
NDLサーチの考察(2) 「読み」に関する例外的事例

国立国会図書館サーチをFileMakerで取り込んで蔵書目録にするカスタムアプリ製作の顛末、なんとなくダラダラ続いているこの連載ですが、この調子で続けていこうと思いますので引き続きよろしくお願いいたします。
さて今回は、いくつかのタイトルを読み込んでいくうちに見つかった例外的事例です。
*2024年6月6日追記。別記事にしようとしていた部分を追記しました。「読み」の確実な取得のための改修部分とデータへのリンクも追加しています。
「読み」が収録されていない場合がある
今回見つかった例外事例はこちら。「DESIGN SCIENCE_01」ISBNは978-4-86757-023-4です。まずは作成したアプリにこのISBNを入力して結果を見てみます。

読み、著者名読みがどちらも「さっぽろしちゅうおうとしょかん」になってしまってます。NDLサーチの結果をみてみます。リクエストURLは次のとおり。
https://ndlsearch.ndl.go.jp/api/sru?operation=searchRetrieve&recordSchema=dcndl&query=isbn=9784867570234&maximumRecords=1
結果はこちらです。

「読み」の欄に格納されている文字列は後半の所蔵館に関する情報にあることがわかります。そして、書籍そのものの情報に関しては、タイトルが英文のみなので読みにあたるものが収録されていないことがわかります。
transcription タグは共通で使われる
なぜこのようなことが起きるかといえば、取り出す部分を<dcndl:transcription>タグで判別しているからです。各項目を読み込むスクリプトの中から、「読み」にあたる部分を変数として取り出すステップを見てみます。
$transcription=
Middle ( 新規入力用::検索結果 ; Position (新規入力用::検索結果 ; "<dcndl:transcription>" ; 1 ; 1 ) + 27 ; Position ( 新規入力用::検索結果 ; "</dcndl:transcription>" ; 1 ; 1 ) -Position ( 新規入力用::検索結果 ; "<dcndl:transcription>" ; 1 ; 1 ) - 27 )
このタグ自体は書名、著者、発行元、所蔵館などあらゆる属性について、読みを収録するのに使われます。記述規則上、タイトルが最初になるのでほとんどの場合、このタグが最初に現れる部分がタイトルの読みであると見做してますが、これが原因でタイトル部分に読みが格納されていない場合は、その後最初に現れる<dcndl:transcription>タグで囲われている部分をピックアップしてしまうのです。
読み込んだXMLをスリムにする
今回の例の場合、タイトルに関するブロックに<dcndl:transcription>タグによる記述が無く、同じタグを使用した記述が後ろにあるために発生しています。後方にある所蔵館に関する記述はここでは必要ないので、XMLを読み込んだ直後の段階でこの不要な部分を削除してしまいます。
<dcndl:transcription>タグ自体は著者名など他の項目の読みを収録するのにも使われているので、この方法で完璧とはいえませんが、データ量が少なくなるので後の処理が高速になるかもしれません。
書籍情報は<BibResource>タグで収録されている
蔵書アプリ(8)の記事で書きましたが、検索結果のXML自体は大きく3段構成になっていて、2段目の<dcndl:BibResource>に書籍に関する情報が収録されています。
XMLを読み込んだ「検索結果」フィールドからこの部分をmiddle関数で取り出してみます。わかりやすいように、別のテキストフィールドを作り、取り出したデータを一旦表示してみます。
Middle ( 検索結果 ; Position ( 検索結果 ; "dcndl:BibResource" ; 1 ; 1 ) ; Position ( 検索結果 ; "</dcndl:BibResource>" ; 1 ; 1 ) - Position ( 検索結果 ; "dcndl:BibResource" ; 1 ; 1 ) )
*注:計算式中では「<」「>」はそれぞれ「<」「>」と記述する。

左が読み込んだそのままのXML全体を格納した「検索結果」フィールド、右がその中から<dcndl:BibResource>タグに囲まれた部分を取り出したテキストです。行数にして1/5くらいになっています。この程度のテキスト量でしたら、デバッグ用にアプリの中に保持しても良いかもしれません。
フィールドの書き換えは一つのフィールドで完結できる
上記の例では、取り出したテキストを別のフィールドに表示しましたが、このために別のフィールドを用意しなくても完結できます。自動入力するスクリプトに「計算結果を挿入」ステップを追加します。ターゲットは「検索結果」フィールドで、上記の「検索結果」フィールドから<dcndl:BibResource>タグ部分を取り出す計算式を指定します。無限ループのようでもありますが、これで大丈夫です。

