#41 グラウンディング恐竜は羊のアテンションを見るか?

どうも、まりなです。
みなさんはChatGPT使ってますか?
文章の要約や創作のネタ出し、プログラミングもしてくれて便利ですよね。
ChatGPTはよく生成AIとも呼ばれます。「AI」は日本語では「人工知能」で、まるで知能を持っているかのような回答文章を書くのでChatGPTが「AI」であることには疑いようはないのですが、「AI」と同じ文脈で「機械学習」という言葉もよく聞きませんか?
こちらの入力した質問や要求に対して回答文を作成する、という過程には「学習」があるようには感じませんがChatGPTは「機械学習」を行っているのでしょうか?
そもそもGPTはGenerative Pre-trained Transformerの略で、日本語にすると「生成的事前学習済みトランスフォーマー」といったところでしょうか。そう、GPTは「事前学習済み」なのです。
ネット上にある大量の文章を使い、学習を済ませた状態で私たちが使えるようにしてあるのがChatGPTなのです。学習に用いた文書の量は容量で言う570GB(GPT-3)で一文字8bitとすると約6120億文字ということになります。全然想像がつきませんね。
生成的(Generative)と事前学習済み(Pretrained)は分かりましたがトランスフォーマーって何やねんって話ですよね。

(海洋堂, https://kaiyodo.co.jp/items/revoltech/ay014/より引用)
2017年、NeurIPSでGoogleの研究チームらにより発表された “Attention is All You Need” という挑戦的な題の論文内で提唱されて以来、トランスフォーマーは論文の題の通り、情報科学の研究で注目の中心となり続けています。
トランスフォーマーはセルフアテンション機構を持ったアルゴリズムで学習データの「どこに注目すべきか」を自ら学習します。つまり入力された文書中のどの単語に注目すべきかを人間が示す必要なく、自ずと判断するようになるのです。
これにより既存のアルゴリズムより少ない計算コストで高い精度の回答文章を生成することを実現しました。
ChatGPTはトランスフォーマーの計算コストの小ささを最大限に活用し、既存のアルゴリズムを遥かに上回る量のデータでの学習を実現しました。その結果多くの種類のタスクで精度の最高記録を更新しました。
「シンギュラリティ」の到来を予感させるこの出来事は情報科学の研究者らをも驚かせました。
もちろん、学習データ内の誤りを含む文章のため、事実と異なる文章をあたかも本当のように生成してしまう「ハルシネーション問題」や、研究が豊富な計算資源をもつ少数の企業にのみ先導されてしまうのではないかという危惧、「これ以上学習データを増やしても私たちの生活にもたらす恩恵は変わらないのではないか」という意見もありますが、トランスフォーマーがChatGPTをはじめとするLLM(Large Linguistic Model)の研究を大きく推し進めたことは事実です。
トランスフォーマーの及ぼす影響は自然言語処理の領域にとどまらず、コンピュータビジョンの領域にも革新をもたらし始めています。
2020年、Dosovitskiyらによって発表されたビジョントランスフォーマーはトランスフォーマーの対象を画像データに広げました。
その拡張方法もシンプルで画像を16x16のパッチに分割し、それをトランスフォーマーに扱える形に処理したものをほとんどそのままのトランスフォーマーに与えるというものでした。
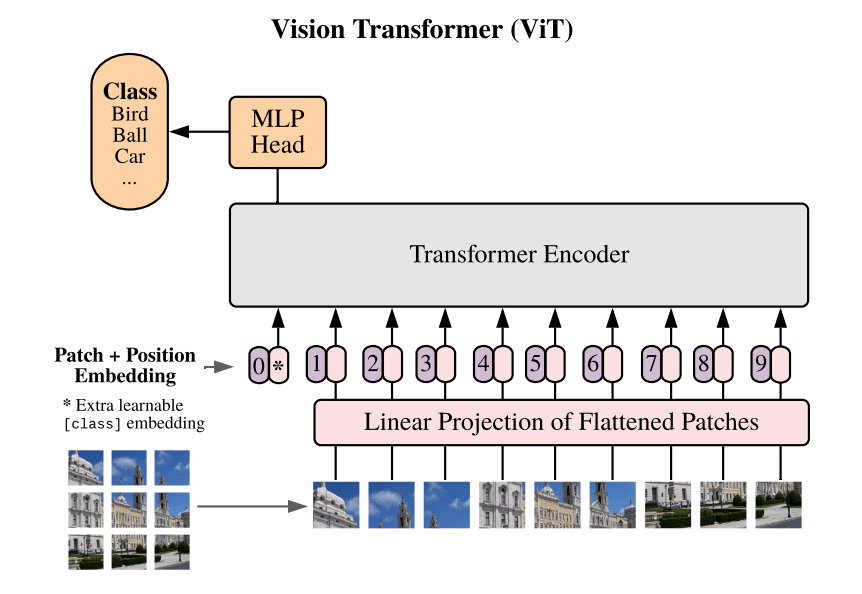
ビジョントランスフォーマーの登場によりこれまでより大量のデータを効率的に、しかも高い精度で活用できるようになり、物体検出、画像認識、画像生成などの研究で大きな躍進が見られました。
例えば2023年、Metaの研究チームにより発表されたSegment Anythingは事前に大量の画像データで学習を行い、新たな画像に対して追加の学習を必要としない高い精度の画像認識を実現しています。

