
ComfyUIでSanaを試す(VRAM 8GB、推奨12GB)

※ 【重要】(1-8-2025) 出力が想定と大きく異なる問題は、CFGの値のミスでした。2前後まで下げると直ります。新たに出た2Kモデルを追加して、別の記事として改めて公開します。(本記事は、新しい記事の公開後に大部分を削除する予定です。)
※ Last update 12-21-2024
※ 生成される画像が想定とはかなり異なるようです。詳細は4.を参照してください。現状は、Demoまたは前回の記事の方法での生成をおすすめします。
※ VRAMが6~8GBの場合は、2-4.を参照して設定を変更してください。
※ 本来、SanaはFlow DPM-Solverを利用しますが、執筆時点ではまだ実装されていません。
■ 0. 概要
▼ 0-0. はじめに
本記事ではComfyUIで画像生成AIの「Sana」を利用してみます。Sanaについては下記の記事を参照してください。
▼ 0-1. 関連リンク
Sana-ComfyUI
https://github.com/NVlabs/Sana/blob/main/asset/docs/ComfyUI/comfyui.mdSana (Code)
https://github.com/NVlabs/SanaDemo (Free)
https://nv-sana.mit.edu/fal ($0.0085 per MP)
https://fal.ai/models/fal-ai/sanaReplicate ($0.0018 per use?)
https://replicate.com/nvidia/sana
■ 1. 利用の準備
▼ 1-1. カスタムノードのインストール
Sanaを利用するためにはカスタムノードが必要です。
コマンドプロンプトを開いてから「ComfyUI\custom_nodes」へ移動して、下記のコマンドを実行します(Gitが必要)。もちろん、ComfyUI-Managerを用いてComfyUI上からインストールしても構いません。
git clone https://github.com/Efficient-Large-Model/ComfyUI_ExtraModels▼ 1-2. 手順の続き
以降の手順は、先に述べたとおり選択できます。
a. 公式のワークフローを使用する
必要なファイルは自動的にダウンロードされます。生成画像を保存したい場合は、ワークフローの修正(ノードの置き換え)が必要です。
→ 2. へ
b. オリジナルのワークフローを使用する
モデルとVAEは自分で設置する必要があります。
→ 3. へ
■ 2. 公式のワークフローで生成
▼ 2-1. 概要
公式のワークフローを用いる方法です。必要なファイルを設置する手間がありません。
▼ 2-2. ワークフローのダウンロード
上記のURLから「Sana workflow」に進んで、「Raw」の2つ右のアイコンからダウンロードしてください。
