
2023年4月Twitterアルゴリズムついに公開(日本語翻訳版)

Twitter社がアルゴリズムを公開したということが話題になっていますね。コードはさすがに無理。だけど気になる。ブログならなんとか理解できそう。ということでTwitter Engineering チームが公開しているブログを日本語にしてみました。これで概要は理解できると思います。少しでも皆さんの参考になれば幸いです。
注意
本記事は2023年3月31日にTwitter ブログで公開された記事を機械翻訳したものであり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
原文はこちら
https://blog.twitter.com/engineering/en_us/topics/open-source/2023/twitter-recommendation-algorithm
Twitterの推奨アルゴリズム(Twitter's Recommendation Algorithm)
Twitterは、今世界で起きていることの中から最高のものをお届けすることを目的としています。そのためには、毎日投稿される約5億件のツイートの中から、最終的にあなたの端末の「おすすめ(For You)」タイムラインに表示されるトップツイートを抽出する推奨アルゴリズムが必要です。このブログでは、このアルゴリズムがどのようにあなたのタイムラインに表示されるツイートを選んでいるのかをご紹介します。
私たちの推奨システムは、多くの相互接続されたサービスやジョブによって構成されていますが、この投稿で詳しく説明します。アプリの中でツイートが推奨される領域は、検索、探索、広告などたくさんありますが、この記事では、ホームタイムラインの「おすすめ(For You)」フィードに焦点を当てます。
ツイートはどのように選ばれるのか?
Twitterの推奨の基盤は、ツイート、ユーザー、エンゲージメントデータから潜在的な情報を抽出する一連のコアモデルと機能です。これらのモデルは、「将来、他のユーザーと交流する確率はどのくらいか」、「Twitter上のコミュニティとその中でのトレンドツイートは何か」など、Twitterネットワークに関する重要な質問に答えることを目的としています。
これらの質問に正確に答えることで、Twitterはより適切な推奨を提供できるようになります。
推奨パイプラインは、これらの機能を消費する3つの主要なステージで構成されています:
候補ソーシングと呼ばれるプロセスで、異なる推奨ソースから最適なツイートを取得する。
機械学習モデルを使用して、各ツイートをランク付けします。
ブロックしたユーザーのツイート、NSFWコンテンツ、すでに見たツイートなどを除外するなどのヒューリスティックやフィルタを適用する。
「おすすめ(For You)」タイムラインの構築と配信を担当するサービスは、Home Mixerと呼ばれています。Home Mixerは、コンテンツのフィードを構築するためのScalaのカスタムフレームワークであるProduct Mixerをベースに構築されています。このサービスは、異なる候補ソース、スコアリング機能、ヒューリスティック、フィルターをつなぐソフトウェアのバックボーンとして機能します。
この図は、タイムラインを構築するために使用される主要なコンポーネントを示しています:
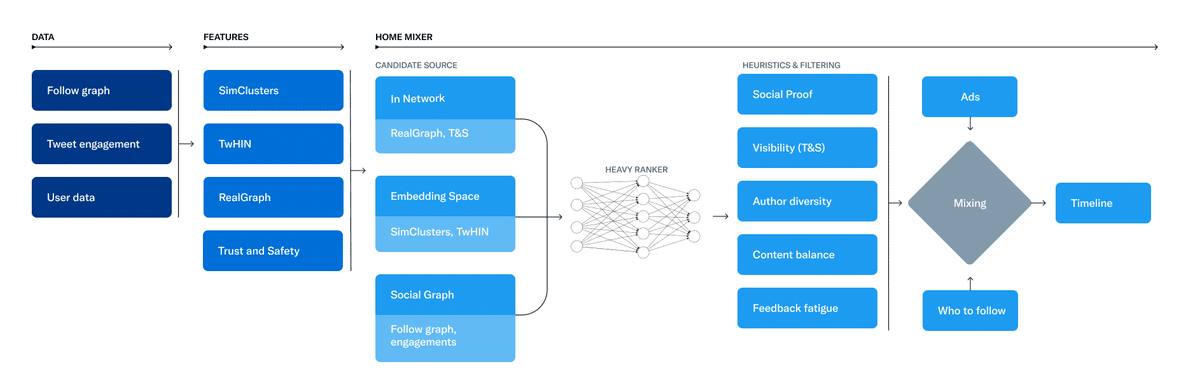
このシステムの主要な部分を、1回のタイムラインリクエストで呼び出される順番に、候補ソースからの候補の取得から見ていきましょう。
候補のソース(Candidate Sources)
