
HADを使ってみた:1.要約統計量

HADという主に心理統計を得意分野とするフリーソフトがある。関西学院大学の清水先生が開発されたものである。私自身は放送大学(心理と教育)の卒業研究をするためにRをやり始め,ヨレヨレになりながらも,なんとかRで(要所要所でExcelの助けを借りながらだが)分析をやってきたので,このままRを使っていればいいのだけれど,なんと清水先生が放送大学の客員教員になられるので(拍手!),それを(勝手に)記念して(?),HADについて何回か書いてみようと思う。清水先生が講師をつとめる「心理学統計法」は来春から開講の予定(たぶん)である。
HADって何さ
詳しくはこちらを。
年末から新年にかけて,どうせ暇だったこともあって,清水先生のブログで「HAD」を検索して,ヒットした記事のすべてに目を通した。そこでわかったのは,もともとこのプログラムが,マルチレベルなんちゃらという分析のためのマクロがもとになっていることで,その分析は,今のところ大学で主に使用されているSPSSという(相当高い!らしい)統計専門ソフトではうまくできないようなのだ。そこで,それをExcelマクロでやってしまおうというところが,その出発点だったみたい。なるほど。
といっても,そのマルチレベルなんちゃらは,私にはとてもとても,とーっても難しいので(やったことないからイメージで書いている),基礎的な部分だけでも明るくなっておこう,と思うのであります。
サンプルデータの準備
さて,ダウンロードやら,マクロの警告がどうのこうのいったややこしい部分はさておいて,さっそく要約統計量の分析をしてみよう。今回使用するデータは,サンプルデータとして提供されている「iris」である。R使いにはおなじみの,あれです。
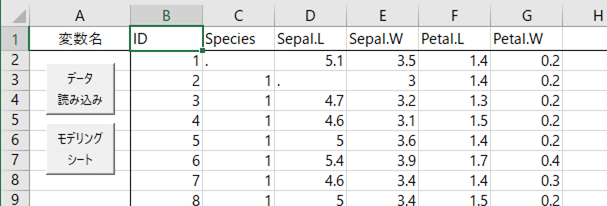
こんな感じにデータを入れて,2か所だけ,わざわざ欠損値にしてみた。これは,欠損値があったときに統計量がどのようになるかを見るため。HADでは欠損値を「.」(半角ピリオド)で入力することになっている(変更したいときは「HADの設定⇒分析設定⇒欠損値設定」)。
あと独特なのがB列の「ID」で,これはデータの識別用に必要な変数らしい。一意であればどんな値でもいいので,とくにこだわりがないなら,変数名を「ID」として,連続数(1,2,...)を入れておくのが簡単。ちなみにサンプルデータには上記のようにすでに連続数が入力されている。
この状態で【データ読み込み】ボタンをクリックして,次へ。
モデリングシート
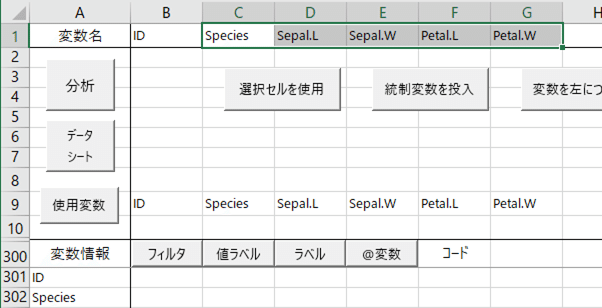
モデリングシートで,使用変数を設定する。データシートの中のどの変数を対象に分析を行うかをあらかじめ9行目に設定するわけですね。今回はとりあえず5つの変数をみんな使うので,C1からG1を選択して,【選択セルを使用】をクリックすると下の図みたいになる。
で,【分析】ボタンをクリックして下の図のようなメニューを出して,「要約統計量」にチェックを入れて【OK】すればよい。かんたん。
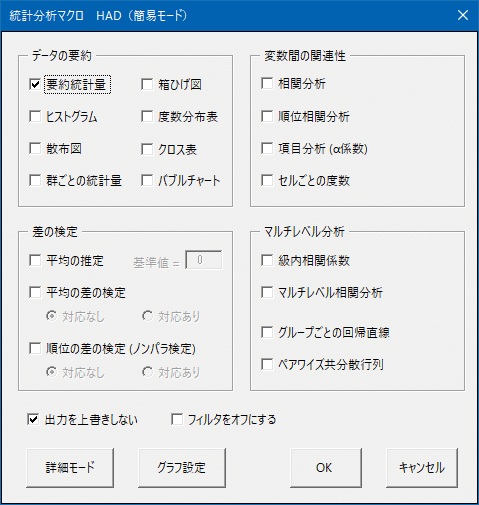
下の方の「出力を上書きしない」というオプションは,分析結果がなくならないようにするための設定。
HADでは,たとえば要約統計量は「Summary」という名前のシートが自動的に作成されてそこに結果が表示されるのだけれど,使用変数やデータそのものを入れ替えて,また「要約統計量」を実行すると,さっき出力された「Summary」がきれいに上書きされてしまって,ときどき悲しい。なので,上書きしない設定にしておいて,これ大事な結果,と思ったら早めにシート名を変えるなり,別のブックに保存するなりするのが賢い。このあたりはおいおいと。
要約統計量
結果はこんな感じ。おそらく多くの統計ソフトでも同じだと思いますが,分散は不偏分散(分母が N-1 になっているやつ)で,標準偏差はその平方根。なんで N-1 なの? というやっかいな話はここではしない。
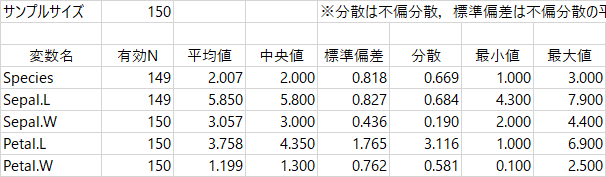
上の2つの変数だけ,有効Nが149になっているのは,言うまでもなく欠損値のせい。サンプルサイズが150なので,どちらの変数も1件だけ欠損値があるのがわかりますね。ほかの3つの変数は欠損なし。だけどこれを見て,「ああ,欠損値が1行あるのね」というのは早合点。さっき見たように,欠損値をふくむ行は2行あった。「欠損値は許せん! 欠損値のないデータだけで分析したいのだ!」という場合は,【分析】フォームの左下【詳細モード】をクリックすると表示が変わる。
