
生成AI時代のレコメンド

生成AIの登場によって、レコメンドの仕組みが大きく変わろうとしています。例えば、ChatGPTにおすすめのマンガを聞いてみると、各漫画の特徴を捉えたうえで、おすすめしてくれます。

生成AIはレコメンドタスクを解くように開発されたわけではないですが、あらゆるジャンルにおいてある程度の性能でレコメンドできてしまうのは、とても驚異的なことです。また、推薦理由の提示も当たり前のようにしてくれるのも驚きです。従来のレコメンドでは、アイテムの並び替えパートやアイテムの推薦理由作成パートなどの、それぞれのパートごとに、異なるアルゴリズムを駆使して、最終的にレコメンドをユーザーに届けていました。一方で、生成AIでは、その一連の作業が、1つのAIでできてしまいます。
このように、生成AIは、従来のレコメンドではできなかった新しいレコメンドを可能にしてくれます。この記事では、生成AIの中でも大規模言語モデル(LLM)に焦点を当てながら、生成AI時代にどのようなレコメンドがありうるのかを俯瞰したいと思います。
レコメンドにおける大規模言語モデルの活用
先ほど、紹介したマンガのレコメンドのように、Web上にデータが大量にある書籍や映画、料理などは、生成AIが学習してくれているので、ある程度のレコメンド性能が実現されています。一方で、Web上にデータがないような自社サービス独自の商品や情報をレコメンドする場合には、いくつかの工夫が必要です。そこで、自社サービスにレコメンドを組み込むことを想定して、レコメンドにおけるLLMの活用を俯瞰していきたいと思います。(※一部技術的に細かい話も出てきますが、必要に応じて適宜読み飛ばしてください。)
活用方法は大きく分けて、事前学習モデルを活用するものと、大規模言語モデルのアーキテクチャを活用する2種類に分けることができます。
事前学習モデルを活用したレコメンド
情報抽出・構造化としてのLLM活用
Embedding取得としてのLLM活用
RAGによるレコメンド
おすすめアイテムの推論としてのLLM活用
大規模言語モデルのアーキテクチャを利用したレコメンド
(※この整理は、あくまで私独自の観点で、網羅的でありません。より一般的な整理を知りたい方は、サーベイペーパが出ていますので、[wu 2024]等をご参考ください。)
事前学習モデルを活用したレコメンド
事前学習モデルは、大量のデータの学習によって、様々な知識や推論能力を有しています。それをレコメンドタスクに活用します。
情報抽出・構造化としてのLLM活用
まずは、テキストなどの非構造データから、情報抽出したり構造化したりする活用方法です。これはシンプルな方法ですが、実務では大変重宝するやり方です。例えば、求人を求職者にレコメンドするという仕事レコメンドのケースを考えてみます。この場合、求人内容はテキストとして記述されています。LLMを活用することで、そのテキストから職種や業種などの情報を構造化して抽出することができます。また、同じように求職者側も職務経歴書や履歴書から、希望の職種や業種などの情報を構造化して抽出できます。そして、その情報をもとに、ルールベースや従来のアルゴリズムでレコメンドを行うことができます。

従来はこの構造化を現場の人手によるオペレーションや独自の機械学習モデルで行っていました。しかし、現場のオペレーションにおいて、タグ付けやカテゴリ付けを徹底させるのが大変だったり、人による作業のばらつきがでたり、人件費が高かったりと難しい側面がありました。また、独自の機械学習モデル構築にも、データ収集や構築に時間がかかっていました。特に、カテゴリやタグが新規に追加される場合に大変でした。例えば、求人レコメンドにおいて、新規に「LLMエンジニア」のような新しい職種が追加される場合には、新しくモデルを構築する必要がありました。一方で、LLMによる情報抽出では、プロンプトに「LLMエンジニア」を追加するくらいで、対応が可能になります。
つまり、情報抽出や構造化は、今まで大変でしたが、LLMの登場により安く速く良い精度で行うことができるようになりました。そのため、情報の変換器としてのLLMは、既存の人手によるオペレーションの至る所に、組み込まれていくように思います。また、最近のLLMは、それを実現する機能が進化しています。例えば、GoogleのGeminiは200万トークンまで対応していたり、JSONモードを利用すれば出力をJSON形式に固定できたり、BigQueryからSQLでLLMを利用することができたりと、多様な場面での活用が可能になります。
Embedding取得としてのLLM活用
続いては、Embedding取得としてのLLM活用です。OpenAIやGoogleのEmbedding APIを利用すると、テキストをベクトルに変換してくれます。そのベクトルには、テキストの意味が埋め込まれており、似ているテキストは似たベクトルになります。このベクトルを用いて、レコメンドすることができます。
例えば、求職者の履歴書と求人の求人票の内容をそれぞれベクトル化します。そして、求職者のベクトルに一番近い求人をおすすめします。この方法の良いところは、ハルシネーションを起こさずに、必ず社内のアイテムをレコメンドできることです。ChatGPTなどに、おすすめマンガを聞くと、時々存在しないマンガを教えてくれることがあります。一方で、このEmbeddingによるやり方では、探索対象の空間が社内のアイテムに限られており、その中で一番近いものをおすすめするので、ハルシネーションは起きません。