Twitterは、ユーザーの最近の関連ツイートを取得するために使用するいくつかの候補ソースを備えています。各リクエストに対して、これらのソースを通じて数億のプールからベストな1500ツイートを抽出するよう試みます。私たちは、あなたがフォローしている人(In-Network)とフォローしていない人(Out-of-Network)から候補を見つけます。現在、「おすすめ(For You)」のタイムラインは、ユーザーによって異なるかもしれませんが、平均して50%のネットワーク内ツイートと50%のネットワーク外ツイートで構成されています。
ネットワーク内ソース(In-Network Source):フォローしている人
In-Networkソースは最大の候補ソースで、あなたがフォローしているユーザーからの最も関連性の高い最新のツイートを配信することを目的としています。ロジスティック回帰モデルを用いて、あなたがフォローしているユーザーのツイートを関連性に基づいて効率的にランク付けします。そして、上位のツイートは次のステージに送られます。
ネットワーク内ツイートのランキングで最も重要な要素は、Real Graphです。Real Graph は、2人のユーザー間のエンゲージメントの可能性を予測するモデルです。あなたとツイート作成者の間のReal Graphのスコアが高いほど、彼らのツイートをより多く含めることになります。
In-Networkソースは、Twitterで最近取り組まれているテーマです。このサービスは、各ユーザーのツイートのキャッシュからネットワーク内ツイートを提供するために使用されていました。また、数年前に更新・学習されたロジスティック回帰ランキングモデルの再設計も行っているところです!
ネットワーク外の情報源(Out-of-Network Sources):フォローしていない人
ユーザーのネットワークの外にある関連ツイートを見つけるのは、より厄介な問題です。投稿者をフォローしていない場合、あるツイートが自分に関連するかどうかをどうやって判断すればいいのでしょうか。Twitterは、この問題に対処するために2つのアプローチをとっています。
ソーシャルグラフ(Social Graph)
私たちの最初のアプローチは、あなたがフォローしている人や同じような興味を持つ人のエンゲージメントを分析することで、あなたが関連性を見出すであろうものを推定することです。
エンゲージメントとフォローのグラフをたどりながら、以下の質問に答えます:
私がフォローしている人たちは、最近どのようなツイートをしたのだろうか?
私と同じようなツイートを「いいね!」しているのは誰で、その人たちが最近「いいね!」したものは何か?
これらの質問に対する答えに基づいて候補となるツイートを生成し、ロジスティック回帰モデルを用いてランク付けします。このようなグラフの探索は、Out-of-Networkの推奨に欠かせないものです。私たちは、この探索を行うために、ユーザーとツイート間のリアルタイムなインタラクショングラフを保持するグラフ処理エンジン、GraphJetを開発しました。Twitterのエンゲージメントとフォローのネットワークを検索するこのようなヒューリスティックは有用であることが証明されていますが(これらは現在ホームタイムラインのツイートの約15%に対応しています)、ネットワーク外のツイートのより大きなソースとなっているのは、エンベッディングスペースへのアプローチです。
エンベッディングスペース(Embedding Spaces)
エンベッディングスペースアプローチは、コンテンツの類似性に関するより一般的な問いに答えることを目的としています:
どのようなツイートやユーザーが私の興味と似ているのか?