▼ 2-3. ワークフローの設定
ComfyUIを起動して、UI上にダウンロードしたファイルをドラッグ&ドロップして、ワークフローを読み込んでください。
これ以降は設定内容の説明ですので、読み飛ばして次項に進んでいただいて構いません。
モデルは「Sana_1600M_1024px_MultiLing」が選択されています。1600MのMultiLingと600Mのモデルは、英語、中国語、絵文字に対応しています。MultiLingでは無い方の1600Mは初回リリース時に公開されたもので、現在は特に選択する必要は無いと思います。
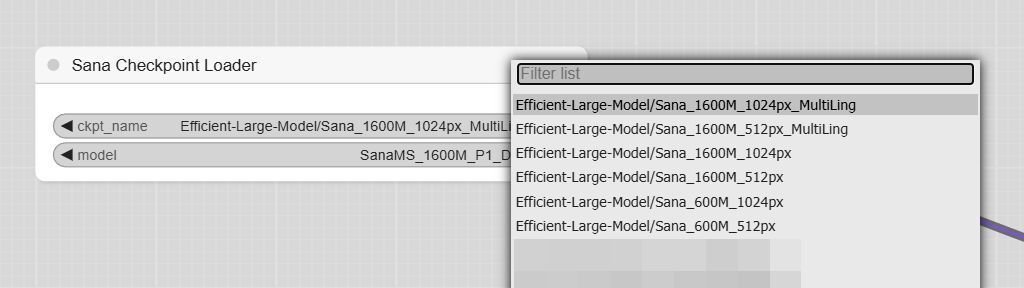
Text Encoderは「google/gemma-2-2b-it」が選択されています。サイズの小さい「unsloth/gemma-2-2b-it-bnb-4bit」も選択できます。deviceを「CPU」に変更することで、VRAMの消費を抑えることもできます。

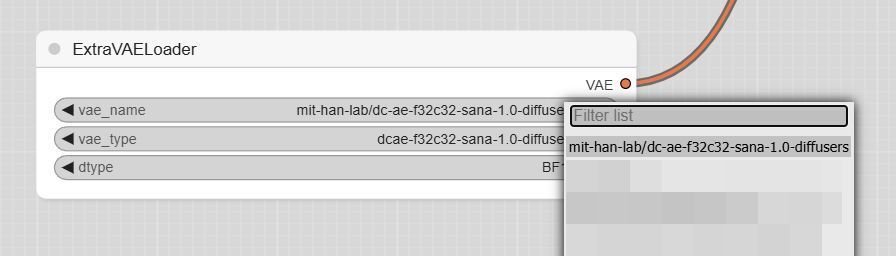
VAEは「mit-han-lab/sc-ae-f32c32-sana-1.0-diffusers」が選択されています。こちらは特に設定を変更する必要はありません。
▼ 2-4. VRAM 6~8GBの場合の対応
通常はVRAMが12GB必要ですが、「Gemma Loader」の設定を変えることで6~8GBでの動作が可能かもしれません。ただし、当該の実機での確認は行っていませんのでご了承ください。
Text Encoderの精度を下げる方法
設定を「unsloth/gemma-2-2b-it-bnb-4bit」「CUDA」「BF16」にすると、8GBで動作する可能性があります(7GB未満で一瞬だけ9GB程度まで上がる)。Text EncoderをCPUで動作させる方法
設定を「google/gemma-2-2b-it」「cpu」「default」にすると、6GBで動作する可能性があります(5GB未満で一瞬だけ7GB程度まで上がる)。
ただし、プロンプトの処理に少し時間がかかります。
また、「unsloth/gemma-2-2b-it-bnb-4bit」を選択すると、なぜかVRAM使用量があまり削減されませんでした。環境に依存する可能性もあるので、実際にお試しください。モデルを600M(0.6B)に変更する方法
モデルを600Mに変更すると、ファイルサイズで5.98GBから2.21GBまで下がるので、VRAM使用量もかなり削減されるはずです。ただし、出力の品質が確実に低下します。
▼ 2-5. 生成
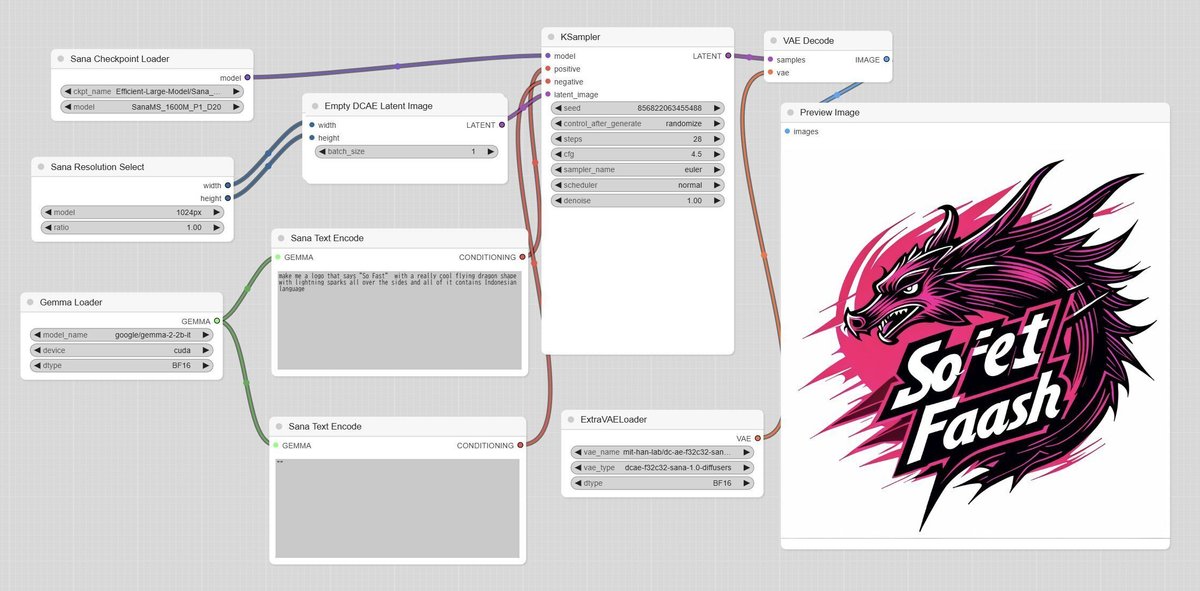
ComfyUIの「Queue」をクリックすると、モデルをダウンロードしてから生成が行われます。そのため、初回はしばらく時間を要します。
