
#4 【完全無料】AppGyverとGoogleスプレッドシートを繋げるプログラミングコードの紹介

・前回のおさらい
前回(#3)では、AppGyverの登録の仕方から作成したアプリの動きを実際にWeb上で確認する方法を紹介しました。
今回は、自分で作成したGoogleスプレッドシートとAppGyverを接続する方法を教えます。
誰でも使えるように、私のコードに関しては【完全無料】で紹介したいと思いますので、ぜひご覧になってください。
・必要な手順
必要になる手順は、以下の3つです。
Googleスプレッドシートで一覧表の作成
Google Apps Script(GAS)でコードの編集
AppGyverでコードのURLの連携
1. Googleスプレッドシートで一覧表の作成
今回はサンプルとして、ChatGPTに作ってもらった、以下のような47都道府県の人口の表を使って、説明しようと思います。

【注意!!】A列は小文字のidにして、1から順にしてください。(IDとかはNG)
エクセルをご用意したので、以下の表をダウンロードして使っていただいても構いません。
まず、自分のスプレッドシートの共有を「リンクを知っている全員」に変更
(閲覧者で構いません)

2. Google Apps Script(GAS)でコードの編集
次に、Googleスプレッドシートの拡張機能であるGoogle Apps Script(通称:GAS)を開きます。

以下のような画面になるので、自由に名称を変更する(「人口統計」になっているところ)
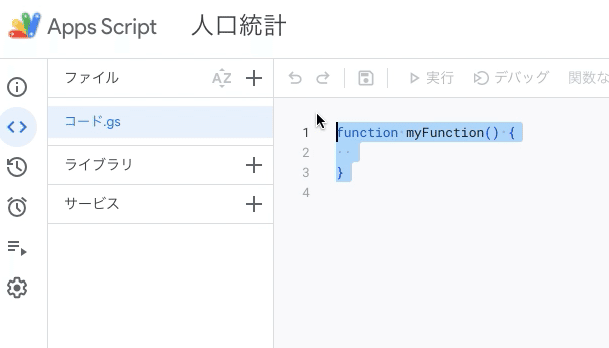
「コード.gs」の部分が開いているため、右のコードの作成欄に以下のコードをコピペする。
1ヶ月 費やし、
100回以上 ChatGPTに質問を投げ、
50回以上 トライ&エラーしたコードが以下
// スプレッドシートのURLからワークブックを開く
var wbook = SpreadsheetApp.openByUrl('あなたのスプレッドシートのURL');
var wsheet = wbook.getSheetByName('タブの名称');
// キャッシュの有効期限(秒)
var CACHE_EXPIRATION = 60; // 1分
// キャッシュに保存するデータの最大サイズ(バイト)
var MAX_CACHE_SIZE = 1000000; // 1MB
var MAX_CACHE_ENTRY_SIZE = 100000; // Individual cache entry size limit (adjust as needed)
function doGet(e) {
var op = e.parameter.action;
if (op === 'get_record') {
var id = e.parameter.id;
return getRecord(id);
}
if (op === 'get_collection') {
var query = e.parameter.query;
if (!query) {
// クエリが提供されていない場合、空のJSONを返す
return ContentService.createTextOutput(JSON.stringify([])).setMimeType(ContentService.MimeType.JSON);
}
return getCollection(query);
}
return ContentService.createTextOutput(JSON.stringify({ "error": "Invalid action" })).setMimeType(ContentService.MimeType.JSON);
}
function getRecord(id) {
var cache = CacheService.getScriptCache();
var cachedData = cache.get(id);
if (cachedData != null) {
return ContentService.createTextOutput(cachedData).setMimeType(ContentService.MimeType.JSON);
}
var record = binarySearchRecordById(wsheet, parseInt(id));
if (!record) {
return ContentService.createTextOutput(JSON.stringify({ "result": "id not found" })).setMimeType(ContentService.MimeType.JSON);
} else {
var jsonRecord = JSON.stringify(record);
if (jsonRecord.length <= MAX_CACHE_SIZE) {
cache.put(id, jsonRecord, CACHE_EXPIRATION);
} else {
console.error('Data size exceeds the maximum cache size.');
}
return ContentService.createTextOutput(jsonRecord).setMimeType(ContentService.MimeType.JSON);
}
}
function getCollection(query) {
var cache = CacheService.getScriptCache();
var cacheKey = 'collection_' + query;
var cachedData = getCachedDataInChunks(cache, cacheKey);
if (cachedData != null) {
return ContentService.createTextOutput(cachedData).setMimeType(ContentService.MimeType.JSON);
}
var dataRange = wsheet.getDataRange();
var values = dataRange.getValues();
var headers = values[0];
var records = [];
for (var i = 1; i < values.length; i++) {
var record = {};
var includeRecord = false;
for (var j = 0; j < headers.length; j++) {
record[headers[j]] = values[i][j];
if (j !== 0 && values[i][j].toString().toLowerCase().includes(query.toLowerCase())) {
includeRecord = true;
}
}
if (includeRecord) {
records.push(record);
}
}
var jsonCollection = JSON.stringify(records);
if (jsonCollection.length <= MAX_CACHE_SIZE) {
cacheDataInChunks(cache, cacheKey, jsonCollection);
} else {
console.error('Data size exceeds the maximum cache size.');
}
return ContentService.createTextOutput(jsonCollection).setMimeType(ContentService.MimeType.JSON);
}
function binarySearchRecordById(sheet, id) {
var dataRange = sheet.getDataRange();
var values = dataRange.getValues();
let low = 1; // Assuming data starts from row 2 (row 1 is headers)
let high = values.length - 1;
while (low <= high) {
let mid = Math.floor((low + high) / 2);
let midId = values[mid][0]; // 1st column is ID
if (midId < id) {
low = mid + 1;
} else if (midId > id) {
high = mid - 1;
} else {
var record = {};
values[0].forEach(function(header, index) {
record[header] = values[mid][index];
});
return record;
}
}
return null; // ID not found
}
function cacheDataInChunks(cache, key, data) {
var dataSize = data.length;
var chunkCount = Math.ceil(dataSize / MAX_CACHE_ENTRY_SIZE);
for (var i = 0; i < chunkCount; i++) {
var chunkKey = key + "_chunk_" + i;
var chunkData = data.slice(i * MAX_CACHE_ENTRY_SIZE, (i + 1) * MAX_CACHE_ENTRY_SIZE);
cache.put(chunkKey, chunkData, CACHE_EXPIRATION);
}
cache.put(key + "_chunk_count", chunkCount.toString(), CACHE_EXPIRATION);
}
function getCachedDataInChunks(cache, key) {
var chunkCount = parseInt(cache.get(key + "_chunk_count"));
if (isNaN(chunkCount)) {
return null;
}
var data = '';
for (var i = 0; i < chunkCount; i++) {
var chunkKey = key + "_chunk_" + i;
var chunkData = cache.get(chunkKey);
if (chunkData != null) {
data += chunkData;
} else {
return null;
}
}
return data;
}
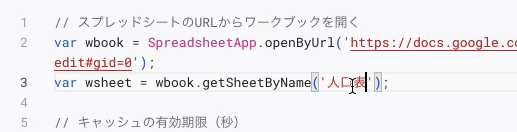
上記のコードのうち、「あなたのスプレッドシートのURL」の部分を自分の作成したスプレッドシートのURLで置き換える。

