
PySparkをTreasure Dataと使う

この記事はArm Treasure Data Advent Calendar 6日目の記事です。
データサイエンスを行う上でPythonはデファクトスタンダードとなっているプログラミング言語です。多くのデータサイエンティストはPythonを通して様々なライブラリ、データソース、フレームワークを利用して日々の仕事に取り組んでいます。そのようなニーズを満たすため分散処理基盤、SaaSの多くがPythonでアクセス可能な機能を提供しています。Pythonはデータサイエンティストが大規模な分散処理基盤を利用する上での共通言語の役割を果たすようになってきました。
PySparkもそのようなインタフェースのひとつで、ユーザはPythonを使ってSparkの分散処理リソースを利用することができます。PySpark自体はApache Sparkのコミュニティからリリースされているライブラリですが、今回はこれをさらに拡張してつくられたtd-pysparkというライブラリの使い方を紹介します。
td-pysparkとは
td-pysparkはTreasure Data(TD)をデータソースとしたPySparkの利用を可能にするライブラリです。ユーザはpipを使って簡単にインストールすることができます。
$ pip install td-pyspark注:このライブラリを使うには別途、td-sparkの機能を有効にしたTreasure Dataアカウントが必要です。詳しくはsupport@treasure-data.comにお問い合わせください。
このライブラリを使うと以下のようにPySparkのDataFrameとしてTreasure Dataのテーブルにアクセスすることができます。
df = td.table("sample_datasets.www_access").df()
df.show()DataFrameとして取り込まれたTreasure Dataのテーブルは通常のDataFrameと同じように利用することができるためシームレスに他のDataFrameをサポートしているライブラリを利用することができます。(e.g. MLlib)
どうやってTDにアクセスしているの
ではどのようにtd-pysparkはTDのテーブルにアクセスしているのでしょうか。TD内のデータは内部的にはPlazmaというストレージシステムによって管理されています。このストレージシステムは基本的にはTD内の他のサービス(例えばPresto)によってアクセスされることが想定されていましたが、インターネットからもアクセス可能なplazma-public-apiというサービスにProxyの役割を担わせることで、安全に外部からPlazmaのデータにアクセスすることを可能にしています。
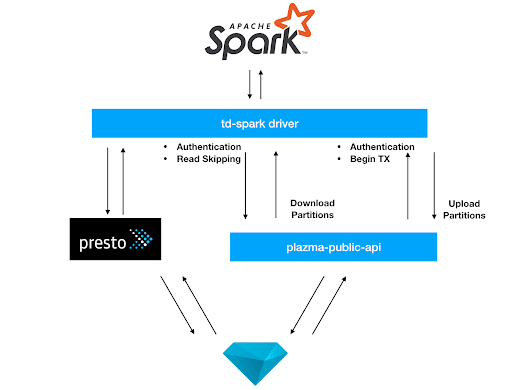
このAPIが認証、predicate pushdown、パーティションファイルのdownload/uploadなどの機能の提供することで外部のサービスも効率的にデータの読み書きをすることを可能としています。
td-pysparkパッケージは中に含まれるtd-sparkのJVM用のDriverを通してplazma-public-apiとのやり取りを行っています。そのため、このDriverを直接使えばScalaやJavaからPlazmaのデータにアクセスすることも可能です。
どうやってテーブルを取得するの
それでもtd-pysparkの使い方を具体的にみていきましょう。
まず以下のような設定をSparkに読み込ませる必要があります。spark.td.apikeyは認証に必要なAPI Key、spark.td.siteは利用しているサイトの名前です。現在TDは米国(us)、日本(jp)、EU(eu01)でサービスを提供しているので、このどれかを選択します。
spark.td.apikey (Your TD API KEY)
spark.td.site (Your site: us, jp, eu01)
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.sql.execution.arrow.enabled trueこれらの設定はpysparkスクリプトなどの--properties-fileオプションにファイルとして与えることもできますし、テストとしていろいろ試す場合には--confオプションに渡すのも便利かもしれません。
しかし、td-pypsarkパッケージをインストールした場合にはおそらく何らかのPythonプログラムからtd-pysparkを利用するはずですので下記のように使うのがいいでしょう。
import os
from td_pyspark import TDSparkContextBuilder
from pyspark.sql import SparkSession
builder = SparkSession \
.builder \
.appName("td-pyspark-app")
td = TDSparkContextBuilder(builder) \
.apikey("Your API Key") \
.site("us") \
.build()
df = td.table("sample_datasets.www_access").within("+2d/2014-10-04").df()
df.show()
