
業務活用事例➀:テレビ番組をまとめたい!

オリジナル投稿日:2019-06-25
IPGの木村です。
機械学習チームのチームリーダーをやらせて頂いています。
今回は、我々機械学習チームが取り組んだ1つの事例を紹介していきたいと思います。
機械学習を導入したいけど、どういう活用方法があるのかわからない
機械学習を導入したけども精度を上げるにはどうしていけばいいのかわからない
機械学習をチューニングするには何を考えればいいのかわからない
こういう方々への事例として、紹介できればと思います。
やりたいこと
テレビ番組を1つのIDでまとめる
例えば、ドラマだったら今週のドラマと来週のドラマは同じID。
とか、東京のドラマと沖縄のドラマが同じIDとか。
※ 1つ1つバラバラな番組情報。これらを1つのIDにまとめることを 番組マスタ化 といいます。
番組情報に番組マスタIDを関連付けることを 紐付け といいます。
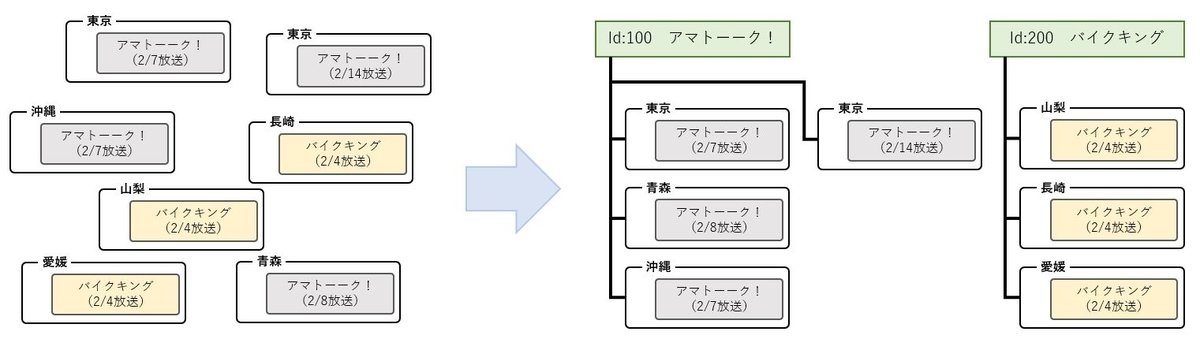
これにより、たとえば1つの番組に、キャッチ画像(番組のロゴや代表カット)を登録すれば、全国で同じデータが使えるようになるので、エコですね。
解決したい課題
現状は、システム側で予め用意した 番組名 、 放送局 、 放送時間 、 放送曜日 というようなパラメータを可変させたルールベースの条件をつけて振り分け(名寄せ)しています。
システムで名寄せしたもの結果から、ルールから外れたものを人の目でみてチェックして、
番組マスタIDへの紐付けを行い、
紐付けが間違っていたら紐付け直しをし、
新しい番組が発生したら番組マスタIDの発行を行う、
ルール化が必要であればルールに追加する
というような業務を実施しています。
※ なんでそもそもこれが課題なのか?
番組情報はその情報の特性上、いかに人の目に触れさせるか?というのが重要になる。
同じ番組なのに回によって、煽り文句がついたり、番組の内容がチラ見されたり、当日のゲストの情報が入ったりしますよね。
ex)
放送局A: アマトーーク! 豆腐大好き芸人[字]
放送局B: 雨上がり決死部隊のトーク番組 アマトーーク!
※ 放送局Aは、その放送回の特集内容を示し、放送局Bは、MCのタレント推し。地方によって、番組情報の入力の仕組みや担当者によって、入力内容が変わる。
その地方の特集番組とかであれば、やっぱり視聴者のみなさんには、あなたの街がテレビで放送されますよ!と伝えたいですよね。
ex)
関東: 今夜見くらべてみました[字] 今ブレイク中!謎の女・いちごちゃんVS木下優樹子!
長崎: 今夜見くらべてみました[字] 内山さん登場&謎の女・いちごちゃんVS木下優樹子!
