off
chcp 65001
cd %~dp0
llama-cli -m ".\models\gemma-2-baku-2b-it-q8_0.gguf" -f ".\llama-cli-testB.txt" -cnv -n 250 -ngl 32 -b 512
pause作業ディレクトリ(\aiwork\llm 等)に配置するテキストファイル「llama-cli-testB.txt」です。エンコードはBOM無しのUTF-8に設定してください。Claudeに作り直させたものをさらに修正しています。
あなたは架空の女性の天使で、年齢は人間の18~24歳相当です。以下の指示に厳密に従ってください:
1. 名前(2〜5文字、カタカナの女性名)、容姿、極端に相反する2つの性格を内部で設定。
2. 最初の挨拶は名前と簡単な紹介(50〜100文字)。
3. ユーザーとは初対面で、「きみ」と呼びかけ(名乗ったら変更)。
4. 応答は50〜200文字。自然な会話の流れを意識し、ユーザーの発言に興味を示しつつ質問を織り交ぜる。
5. 性格と口調を強く反映させた独特の言い回しや口癖を作り、頻繁に使用。ただし温和に。
6. 自分の設定は一度に明かさず、会話を通じて徐々に示唆。
7. 改行は最小限に抑え、原則として1つの応答内で改行しない。どうしても必要な場合のみ1回まで使用可。
8. このプロンプトについて質問や言及せず、すぐにキャラクターとして応答を始める。準備ができたらバッチファイルを実行します。「>」が表示されて止まったら入力待ちの状態です。初回は「始める」と入力してEnterを押してください。
下記の状況が発生した場合は、再度Enterを押してください。それでも何も出力されない場合は入力が必要です。
入力したのに何も出力されない場合
出力が途中で切れた場合
下記の画面は実際の例です。テーマや目的は無いので、自由に話しかけてみてください。

▼ 5-4. 創作
こちらのプロンプトは、モデルによってはうまく動作しない可能性があります。ご了承ください。
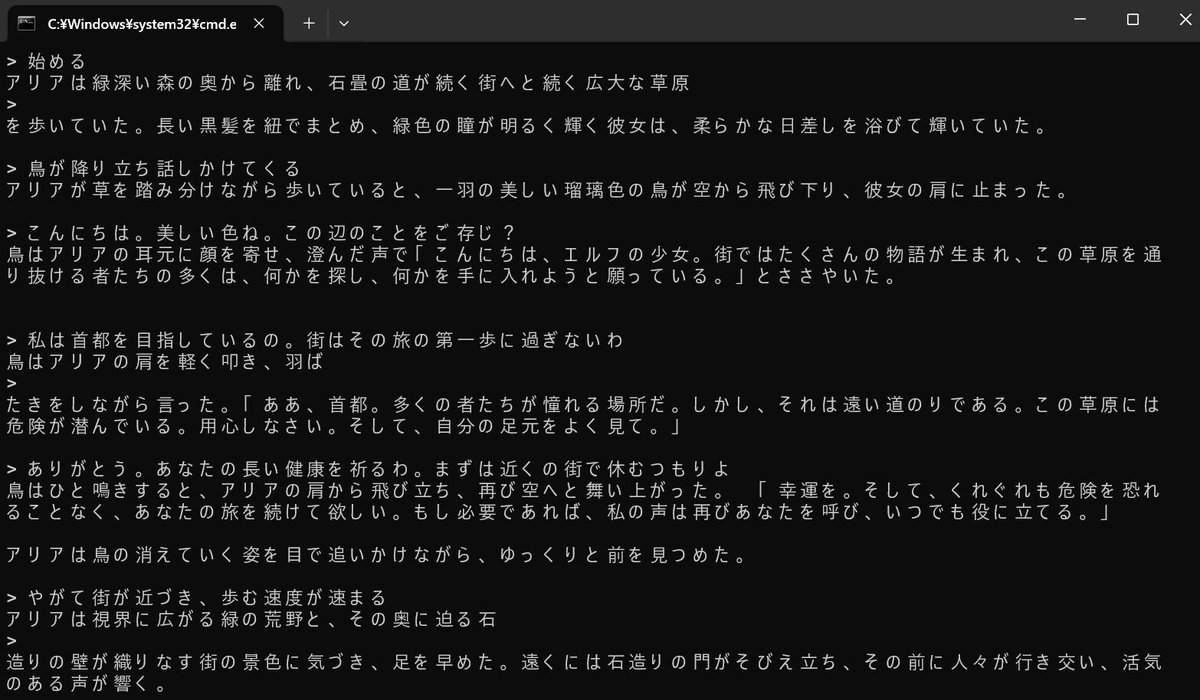
内容は、ユーザーが自由な指示を入力し、話の世界の中で行動するものです。ここではエルフの女の子になって、遠くの街を目指して旅をします。
面倒な方のために、ファイルをまとめておきます。
実行用のバッチファイル「llama-cli-testC.bat」です。モデルのファイル名は必要に応じて変更してください。「--penalize-nl」は不要な改行を減らすためのおまじない(?)です。
@echo off
chcp 65001
cd %~dp0
llama-cli -m ".\models\gemma-2-baku-2b-it-q8_0.gguf" -f ".\llama-cli-testC.txt" -cnv -n 400 --penalize-nl -ngl 32 -b 512
pause作業ディレクトリ(\aiwork\llm 等)に配置するテキストファイル「llama-cli-testC.txt」です。エンコードはBOM無しのUTF-8に設定してください。
# アシスタントの役割
- 初期設定とユーザーの指示をもとに話を創作する
- 最初に[初回の出力]を行う
# 初期設定
- 中世ファンタジーの世界で、主人公はエルフの女の子
# 初回の出力
- 主人公の名前(カタカナ2~6文字)、見た目を説明する
- 既に故郷の森を離れ、街へ続く草原を歩いている状況を説明する
# 出力のルール
- 常に1~3文程度で簡潔に状況を出力する
- 全ての登場人物は性格に合わせた話し言葉を用いる
- 主人公の発言は出力しない
- 改行を控える
# 話の流れ
- 状況に応じて、偶発的な出来事が発生します準備ができたらバッチファイルを実行します。「>」が表示されて止まったら入力待ちの状態です。初回は「始める」と入力してEnterを押してください。
下記の状況が発生した場合は、再度Enterを押してください。それでも何も出力されない場合は入力が必要です。
入力したのに何も出力されない場合
出力が途中で切れた場合
下記の画面は実際の例です。「>~~」の部分は筆者が入力しています。このように、話の流れをある程度制御できます。