ただし、Embeddingによるレコメンドの性能を上げるには、様々な工夫が必要になります。ここで紹介したすごくシンプルなベクトル化と類似検索では、実用に耐えないことがしばしばあり、ベクトル化する前のテキストの処理を工夫したり、類似度計算の機械学習モデルを構築するなどの対応が必要になることがあります。
RAGによるレコメンド
Retrieval-Augmented Generation(RAG:検索拡張生成)は、外部情報の検索を組み込むことで、ハルシネーション等を防ぎ、回答生成の質を向上させる仕組みです。この仕組みをレコメンドに応用する方法を紹介します。
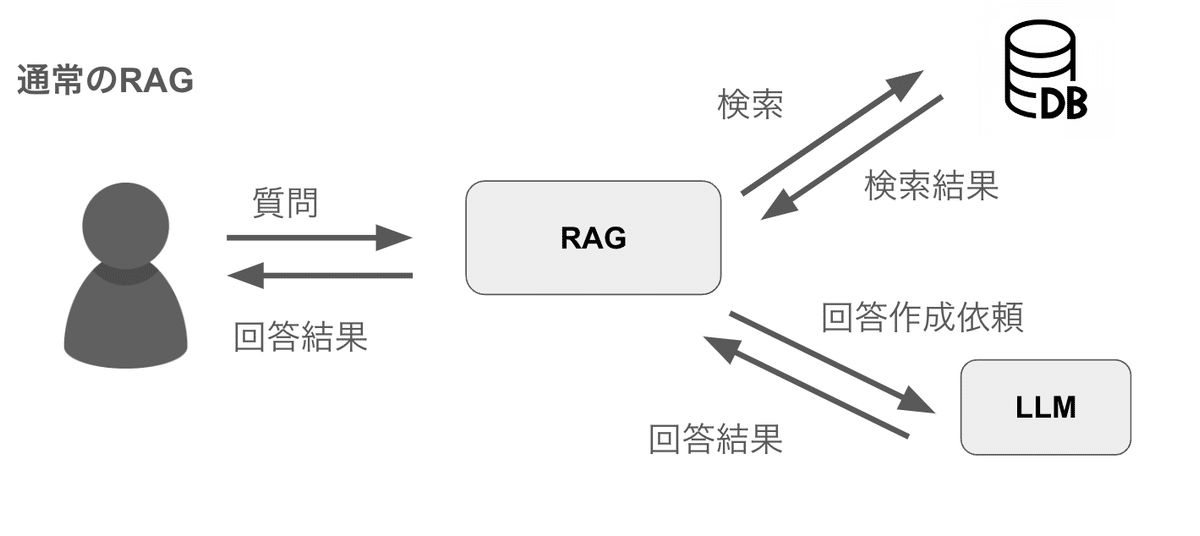
まずはその前に、検索とレコメンドの違いを簡単に説明します。検索では、ユーザーが検索キーワード(クエリ)によって能動的に情報を探しに行きます。一方で、レコメンドでは、検索キーワード(クエリ)が入力されないことも多く、ユーザーの行動履歴等から推測されたおすすめアイテムをユーザーに提示します。(※そのため、冒頭に紹介したChatGTPによるマンガレコメンドの例は、検索と分類されることもあります。)
RAGにおいて、ユーザーからの入力なしで、ユーザーの行動履歴等を入力することで、ユーザーにおすすめアイテムを届けることができます。前述した「情報抽出・構造化としてのLLM活用」や「Embedding取得としてのLLM活用」を利用することで、システムの裏側で自動的にユーザーの嗜好や興味を抽出して、おすすめアイテムをレコメンドすることが可能です。つまり、ユーザーからの明示的な質問がなくても、レコメンドすることが可能です。

