
Windows PCでStable Cascadeの生成を試してみる

Last update 2-25-2024
※(2-25) 本記事が始まる前に、別の方法を紹介しているのでご覧ください。
※VRAM 6GB以上、推奨12GB以上です。本記事では実際の手順を示していますが、通常の記事よりも少しだけ説明を省略しています。
ComfyUIで生成する記事を公開しました。LargeモデルはVRAM 8GB、Liteモデルは6GBで実行できそうです。
扱いやすいGUIを紹介します(要VRAM 12GB)。
▼ 本記事について
概要
Stability AIは日本時間の2-13-2024に、新しいText to Image(T2I)モデルのStable Cascadeを発表し、翌日にはモデルとサンプルコード(スクリプト)が公開されました。VRAM使用量は少し多め(16GB超)でしたが、hakomikan氏が改良したコードで節約ができるようですので、さっそく試してみます。
使用するコードについて
基本的に、下記の記事にあるコードを使用します。こちらに目を通して事足りる方は、本記事は必要ないと思います。そうではない方も、記事の内容をよく確認してください。
Stable Cascadeについて
名称がStable Diffusionではない理由はアーキテクチャが異なるためです。つまり、Stable Diffusionの後継バージョンではありません。
Stable Cascadeのご紹介
https://ja.stability.ai/blog/stable-cascade
Stable Cascade用のサンプルコード(スクリプト)
https://github.com/Stability-AI/StableCascade
Stable Cascadeモデル(Diffusers及びsafetensors)
https://huggingface.co/stabilityai/stable-cascade
▼ 関連記事等
他の方の、Stable Cascadeに関する記事等です。早めに紹介しておきたいので、ここに挟みます。
下記は実行例等です。VRAM使用量が16GBを超えるケースが多いようです。Google Colabの場合は、足りないとエラーを出して処理を停止します。Windowsの場合は、足りないと共有GPUメモリにはみ出て実行が遅くなるか、メモリ不足で処理を停止します。
ComfyUIを利用(VRAM 12GBなら余裕?)
Google Colabを利用(無料枠で実行可能)
Google Colabを利用(有料版でA100が必要)
WSLを利用
Windowsを利用(1)
Windowsを利用(2)
Stable Cascade One-Click Installer
https://github.com/EtienneDosSantos/stable-cascade-one-click-installer
▼ 準備1
インストール
動作の確認は、VRAM 12GBのGeforce RTX 3060、Python 3.10、Git、CUDA Toolkit 11.8が導入されたPCで行いました。作業ディレクトリを「C:\aiwork」としていますので、適宜読み替えてください。
コマンド プロンプトを開いて、下記のコマンドを順番に実行します。途中、renコマンドでディレクトリ名を変更して、Pythonで専用の仮想環境を作成しています。最後の行で、数GB程度のダウンロードが発生します。
cd \aiwork
git clone https://github.com/Stability-AI/StableCascade
ren StableCascade stable-cascade-test
cd stable-cascade-test
python -m venv venv
venv\Scripts\activate
python -m pip install --upgrade pip
pip install -r requirements.txt実行のためのパッケージが足りなかったので、下記も実行します。
pip install ipythonモデルのダウンロード
次に https://huggingface.co/stabilityai/stable-cascade/tree/main から下記のファイルをダウンロードして「stable-cascade-test\models」ディレクトリに移動します。
effnet_encoder.safetensors (81.5 MB)
previewer.safetensors (16 MB)
stage_a.safetensors (73.7 MB)
続けてstage_bとstage_cについても同様に対応します。こちらはLargeモデルとLiteモデルそれぞれにfloat32とbfloat16があるため、4種類ずつ存在します(stage_cはさらにpretrainedのfloat32モデルあり)。
stage_[b,c].safetensors (6.25GB, 14.4GB)
stage_[b,c]_bf16.safetensors (3.13GB, 7.18GB)
stage_[b,c]_lite.safetensors (2.8GB, 4.12GB)
stage_[b,c]_lite_bf16.safetensors (1.4GB, 2.06GB)
STAGE BとSTAGE Cのモデルの選択は、使用VRAM量に影響します。また、公式にアナウンスしていて実際に確かめた結論として、なるべくstage_cはliteではない方の使用を推奨します。
筆者の実行結果も踏まえると、以下のように対応してみるのが良いと思います。コードはオリジナル版と改良版の2種類があり、本記事では便宜上「標準版」「節約版」と呼びます。
VRAM 6GB:「stage_c_lite_bf16 + stage_b_lite_bf16 + 節約版」とする。
VRAM 8GB:「stage_c_lite_bf16 + stage_b_lite_bf16 + 標準版または節約版(実行時間の短い方)」とする。画質に不満があればVRAM 12GBの方法を試してみる(可否や実行時間は未確認)。
