
【Athena】「簡単!安価!」にSQLで分析できる環境を、AWS-Athenaを利用して構築する!概要から実際の手順をまとめてみた

はじめに
「1月実施のキャンペーンでサイト流入して、その後セッション回数が3回以上あり、購買まで結びついたのは、全体の何%だろうか?」
「番組ごとにどの時間帯にどのデバイスで見られているのか、また番組の何%まで視聴されているのだろうか?」
こういったいくつかの条件を組み合わせて分析したい場合、どのようにすれば数値を算出することができるでしょうか?
例えばですが、エクセルで関数を組んでリストを作成している方も多いと思います。ただエクセルの限界行が約100万行なので、昨今のビックデータ時代では全てエクセルで対応することは難しいです。
そういうリスト作成や細かな分析を実行するためには、クエリ(SQL)を利用することが一般的です。
今回のブログの内容では、クエリの書き方の説明よりも前段階の実行する環境を、構築する方法をご紹介したいと思います。
よく使われているのは、GCPのBigQuery、AWSのRedshiftがありますが、もっと手軽に安価に環境を作りたい場合は、AWSのAthena(アテナ)をお勧めします。
今回の記事では、そんなAthenaの環境構築の方法をご紹介していきます。
Athenaとは
S3上のデータに対して、クエリ(SQL)を利用してデータの分析を行うことができるサービスです。S3にデータを配置するだけでデータ分析を始められ、フルマネージドサービス(サーバーの管理・メンテナンスが不要)のため、簡単に開始できることができます。
金額体系 ※2024年1月1日現在
クエリ単位の従量課金
S3のデータスキャンに対して、1TBあたり5USD
実行に失敗したクエリの料金は無料(キャンセルしたクエリは料金がかかる)
計算方法としては、例えば300万レコードのデータを1GBと仮定し、そのデータを200回スキャンした場合は、
5(USD/TB) × 0.001(TB) × 200(回) = 1USD
と計算され、1USD(≒ 144円 ※)の金額がかかります。
また別途、S3にデータを置くのでS3の保存金額も発生します。
(1GBだと月に0.023USD(≒ 3.3円 ※)です。)
※2024/1/10の為替レート
メリット
使った分だけの料金体系なので金額が安価。
サーバーの保守やメンテナンスが不要。(サーバーレスのサービス)
クエリの実行が速い。
S3にデータを配置するだけで、手軽に利用することが可能。
利用料金が安値で簡単に開始できるのが、Athenaの最大の魅力です。
ユースケース
AWSのアカウントがあり、AWS内にデータがある。
色々なパターンの分析を手早く試したい。
BIツールと連携したい。(TableauやDOMOなどと連携できます。)
ただ、定期的に大きいデータ量を集計する際にはあまり向いていないので、その場合は、RedshiftやBigQueryの利用をお勧めします。
環境構築手順
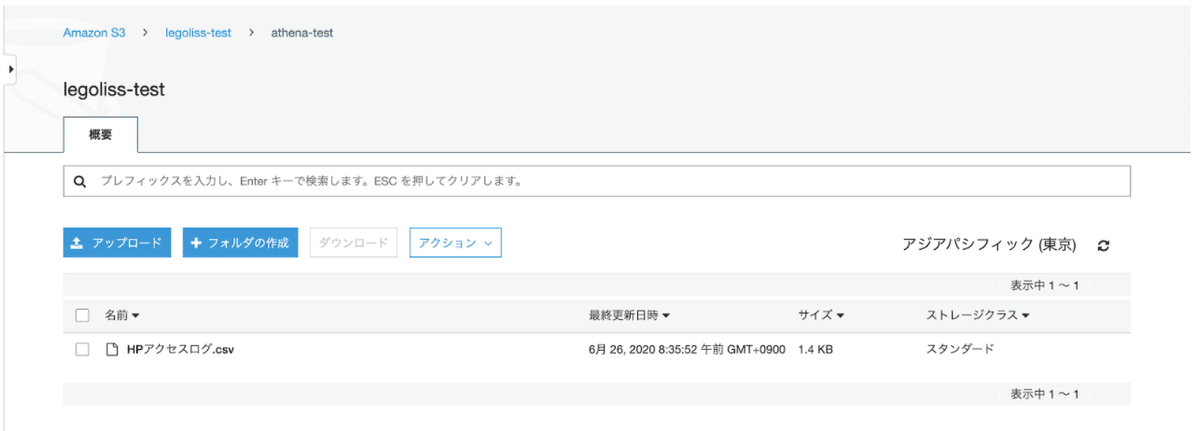
①:S3にデータを置く
今回は、HPのアクセスログ(CSV形式)のデータを使用します。
まずはこのデータを、S3の中に置きます。(S3のバケット作成手順の説明は割愛します。)

