
SD 1.5、SDXL、SD 3、FLUX.1、AuraFlowモデルのGGUF化と利用方法(Windows)

※ Last update 1-15-2025
※ 変換の手順は1.~2.を参照してください。対応形式は、タイトルに記載のほかにはLTXVがあります(未検証)。
※ モデル内蔵のText Encoderがベースモデルのものとは異なる場合は、GGUF変換後も同じText Encoderを使用する必要があります(特にSD 1.5やSDXLは注意)。
■ 0. 概要
▼ 0-0. はじめに
本記事では、各種の画像生成モデルをGGUF形式に変換する環境を構築します。また、実際に変換を行って利用してみます。
この記事を公開するまでに数ヶ月が経ってしまいましたが、変換の方法については下記の記事で知りました(感謝)。
▼ 0-1. GGUF形式のメリット
モデルをGGUF化すると、例えばQ8_0ではファイルサイズが約半分(FP16やBF16比の場合、Text EncoderとVAEは除外)になり、同等サイズのFP8形式よりも精度が良いことが利点となります。Q6_K以下であればさらに小さくなりますが、当然ながら精度も下がっていきます。
下記の記事では、FLUX.1にて比較を行っています。リソースを少しでも節約したい場合は、Q6_K等も選択肢に入るかもしれません。
▼ 0-2. GGUF形式について
大規模言語モデル(LLM)を読み込むためには、規模に応じた大量のメモリ(例えば数十GB以上や100GB以上)が必要で、動作環境が限定されます。そのため、より少ないメモリで、かつ早く推論できるように量子化する場合も多く、その際に利用されるフォーマットがGGUF形式です。24年夏頃より、画像生成モデルにおいてもある程度の広がりを見せています。
参考まで、下記の記事にてLLMをGGUF形式に変換する方法を説明しています。本記事ではllama.cppにパッチを当てることで、画像生成モデルの変換ができるようにします。
■ 1. 環境の構築
▼ 1-1. 概要
ComfyUIでGGUF形式を利用するための拡張ノードがあり、リポジトリのtoolsディレクトリには変換に必要な情報があります。現在の対応状況は履歴を確認してください。執筆時点での最終更新は24年11月です。
ComfyUI-GGUF/tools/
https://github.com/city96/ComfyUI-GGUF/tree/main/toolsHistory for ComfyUI-GGUFtools
https://github.com/city96/ComfyUI-GGUF/commits/main/tools
変換するための環境は、ComfyUIの仮想環境に便乗できそうな気もしますが、本記事では独立した仮想環境を作成します。この先の手順ではPythonが必要です。
ComfyUIをご利用の方は「ComfyUI-GGUF」を最新版に更新しておいてください。
▼ 1-2. Build Tools for Visual Studio 2022のインストール
既にインストールされている場合は読み飛ばしてください。
https://visualstudio.microsoft.com/ja/downloads/ へアクセスしてください。下にスクロールすると「すべてのダウンロード」がありますので、「→すべて展開」をクリックします。「Tools for Visual Studio」の中に「Build Tools for Visual Studio 2022」があるので、ダウンロードして実行します。
(※この手順はたまに、微妙に変更される場合があります)

インストーラーが起動したら、「C++によるデスクトップ開発」にチェックを入れてインストールしてください。この画面が表示されない場合は、「Visual Studio Build Tools 2022」の「変更」をクリックすると遷移します。