td-pysparkに含まれるTDSparkContextBuilderというクラスを使ってTD用のDriverを含んだSparkSessionを作ります。このTDSparkContextBuilderに必要なapikeyなどの設定を渡すことで適切なSparkSessionを構成します。
ここに記載されているように。td.table("データベース名.テーブル名")でTDテーブルをDataFrameとして読むことができます。
withinを使うと指定された範囲でフィルタリングしたレコードのみを含んだDataFrameを作ります。ここで大事なことは、この条件はplazma-public-apiの方までpushdownされるため、そもそものDownloadを減らし帯域を節約することができます。一般的にこのwithinを常に指定しておくことが強く推奨されます。
ここで指定できる記法に関してはTD_INTERVALを参照ください。
どうやってテーブルを作成するの
td-pysparkから新たなテーブルをTD内に作成することができます。下記のようにPySparkのDataFrameをTD内に書き戻すことができます。
# Insert the records in the input DataFrame to the target table:
td.insert_into(df, "mydb.tbl1")
# Create or replace the target table with the content of the input DataFrame:
td.create_or_replace(df, "mydb.tbl2")このデータのアップロードはparitioningされたファイルごとにSparkのexecutorを使って並列に行われるため、効率よくTD内に書き戻すことができます。
またこの機能は以下の複数アカウント機能と共に使うとデータのマイグレーションを強力にサポートしてくれます。
# Read a table with key1
td1 = td.with_apikey("key1")
df = td1.table("sample_datasets.www_access").df()
# Returns a new TDSparkContext with the specified key
td2 = td.with_apikey("key2")
...
# Insert the records with key2
td2.insert_into(df, "mydb.tbl1")td.with_apikeyを使ってSparkSessionごとに異なるユーザを使い分けることが可能になるため、あるTDアカウントから別アカウントへ、あるリージョンから他のリージョンへとデータをtd-pysparkを使って移すことができます。
簡単に試すには
td-pysparkパッケージを使うと最も柔軟にTDとのインテグレーションをプログラムに組み込むことができますが、もっとお手軽に試したい場合にはどうしたらいいでしょう。
Treasure Dataは専用のDockerイメージを用意しています。
$ docker run -it -e TD_SPARK_CONF=td-spark.conf -v $(pwd):/opt/spark/work armtd/td-spark-pyspark:latest
Python 3.6.6 (default, Aug 24 2018, 05:04:18)
[GCC 6.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
19/06/13 19:33:46 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.4.3
/_/
Using Python version 3.6.6 (default, Aug 24 2018 05:04:18)
SparkSession available as 'spark'.
2019-06-13 19:33:49.449Z debug [spark] Loading com.treasuredata.spark package - (package.scala:23)
2019-06-13 19:33:49.486Z info [spark] td-spark version:1.2.0+31-d0f3a15e, revision:d0f3a15, build_time:2019-06-13T10:33:43.655-0700 - (package.scala:24)
2019-06-13 19:33:50.310Z info [TDServiceConfig] td-spark site: us - (TDServiceConfig.scala:36)
2019-06-13 19:33:51.877Z info [LifeCycleManager] [session:7ebc16af] Starting a new lifecycle ... - (LifeCycleManager.scala:187)
2019-06-13 19:33:51.880Z info [LifeCycleManager] [session:7ebc16af] ======== STARTED ======== - (LifeCycleManager.scala:191)
>>>このイメージを利用することで、SparkやPythonの環境がなくてもすぐにPythonからTDにアクセスすることができます。ぜひ利用してみてください。
より詳しく知りたい場合にはぜひ下記をご参照ください。
参照
いいなと思ったら応援しよう!