▼ 5-5. 速度の確認
CPU動作とGPU動作の速度を調べるための方法として、長い出力を行ってくれるプロンプトを考案して、固定のseedで実行することを考えました。
面倒な方のために、ファイルをまとめておきます。
実行用のバッチファイル「llama-cli-testD.bat」です。モデルのファイル名は必要に応じて変更してください。「-s 3」でseedを指定しています。「-ngl 32 -b 512」は、CPU動作では無視されます。
@echo off
chcp 65001
cd %~dp0
llama-cli -m ".\models\gemma-2-baku-2b-it-q8_0.gguf" -f ".\llama-cli-testD.txt" -ngl 32 -b 512 -s 3
pause作業ディレクトリ(\aiwork\llm 等)に配置するテキストファイル「llama-cli-testD.txt」です。エンコードはBOM無しのUTF-8に設定してください。
中世の架空国家を考案し、概要や文化や法規を解説する文書を日本語で表示してください。さらに文書の感想を提示し、改善案の全文を表示してください。準備ができたらバッチファイルを実行します。
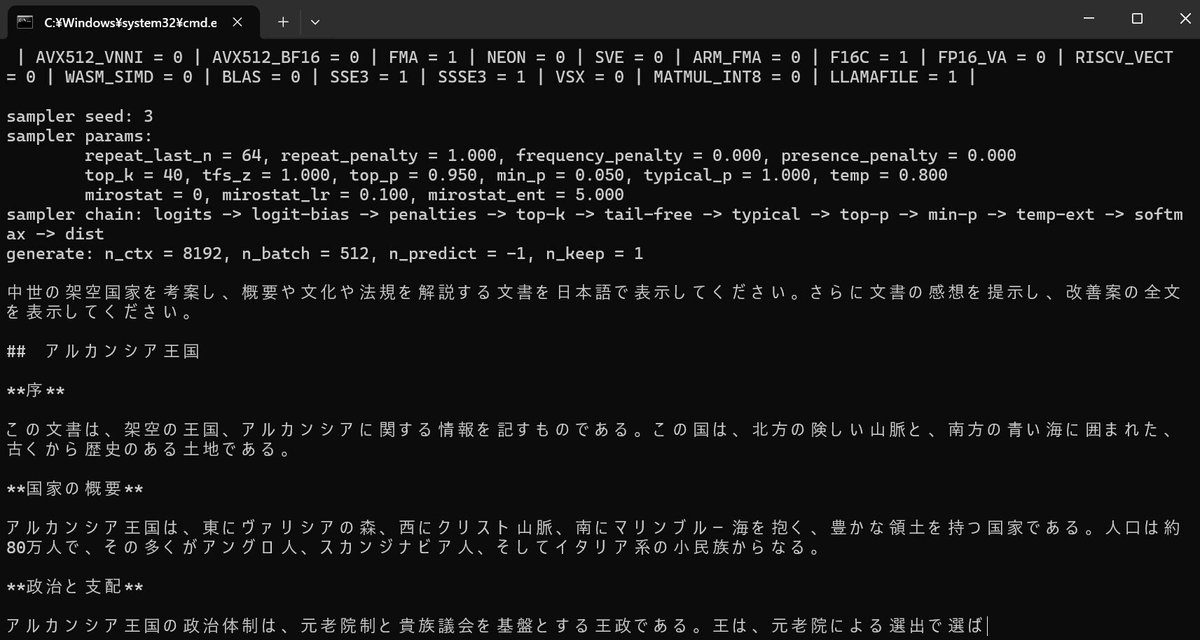
最後に実行時間等が表示されます。下から2行目の「eval time」が、出力開始から終了までの時間です。つまり、CPU(Ryzen5 3600)では出力に149秒かかり、1秒あたり12.08トークンとなりました。
llama_perf_sampler_print: sampling time = 318.56 ms / 1845 runs ( 0.17 ms per token, 5791.74 tokens per second)
llama_perf_context_print: load time = 1112.89 ms
llama_perf_context_print: prompt eval time = 682.53 ms / 43 tokens ( 15.87 ms per token, 63.00 tokens per second)
llama_perf_context_print: eval time = 149073.52 ms / 1801 runs ( 82.77 ms per token, 12.08 tokens per second)
llama_perf_context_print: total time = 150539.28 ms / 1844 tokensGPU(RTX 3060)では出力に21.9秒かかり、1秒あたり80.33トークンとなりました。速度としては6.65倍です。なお、初回の実行時は出力開始までに時間がかかる場合があります。
llama_perf_sampler_print: sampling time = 257.49 ms / 1806 runs ( 0.14 ms per token, 7013.89 tokens per second)
llama_perf_context_print: load time = 1613.21 ms
llama_perf_context_print: prompt eval time = 40.00 ms / 43 tokens ( 0.93 ms per token, 1075.11 tokens per second)
llama_perf_context_print: eval time = 21933.25 ms / 1762 runs ( 12.45 ms per token, 80.33 tokens per second)
llama_perf_context_print: total time = 22643.92 ms / 1805 tokens消費リソースの遷移は、おおよそ下記のとおりでした。モデル(gemma-2-baku-2b-it-q8_0.gguf)のファイルサイズは2.59GBです。
実行前
メインRAM:7.1GB
GPUメモリ: 0.7GBCPU動作時
CPU:66%
メインRAM:10.2GBGPU動作時
