
国立国会図書館の書影APIでどれだけの書影が取得できるか試してみる。

前回、国立国会図書館サーチの仕様が変更されたこと、その内容について少しだけ触れました。そこで、思い立ったので書影APIでどの程度取得できるか試してみました。2022年に試してみたのですが、その時は楽天booksや版元ドットコムの方が多くのタイトルを取得でき、あまりメリットを感じませんでした。
この時に取得できたのが92/380タイトル、新旧あるいはジャンルごとに得意不得意はあるかと思いますが、版元ドットコムが294タイトル、楽天booksが251タイトル取得できたことに比べると、ちょっと頼りない感じでした。
今回は、データベースを改修するついでに、同じ要領でもう一度トライして、現行のAPIでどれだけの書影を取得できるか試してみます。
前回から約2年経っていて、手元の読書記録にある本のタイトル数は440タイトルと、60ほど増えています。そのことも加味して比較してみます。
下準備(1) ISBNを13桁で揃える。
いま手元にある蔵書リストには440タイトルあり、そのISBNが、10桁と13桁が混在した状態で、(ISBN)フィールドに格納されているデータベースがあります。これをスタート地点にします。
まずは混在してるISBNを13桁に統一して、(ISBN13)フィールドに格納します。
ステップは次のようにします。
1・ISBNフィールドに入力されてる数値の長さを取得する
2a・10桁の場合は一旦別フィールド(ISBN10)に格納する
2b・13桁の場合はそのまま(ISBN13)に格納する
3・(ISBN10)に格納されたコードを13桁に変換して(ISBN13)に格納する
これを、filemaker関数にするとこうなります。
ISBN10 = If ( Length ( ISBN )= 10 ; ISBN ; "")
ISBN13 = If( Length ( ISBN )= 13 ; ISBN ; [10桁を13桁に変換した計算結果])
*ここでは、(ISBN)フィールドに入力されている値が、10桁もしくは13桁のISBNに限定され、雑誌コードなど他のコードは入ってないことを前提とします。
10桁を13桁にする計算式は以前に書いてますので、詳しくはそちらをご覧ください。
下準備(2) 画像を格納するフィールドを用意する。
次に、実際に取得した画像を格納するオブジェクトフィールドを用意します。
適当なサイズの四角形を配置したら、取得する画像のURLを格納するテキストフィールドを用意します。URL自体は演算子でテキストを繋げればOKです。
書影URL= "https://ndlsearch.ndl.go.jp/thumbnail/" & ISBN13 & ".jpg"
これで準備は完了です。
画像を取得して格納していく
次に実際に画像を流し込む作業をしていきます。
1・「URLから挿入」ステップを使用して画像を格納する
2・次のレコードに進む
この2ステップを繰り返すスクリプトで処理します。

このスクリプトは何度も使用するものではないので、特にボタンをレイアウトに入れたりせず、スクリプトワークスペースの再生ボタンで実行すれば良いでしょう。実行する際、アクティブなレコードから前のレコードは処理されないので、最初のレコードが表示されている状態で始めるようにします。
全ての画像があるわけではない
そうして画像を取得してみました。かなり多くの画像が得られましたが、取得できたものとそうでないものが入り乱れてる状態です。取得できなかったものはアイコンが表示されている状態になります。
レコード総数が440なので、画像が取得できたもの、できなかったものを一つずつ確認しても良いですが、ひと工夫します。
XMLテキストから属性を拾うために使用していたLength関数の説明には、こうあります。
目的
フィールド内の文字数を返します。これにはスペース、数字、特殊文字もすべて含まれます。
構文
Length ( テキスト )
引数
テキスト - 任意のテキスト、数字、日付、時刻、タイムスタンプ、またはオブジェクトのフィールド、または任意のテキスト式または数値式
戻り値のデータタイプ
数字
起点
FileMaker Pro 6.0 以前のバージョン
説明
オブジェクトフィールドについては、Length は元のファイルのサイズをバイト数で返します。
書影バイト数を格納するフィールドを作り、Length関数で取得した書影の画像データのバイト数を取得し、アイコンと画像を振り分けます。ここではマージフィールドを使っています。
書影バイト数 = Length(書影)
取得できた画像のバイト数はものは2000バイト〜18000バイト、取得できなかったものは298バイトもしくは310バイトでした。
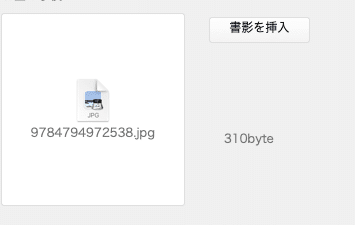