「検索結果」フィールド自体を書き換えたので、その後にある各項目を入力するステップは特に改変しなくても、これまでと同じように処理されます。

「よみ」フィールドが空欄になりました。一応は完成です。
「ふりがな」フィールドによる(半)自動修正
もうひとつ簡単な方法として、「読み」のフィールドをふりがな設定してしまう方法があります。各フィールドの設定を行うデータベースの管理画面で、フィールドのオプション画面で、ふりがなを入力するフィールドを設定することができます。
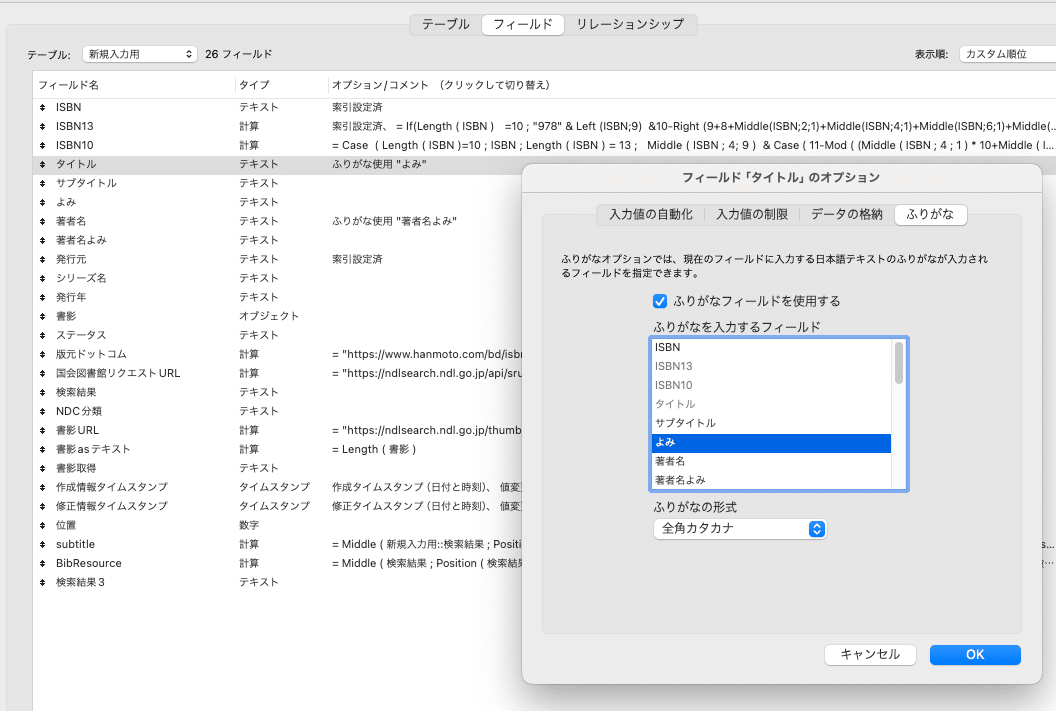
これを設定することで、該当するフィールド(この例ではタイトル)に入力・修正があった場合にふりがなを入力するフィールド(この例ではよみ)に自動で置き換えられます。今回のように、英文のみのタイトルは全角英数で格納されます。
ですので、バーコード読み込みの後の画面でタイトルを編集すると、その内容に合わせて「よみ」フィールドに入力されます。(スクリプトステップによる自動入力では機能しないようです)編集といっても、スペースを1個追加して元に戻すだけでも構いません。しかしこの方法だと、ソフトウェアに委ねるので正確かどうかにやや懸念が残ります。特に著者名の読み、人名については機械の限界を超えてくるものが多々あるでしょう。もっとも、国立国会図書館の目録に収録されている「よみ」を読み込んでいるので、それを使わない理由はありません。
これで完全とはいえない

この記事が気に入ったらチップで応援してみませんか?