ここで,「欠損値処理方法」を「リストワイズ削除」にしてから「OK」すると,次のような統計量が出力される。
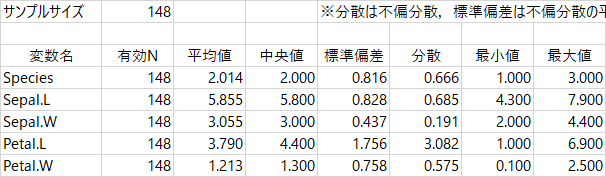
サンプルサイズが148になり,すべての変数の有効Nも148になった。欠損値をふくむ2行が,分析から完全に除外されたのがわかる。
とはいっても,こんなふうに欠損値をふくむデータを完全に除外してしまうことは稀だろう。せっかく集めたデータは有効活用したい。
HAD2Rはちょっと残念
ところで,HADには「HAD2R」という不思議な機能がある。清水先生のブログによると「R初心者の最初の道しるべ的な機能」と説明されている。設定するには,データシートにある【HAD2R】ボタンをクリックして,設定をして,「HAD2Rをオンにする」にチェックを入れてOKすればよい。
この状態で,いつものように分析をすると,分析結果を表示する代わりに,たとえば次のようなRコードを返してくれる。
dat <- read.csv("C:/ .... /csvdata.csv")
subdat <- subset(dat, select = c(Species,Sepal.L,Sepal.W,Petal.L,Petal.W))
summary(subdat) さきほどのフォーム上で,「書き出し」をクリックすれば,今入力しているデータをCSVで書き出してくれるし,欠損値をR用に「NA」に変換してくれるし,読み込みコードではファイルをフルパスで指定してくれるという親切設計である。
なので,出力されたコードをRのコンソールに貼り付けて実行すれば,Rで分析ができてしまうというわけだ。すごい!
が。
それだけに残念なのは,たとえば上記のコードだけでは,HADの分析結果とあまりにも異なる結果しか返ってこないことだ。R使いの方はおわかりでしょうが,上のコードを実行するとこうなります。

Rの Summary 関数は,こんなふうに分位系の統計量と平均値を返すだけで,Nすら返してくれません。標準偏差も,分散もなし。ここで「なあんだ,Rって不便じゃん」と思われるのもしゃくではないですか? ぜひとも清水先生には,この機能を改善していただきたいと思っています。ちょっと提案を書いておきます。
提案1:「HAD2R」オプションを「分析」フォーム上につけてほしい。
「分析」フォームに「Rコードを出力する」オプションをつけて,それをチェックすると,分析結果の末尾にRコードを付け足してくれる,という動作をしてほしい。今の設定だと,HADの分析結果とRコードを別々に出力する必要があるのでわかりにくい。というか,ほんとに両者が同じ設定の分析なのか不安になってしまう,プラス,上書き設定していないとHADの結果が消えてしまって,悲しい。
その上で,HAD2R設定は今のままのフォームを残しておけば,コードの生成やデータの書き出しはそこで対応できる。
提案2:やっぱりHADの結果と同じような結果を出すコードにしてほしい。
ということで,ちょっとやってみました。いや,やってみると確かに面倒なのです。どんなデータにも対応できるコードを書かないといけない,ということもあり,また,なるべく基本的なライブラリだけで書いたほうがいいだろうと思うので。
とりあえず,要約統計量のコードはこんな感じ。
subdat <- subset(dat, select = c(Species,Sepal.L,Sepal.W,Petal.L,Petal.W))
library(psych)
d0 <- describe(subdat)
d0$v <- d0$sd ^ 2
d1 <- d0[, c("n", "mean", "median", "sd", "v", "min", "max")]
colnames(d1) <- c("有効N","平均値","中央値","標準偏差","分散","最小値","最大値")
print(d1, dig=3)ほら長い。これで出力すると,
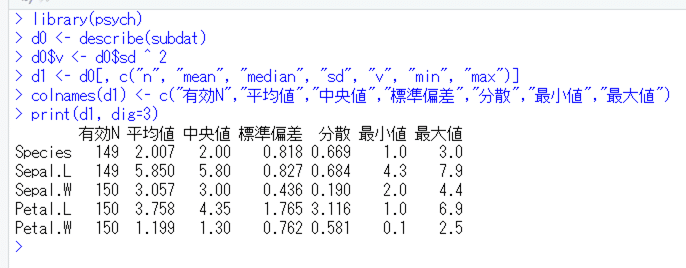
こんな感じ。HADに近づきましたね。表示される数値も並び順も,HADのものと完全に一致します。余計なオブジェクトが残ってしまうのが気になるので,print行の前に「rm(d0)」とか書いておいてもいいかもしれません。表示桁数とか,日本語の使用とか,気にしなければもっと短くなるのですけどね。
しかしまあ,清水先生が,結果がRやSPSSと一致することを確かめています,とか書いておられるのを見ると,ずいぶんムダなことをしている気がしてきます。いいんです。好きでやってるんですから。
ええっと,もう少し要約統計量については書いておきたいことがあるんですが,長くなったので次の機会に。