QC検定2級テキストでの学習(今日は検定と推定)

昨日に続き、QC検定2級のテキストで品質管理におけるデータの見方を学習しています。
今日は取得したデータが以前取得したデータと同じなのか、異なるのかを凄く簡単に言うと計算した数字で判断すると言うもの。
比較対象はデータの規格値であったりすることもあります。
良くデータを比較するときに、グラフで可視化して、グラフの曲線が上昇傾向にあるとか下降傾向にあるとか、横倍とかで言うことがあります。
グラフからだけでは正確にデータが変化したかどうか判断できない場合もあります。
何かの変化点を境に、データが変化したと数字で言えないかどうかを判断するのに検定という考え方・手法を使うことがあります。
検定とは?
検定を行う上で2つの仮説を立てます。比較対象がある値と等しい(帰無仮説という)と比較対象はある値と異なる(対立仮説)です。
条件の上で検定の判断が間違っている確率(有意水準)を設定します。有意水準から、帰無仮説を棄却する領域を設定します。
次に調べたい母集団からサンプルデータを収集し、検定統計量というものを計算します。
検定統計量と棄却領域を比較して、検定統計量が棄却領域に入れば、帰無仮説を捨てます。そうすると、対立仮説だけが残ります。
したがって、調べたい対象は比較対象と異なると言えると結論付けられます。
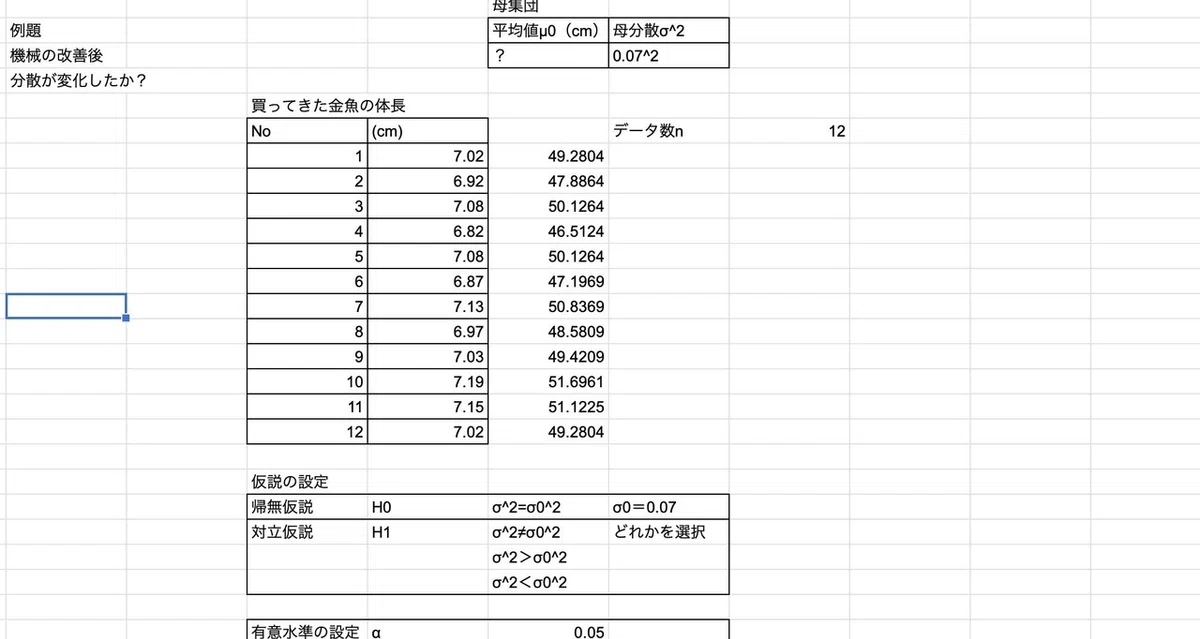
実際にテキストの問題を解いてみた
というようなことを文章で書いてもイメージが湧かないので実際にテキストの例題をもとに計算してみました。
検定と推定は、調査対象によって計算モデルが複数あるため、このケースのときは、どの計算モデルを使うか判断する必要があります。
今は専用のソフト等がありますので自分で計算する回数は減ったような気がします。ただソフトを使うにしても検定・推定の考え方は知っておいた方がいいかなと思います。
今日私がテキストの例題で計算したものは、一部ですが紹介します。きれいにまとめてはいませんが。
平均値の検定と推定(比較対象が正規分布である場合)


一つの母分散に関する検定(比較対象の母分散は分かっているが平均値は不明)