※ 内山さんは、長崎県出身の方。緊急編成や延長によって、番組の放送時間が揺れたりする。
野球の延長でドラマの放送時間が変わっているなんてよくあることです。
ex)
通常: 家買うオンナ 21:00放送開始
伸延: 家買うオンナ 21:45放送開始
※ 通常21時放送開始のドラマが、事前の野球が延長したことで、開始時間がずれた。こういった入力データの特性があります。そのため、単純なルールでは、なかなか追いつかない事態が発生するんです。 もちろん、長年のノウハウで潰してきた問題は数多ありますが、それらが影響する場合もあります。
システム的な問題も踏まえて以下のような課題を抱えています。
▶ 振り分けシステム自体がかなり古く、ルールの変更による影響範囲が把握できないため、簡単にルールが変えられない。ルールに逸脱した番組がでると日々同じ作業を繰り返さないといけない。
▶ 作業者に関東の人間が多いので、メジャーな番組ならよいが、深夜番組や地方局の番組などは、作業者によってまちまちな判断になる場合がある。
▶ 作業者の習熟度によって、作業練度が異なる。作業者の教育コストがかかる。
これらの課題を解決するため、
機械学習が有益であると考え、導入に向けてのプロジェクトを立ち上げました。
機械学習の導入
これが、現在の学習モデルのイメージとなります。ここからは、この機械学習のモデルが解決すべき問題を整理しながら、学習データの処置と学習モデルの説明をしてみようと思います。
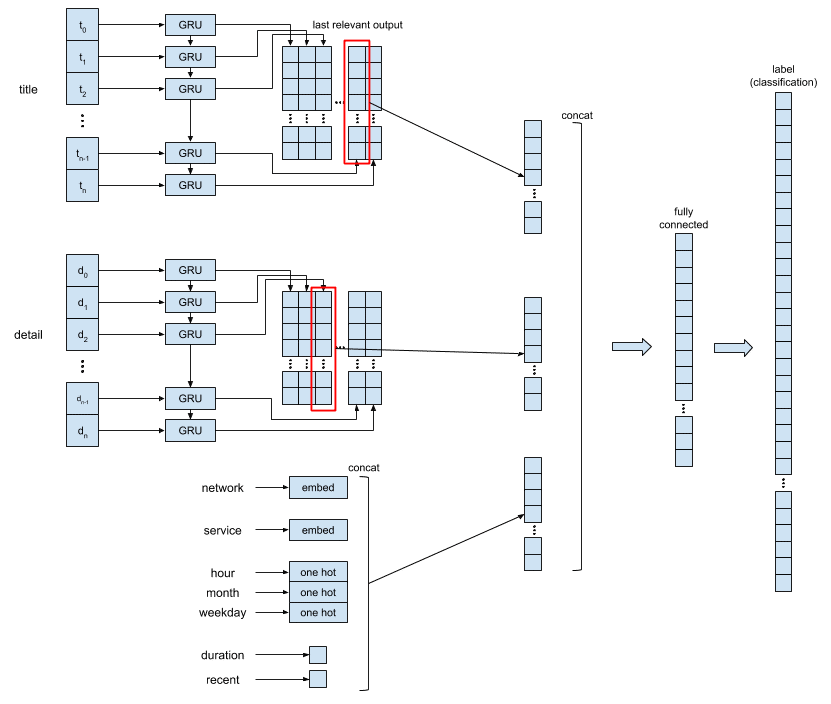
問題提起
(1) 新たな番組情報が発生したときに、この番組がどの番組マスタIDに属するのか、を分類する。
(2) 既存の番組マスタIDに属さない新たな番組が発生した場合に、それを分類しない(例えば、あるしきい値よりも低いスコアを与える)か、新しい番組マスタIDに分類する。
学習データ
学習を行う時点から、1年1ヶ月前までのデータを利用します。約 400万件の番組情報と約 2万件の番組マスタIDの組み合わせを学習データに使います。
まず最初は過去1ヶ月分程度から開始しましたが、なかなか精度があがらない。
テレビの番組の特性として、1年に1回しか放送しないものや、シーズンによって放送されるものなどがある。
1年以上にしても精度はあまり上がらず、それに対して、ハードウェアリソースや処理コストが増大した。
そのため、この期間にしています。
学習データの前処理
学習に用いる番組情報には、以下のようなパラメータが含まれます。
番組タイトル・番組概要
network_id・service_id
※ network_id は、放送局毎にユニークなID。
※ service_id は、放送局の各チャンネル毎にユニークなID。時間情報(放送開始・終了時刻)
これらを ニューラルネットワーク に入力するために、単純に投入することができないため、それぞれ以下のような処理を行いました。
番組タイトル・番組概要
番組タイトルと番組概要は、unigram によって解析します。
英数字は、グループ化し、英数字以外の文字(記号、スペース、日本語文字など)が表示されるまでを1文字とし、日本語文字は、1文字で区切っています。
例:
アマトーーク -> ['ア','マ','ト','ー','ー','ク']
hello world! -> ['hello','world','!']次に、unigram により解析された各文字を、学習データ 内で一意の ID を持つ 辞書 を作成します。ID = 0 は、未知の文字 に設定します。
例:$$
\begin{array}{c:l}
id & letter \\
\hline
0 & unknown \\
1 & ア \\
2 & マ \\
3 & ト \\
4 & ー \\
5 & ク \\
\end{array}
$$
アマトーーク -> [1,2,3,4,4,5]このままだと、ニューラルネットワーク の次元数が肥大化してしまうため、入力次元数を下げ、情報の高密度化を行うために、100〜200の層の embed layer に流し込みます。

embed layer を、100〜200層にしたのは、 word2vec を使用した場合に最大のパフォーマンスを出せる層の数と同様の値としました。