このワークフローは画像の保存が行われませんので、「Preview Image」を「Save Image」に置き換える必要があります。
▼ 2-6. 補足:出力解像度について (1)
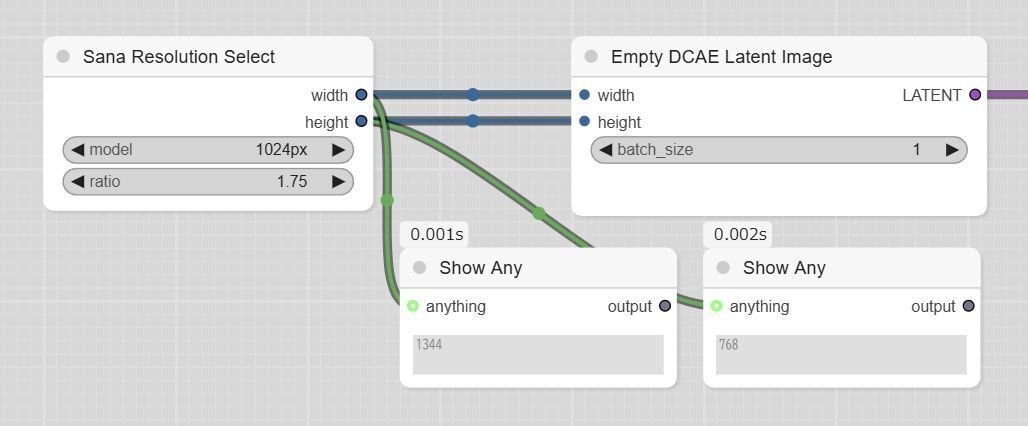
公式のワークフローでは「Sana Resolution Select」「Empty DCAE Latent Image」が用いられています。詳細は次項で述べますが、好みの解像度に設定するのがやや難しいように見えます。値を直接入力したい場合は、「Empty Sana Latent Image」に置き換えるのが良いでしょう。

▼ 2-7. 補足:出力解像度について (2)
前項にて挙げた「Sana Resolution Select」が出力する解像度について、参考まで書き出しておきます。「ratio」が1.00の場合は下記のとおりです。
1024px … 1024 x 1024
512px … 512 x 512
2K … 2048 x 2048
SanaMS_600M_P1_D28 … 1024x1024
SanaMS_1600M_P1_D20 … 1024 x 1024
設定の「ratio」を変更すると縦横比が変わり、値を丸められた解像度が設定されます。「1024px」を選択していた場合は下記のように変化します(少々わかりにくい)。
※ 「ComfyUI\custom_nodes\ComfyUI_ExtraModels\Sana\conf.py」に、全ての設定値が記述されています。下記は抜粋です。
4.00 … 2048 x 512 (4:1)
3.75 … 1920 x 512 (15:4)
2.50 … 1600 x 640 (5:2)
2.40 … 1536 x 640 (12:5)
1.75 … 1344 x768 (7:4) ※ 16:9に近い
1.67 … 1280 x768 (5:3)
1.29 … 1152 x 896 (9:7)
1.07 … 1024 x 960 (16:15)
1.00 … 1024 x 1024 (1:1)
0.94 … 960 x 1024 (15:16)
0.78 … 896 x 1152 (7:9)
0.60 … 768 x 1280 (3:5)
0.57 … 768 x 1344 (4:7) ※ 9:16に近い
0.42 … 640 x 1536 (5:12)
0.40 … 640 x 1600 (2:5)
0.27 … 512 x 1920 (4:15)
0.25 … 512 x 2048 (1:4)
とりあえず、下記のようなカスタムノードを使って値を表示するのも一つの方法です。
rgthree-comfy
https://github.com/rgthree/rgthree-comfy
→Display Any (rgthree)ComfyUI-Easy-Use
