
LangChainの新機能Contextual Compression Retrieverを試す

Q&Aチャットボットのようなシステムを作成するとき、ユーザーの問い合わせに関連した情報をプロンプトに埋め込んで精度の高い回答を返す、といった仕組みはもはや一般的だと思います。
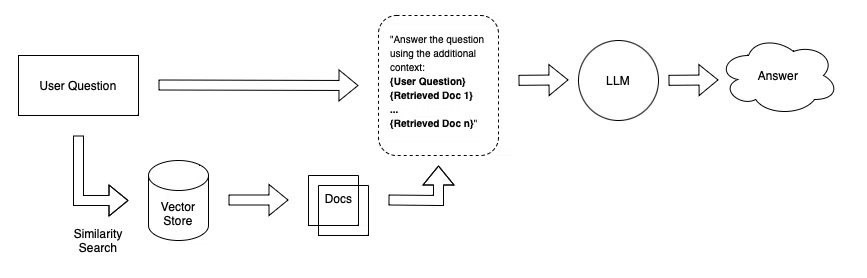
その上で、関連情報を取り出す仕組みとしてベクトルDBの利用が一般的になってきていますが、抽出した文章が必ずしも質問に対して適切な情報源になっているとは限らない可能性はあります。類似度から算出して似ていると評価されていても、文脈が違うケースもあったりするのではないでしょうか。
先日(4/21)追加されたContextual Compression Retrieverはまさにこの問題を解決するためのもので、ベクトルDBなどから抽出した情報の評価を行い、更にLLMsを利用して余計な情報を圧縮することで情報量の改善も行うことができる仕組みです。

コード例を試す
そういうわけで、早速下記のページで紹介されているコード例を試してみました。
データソースとしてWikipediaのキングダム解説ページを利用しました。
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.document_loaders import TextLoader
from langchain.vectorstores import FAISS
def pretty_print_docs(docs):
print(f"\n{'-' * 10}\n".join([f"Document {i+1}:\n\n" + d.page_content for i, d in enumerate(docs)]))
documents = TextLoader('kingdom.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
retriever = FAISS.from_documents(texts, OpenAIEmbeddings()).as_retriever()
docs = retriever.get_relevant_documents("信が目指しているものは何ですか?")
pretty_print_docs(docs)まずベクトルDBのFAISSにデータソースから1000文字ずつ分割した文字列をストアし、単純な類似度検索でドキュメントを抽出してみます。

次にContextualCompressionRetrieverを利用して、抽出した文章をクエリの意図に最適となるよう圧縮します。
from langchain.chat_models import ChatOpenAI
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
llm = ChatOpenAI(temperature=0)
compressor = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(base_compressor=compressor, base_retriever=retriever)
compressed_docs = compression_retriever.get_relevant_documents("信が目指しているものは何ですか?")
pretty_print_docs(compressed_docs)Document 1:
信が目指しているものは「天下の大将軍」。
----------
Document 2:
「中華統一」を目指す後の始皇帝・第31代秦王・嬴政と、その元で「天下の大将軍」を目指す主人公・信の活躍を中心に描く。
----------
Document 3:
信は目指しているものは何かについての情報は含まれていないので、NO_OUTPUTとなります。
Document 3の結果から、FAISS DBから抽出したデータに対してLLMsによる情報圧縮をかけていることがわかります。
base_compressorにはLLMChainExtractorの他にも、以下のようにフィルタオプションを取ることもできます。
LLMChainFilter
LLMsを利用して類似している文章で絞り込む。LLMsを利用するため、OpenAIのAPIを利用している場合は処理した分だけ費用が発生する。
EmbeddingsFilter
検索対象の文章とクエリの埋め込みベクトル値を求め、埋め込まれたクエリと類似していない文章を除外する。単体で利用するのではなく、DocumentCompressorPipelineで繋げて使うためのもの。
さらにDocumentCompressorPipelineを利用することで、「ドキュメントを小さな塊に分割→冗長なドキュメントを削除→クエリとの類似性に基づいてフィルタリング」といった処理を連続で行わせることができます。
from langchain.document_transformers import EmbeddingsRedundantFilter
from langchain.retrievers.document_compressors import DocumentCompressorPipeline
from langchain.text_splitter import CharacterTextSplitter
splitter = CharacterTextSplitter(chunk_size=300, chunk_overlap=0, separator="\n")
redundant_filter = EmbeddingsRedundantFilter(embeddings=embeddings)
relevant_filter = EmbeddingsFilter(embeddings=embeddings, similarity_threshold=0.76)
# 各フィルタをDocumentCompressorPipelineで繋ぐ
pipeline_compressor = DocumentCompressorPipeline(
transformers=[splitter, redundant_filter, relevant_filter]
)
compression_retriever = ContextualCompressionRetriever(
base_compressor=pipeline_compressor,
base_retriever=retriever
)
compressed_docs = compression_retriever.get_relevant_documents("信が目指しているものは何ですか")
pretty_print_docs(compressed_docs)Document 1:
信→李信(しん→りしん)
声 - 森田成一 / 演 - 山崎賢人
主人公。戦争孤児で下僕の出ながらも漂と共に「天下の大将軍」を目指す。漂の死を経て政と出会い、王都奪還に尽力。その後初陣での活躍で飛信隊が結成。隊を率いて数々の戦で武功を重ね、大将軍への道を駆け上がる。
漂(ひょう)
声 - 福山潤 / 演 - 吉沢亮
信の親友であり、信と共に「天下の大将軍」を目指し修業を重ねる。そんな中政の影武者という大任をこなすも深手を負う。死の間際、信に二人の夢を託し政と引き合わせる。
嬴政(えいせい)
声 - 福山潤 / 演 - 吉沢亮
----------
Document 2:
用語
部隊・称号
飛信隊(ひしんたい)
初陣での戦果で信が百人将となった時に発足した特殊部隊で、発足初戦の馬陽戦において王騎から「飛信隊」の名を授かる。
----------
Document 3:
だが、魏の装甲戦車隊の突撃により秦軍歩兵は甚大な被害を出す中、信達は孤軍奮闘する。それを知った麃公は全騎馬隊を第4軍の元に派遣、千人将・縛虎申は魏軍副将・宮元の布陣する丘を目指し突撃する。縛虎申は丘を登りきり宮元と刺し違え、秦軍は丘を奪取する。秦軍が丘への布陣を急ぐ中、突如王騎が現れた。そして、信は王騎に武将とは何かを教わる。
所感
LLMChainExtractorを使った場合に、一番理想的な結果が得られましたが、全ての文章にLLMsを適用するため、速度と費用の問題があります。
一方でEmbeddingsFilterなどを組み合わせたパイプラインを利用すれば費用の問題は軽減できますが、期待するほどは情報量を圧縮できないような気がします。
プロンプトに埋め込むコンテキストから冗長な情報を除去/圧縮するというアイデアそのものは理に適っているため、これをいかにLLMsに頼り切らずに実装するか、というところが腕の見せ所になっていきそうです。
現場からは以上です。