▼ 1-3. CMakeのインストール
量子化を行うllama-quantizeをビルドするために、CMakeの最新版をインストールします。インストールしたバージョンが古くなっている場合があるので、導入が最近ではない場合は更新をおすすめします。
https://cmake.org/download/ へアクセスしてください。「Binary distributions:」にある「Windows x64 Installer:」をダウンロードして、実行します。そのまま進めるだけで構いません。
▼ 1-4. 実行環境の準備(1)
本記事では作業ディレクトリを「\aiwork」、実行ディレクトリを「\aiwork\sd-gguf」としています。お好みで読み替えてください。
コマンドプロンプトを開き、下記のコマンドを順に実行してください。「pip install」の箇所は、ダウンロード等で多少の時間を要します。
cd \aiwork
mkdir sd-gguf
cd sd-gguf
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
python -m venv venv
venv\Scripts\activate
python.exe -m pip install --upgrade pip
pip install torch --index-url https://download.pytorch.org/whl/cu121
pip install safetensors
pip install .\gguf-py▼ 1-5. 実行環境の準備(2)
下記の2ファイルをダウンロードして、「\aiwork\sd-gguf」に移動してください。
https://github.com/city96/ComfyUI-GGUF/blob/main/tools/convert.py
https://github.com/city96/ComfyUI-GGUF/blob/main/tools/lcpp_sd3.patch
今後、対応形式が増えた際に「lcpp_sd3.patch」よりも新しいpatchファイルが公開されている可能性があります。ComfyUI-GGUF/tools/ の情報を確認してみてください。
なお、ダウンロードはアクセス先の画面の右上から行えます。
ここまでの手順で、実行ディレクトリが下記画面の状態になっているはずです。