エンベッディングは、ユーザーの興味とツイートの内容を数値化したものを生成することで機能します。そして、この埋め込み空間における任意の2人のユーザー、ツイート、ユーザーとツイートのペア間の類似度を計算することができます。正確な埋め込みを生成すれば、この類似度を関連性の代用として使うことができます。
Twitterの最も有用な埋め込み空間の1つがSimClustersです。SimClustersは、カスタム行列因数分解アルゴリズムを用いて、影響力のあるユーザーのクラスターを中心としたコミュニティを発見します。コミュニティは145kあり、3週間ごとに更新されます。ユーザーとツイートはコミュニティの空間に表現され、複数のコミュニティに所属することができます。コミュニティの規模は、個人の友達グループの数千人から、ニュースやポップカルチャーの数億人規模まで様々です。これらは、最も大きなコミュニティの一例です:

各コミュニティにおけるツイートの現在の人気度を見ることで、ツイートをこれらのコミュニティに埋め込むことができます。あるコミュニティのユーザーがそのツイートを気に入れば気に入るほど、そのツイートはそのコミュニティと関連づけられることになります。
ランキング(Ranking)
「おすすめ(For You)」のタイムラインの目標は、関連性の高いツイートを提供することです。パイプラインのこの時点では、関連性のある候補が1500件ほどあります。スコアリングは、各候補ツイートの関連性を直接予測し、タイムライン上のツイートをランク付けするための主要なシグナルとなります。この段階では、どの候補から発信されたものであるかは関係なく、すべての候補が平等に扱われます。
ランキングは、ツイートの相互作用を継続的にトレーニングし、肯定的なエンゲージメント(いいね、リツイート、返信など)を最適化する、約4800万パラメータのニューラルネットワークで実現されています。このランキングメカニズムは、何千もの特徴を考慮し、10個のラベルを出力して各ツイートにスコアを付けます(各ラベルはエンゲージメントの確率を表します)。このスコアからツイートがランク付けされます。
ヒューリスティック、フィルター、製品の特徴(Heuristics, Filters, and Product Features)
ランキングの段階を経て、ヒューリスティックとフィルターを適用して、さまざまな製品機能を実装します。これらの機能は、バランスよく多様なフィードを作成するために連携しています。いくつかの例を挙げます:
視認性フィルタリング: ツイートの内容や好みに応じて、フィルタリングを行います。例えば、ブロックやミュートをしたアカウントのツイートを削除します。
著者の多様性: 一人の著者が連続してツイートしすぎないようにします。
コンテンツのバランス: ネットワーク内のツイートとネットワーク外のツイートを公平なバランスで配信するようにします。
フィードバックに基づく疲労度: 視聴者からネガティブなフィードバックがあった場合、特定のツイートのスコアを下げます。
ソーシャルプルーフ: 品質保証として、そのツイートと二次的なつながりがないネットワーク外のツイートを除外する。つまり、あなたがフォローしている誰かがそのツイートに関与しているか、そのツイートの作者をフォローしているかを確認する。
会話: 元のツイートと一緒にスレッド化することで、返信にさらなる文脈を提供する。
編集されたツイート: 端末に表示されているツイートが古くなっていないかどうかを判断し、編集済みのツイートと入れ替える指示を出す。
ミキシングとサービング(Mixing and Serving)
この時点で、Home Mixerはあなたのデバイスに送信するツイートのセットを準備しています。最後に、ツイートと、広告、フォロー推奨、オンボーディングプロンプトなど、ツイート以外のコンテンツを混ぜ合わせ、お客様の端末に返送して表示させます。
上記のパイプラインは1日に約50億回実行され、平均1.5秒未満で完了します。1回のパイプラインの実行には220秒のCPU時間が必要で、アプリで感じるレイテンシーの150倍近くです。

私たちのオープンソースの目的は、私たちのシステムがどのように動作しているのか、ユーザーの皆さんに完全な透明性を提供することです。私たちは、私たちのアルゴリズムをより詳細に理解するために、ここ(およびここ)で見ることができる私たちの推奨を駆動するコードを公開し、また、私たちのアプリでより透明性を提供するためにいくつかの機能を開発しています。私たちが計画している新しい開発には、以下のようなものがあります:
クリエイターのための、リーチとエンゲージメントに関するより良いTwitter分析プラットフォーム。
ツイートやアカウントに貼られた安全ラベルの透明性を高めることができます。
ツイートがタイムラインに表示される理由をより深く知ることができます。
次は何をする?What’s Next?
Twitterは、世界中の会話の中心です。毎日、1,500億以上のツイートが人々の端末に配信されています。ユーザーに最高のコンテンツを提供することは、困難であると同時にエキサイティングな問題でもあります。私たちは、新しいリアルタイム機能、埋め込み機能、ユーザー表現など、推薦システムを拡張する新しい機会に取り組んでいます。私たちは、未来の開かれた場所を作っているのです。もしあなたがこのことに興味を持たれたなら、ぜひ私たちに加わってください。
文責:Twitterチーム
最後に
読んでみて、少しTwitterの動きが理解できたのではないでしょうか?
Twitterを攻略することも大事ですが、コミュニケーションツールとして人と人との繋がりを大事にしていきたいですね。
最後までお読みいただきありがとうございました。