
初心者向け:データ分析②

1. はじめに
こんにちは、大学院生のYukiです。
今回は、K-means法を用いたBig Data分析に関する手法についての記事を記載します。
前回からの引き続きの記事にはなりますが、既に基礎的な内容を理解している方はこちらから始めても大丈夫です。
本日はこちらの皆大好きポケモンのデータセットを使用して、手を動かしながら、データ解析の入門を行いましょう。
ポケモンのパラメータを吟味することで似たグループを特定し、最後に視覚化までできることが本日の目標です。
2. まずはデータの前処理をしよう
import pandas as pd
dataset = pd.read_csv('Pokemon.csv', index_col=1)
print("Pokeman dataset size:", dataset.shape)
print("Pokeman dataset head \n", dataset.head())
print("column name and data types: \n", dataset.dtypes)
もし実行ファイルと同じ階層にCSVを配置していたら、上記でひとまずコードの実行ができているはずです。
ポケモンの歴史は長いので、1000を超える種類のレコードが格納されているのが確認できましたか?
簡単に情報を確認すれば分かるとおり、こちらでのnumberという項目はインデックス番号を表す機能を所持していません。
pokemon = dataset.drop('number', axis=1, inplace=True)ですので、今回はnumberをドロップし、次の行(name)をインデックスとして取り扱います。
更に今回は前回使用したデータセットと違いタイプの中にobjectやboolが含まれています。一般的にデータ解析の際はint型以外はきちんと前処理をしないとエラーが発生します。
pokemon.drop(columns=['type1','type2','legendary','generation'])こちらはデータセットの中からint以外の形式の項目をドロップさせています。本日の目標に沿えばポケモンのタイプや伝説、世代等の値は無視できるので、このように対応しています。
3. K-means法を適応してみよう
それでは、実際のポケモンのデータセットにk-means法を使用してみましょう。
from sklearn.cluster import KMeans
km = KMeans(n_clusters=2)
km.fit(pokemon)こちらのK-meansアルゴリズムは、所持している数値的特徴を使用して、似たような特性を持つPokemonを2つのグループに分類します。
pokemon['label'] = km.predict(pokemon)
print("pokeman with cluster labels: \n", pokemon)
こちらではラベルは0または1の値で、各ポケモンがどのクラスターに属するかを示しているか確認することができます。km.predict()関数を使用して生成されたこれらのラベルは、新しい'label'列としてpokemonデータフレームに追加されていることが確認できます。
何かしらの規則と特徴で0と1に分類されてはいるようですが、一体何の規則に従っているかはっきりしませんね。
では以下のコードを入力し、実行してみてください
pokemon_mean = pokemon.groupby(['label']).agg('mean')
print(pokemon_mean)これはラベルごとにそれぞれのカラムの平均を算出したものです。
この結果を見るに、どうやら強い(数値が高い)ポケモングループと、弱いグループで別れているようです。
それでは各項目ごとの散布図をプロットしてみましょう。
import matplotlib.pyplot as plt
fig, axs = plt.subplots(11, 2, figsize=(20,80))
columns = list(pokemon_mean.columns)
j2, i2 = 0, 0
for i in range(len(columns)-1):
for j in range(i+1,len(columns)):
if j2 > 1:
j2 = 0
i2 += 1
axs[i2,j2].scatter(pokemon[columns[i]], pokemon[columns[j]], c=pokemon['label'])
axs[i2,j2].set_title('{} vs {}'.format(columns[i], columns[j]))
j2 += 1
plt.show() 
xとy軸に{} vs {}とさまざまな値を据えて、ラベル0と1のポケモンの分布を確認します。右上に行けば行くほど値が大きく、左下は小さいポケモンです。
綺麗に強いポケモンと弱いポケモンのクラスタが分かれているのが確認できました。
では上記の探索を元に、今度は適切なk個のクラスターにk-means法を適応させましょう。(好きに値をいじってみてください)
以下では3つに設定しています。
km = KMeans(n_clusters=3)
km.fit(pokemon[columns])
pokemon['label_c'] = km.predict(pokemon[columns])
pokemon_mean = pokemon.drop('label',axis=1).groupby(['label_c']).agg('mean')
print(pokemon_mean)
plt.scatter(pokemon['total'], pokemon['hp'], c=pokemon['label_c'])
plt.title('Total vs HP, n_cluster=3')
plt.show()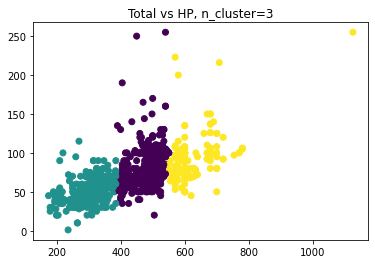
これにより更に細かく分類されているのが確認できたでしょうか?このポケモンの例で言えば、強い、弱いの間に中程度の強さのクラスタが誕生しています。
全体の個体のトータルの値は綺麗に三分割されており、縦軸のHPは右側のクラスタに行けば行くほど平均的に高い値を保持しているのが確認できます。
4. 階層クラスタリング
続いて階層クラスタリングを行ってみましょう。
数が多いと図示しても確認が難しくなるので、今回は初代のポケモンに数を絞りましょう。まずは以下のように下処理をしてください。第一世代のポケモンのみを対象にしています。
from scipy.cluster.hierarchy import linkage, dendrogram, cut_tree
from scipy.spatial.distance import pdist
gen1_pokemon = dataset[(dataset['number'] <= 151) & (dataset['generation'] == 1)]
gen1_pokemon.drop('number', axis=1, inplace=True)
gen1_pokemon.drop(columns=['type1','type2','legendary','generation'])ひとまず数を絞り、不要なカラムをドロップしました。私のデータだと大体180匹前後のポケモンがヒットしました。
続いてユークリット距離を計算し、完全連結法でクラスタ間の距離を計算します。
dist = pdist(gen1_pokemon, 'euclidean')
linkage_matrix = linkage(dist, method = 'complete')ユークリット距離が小さいほど、各ポケモンの特性が似ていることを表します。完全連結法は階層的クラスタリングにおいてクラスタ間の距離を決定するために使用されます。たとえばクラスタAとクラスタBにおいてそれぞれ抽出したデータポイント(1ポケモン)において、最も距離が遠いポケモンたちのペアをクラスタA-B間の距離とします。
それではこちらをプロットしてみましょう。
plt.figure(figsize=(15,7))
dendrogram(linkage_matrix)
plt.show()
緑、オレンジの2色は、2つの主要クラスタを示しています。縦軸は距離(非類似度)を表します。上に行くほど、クラスタ間の距離が大きくなります。横軸は個々のポケモンを表します。各葉(最下部の枝の先端)が1匹のポケモンに対応します。
上記の図ではオレンジ色のグループが強く、緑が弱いグループになっています。
更に階層クラスタリングにおける数値もターミナルで確認してみましょう。
labels = cut_tree(linkage_matrix, n_clusters=2)
pokemon['label'] = labels
print("describe cluster labeled 0: \n", pokemon[pokemon['label']==0].describe())
print("describe cluster labeled 1: \n", pokemon[pokemon['label']==1].describe())先ほど視覚的に強いポケモンが弱いポケモンの三分の一ほどしかありませんでしたが、こちらのコンソールで具体的な数値まで確認ができるはずです。
5. 最後に
今回はk-means法の使い方と階層クラスタリングの解説を行いました。
次回はもう少し応用的な演習を行い、決定木など分類についての学習をしていきたいと思います。
最後まで読んでいただき、ありがとうございました。
Yuki
この記事が気に入ったらサポートをしてみませんか?