▼ 1-6. 実行環境の準備(3)
続けて、下記のコマンドを順に実行してください。色々とメッセージが表示される場合がありますが、気にする必要はありません。
なお、「tags/b3962」と「lcpp_sd3.patch」の箇所は、対応形式の追加で変更される場合があります。もし ComfyUI-GGUF/tools/ に新バージョンの情報があれば、内容を確認しながら読み替えてください。
git checkout tags/b3962
git apply ../lcpp_sd3.patch
mkdir build
cd build
cmake ..
cmake --build . --config Debug -j10 --target llama-quantize手順を終えると、「\aiwork\sd-gguf\llama.cpp\build\bin\Debug」の中に量子化を行うための「llama-quantize.exe」が入っています。
環境の構築は以上です。コマンドプロンプトのウインドウを閉じてください。
■ 2. 変換の実行
▼ 2-1. 概要
実行ディレクトリ「\aiwork\sd-gguf」にバッチファイルを設置し、モデルのファイルをドラッグ&ドロップするだけで変換できるようにします。ファイル名は個人的に「cnv_sft-to-q8_0.bat」としましたが、特に決まりはありません。
複数ファイルには対応していません。内容を提示してChatGPTやClaude等に質問すると、すぐに作ってくれると思います。
なお、変換の手順は「オリジナル → F16.gguf → Q8_0.gguf」となっています。変換後のタイプをQ8_0以外(Q6_K等)にしたい場合は、「Q8_0」の記述をすべて書き換えてください。
下記は、llama-quantize のヘルプからの抜粋です。Qで始まるタイプはどれでも利用できると思いますが、低くてもQ4程度にとどめておくと良いでしょう。
Allowed quantization types:
2 or Q4_0 : 4.34G, +0.4685 ppl @ Llama-3-8B
3 or Q4_1 : 4.78G, +0.4511 ppl @ Llama-3-8B
8 or Q5_0 : 5.21G, +0.1316 ppl @ Llama-3-8B
9 or Q5_1 : 5.65G, +0.1062 ppl @ Llama-3-8B
10 or Q2_K : 2.96G, +3.5199 ppl @ Llama-3-8B
21 or Q2_K_S : 2.96G, +3.1836 ppl @ Llama-3-8B
12 or Q3_K : alias for Q3_K_M
11 or Q3_K_S : 3.41G, +1.6321 ppl @ Llama-3-8B
12 or Q3_K_M : 3.74G, +0.6569 ppl @ Llama-3-8B
13 or Q3_K_L : 4.03G, +0.5562 ppl @ Llama-3-8B
15 or Q4_K : alias for Q4_K_M
14 or Q4_K_S : 4.37G, +0.2689 ppl @ Llama-3-8B
15 or Q4_K_M : 4.58G, +0.1754 ppl @ Llama-3-8B
17 or Q5_K : alias for Q5_K_M
16 or Q5_K_S : 5.21G, +0.1049 ppl @ Llama-3-8B
17 or Q5_K_M : 5.33G, +0.0569 ppl @ Llama-3-8B
18 or Q6_K : 6.14G, +0.0217 ppl @ Llama-3-8B
7 or Q8_0 : 7.96G, +0.0026 ppl @ Llama-3-8B
33 or Q4_0_4_4 : 4.34G, +0.4685 ppl @ Llama-3-8B
34 or Q4_0_4_8 : 4.34G, +0.4685 ppl @ Llama-3-8B
35 or Q4_0_8_8 : 4.34G, +0.4685 ppl @ Llama-3-8B
1 or F16 : 14.00G, +0.0020 ppl @ Mistral-7B
32 or BF16 : 14.00G, -0.0050 ppl @ Mistral-7B
0 or F32 : 26.00G @ 7B▼ 2-2. 変換バッチファイル1
変換後の「*-Q8_0.gguf」を、バッチファイルと同じ場所に書き出します。処理が終わったら、必要に応じて移動等を行ってください。2-1.に記載したとおり、必要に応じて「Q8_0」の箇所を変更してください。
変換の途中で使用する「*-F16.gguf」は、変換後に削除しています。削除したくない場合は「del %cnv_file1%」を「rem del %cnv_file1%」に変更するか、この行を削除してください。
@echo off
cd /d %~dp0
set input_file="%1"
set cnv_file1="%~dp0%~n1-F16.gguf"
set cnv_file2="%~dp0%~n1-Q8_0.gguf"
if not exist %input_file% (
echo.
echo convert the image generation model to GGUF format
echo please drag-and-drop model file ^(.safetensors, etc.^) onto this batch file
pause
exit /b 1
)
call llama.cpp\venv\Scripts\activate.bat
convert.py --src %input_file% --dst %cnv_file1%
if not exist %cnv_file1% (
echo.
echo error: not found %cnv_file1%
echo failed to process convert.py?
pause
exit /b 1
)
llama.cpp\build\bin\Debug\llama-quantize %cnv_file1% %cnv_file2% Q8_0
del %cnv_file1%
if not exist %cnv_file2% (
echo.
echo error: not found %cnv_file2%
echo failed to process llama-quantize?
) else (
echo.
echo saved file %cnv_file2%
echo convert processing completed successfully
)
pause▼ 2-3. 変換バッチファイル2
変換後の「*-Q8_0.gguf」を、変換元のモデルと同じ場所に書き出します。なお、2-2. との違いは1文字だけです。2-1.に記載したとおり、必要に応じて「Q8_0」の箇所を変更してください。
変換の途中で使用する「*-F16.gguf」は、変換後に削除しています。削除したくない場合は「del %cnv_file1%」を「rem del %cnv_file1%」に変更するか、この行を削除してください。
@echo off
cd /d %~dp0
set input_file="%1"
set cnv_file1="%~dp0%~1-F16.gguf"
set cnv_file2="%~dp10%~n1-Q8_0.gguf"
if not exist %input_file% (
echo.
echo convert the image generation model to GGUF format
echo please drag-and-drop model file ^(.safetensors, etc.^) onto this batch file
pause
exit /b 1
)
call llama.cpp\venv\Scripts\activate.bat
convert.py --src %input_file% --dst %cnv_file1%
if not exist %cnv_file1% (
echo.
echo error: not found %cnv_file1%
echo failed to process convert.py?
pause
exit /b 1
)
llama.cpp\build\bin\Debug\llama-quantize %cnv_file1% %cnv_file2% Q8_0
del %cnv_file1%
if not exist %cnv_file2% (
echo.
echo error: not found %cnv_file2%
echo failed to process llama-quantize?
) else (
echo.
echo saved file %cnv_file2%
echo convert processing completed successfully
)
pause▼ 2-4. 変換の実行
2-1. にも書いたとおり、変換したいモデルのファイルをバッチファイルにドラッグ&ドロップするだけです。バッチファイルと同じ場所、または変換元のファイルと同じ場所に出力します。Text EncoderやVAEを含んだモデルでも構いません。
変換ができない場合は、対応していない形式か、ディスクの空きが不十分か、変換プログラムの問題かのいずれかです。
■ 3. GGUFモデルの利用方法
▼ 3-1. 概要
FLUX.1を例に、「Stable Diffusion WebUI Forge」と「ComfyUI」、それぞれでGGUF形式に変換したモデルを利用してみます。各アーキテクチャでの動作確認は4.に掲載しています。
なお、詳細な手順は説明しませんので、3-2.や3-3.に示したリンク先の記事を参考にしてください。ここでは、オリジナルの「flux1-dev.safetensors」をGGUF形式に変換しました。変換済みモデルの配布場所も紹介しておきます。