事前学習 は、実施していませんが、各文字の意味表現をより良くするために事前学習済みの word2vec と同じような処置を構築しています。
network_id・service_id
それぞれで、約 300のユニークなIDが存在します。初期には、 one hot を作って、ニューラルネットワーク に投入していたのですが、これらも番組タイトルや番組概要と同様に非常にまばらな状態のため、 embed layer に挿入することで、パフォーマンスが向上しました。
時間情報(放送開始・終了時刻)
放送開始・終了時刻 には、特定の番組マスターを区別できる重要な情報が多く含まれています。
たとえば、テレビ番組の多くは、平日の日中に放送されているものや、シーズンで放送されているもの、30分番組や2時間番組など、番組によって特徴があります。このことから、放送開始・終了時刻を使って、以下のような特徴を抽出しています。
month
weekday
hour in the day
duration
how recent
month 、 weekday 、 hour は、それぞれ、12/7/24 のサイズを持つ one hot として利用します。テストの結果、 sine/cosine 変換よりもパフォーマンスがよかったため、 one hot にしています。
duration は、放送時間長(秒) を、7200秒(2時間)で割り、それに 1 をかけます。これは、大体の番組の最大時間長は、2時間であるためそれをもとに計算しています。そして、how recent は、いま現在(学習するタイミングから)どれだけ、直近の番組であるかという特徴をだすために以下のように計算しています。
duration = min( 1.0, ( end_datetime - start_datetime ).seconds / 7200 )
how_recent = ( max_start_datetime - event_start_datetime / ( max_start_datetime - min_start_datetime ) )
学習モデル
上記のように処理した 学習データ を以下の 学習モデル(再掲)に入力します。
番組タイトル・番組概要
embed layer から吐き出されたものを、 RNN(Recurrent Neural Networks) 層に入力します。 RNN を利用しているのは、文字の出現順を覚えたまま学習を進めるためです。最初は、直接 fully connected に入れていたのですが、なかなか精度が向上せず、 RNN を導入しました。 RNN のモデルには、 GRU(Gated Recurrent Unit) を採用しています。
network_id・service_id・時間情報
それぞれ、 embed layer から出力されたもの、 one hot のデータなど、すべて結合します。
上記で吐き出された データ のすべてを結合し、 fully connected に挿入します。
fully connected の出力ラベルは、 番組マスタID で、これにより入力された 番組がどの番組マスタID に分類されるかを学習します。
テスト結果


表1.は、新規に発生した番組全体に対して、テストした結果を示し、表2.は、ルールベースの紐付けから漏れた番組に対してのみテストした結果になります。
それぞれ表において、
一致率とは、予測した番組マスタIDが正しかった番組の件数の割合を示します。
判定率とは、fully connected の output に対して、予測値の信頼度を割り出したものです。
網羅率とは、ある判定率以上の予測結果を抽出できた番組の件数の割合を示します。
※ 現状、判定率には softmax の値を利用しています。仮に、softmax に入れる前の output が、2番目の値と競っている場合でも判定率が99%を超えてしまうことも考えられるため、単純な確率で計算をしたほうが良いかもしれません。
番組情報全体の一致率は、約 93 % ということになります。機械学習モデルの精度を図る上では、この数値が高いほどいいモデルになったと言えると思います。