バイト数を数値データで格納できましたので、この値をもとにソートや検索ができますので、仕分けが簡単にできます。この場合、少しマージンを見て500バイト以下は画像が無いものとして処理して良さそうです。先のスクリプトに1行、If関数を使って500バイト以下の場合は画像を削除するスクリプトステップを入れて自動化しても良いです。
結果、手元の440タイトルのうち321タイトルの書影が取得できました。2年前にやってみた時と比べると、かなり良くなっています。
版元ドットコム・楽天booksと比較する
同じ要領で、版元ドットコムと楽天booksで試してみました。
細かいことは省略しますが、版元ドットコムでは358タイトル、楽天ブックスでは286タイトルの書影を取得できました。
楽天ブックスが前回比で見てもあまり伸びてないですが、楽天ブックスのwebサイトで検索してみるとちゃんとヒットするので何か傾向があるのかもしれません。ただ、楽天ブックスAPIは、リクエストが集中すると途中で制限がかかる仕様になっていること、一旦検索結果のxmlを出し、その中から画像URLを抜き出すステップがあるので、1件ずつ追加していく際に使うのには使えますが、今回のようにまとまった量を自動処理する使い方にはあまり向いてないということはわかりました。
版元ドットコムは数が多く、画像自体もやや大きいですが、取得できなかった場合の画像がアイコンではなくグレーのベタ塗り画像になるのでバイト数が画像に近づきます。画像取得の可否の閾値がはっきりしないという、些細な気になる点はあります。
これまで取り上げた3つのAPIでどれだけ取得できるかを検討しました。
まず、440タイトルのうち、どれでも取得できなかったのは30タイトルありました。数点ある自費出版や小出版のものはここに含まれますが、それを除けば国会図書館のデータベースにほぼ全てのタイトルが載っています。
それを除いた410タイトルのうち、
国立国会図書館のみで画像取得できたもの・・・ 12タイトル
版元ドットコムのみで取得できたもの・・・ 21タイトル
楽天ブックスのみで取得できたもの・・・ 20タイトル
でありました。
母集団が個人の蔵書と図書館で借りたものなので、偏りはありますが今回の場合、単一のAPIを使用するのであれば版元ドットコムが最も多く、358タイトルの書影を取得でき、2つ使うことができるのであれば、版元ドットコム+楽天ブックスだと398タイトルの書影を取得できることになります。
結局何を使うのか良いのか
しかしながら、使い勝手を加味すると書影に関しては
1・国立国会図書館で取得
2・版元ドットコムで補完
が基本で、それでも取得できないものは楽天ブックスですが、そこまで執着して取得するのでしたら、普通にwebで画像検索した方が良いような気がします。
あまり出番がないような楽天ブックスですが、タイトルや出版社名など他の属性とともにXMLの中に画像URLを取得できる、という仕様なので、目的によっては基本データをすべて楽天ブックスで取得して、書影を版元ドットコムで補完するのも良さそうです。
今回はここまで。いろいろやったのでそろそろ、iPhoneで動く蔵書管理のことに戻ろうと思います。
以下の有料部分に今回の検証に使用したFileMakerファイルを置いておきます。

この記事が気に入ったらサポートをしてみませんか?