CPU:13%
メインRAM:10.6GB
GPUメモリ: 4.8GB
GPUを他のことに使用したいときは、速度に目をつぶってCPUで動作させるのも1つの考え方です。
■ 6. HFモデルの変換
▼ 6-1. 概要
llama.cppには様々な機能がありますが、スクリプトとして提供されているものは仮想環境を構築しないと実行できません。6.では例として、HFモデルの変換を行うまでの手順を簡単に説明します。
▼ 6-2. 仮想環境の構築
初回の利用開始時のみ、仮想環境を構築する必要があります。4-2.~4-4.で作ったいずれかのバッチファイルを実行してコマンドプロンプトを開いてください。もしくは、コマンドプロンプトを開いて作業ディレクトリまで移動してください。
次に、下記のコマンドを順に実行してください。最後の行で多少の時間を要します。終わったらウインドウを閉じてください。
python -m venv venv
venv\Scripts\activate
python -m pip install --upgrade pip
pip install transformers accelerate sentencepiece作業ディレクトリに、下記の内容で「cmd-llm.bat」(名前は任意)を作成してください。ファイルも置いておきます。
@echo off
cd %~dp0
call .\venv\Scripts\activate.bat
cmd /k作成したバッチファイルをエクスプローラー上からダブルクリックすると、仮想環境が有効化された状態でコマンドプロンプトが開きます。
この状態からCPU/GPU設定用バッチファイルを実行しても構いません。
▼ 6-3. HFモデルからGGUFへの変換 (1)
参考まで、Hugging Faceモデルのダウンロードから変換までの例を、下記の記事の2.~4.に記載しています。
ここでは例として、Qwen2.5を変換する手順を説明します。CPU動作を考慮して3B-Instructを選びます。
まず、6-2.で作成したバッチファイルを実行します。作業ディレクトリにて、仮想環境を有効化した状態のコマンドプロンプトが開きます。次に、下記のコマンドを順に実行してダウンロードを行います。
git lfs install
git clone https://huggingface.co/Qwen/Qwen2.5-3B-Instruct次は、BF16やQ8_0への変換を行います。Q8_0未満の量子化を行いたい場合は、いったんBF16に変換してください。ファイルサイズは、Qwen2.5-3B-InstructのBF16で5.75GB、Q8_0で3.05GBです。
# BF16へ変換する場合
python .\llama.cpp\convert_hf_to_gguf.py .\Qwen2.5-3B-Instruct --outtype bf16 --outfile .\Qwen2.5-3B-Instruct-bf16.gguf
# Q8_0へ変換する場合
python .\llama.cpp\convert_hf_to_gguf.py .\Qwen2.5-3B-Instruct --outtype q8_0 --outfile .\Qwen2.5-3B-Instruct-q8_0.ggufBF16からQ8_0以下に変換する場合は、4-2.に掲載した「cmd(cpu).bat」を実行してパスを通すか、実行ファイルのパスを記述します。下記はQ6_Kへ変換する場合の例です。
# cmd(cpu).batを実行した場合
llama-quantize .\Qwen2.5-3B-Instruct-bf16.gguf .\Qwen2.5-3B-Instruct-q6_k.gguf q6_k
# 実行ファイルのパスを直接記述する場合
.\llama.cpp\bin_cpu\llama-quantize .\Qwen2.5-3B-Instruct-bf16.gguf .\Qwen2.5-3B-Instruct-q6_k.gguf q6_k▼ 6-4. HFモデルからGGUFへの変換 (2)
中にはアクセスに許可が必要なモデルがあります。ここでは例として、Llama 3.2を変換する手順を説明します。CPU動作を考慮して3B-Instructを選びます。
