
HADを使ってみた:2.要約統計量(続き)

HAD(清水, 2016)で要約統計量を出す,という分析の続きについて,ちょっと書いてみたい。
群ごとの統計量
要約統計量を,群ごとに見たい,という場面はけっこうある。例えば,全体の平均値わかったけど,男女で違わないの? とかいう場合である。もちろんt検定してしまえば両群の平均値が出力されるのだけれど,性別の標準偏差や中央値などまとめて表示してくれるわけじゃない。それに,検定してしまうと,どうしても有意確率や効果量に目がいってしまって,「その差がいったいどのくらい意味があるの?」という本質的な部分が後回しになったりする。
つまり「検定で「有意差あり」って言ってるけど,それはNが多かったからでしょ。こんな小さな差に意味あるの?」というような意義深いつっこみを入れるためには,群ごとの統計量を見ることが重要なのである。というわけで,HADに用意されている「群ごとの統計量」という分析をするといい。
書式は,統計量がほしい変数群を好きなだけ並べ,最後に群分け変数をおく。この「群分け変数」は,性別とか,年齢段階とか,実験群と対照群を表す記号とか,そういうのを記録した変数ですね。「群ごとの統計量」分析ではこれを1つしか指定できないので(つまり2要因とかできないので),「性別×年齢層」で比較したいときは,男性20代,女性20代,男性30代,…のようなカテゴリを表す合成変数を作るといい。こういう細かい作業は,HADでは限界があるので,Excelの機能を使って自分でやる。
前回も使用したサンプルデータ iris でやってみよう。このデータで群分け変数になるのは Species(種)ですね。ちなみに,Sepal は(花の)萼片(がくへん)のこと,Petal は花弁のこと。iris の Species ? って何のことやらわからないときは,次のページで見られます。画像付き。種の名前も英語で記されているので,のちほど,分析に使いましょう。
分析してみよう
使用変数の設定をします。こんな感じ。

今回は順番が大事なので,たとえば,
D1~G1ドラッグ⇒Ctrl押しながらC1クリック
みたいに選択してから「選択セルを使用」をクリックすると,ちゃんと選択した順番に「使用変数」に並んでくれる。あとは,Ctrl+CとCtrl+Vで順番に並べてもいいし,【使用変数】ボタンからGUIで設定してもいい。直接気ボードから打ち込んでもOKだけど,大文字と小文字を間違えるだけでも「変数が見つからない」といって止まるので,あまりお勧めしない。あとは
【分析】⇒「群ごとの統計量」⇒OK
で結果が出ます。かんたん。こんな感じ。「人数」は「有効N」のこと。

この表の下に,群ごとの箱ひげ図が表示されます。右側にもう1つ表が出てくるのは,箱ひげ図を描画するのに必要な数値なので消してはいけない。箱ひげ図についてはいろいろとあるんだけど,分析メニューに「箱ひげ図」というのがあるんで,そこで遊びましょう。
日本語で出したい
ところで,Species とか Petal とか,やはり日本語で表を作りたい,と思いますね。もっとも簡単にするには,出力された表を書き直してやれば終わりですね。でも,分析って何度もやり直すこともあるので,最初から日本語が出てきた方が便利。論文に貼り付けてから「あっ」とか思いたくない。
まず,変数名。「ラベル」と表示されている列に,それぞれの変数名を日本語で入力する。「ラベル」というボタンをクリックしてGUIを使ってもOK。

次にカテゴリの名前。Species の 1 は「setosa」という種,2は「varsicolor」,3は「versinica」ですよ,というのを,上のように数字と文字列を等号で結び,カンマで区切って入力する。ここで大事なのは,数字,等号,カンマをいずれも半角で入力すること。これも,「値ラベル」というボタンをクリックするとGUIが使える。
最後に,【HADの設定】ボタンで出てくるフォームで,「ラベルで結果を出力」にチェックを入れます。これしないと,せっかく設定したラベルが無視されて悲しい。
その下の「出力のフォントをTimes New Romanにする」は,お好みで。というか,論文を出すときに,図表のフォントも「明朝+Times New Roman」で書いてね,という指示が担当教員からあるならば,最初から設定しておくのがよいでしょうね。見た目もかなり変わるので,見慣れておくのも大事。ついでに日本語フォントも「MS明朝」とかに変えてもいいかも。
結果はこうなります。