しかしながら、実運用を考えた場合が、仮にこれらすべて機械学習の結果によって紐付け行為をした場合に、約 7 %の間違いが存在しているということを示します。紐付けた状態からこの 7% の間違いを見つけるのは非常に困難です。
ここで、機械学習の結果の信頼度として、判定率という数値で threshold を設けると、判定率 99 %以上の場合の一致率は、99.8 %となり、かなり高い数値となりますが、まだ間違いが混入します。
間違うケースとしては、以下のように人でも間違いそうなケースが難しいようでした。そして、こういった単純なルールが組めるケースは、ルールベースのほうが強いようでした。
例:
- シリーズのバージョン違い
番組情報 水戸青門第15部 第1話「謎の美剣士隠密旅」(高松)[再]
機械学習の答え: 水戸青門 第32部(再放送)
実際の答え: 水戸青門 第15部(再放送)
- 本放送/再放送の違い
番組情報 解決済の女 警視庁文書捜査官 #2[再][字]
機械学習の答え: 解決済の女 警視庁文書捜査官(連続ドラマ)
実際の答え: 解決済の女 警視庁文書捜査官(再放送)そこで、対象を全体にするのではなく、ルールベースから漏れたものにすることとしました。それが表2.の結果となります。
表2の結果で重要なのは、判定率 99 %以上での一致率となりますが、この結果は、ほぼ、100%となっています。
※ case4.のみ、間違いがありますが、これは教師データの中でも結果が揺れたもの(作業者によって異なるマスターに紐付けたものと思われる)になり、機械学習の結果による間違いはなかったと判定しています。一応、判定率 99.9 %の結果を乗せていますが、一致率は 100 % となっていますが、やはり網羅率が低くなっています。
判定率 99% 以上の結果から自動紐付けを行った場合の網羅率は、約 57 % となっています。
判定率を下げていった場合の一致率に関して、表3. に記します。 98 %以下とすると間違いが混入する確率が多くなってしまいます。

これらの結果から、実運用では、ルールベースのものから漏れたもののみを対象に機械学習の結果で自動紐付けをすることとしました。
機械学習の結果の判定率により threshold を設け、判定率 99 %以上のもののみを紐付けることとしました。
判定率で、 threshold を設けることで、新しい番組は、ほぼ足切りされました。
しかしながら、新しい番組だけではなく、機械学習が判断つかなかったものなども入り混じっていました。(これには教師データのゆらぎも含まれます。)
判定率 99 %以下のものでも、70 %以上のものに関しては、管理UI上でサジェスト表示し、作業者の判断の揺れを防ぐような措置を導入しました。
これらの導入により、オペレータさんの作業は、
約 50 %の削減 を果たしました。
ということで、会社のMVPにも選ばれました!パチパチ
今回の記事では、このモデルに行き着くまでの経緯や、異なるモデルでの闘争記録、モデル内でのハイパーパラメータのチューニングの結果など、書ききれない内容がたくさんありました。また、いつか記事にしてご紹介できればなと思っています。
また、 新しい番組のみを判定する や すべて機械学習化していく など、 まだまだこれからの課題や改善の余地があります。 これらの取り組みについても、また別途ご紹介できればなと思っています。 ちなみに、こういった実績なども評価され radiko社の運営する radikoアプリの番組情報基盤として、我々の仕組みが採用されていたりします。ありがたい。
エンジニア募集中!
現在IPGでは、機械学習エンジニア、アプリエンジニア、Webエンジニアを募集しています。
こんなエンジニア募集中です。気軽にオフィスに遊びに来てください!ご連絡はこちらまで
生涯エンジニアを希望している人。
何事も「変化すること」を前提に、変化を受け入れ、柔軟に物事を進める事ができる人。
常に新しい技術分野にチャレンジし、良い物はチームや世間に広げたい人。
ユーザーファーストで物事を思考している人。
チームワークを大事にしている人。
効率化のために何でも自動化したくなる人。