https://huggingface.co/meta-llama/Llama-3.2-3B-Instruct へアクセスして、「LLAMA 3.2 COMMUNITY LICENSE AGREEMENT」に同意し、必要事項を記入してSubmitします。筆者の場合は10分以内に許可されました。
許可が下りた後、6-2.で作成したバッチファイルを実行します。作業ディレクトリにて、仮想環境を有効化した状態のコマンドプロンプトが開きます。
次に、下記のコマンドを順に実行してください。1行目は初回の実行時のみで構いません(おそらく既に入っています)。
pip install huggingface_hub
huggingface-cli login2行目を実行するとトークンの入力を促されるので、Hugging Faceの有効なトークン(User Access Tokens)を貼り付けてEnterを押します。その次もEnterを押します。
(取得方法:最初に https://huggingface.co/settings/profile へアクセスして、左側からAccess Tokensを選択します。既に存在するトークンを更新しても良い場合は、右側の三点をクリックして「Invalidate and refresh」を選ぶと新しいトークンが表示されます。もしくは、「Create new token」をクリックして「Token type」は「read」を選び、適当な名前を付けて「Create token」をクリックすると表示されます。トークンの値は再表示できないので注意してください。他で利用していなければ、その都度「Invalidate and refresh」を行って取得しても構いません。)
操作が正しければ「Login successful」と表示されます。「ValueError: Invalid token passed!」の場合は入力が正しいか確認してください。
Enter your token (input will not be visible):
Add token as git credential? (Y/n)次に、下記のコマンドを順に実行してダウンロードを行います。トークンの設定が正しければダウンロードが進行します。
git lfs install
git clone https://huggingface.co/meta-llama/Llama-3.2-3B-Instructここからの変換例を挙げておきます。
# BF16へ変換する場合
python .\llama.cpp\convert_hf_to_gguf.py .\Llama-3.2-3B-Instruct --outtype bf16 --outfile .\Llama-3.2-3B-Instruct-bf16.gguf
# Q8_0へ変換する場合
python .\llama.cpp\convert_hf_to_gguf.py .\Llama-3.2-3B-Instruct --outtype q8_0 --outfile .\Llama-3.2-3B-Instruct-q8_0.gguf
# BF16からQ6_Kへ変換する場合
llama-quantize .\Llama-3.2-3B-Instruct-bf16.gguf .\Llama-3.2-3B-Instruct-q6_k.gguf q6_k■ 7. まとめ
▼ 7-1. 所感
前回はCPUに対応したので、今回はGPUだけ対応しようと考えていましたが、非効率すぎるので両方に対応することにしました。その影響で実行ファイルのパスが二種類存在することになり、パスを切り替えるためのバッチファイルを設けました。うまく使いこなせば便利なはずです。
一方、全ての操作がCUIのままで取っつきが悪いのも事実なので、扱いに慣れて今後の方針が固まってきたら考えたいと思います。
■ 8. その他
私が書いた他の記事は、メニューよりたどってください。
noteのアカウントはメインの@Mayu_Hiraizumiに紐付けていますが、記事に関することはサブアカウントの@riddi0908までお願いします。