やってはいけない
その1:値ラベル設定の等号やカンマに全角文字が混入する。
実験してみました。「3=versinica」のように,この部分だけ等号(=)を全角にしてみました。HADさん,ごめんなさい。結果は?

統計量はあってます。種の表示が変だけど。でも悲惨なのは箱ひげ図で,

一部だけ抜き出していますが,明らかに変ですね。クリックすると,参照範囲がめちゃくちゃになっていました。気をつけましょう。
その2:群分け変数にうっかり連続変数を指定する。
要約統計量のときみたいに,「Petal.W」 が最後になったままやってみました。HADさんごめんなさい。苦しかったでしょう? しばらく沈黙なさいましたが,数十秒後,ものすごい表を返してくれました。

こんな感じで90行ほど。みなさまお気を付けください。
やっぱりHAD2R
さて,前回もちょっとこだわってしまったHAD2Rですが,今回もやってみました。「群ごとの統計量」でHADが返してくれるのは次のようなコードです。
dat <- read.csv(" ... /csvdata.csv")
tapply(dat$Sepal.L, dat$Species, summary)
tapply(dat$Sepal.W, dat$Species, summary)
tapply(dat$Petal.L, dat$Species, summary)
tapply(dat$Petal.W, dat$Species, summary)やはり Summary 関数なのですね。これを実行すると,こんな感じ。Summary 関数については繰り返しません。箱ひげ図がないのも残念ですね。

では,HADの出力に近づけるためにはどうすればいいかというと,
library(psych)
d0 <- describeBy(dat[,c("Sepal.L","Sepal.W","Petal.L","Petal.W")], dat$Species)
for (n in 1:length(d0)) {
cat(paste("Species: ", dimnames(d0)$group[n], "\n", sep=""))
print(d0[[n]][,c("mean","median","sd", "n")], dig=3)
cat("\n")
}
boxplot(dat$Sepal.L ~ dat$Species)
boxplot(dat$Sepal.W ~ dat$Species)
boxplot(dat$Petal.L ~ dat$Species)
boxplot(dat$Petal.W ~ dat$Species)やはり psych ライブラリの describeBy 関数を使うのが簡単なようです。途中,for 文の中でやっているのは,
1.どの群かをまず表示し(最初のcat文)
2.必要な変数だけを出力し(print文)
3.空白行を入れて見やすくする(cat文)
です。
後半の4行は箱ひげ図です。チルダ演算子(~)でつなげることで,群ごとの箱ひげ図がきれいにならんでくれます。
そういえば,Rを覚え始めて間もないころ,t検定も,分散分析も,回帰分析も,このチルダ演算子で書けることを知って,さらにこうしたプロット描画にも使えることを知って,「チルダ演算子万能!」とか思ったことを思い出しました。では,出力結果です。
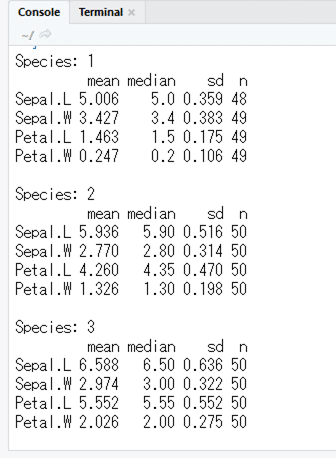

こんな感じ(プロットは当然ですが4枚出ます。ここには1枚だけ)。やっぱりHADも,ここで箱ひげ図のコード出してほしいなあ,とか思ったりしますね。「おお,チルダ使えるんだ」と思って感激してほしい。(しないか?)