https://github.com/yolain/ComfyUI-Easy-Use
→Show Any
■ 3. オリジナルのワークフローで生成
▼ 3-1. 概要
Sanaのモデルを自身で設置する方法です。モデルの種類が混乱しないよう、デフォルトの場所にディレクトリを作成して、その下に設置する方針をとっています。
▼ 3-2. Model
モデルをダウンロードして「ComfyUI\models\checkpoints\sana」に移動してください。通常は「1.6B, 1024px, MultiLing」のモデルを選択します。
Model (1.6B, 1024px, MultiLing)
https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_MultiLing
checkpoints/Sana_1600M_1024px_MultiLing.pth
その他、512px版や0.6B版があります。0.6Bの場合、品質は劣りますが生成速度が上がり消費リソース量が削減できます。
Model (600M, 1024px, MultiLing)
https://huggingface.co/Efficient-Large-Model/Sana_600M_1024px
checkpoints/Sana_600M_1024px_MultiLing.pthModel (1.6B, 512px, MultiLing)
https://huggingface.co/Efficient-Large-Model/Sana_1600M_512px_MultiLing
checkpoints/Sana_1600M_512px_MultiLing.pthModel (600M, 512px, MultiLing)
https://huggingface.co/Efficient-Large-Model/Sana_600M_512px
checkpoints/Sana_600M_512px_MultiLing.pth
▼ 3-3. VAE
下記のファイルをダウンロードして「ComfyUI\models\vae\sana」に移動してください。
https://huggingface.co/mit-han-lab/dc-ae-f32c32-sana-1.0-diffusers
diffusion_pytorch_model.safetensors
▼ 3-4. ワークフロー
こちらで配布するワークフローは、VRAM 12GBを前提としています。VRAMが6~8GBの場合は2-4.を参照して、設定を変更してください。0.6Bのモデルを使用する場合は、Loaderの「model」を600Mに変更しないとエラーが出ます。
ワークフローを実行すると、下記の画面のようになると思います。
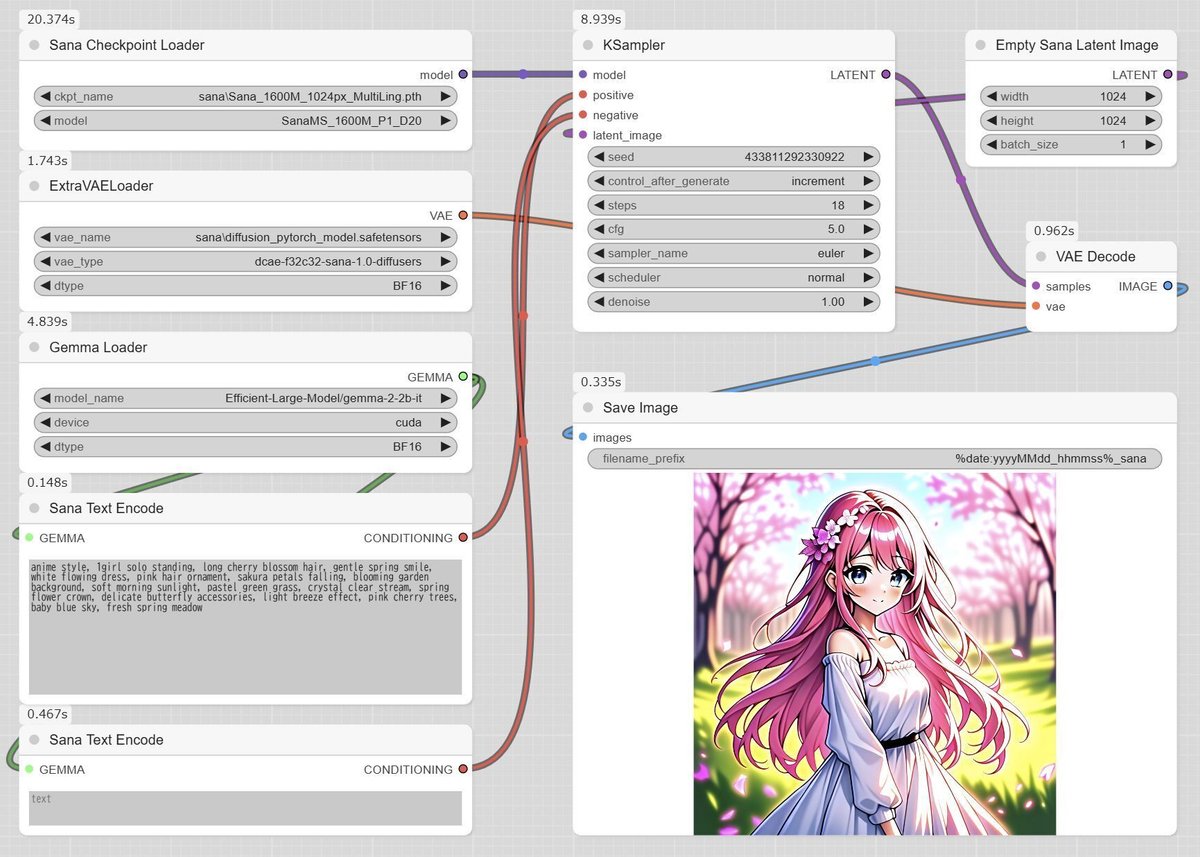