black-forest-labs/FLUX.1-dev
https://huggingface.co/black-forest-labs/FLUX.1-dev
※ ダウンロードに許可が必要city96/FLUX.1-dev-gguf
https://huggingface.co/city96/FLUX.1-dev-gguf
※ 変換済みのモデル(F16、Q2_K~Q8_0)
▼ 3-2. Stable Diffusion WebUI Forge
Stable Diffusion WebUI Forgeは、標準でGGUF形式のFLUX.1に対応しています。

利用方法は、下記の記事の 4-3. から 4-5. あたりを参考にしてください。
▼ 3-3. ComfyUI
ComfyUIは、拡張ノードをインストールすることでGGUF形式のFLUX.1に対応します。ワークフローのモデルを読み込む部分を「Unet Loader (GGUF)」に変更します。別途、Text EncoderとVAEを用意する必要があります。

GGUF形式のモデルに対応していない(Unet Loader (GGUF) が無い)場合は、下記の記事の 4. を参考に準備を行ってください。
■ 4. GGUFモデルの利用(ComfyUI)
▼ 4-1. 概要
本記事で構築した環境は、FLUX.1以外の方式にも対応しています。執筆時点で対応している方式(SD 1.5、SDXL、SD 3、FLUX.1、AuraFlow)について、実際に変換を行った上で動作を確認してみます。
特にSD 1.5やSDXLは重要な留意事項があるため、説明が長くなっています。
▼ 4-2. 注意点(やや長文)
変換元のモデルに内蔵されたText EncoderやVAEがベースモデルのものとは異なる場合、別のText EncoderやVAEを使用すると出力が変化してしまいます。
これ以降は興味のある方のみご覧いただき、そうではない場合は読み飛ばしてください。
出力が変化してしまう問題は特に、SD 1.5やSDXLのチューニングモデルで発生します。Text EncoderやVAEを変更(いずれかに固定)しても差し支えないかどうかは、出力を元のモデルのものと比較してみるしかありません。
ただし、モデルが分離された状態で公開されているアーキテクチャの場合は、共通の(無加工の)Text EncoderやVAEを利用するため、問題が起こる可能性が低いです。
ここからは、問題が発生する例を挙げます。下記のモデル(分離済みを含む)が手元にあるとします。
ベースモデル A0(= A1 + A2 + A3)
Diffusion Model = A1
Text Encoder = A2
VAE = A3チューニングモデル B0(= B1 + B2 + B3)
Diffusion Model = B1(≠ A1)
Text Encoder = B2(≠ A2)
VAE = B3(≠ A2)B0 をGGUF形式に変換したモデル B1.gguf
Diffusion Model = B1.gguf
もしも、「B1.gguf + B2 + B3」の組み合わせであれば、元のモデル「B0」の代わりに利用できます。しかし、「B1.gguf + A2 + A3」の組み合わせにしてしまうと、出力が(場合によっては大きく)変化してしまいます。
実際に、チューニングモデル「ToraFurryMix v20」と、ベースモデルの「Stable Diffusion v1-5」で試してみます。前者はText Encoder、VAEともにベースモデルのものとは異なっています。
ToraFurryMix
https://huggingface.co/tlano/ToraFurryMixStable Diffusion v1-5 Model Card
https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5
まず、チューニングモデルを利用した下記の画面を比較元とします(次項に生成画像のみを掲載しています)。