VRAM 12GB:「stage_c_bf16 + stage_b_bf16 + 節約版」とする。
VRAM 16GB:「stage_c_bf16 + stage_b_bf16 + 標準版」とする。念のため、節約版と実行時間を比較してみる。
▼ 準備2
設定ファイルを用意します。「stable-cascade-test\configs\inference」内に「stage_b_3b.yaml」と「stage_c_3b.yaml」があるので、コピーしてから編集します。ファイル名はコード(スクリプト)側で指定するだけなので任意です。モデルのファイル名に合わせるのが分かりやすいと思います。
stage_b
下記はオリジナルの内容です。
# GLOBAL STUFF
model_version: 3B
dtype: bfloat16
# For demonstration purposes in reconstruct_images.ipynb
webdataset_path: file:inference/imagenet_1024.tar
batch_size: 4
image_size: 1024
grad_accum_steps: 1
effnet_checkpoint_path: models/effnet_encoder.safetensors
stage_a_checkpoint_path: models/stage_a.safetensors
generator_checkpoint_path: models/stage_b_bf16.safetensorsmodel_version: 3B → liteの場合は700M
dtype: bfloat16 → bf16ではない場合はfloat32
batch_size → 1にする
generator_checkpoint_path → 使用するモデルのファイル名
stage_c
下記はオリジナルの内容です。
# GLOBAL STUFF
model_version: 3.6B
dtype: bfloat16
effnet_checkpoint_path: models/effnet_encoder.safetensors
previewer_checkpoint_path: models/previewer.safetensors
generator_checkpoint_path: models/stage_c_bf16.safetensorsmodel_version: 3.6B → liteの場合は1B
dtype: bfloat16 → bf16ではない場合はfloat32
generator_checkpoint_path → 使用するモデルのファイル名
▼ 準備3
コードの作成
冒頭でも述べたとおりコードは拝借しますので、そちらからコピーしてください。それを、「stable-cascade-test\」上に拡張子pyのファイルとして保存します。ファイル名は任意です。
前述の通り、コードはオリジナルの標準版と、改良された節約版の2種類があります。どちらであっても編集内容は変わりません。
まずは下記の部分を、準備2で作ったファイル名に変更します。
# SETUP STAGE C
config_file = 'configs/inference/stage_c_lite_3b.yaml'
...
# SETUP STAGE B
config_file_b = 'configs/inference/stage_b_lite_3b.yaml'下記の修正も推奨します。変数名を「time」から変更します。
time = time.strftime(r"%Y%m%d%H%M%S")
↓
nowtime = time.strftime(r"%Y%m%d%H%M%S")
fileName = f"img-{time}-{i+1}.png"
↓
fileName = f"img-{nowtime}-{i+1}.png"下記のプロンプトと画像サイズは、好みで変更することができます。
caption = "Cinematic photo of a girl in cafe"
height, width = 832,1216コメントアウトを外して下記のようにすると、固定のSeed値が使用できます(デフォルトはランダム)。インデントがずれるとPythonではエラーになるので、「#」とその後ろのスペース1個のみを削除します。
torch.manual_seed(2244096)▼ 実行
準備に使用したコマンド プロンプトを開いたままであれば、すぐに実行できます。そうではない場合は、最初に下記のコマンドを実行します。
cd \aiwork\stable-cascade-test
venv\Scripts\activateあとは下記のようにコードをPythonに渡すだけです。初回は12GB程度のダウンロードが発生します。また、設定ファイルに誤りがあればエラーを出して終了するので内容を確認します。
python t2i_test1.py不備がなければ最後まで実行されて、画像ファイルが保存されます。
▼ 実行時間とVRAM使用量
使用するモデルとコードによって、実行時間とVRAM使用量が変わります。ここでは、VRAM 12GBのRTX 3060にて1216x832のサイズで出力した際の結果を記載します。標準版(オリジナルのコード)と、節約版(改良版のコード)の場合について、順番に記載します。VRAMは常時1GBほど消費していたため、一律で1GBを引いています。
stage_c_lite_bf16 + stage_b_lite_bf16
stage_c_liteを使用すると、見て分かる程度に質が悪くなる点に留意してください。参考まで、下の方にサンプル画像を掲載しました。
標準版では全体の実行時間が47秒、STAGE Cが20秒、STAGE Bが13秒でした。アプリのVRAM使用量は6GB台で、STAGE A(最後の部分)のピークは9.1GBでした。8GBの環境向けです。節約版と実行時間を比べて短い方を選んでください。