anime style, 1girl solo standing, long cherry blossom hair, gentle spring smile, white flowing dress, pink hair ornament, sakura petals falling, blooming garden background, soft morning sunlight, pastel green grass, crystal clear stream, spring flower crown, delicate butterfly accessories, light breeze effect, pink cherry trees, baby blue sky, fresh spring meadow
■ 4. ComfyUI利用時の画質について
▼ 4-1. 概要
ComfyUIで生成したSanaの画像はコントラストが高く、さらに黒つぶれや白飛びが起こっています。かなり暗い画像になる場合もあり、正直なところ正常とは思えません。
前回のCUI上で生成した記事の場合もコントラストが高い傾向があったので、個人的に調整を行って改善しました。ComfyUI側でも調整を試みましたが、結果的にはあまりうまくいきませんでした。
▼ 4-2. SanaのDemoで生成した場合
3-4.に掲載した画像と同じプロンプトを、SanaのDemo(URLは0-1.を参照)で使用してみました。「Flow_DPM_Solver」が使用されているなどの違いはありますが、モデルは同じ「Sana-1.6B 1024px」です。

▼ 4-3. CUI上で生成した場合
前回の記事の手順で生成してみました。SanaPipelineの出力を筆者が調整して、Demoとあまり変わらない状態にしています(少しだけ明るいかも?)。

■ 5. 補足
▼ 5-1. 概要
後学のため、4.の問題(黒つぶれ、白飛び等)をどうにかできないか、あがいてみた方法を残しておきます。Sanaが使用するVAE、DCAEのDecoderにてヒストグラムの調整を行います。コードはChatGPTにて作成しました。
この処理を加えると、「ExtraVAELoader」のノードを利用してDCAEを指定した全ての出力に影響が出るので注意してください。
▼ 5-2. ヒストグラムのリマッピング
エディタで「custom_nodes\ComfyUI_ExtraModels\VAE\models\dcae.py」を開いて、「class Decoder(nn.Module):」の末尾に追加します。必ずバックアップを取ってください。
def remap_histogram(output, ranges=[(-3.7, -3.5), (-3.5, 3.5), (3.5, 3.7)], targets=[(-3.7, -3.0), (-3.0, 3.0), (3.0, 3.7)]):
