
5行で音声テキスト化|Google Colabで動かすWhisper

OpenAIから公開された音声テキスト化モデル「Whisper」を、Google Colabで動かします。シンプルなやり方であれば、ライブラリのインストールを含めても5行で実行できます。楽ですね!
とりあえず動かしたい方向けですので、より詳しい使い方を知りたい方は公式や他の記事をご参照くださいませ。
▍事前準備
Google Colabの環境準備を準備します。
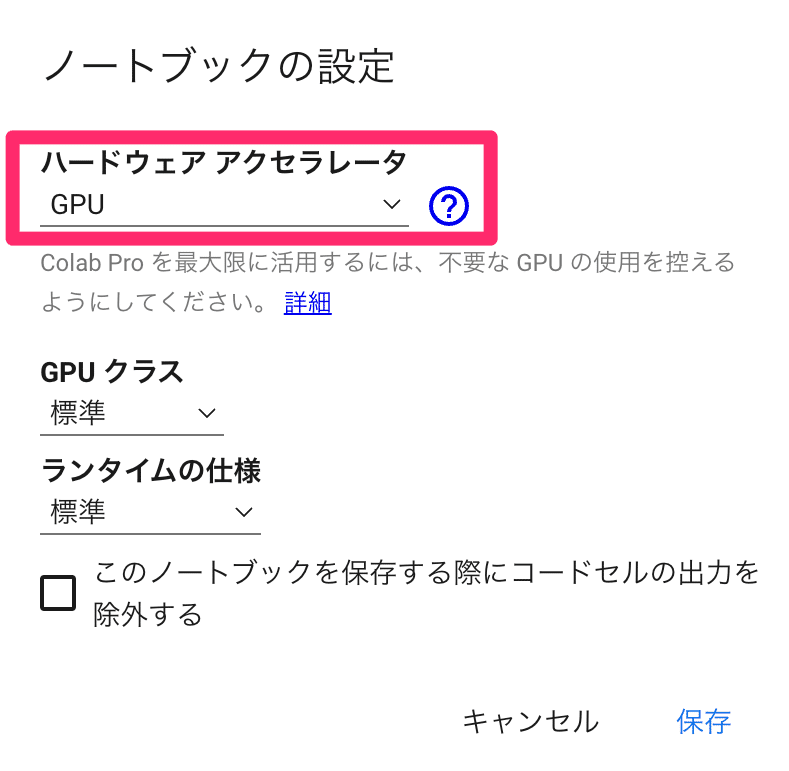
1️⃣ ランタイムのタイプをGPUに変更
[ランタイム] → [ランタイムのタイプを変更]から、[ハードウェアアクセラレータ]を「GPU」に変更
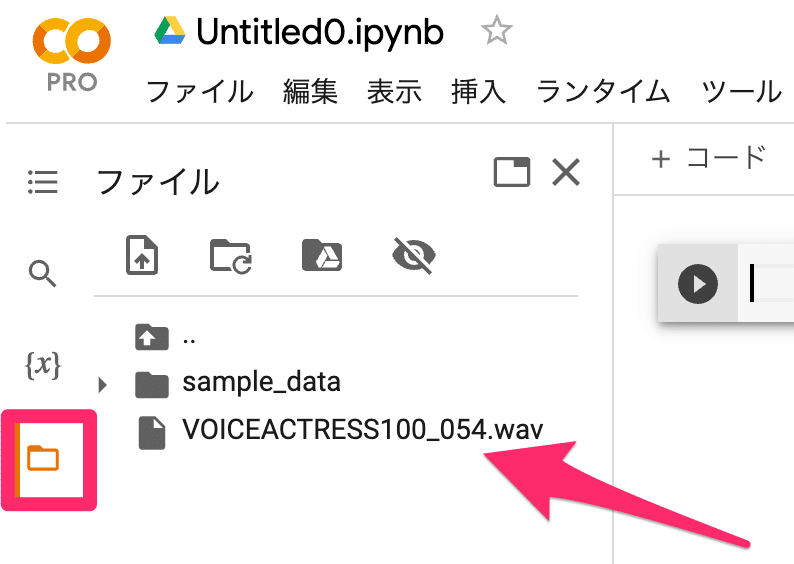
2️⃣ 音声ファイルをアップロード
画面左のフォルダアイコンを選択し、音声ファイルをドラッグ&ドロップでアップロード(この例では「VOICEACTRESS100_054.wav」)
▍コード
次の5行です。なお、「VOICEACTRESS100_054.wav」の部分はご自身でアップロードしたファイル名に置き換えてください。
# ライブラリをインストール
!pip install git+https://github.com/openai/whisper.git
# ライブラリをインポート
import whisper
# モデルをダウンロード
model = whisper.load_model("base")
# 対象ファイルに対してモデルを適用(音声テキスト化
result = model.transcribe("VOICEACTRESS100_054.wav") # アップロードしたファイル名に置き換えてください。
# 結果を出力
print(result["text"])結果はシンプルにテキストとして出力しています。

なお、ダウンロードするモデルを「base」以外に変えると精度や速度も変わります。詳しくは公式や、次の記事などをご参考ください。
▍おわりに
動かすだけであれば、とっても簡単ですね。5行はすごい。
この記事のほか、私たちのIT活用のメモが次のマガジンにあります。よろしければ覗いてみていってください。