節約版では51秒、STAGE Cが20秒、STAGE Bが13秒でした。アプリのVRAM使用量はSTAGE C(前側の山)が4.4GB、STAGE B(後ろ側の山)が3.9GB、STAGE Aのピークは6.4GBでした。こちらは6GBの環境向けです。
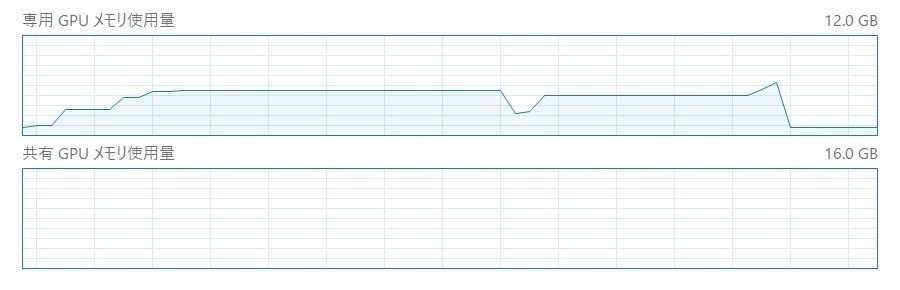
stage_c_bf16 + stage_b_bf16
標準版では16分3秒(VRAM不足が原因)、STAGE Cが3分、STAGE Bが11分でした。アプリのVRAM使用量は12GB台が大半を占め、STAGE Aのピークは14.4GBでした。16GB以上の環境向けと思われます。

節約版では2分27秒で、STAGE Cが1分、STAGE Bが40秒でした。アプリのVRAM使用量はSTAGE Cが9.2GB、STAGE Bが5.6GB、STAGE Aのピークが7.1GBでした。12GBの環境向けで、8GBでも一応動作するかもしれません。

その他
少しでも早く生成したい場合は、STAGE Bのみliteを選択する方法も考えられます。また、VRAM 24GB以上のリッチな環境では、float32のモデルを使用したり、batch sizeを上げたりすることができると思います。
▼ 画像サンプル
ここで最も注目していただきたいのは、STAGE Cにliteモデルを使用するとディテールが甘くなってしまう(質が落ちる)点です。
設定したプロンプトは「pastel color, flat anime style, upper body, girl, dynamic cute pose, frill dress, gold long hair, brown eyes, gentle smile, deep night, starry sky,」だったと思います。
stage_c_lite_bf16 + stage_b_lite_bf16
生成時間が短く、VRAM使用量もかなり抑えられます。

stage_c_bf16 + stage_b_bf16
liteモデルを選ばなければ、十分な画質が得られそうです。

stage_c_bf16 + stage_b_lite_bf16
生成時間を少しでも短縮したい場合は、STAGE Bのみliteモデルを使用する方法もあります。

おまけ
実写風の画像はかなり綺麗に生成できると思います。

アニメ風も、(アーキテクチャは違いますが)SDXLのベースモデルと比較して改善されていると思います。さらにチューニングを行うことで、利用者が望むモデルに変化することが期待されます。

▼ その他
私が書いた他の記事は、メニューよりたどってください。
noteのアカウントはメインの@Mayu_Hiraizumiに紐付けていますが、記事に関することはサブアカウントの@riddi0908までお願いします。
この記事が気に入ったらサポートをしてみませんか?