"""
ヒストグラムリマッピングを行い、指定された範囲を別の範囲に置き換える。
Args:
output (torch.Tensor): 入力テンソル。
ranges (list of tuple): 入力テンソル内のリマッピングする範囲のリスト。
targets (list of tuple): リマッピング後の対応する範囲のリスト。
Returns:
torch.Tensor: リマッピング後のテンソル。
"""
current_min, current_max = output.min(), output.max()
print(f"remap_histogram(before): current_min: {current_min}, current_max: {current_max}")
remapped_output = torch.zeros_like(output)
for (in_min, in_max), (out_min, out_max) in zip(ranges, targets):
# 対応する範囲のマスクを作成
mask = (output >= in_min) & (output < in_max)
# 対応範囲内の値をスケール変換
scale = (out_max - out_min) / (in_max - in_min + 1e-8)
remapped_output[mask] = out_min + (output[mask] - in_min) * scale
current_min, current_max = remapped_output.min(), remapped_output.max()
print(f"remap_histogram(after): current_min: {current_min}, current_max: {current_max}")
return remapped_output追加した部分の直前に「return hidden_states」があるので、その手前に呼び出す行を追加します。
hidden_states = self.conv_out(hidden_states) ※元から存在する行
hidden_states = remap_histogram(
hidden_states,
ranges= [(-2.00, -1.70), (-1.70, -1.60), (-1.60, 1.60), (1.60, 1.70), (1.70, 2.00)], # マッピング元の範囲
targets=[(-1.90, -1.50), (-1.50, -1.40), (-1.40, 1.40), (1.40, 1.50), (1.50, 1.90)] # マッピング先の範囲
)