おすすめアイテムの推論としてのLLM活用
大規模言語モデルの推論能力を駆使してレコメンドを行う方法です。ユーザーのプロフィール情報と過去に購入・閲覧したアイテムとおすすめすアイテム候補群をテキストとして記述し、おすすめすべきアイテムをLLMに出力してもらうという方法です。RAGでは、おすすめアイテムのスコア計算をEmbedding等を用いて、LLMの外側でしています。一方で、ここで紹介する方法は、以下のようなプロンプトでLLM自体におすすめアイテムのランキング計算をしていもらいます。
[ユーザーの過去の行動履歴: トイ・ストーリー, マトリックス, ……]
[候補アイテム候補群: スターウォーズ, スパイダーマン, ……]
私の行動履歴に基づいて、次に見たいと思う可能性が高い順にこれらのアイテムをランク付けしてください。
このプロンプトの記述の仕方によって性能が大きく変わることが報告されています[How 2024]。例えば、映画レコメンドにおいて、ユーザーの視聴履歴の記述の仕方は、次のような種類があります。
1.系列プロンプト
私は過去に以下の映画を順番に観てきた。0.トイ・ストーリー、 1.ジュラシック・パーク、・・・・
2.直近のインタラクションを重視したプロンプト
私は過去に以下の映画を順番に観てきた。0.トイ・ストーリー、 1.ジュラシック・パーク、・・・・。私が最近見た映画は『タイタニック』です。
3.In-context learning (ICL)
過去に次の映画を順番に見たとしたら、『0. トイ・ストーリー』、『1. ジュラシック・パーク』、...、あなたは私に『タイタニック』を勧めるべきです。そして、今『タイタニック』を見ました。
この3種類の中では、2と3番目の方法がレコメンド性能が高かったと報告されています。

また、候補アイテムをプロンプトに入力する方法によっても性能が変わることが報告されています。LLMにおすすめアイテムをランキング付けしてもらう際に、アイテムすべてをプロンプトにいれるのは、文字数制限のため難しいです。そのため、なにかしらのアルゴリズムで、まずは候補アイテムを数十個に絞って、それをプロンプトに入れます。そのときに、アイテム候補群の順番が予測順位に大きく影響を与えることが報告されています。最初の方に位置するアイテムのほうがレコメンドされやすいです。その影響を抑えるために、候補のアイテム群の順番をランダムに並び替えて、LLMに予測させるということを複数回行い、その結果を集計して最終的にレコメンドする方法が提案されています。
他にも、LLMをレコメンドタスクに特化するようにファインチューニングするような方法も提案されています。[Bao 2023]
ユーザーの過去の好き嫌いのアイテム群をプロンプトに入れて、新規のアイテムが好きか嫌いかを予測するタスクをLLMに解かせると、常に好きと回答したり、回答することを拒否するということが報告されています。その課題を解決するために、Instruction-Tuningをレコメンドに特化させた手法が提案されています。まずは、Alpacaデータセットで一般的なInstruction-Tuningをしたあとに、レコメンドタスクに特化した下記のデータセットでInstruction-Tuningを行います。どちらもLoRAを利用することで軽量に学習が可能です。このファインチューニングにより性能が向上したと報告されています。


これらのように豊富な知識と高い推論能力があるLLM自体にレコメンドしてもらう方法が増えています。
大規模言語モデルのアーキテクチャを利用したレコメンド
事前学習モデルを利用するのではなく、モデルのアーキテクチャを利用するレコメンドを紹介します。LLMが驚異的な推論性能を有している理由の1つに、Transformerと呼ばれるアーキテクチャがあります。このアーキテクチャを利用して、レコメンドのデータセットを1から学習させます。
LLMでは、単語の系列を渡して、次の単語を予測するように学習します。レコメンドタスクにおいても、各ユーザーが購入したアイテムの系列をもとに、次に購入するアイテムを予測します。そこで、アイテムのIDを単語とみなして、アイテムの系列を文章とみなすことで、LLMのモデルを活用することができます。
このように言語のデータとレコメンドのデータは、IDの系列データとして同一視し、自然言語処理分野で提案されてきた手法をレコメンドに活用することは昔からされていました。

レコメンド分野でのTransformerの活用は、デコーダ型の単方向のSASRecや、エンコーダ型の双方向のBERT4Recなどの手法が提案され、従来のレコメンド手法より性能が高いことが報告されています。