次に、ModelのみをGGUF Q8_0に変更します。出力が少し異なりますが、これは変換(FP32→FP16やFP16→FP8等)を行った際に起こることなので、気にする必要はありません。
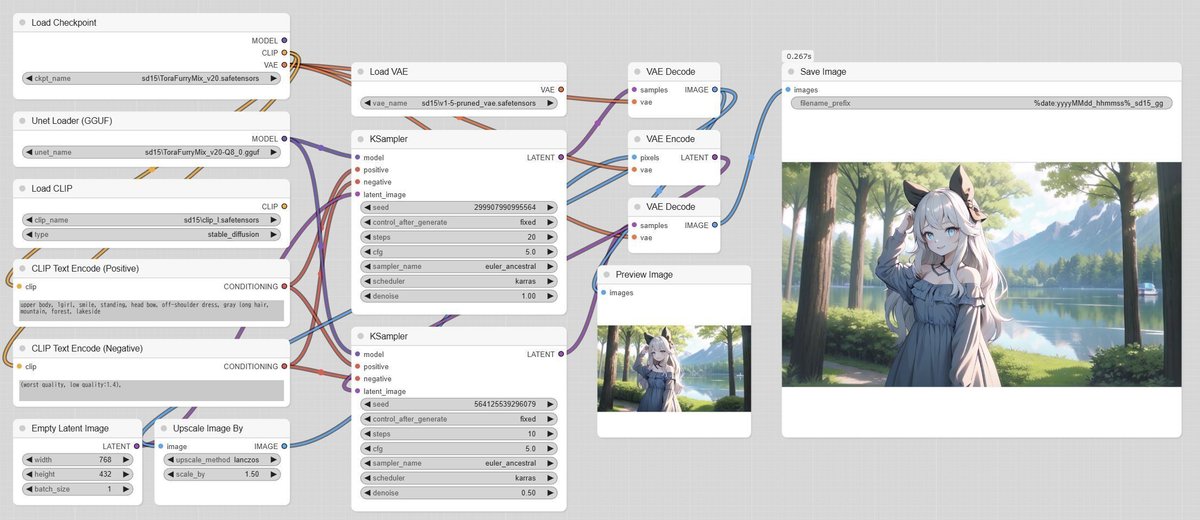
さらに、Text Encoderをベースモデルのものに変更すると、出力が大きく変化します。Seedを何回か変更しても、ズームインされた構図にはなりませんでした。

最後に、Text Encoderを戻して、VAEをベースモデルのものに変更しました。分かりづらいですが、実は出力が変化しています。

下記の画像は、上が変換元のモデルに内蔵されたVAE、下がベースモデルのVAEです。VAEが異なると、細かい描写や発色が変化します。

余談ながら、一部の系統のSD 1.5モデルに内蔵されたVAEは性質が異なるため、使用するVAEを誤ると適切な出力が行えなくなる場合があります。
▼ 4-3. Stable Diffusion 1.5
モデルのサイズがもともと小さいこと(約2GB)や、チューニングモデルが独自のText EncoderやVAEを持つ可能性が高いことから、GGUF化は可能ですが非推奨とします。
なお、ベースモデル(Stable Diffusion v1-5)を分離してGGUF Q8_0に変換した場合の内訳は下記のとおりで、Modelのサイズが765MB縮小しました。
Model
1.6GB - original (built into)
874MB - GGUF Q8_0Text Encoder
235MB - original (clip_l, built into)VAE
159MB - original (built into)
比較のために使用したモデルは下記のとおりです。ワークフローは前項を参照してください。
ToraFurryMix
https://huggingface.co/tlano/ToraFurryMix
元のモデルの出力と、GGUF化したモデルの出力を掲載します。


▼ 4-4. SDXL
SDXLのチューニングモデルは独自のText Encoderを持つ可能性が高いです。その場合はGGUF形式に変換した後も、元のモデルと同じText Encoderを使用する必要があります。なお、VAEについては特殊な例外や好みによる変更を除き、通常はベースモデルと同じもので差し支えないと思います。
結論として、下記のようにメリットの方が大きい条件下であれば、GGUF化は有効かもしれません。
もともとVRAMが不足していてGGUF化で改善できそう
同じモデルを多用するので固有のText Encoderを保持しても構わない
なお、ベースモデル(SD-XL 1.0-base)を分離してGGUF Q8_0に変換した場合の内訳は下記のとおりで、Modelのサイズが2.23GB縮小しました。
Model
4.78GB - original (built into)
2.54GB - GGUF Q8_0Text Encoder
1.29GB - original (clip_g, built into)
235MB - original (clip_l, built into)VAE
159MB - original (built into)
他に考慮が必要な事項として、LoRA適用済みのモデルを保存してからGGUF形式に変換した方が、GGUF形式のモデルにLoRAを適用するよりもVRAM使用量が少ないことがわかっています。