またビジョントランスフォーマーのもたらした恩恵は既存のタスクの精度を向上したことに限らず、「自然言語処理とコンピュータビジョンの問題を同じ構造(トランスフォーマー)で扱うことを可能にした」ということもあります。これにより画像データと言語データを同時に扱う、ビジョンアンドランゲージの分野にいくつもの新たなタスクが生まれました。
その一例であるGrounding DINOは入力したテキストに対応する画像の領域はどこなのかを推定する、Open vocabulary object detectionを実現しています。

これを可能にしているのがクロスアテンション機構です。セルフアテンション機構は学習データのどこに注目すべきかを自ら学習するアルゴリズムでしたが、クロスアテンション機構は「あるデータに対するあるデータの関係がどこにあるのか」を学習します。Grounding DINOの場合、テキストに対する画像中の物体の関係がどこにあるのかを学習します。

よく「AIはブラックボックスで判断根拠がわからない」と言われますがトランスフォーマーに関してはアテンションを分析することである程度判断根拠を知ることができます。
Grounding DINOを使って少し実験をしてみましょう。以下の画像に対し、「sheep」というテキストを入力してみます。

結果はこのようになりました。

ちゃんと入力テキストに対応する領域を示していますね。手前の羊については89%、後ろの羊については数字が見切れていますが73%の信頼度で検出しています。
この判断の根拠となったクロスアテンションを可視化してみましょう。

奥の小さな羊は全体的にアテンションが強いのに対し、手前に大きく映る羊は意外にも中心ではなく頭部や足にアテンションが集中しています。
羊の映らない画像の周りの部分にもアテンションがあるのはこの写真の環境が牧場っぽい「羊のいそうな環境」であることを注視しているのかもしれません。
トランスフォーマーが2017年に発表されてからChatGPTが生まれるまで6年の期間がありました。私はただの修士の一学生なのでこの期間の研究の最前線がどうであったかを語ることはできないのですが、トランスフォーマーを理解し活用方法を考案するまでに6年を要したと考えられます。
一方ビジョントランスフォーマーは登場から2023年現在、約3年が経っています。コンピュータビジョンの研究者には3年後、ChatGPTのような大きな影響を持ったモデルがコンピュータビジョンの分野にも現れるのではないかという考えの研究者もいます。
以上、一介の情報科学オタクがゆるく楽しくトランスフォーマーについて語らせていただきました。内容には厳密性を欠く部分や、誤りを含む可能性があるため他人に話すときはご注意ください。
最後まで読んでいただきありがとうございました。それでは。
参考文献
[1] Vaswani et al., "Attention is All You Need," NeurIPS, 2017
[2] Bender et al., "On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?," ACM, 2021
[3] Dosovitskiy et al., "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale," ICLR, 2021
[4] Kataoka et al., "Vision Transformer入門," 技術評論社 Computer Vision Libraryシリーズ, 2022
[5] Kirillov et al., "Segment Anything," arXiv: 2304.02643, 2023
[6] Liu et al., "Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection," arXiv: 2303.05499, 2023