一方で、レコメンドのデータには、言語のデータにないような特徴がいくつかあり、その特徴を反映した新しいモデルも提案されています。ここでは、個人的におもしろかった2つのモデルをご紹介します。
1つ目が、アイテムの系列におけるタイムスタンプを考慮するモデルです[Li 2020]。レコメンドのデータセットでは、ユーザーがアイテムを購入や閲覧したときのタイムスタンプの情報が手に入ります。下図の映画の例のように、アイテムの系列が同じだったとしても、そのタイムスタンプが異なれば、レコメンドすべきアイテムは変わるだろうということをモデル化したものです。

アーキテクチャとしては、アイテムのEmbeddingに位置Embeddingを足す箇所において、時系列間隔の情報も足し込むことで、時系列の情報もモデルに組み込みます。
2つ目が、膨大なアイテムの種類に対応したモデルです[Petrov 2024]。例えば、Amazonでは数億を超えるアイテムがあります。これらの数億のアイテムに対して、別々のトークンを付与した場合、Embeddingのデータ量だけでも甚大になり、学習がうまくいきません。そこでサブトークンを活用して、似たアイテムには、似たサブトークンが割り振られるようなトークン割り当て方法が提案されています。それを実現するために、ユーザーとアイテムの行列を特異値分解(SVD)を駆使して、サブトークン化を実現しています。この点が、レコメンドならではでおもしろかったです。


以上をまとめると、レコメンドタスクに対して、IDの時系列という類似性を利用して、大規模言語モデルのアーキテクチャを利用することができ、性能が高いです。また、言語タスクにはないレコメンドならではの特徴をモデルに組み込むことで、さらに性能が高まります。
バイアス
最後に、LLMによるレコメンドのバイアスについて紹介して終わりたいと思います。従来のレコメンドでは、人気なアイテムほどレコメンドされやすいなどのバイアスが報告されています。LLMによるレコメンドでも、このような人気バイアスは観測されています[How 2024]。また、豊富な知識と高い推論能力を有するゆえのLLM独自のバイアスも指摘されています[Xu 2023]。例えば、ニュース記事を次のようなプロンプトでレコメンドする場合を考えます。
ユーザー名:{{user name}}におすすめのニュースタイトル20件とそのカテゴリーを教えてください。
ユーザー名を世界各国のそれぞれの国で一般的な名前に設定して、どのようなレコメンドがされるかを分析したところ、ユーザー名によってレコメンド結果が大きく変わることが報告されています。例えば、アフリカ系のユーザー名の場合は、政治などのニュースがレコメンドされやすいです。

同様のバイアスが、仕事のレコメンドにおいても見られています。アフリカ系のユーザー名の場合は、サービス職がおすすめされやすく、アジア系の場合は、教育職がおすすめされやすいです。
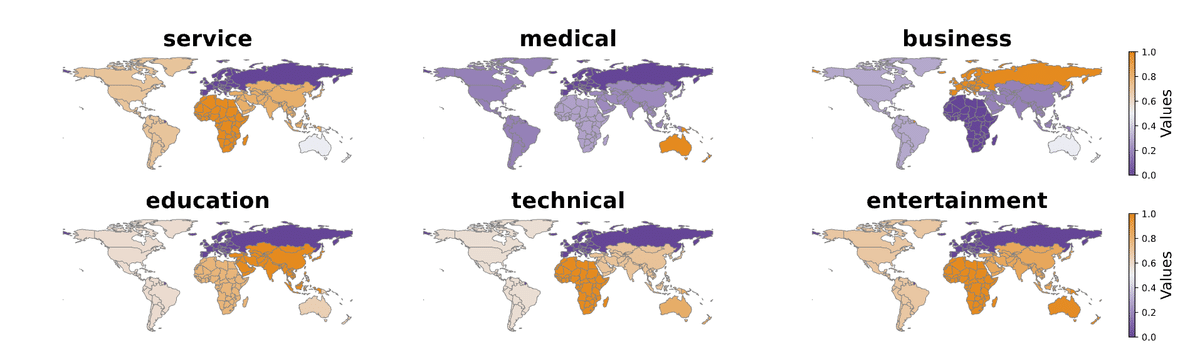
このように、LLMを用いたレコメンドには、知らず知らずのうちに、様々なバイアスが入り込む可能性があります。そのため、実務で活用する際は、このようなバイアスを検知し低減させるような取り組みが重要になってきます。
まとめ
生成AI時代のレコメンドについて、大規模言語モデル(LLM)について焦点を当てながら、事前学習モデルを使うものとLLMのアーキテクチャを利用するものを紹介しました。この記事を書くにあたり、レコメンドの論文を眺めてると、レコメンド分野と自然言語処理分野、レコメンド分野と検索分野の境界が今後より薄れていくように感じました。今後の新しいレコメンドの可能性はとても楽しみです。