使用したモデルは下記のとおりです。低Stepsで生成するためにPCM LoRAを適用して、VAEはベースモデルと同じものを利用します。
SuimeiXL
https://civitai.com/models/1031193Phased Consistency Model(PCM)
https://huggingface.co/wangfuyun/PCM_Weights
sdxl\pcm_sdxl_smallcfg_8step_converted.safetensorsSDXL - VAE
https://huggingface.co/stabilityai/sdxl-vae
sdxl_vae.safetensors
まず、元のモデル(+PCM LoRA)で出力します。


次に、GGUF化したモデルで出力します。前述のとおり、変換元はPCM LoRAを適用済みです。Text Encoderは、元のモデルから分離したものを使用しています(元のモデルからCLIPをつなげても出力は変わりません)。

細かな相違しかないため、Modelのサイズが半分近くになっていることには気づかないと思います。Q6_K以下に下げていくと、相違が大きくなると思います。

ここで、Text Encoderをベースモデルのものに変更すると出力が壊れます(clip-gとclip_l、どちらの影響かは未確認)。このように独自のText Encoderを持つモデルでは、変換後も同じText Encoderを使用する必要があります。

この先は検証していないので分かりませんが、同じ系列のモデルであれば、内蔵するText Encoderに互換性があるかもしれません。
▼ 4-5. SD 3 Medium
SD 3.5ではなくSD 3です(執筆時点ではSD 3.5には未対応の様子)。チューニングモデルは未確認ですが、通常は共通のText EncoderとVAEを利用するとみられ、GGUF化で問題が発生する可能性はおそらく低いと思います。
ベースモデル(Stable Diffusion 3 Medium)を分離してGGUF Q8_0に変換した場合の内訳は下記のとおりで、Modelのサイズが1.75GB縮小しました。ベースモデルは、Text Encoderを内蔵しているものと、そうでないものがあります。t5xxlはいずれかのみを使用します。
Model
3.88GB - original (built into)
2.12GB - GGUF Q8_0Text Encoder
1.29GB - original (clip_g, built into)
235MB - original (clip_l, built into)
9.11GB - original (t5xxl_fp16, built into)
4.55GB - original (t5xxl_fp8_e4m3fn, built into)VAE
159MB - original (built into)
ベースモデルや、変換済みの各種GGUFモデルは、下記のURLにて公開しています。
Stable Diffusion 3 Medium
https://huggingface.co/stabilityai/stable-diffusion-3-medium
※ ダウンロードに許可が必要city96/stable-diffusion-3-medium-gguf
https://huggingface.co/city96/stable-diffusion-3-medium-gguf
まず、元のモデルで出力します。


次に、GGUF化したモデルで出力します。それほど変化はありません。


▼ 4-6. FLUX.1
FLUX.1のモデルは通常、共通のText EncoderとVAEを利用するとみられ、GGUF化で問題が発生する可能性は低いと思います。むしろ、GGUF形式で用意されている割合が最も高いアーキテクチャかもしれません。
ベースモデル(FLUX.1 [dev])をGGUF Q8_0に変換した場合の内訳は下記のとおりで、Modelのサイズが10.2GB縮小しました。FLUX.1はサイズが比較的大きいので、変換による恩恵を受けられやすいかもしれません。
Model
22.1GB - original
11.9GB - GGUF Q8_0
参考まで、Text EncoderとVAEの情報です。t5xxlはいずれかのみを使用します。
Text Encoder
235MB - original (clip_l)
9.11GB - original (t5xxl_fp16)
4.55GB - original (t5xxl_fp8_e4m3fn)VAE
319MB - original
ベースモデルや、変換済みの各種GGUFモデルは、下記のURLにて公開しています。
FLUX.1 [dev]
https://huggingface.co/black-forest-labs/FLUX.1-dev
※ ダウンロードに許可が必要city96/FLUX.1-dev-gguf
https://huggingface.co/city96/FLUX.1-dev-gguf
まず、元のモデルで出力します。