return hidden_states ※元から存在する行上記の場合の設定は「-2.00から-1.70の範囲を-1.90から-1.50の範囲にリマッピングする」「-1.70から-1.60の範囲を-1.50から-1.40の範囲…」という流れになっています。リマッピングの数は増減できます。
テスト用のワークフローです。
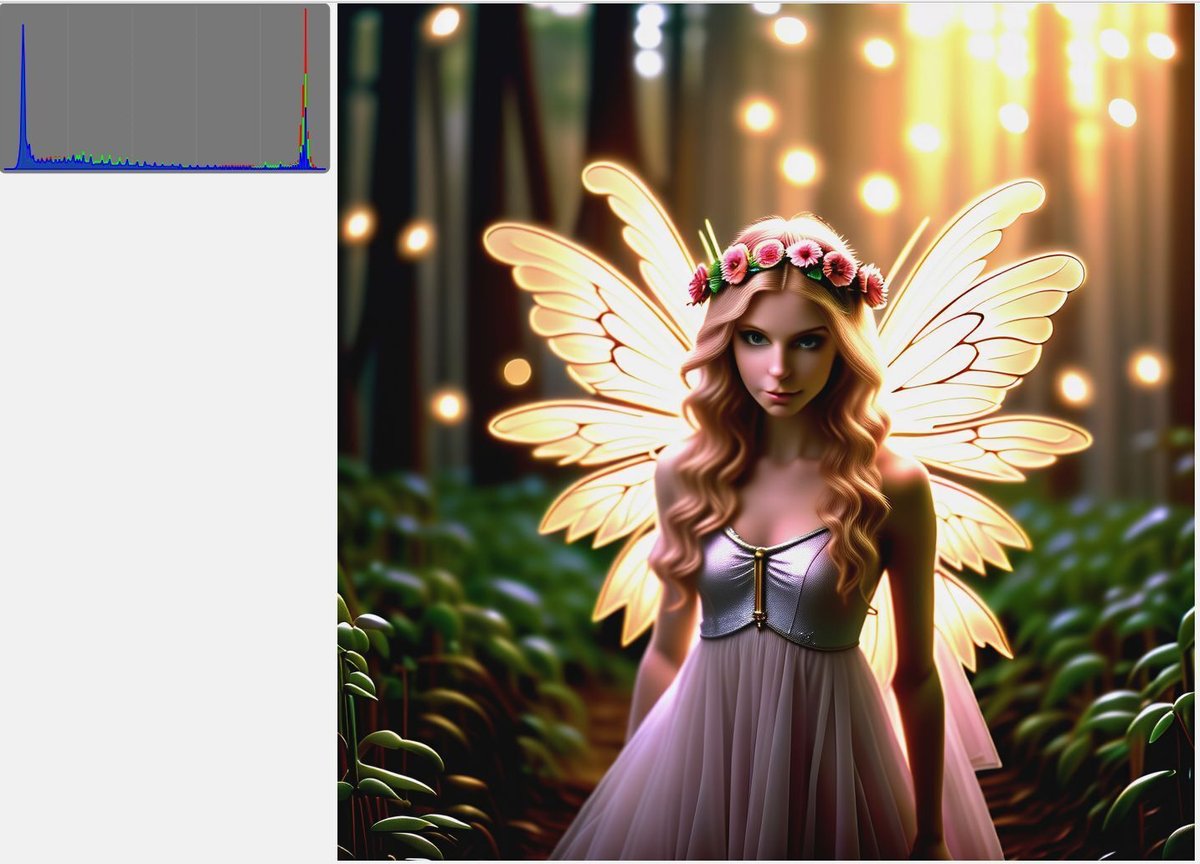
リマッピングを行わなかった場合の出力です。両端にピークが来ているのが分かります。

先ほどの変更を加えると、ピークが少しだけ中央寄りになります。両端に寄っている状況は変わらないので、さらに加工する必要があります。リマッピングをさらに調整して改善しないか試してみましたが、思った以上に難しいようです。
▼ 5-3. リマッピング2
こちらは単純に、値を指定した範囲内にマッピングします。設置方法や使い方は同様ですが、設定できる値は最小値と最大値のみです。値をうまく設定すると、中央に寄りすぎて真っ黒と真っ白が無い状態を改善することができるかもしれません。
def adjust_dynamic_range(output, target_range=(-1.8, 1.8)):
"""
出力値を指定された範囲に動的にマッピングする。
Args:
output (torch.Tensor): 調整対象のテンソル。
target_range (tuple): 出力値を収める範囲 (min, max)。
Returns:
torch.Tensor: 調整後のテンソル。
"""
current_min, current_max = output.min(), output.max()
print(f"current_min: {current_min}, current_max: {current_max}")
desired_min, desired_max = target_range
# スケール計算(ゼロ除算回避のための epsilon を追加)
scale = (desired_max - desired_min) / (current_max - current_min + 1e-8)
adjusted_output = desired_min + (output - current_min) * scale
return adjusted_output
▼ 5-4. その他
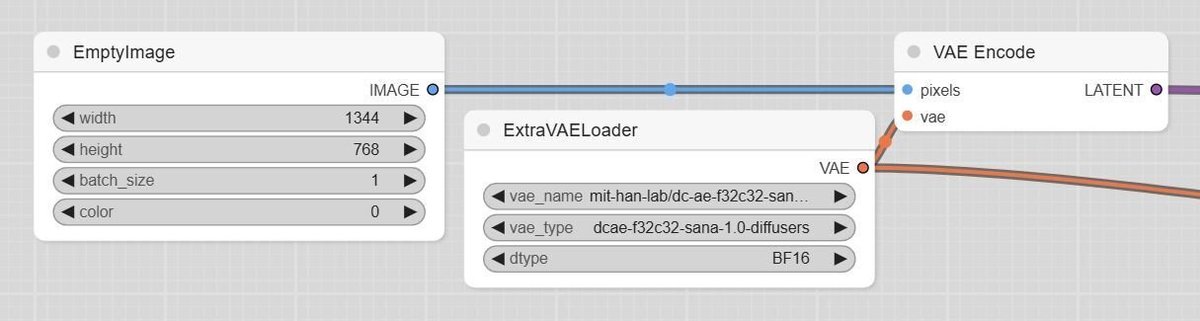
下記の方法で空のLatent Imageが作れたので、i2iも可能かもしれません。ただし、DCAE Encoderの動作は確認していないので無保証です。
■ 6. その他
私が書いた他の記事は、メニューよりたどってください。
noteのアカウントはメインの@Mayu_Hiraizumiに紐付けていますが、記事に関することはサブアカウントの@riddi0908までお願いします。