今回は一例として、バケット名「legoliss-test」、ディレクトリ先は「athena-test」に置きました。
本来は環境毎に、バケット名とディレクトリ先を変更する必要があります。
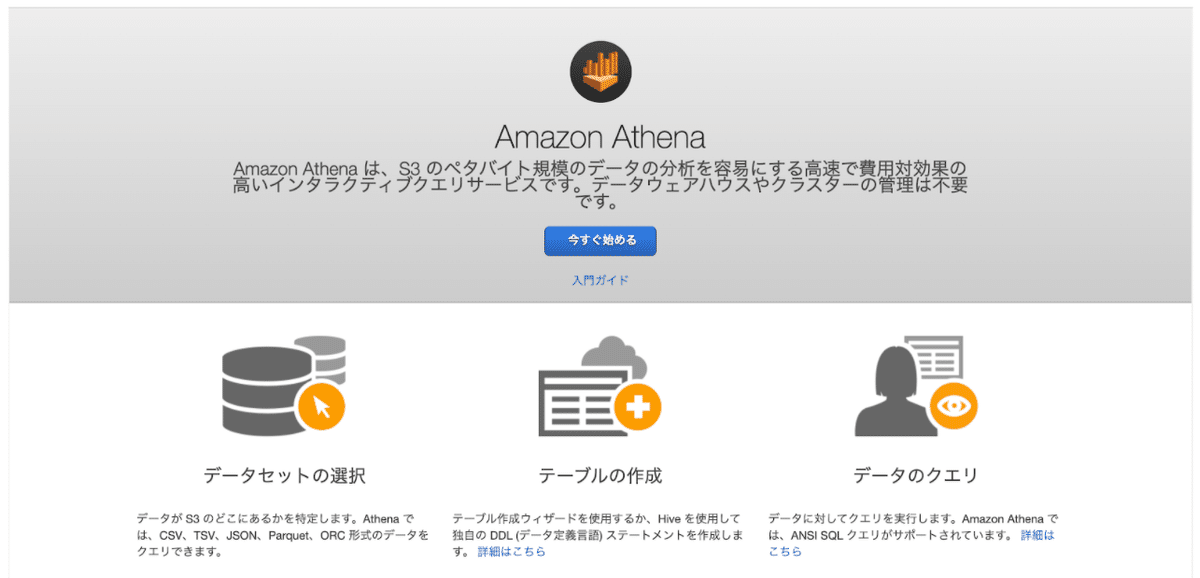
②:初期設定
AWSのコンソールからAthenaを選ぶと以下の画面に遷移しますので、「今すぐ始める」をクリックして下さい。
クリックすると以下の画面になります。
「最初のクエリを実行する前に、Amazon S3 でクエリ結果の場所を設定する必要があります。」と青文字で出ているので、クリックします。

今回はバケット名「legoliss-test」、ディレクトリ先は「athena-output」に結果を置くように設定したいので、クエリの結果の場所を「s3://legoliss-test/athena-output/」と指定します。下2つはとりあえずチェックを入れずに「保存」をクリックします。

これで初期設定が完了です。簡単ですね!
③:Create-Database/Table
まずはデータベースを作成します。
今回は「athena_test」という名前でデータベースを作成したいので、
CREATE DATABASE athena_testとクエリを書いて実行します。

左側のデータベースをクリックして見ると「athena_test」という名前で作成されているのが確認できます。

次に、先ほどS3に置いたアクセスログのデータに、クエリを投げられるようにテーブルを作成します。今回のファイル形式に合わせて以下のクエリを実行します。
この辺りのファイルごとのCreate-Table構文の記述方法は、別記事でも詳しく説明します。
CREATE EXTERNAL TABLE IF NOT EXISTS accesslog (
time string,
cookie string,
title string,
url string,
browser string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
LOCATION 's3://legoliss-test/athena-test'
TBLPROPERTIES (
'skip.header.line.count'='1'
);実行すると「クエリは成功しました。」と表示され、左側のテーブルに「accesslog」というテーブルが作成できました。

また「accesslog」に対して、クエリを投げるとS3に置いたデータと同じ内容が確認できます。

以上で完了です。非常に簡単に環境を構築することができました!
まとめ
- 数値分析のためにエクセルではなく、クエリ(SQL)を利用することが一般的。
- AWSのAthenaは手軽で安価な環境構築が可能であり、S3上のデータに対してクエリを利用してデータの分析を行うことができる。
- クエリ単位に従量課金され、計算された金額がかかるが、S3のデータスキャンに対しては1TBあたり5USD。
簡単にクエリが投げられる分析環境が構築できました。
AWSのサービスと組み合わせて利用もできますので、S3にデータがあればすぐに分析が実施できます。
Legolissへのご相談・お問い合わせはお気軽に!