次に、GGUF化したモデルで出力します。変化は小さく、ぱっと見では分かりにくいです。


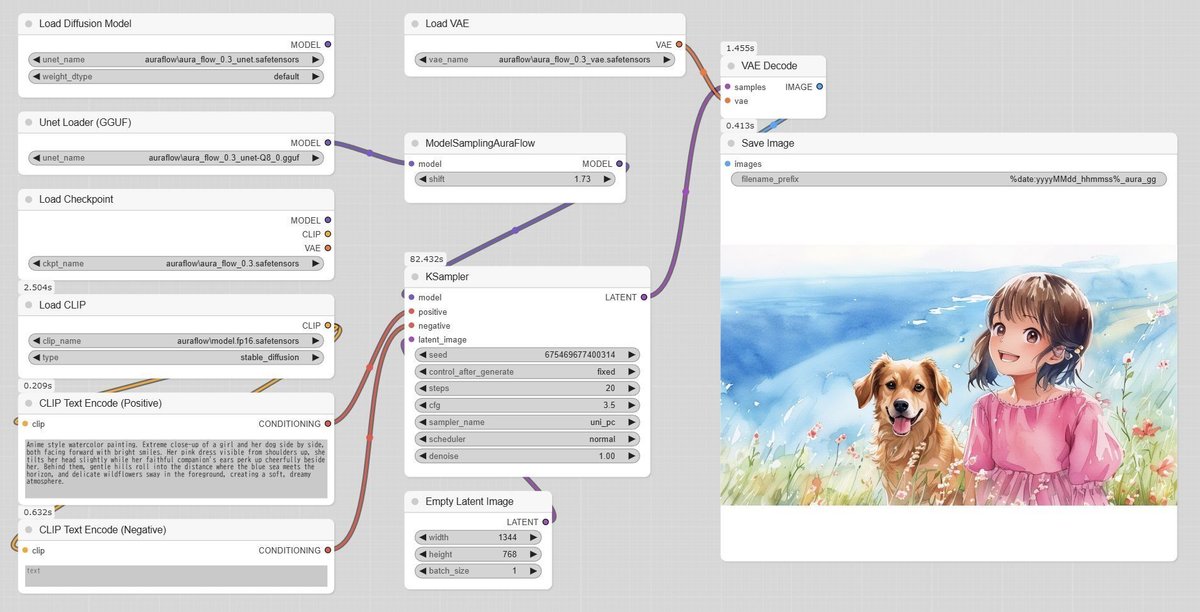
▼ 4-7. AuraFlow
AuraFlowについて簡単に説明しておくと、SD 3にインスピレーションを受けて作られ、有名なPony Diffusionの次期モデルV7(開発中)はこれをプライマリベースとして選択しています。AuraFlowは、生成サービスも行っているfalがリリースしています。
ベースモデルがText EncoderとVAEを内蔵していることや、前述の事情から察するに、チューニングモデルは独自のText EncoderやVAEを持つ可能性があります。
ベースモデル(AuraFlow v0.3)を分離してGGUF Q8_0に変換した場合の内訳は下記のとおりで、Modelのサイズが6.08GB縮小しました。単体で配布されているText EncoderとVAEの情報も加えておきます。
Model
12.7GB - original (built into)
6.84GB - GGUF Q8_0Text Encoder
2.27GB - original (built into)
2.74GB - original (text_encoder/model.fp16.safetensors)
4.55GB - original (text_encoder/model.safetensors)VAE
159MB - original (built into)
159MB - original (vae/diffusion_pytorch_model.fp16.safetensors)
319MB - original (vae/diffusion_pytorch_model.safetensors)
ベースモデルや、変換済みの各種GGUFモデルは、下記のURLにて公開しています。
AuraFlow v0.3
https://huggingface.co/fal/AuraFlow-v0.3city96/AuraFlow-v0.3-gguf
https://huggingface.co/city96/AuraFlow-v0.3-gguf
まず、元のモデルで出力します。


次に、GGUF化したモデルで出力します。本例では顎の形が違いますが、全体的な変化は小さいです。なお、モデルに入っていたText Encoderではエラーが出ます。Load CLIPのtypeは該当するものが無く、設定内容は無視されるようです。

■ 5. その他
私が書いた他の記事は、メニューよりたどってください。
記事に関することで何かありましたら、Xの@riddi0908までお願いします。