上の「http」から始まる部分を、コピーし、「var wbook = SpreadsheetApp.openByUrl('あなたのスプレッドシートのURL')」の部分に置き換える。
さらに、「var wsheet = wbook.getSheetByName('タブの名称')」の部分は、スプレッドシートのタブの名称に置き換える。
最終的に修正した部分が以下の通り。
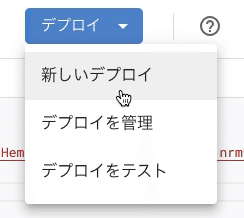
その後、「プロジェクトの保存」→「デプロイ」→「新しいデプロイ」を押す。
「新しいデプロイ」の画面で「ウェブアプリ」を選択する。

以下の3つを設定し、「デプロイ」を押す。
・説明 → アプリの名称
・次のユーザーとして実行 → 自分
・アクセスできるユーザー → 全員

すると、承認画面が現れるので、以下に従って承認していく。(画面は英語です。Googleアカウントの初期設定によって、日本語の場合もありますが、クリックする位置は同じ)

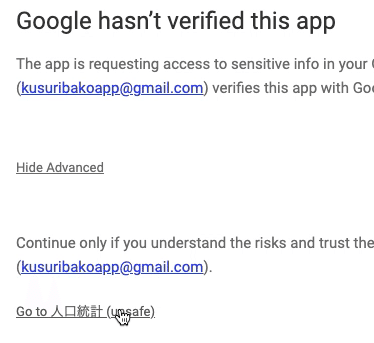
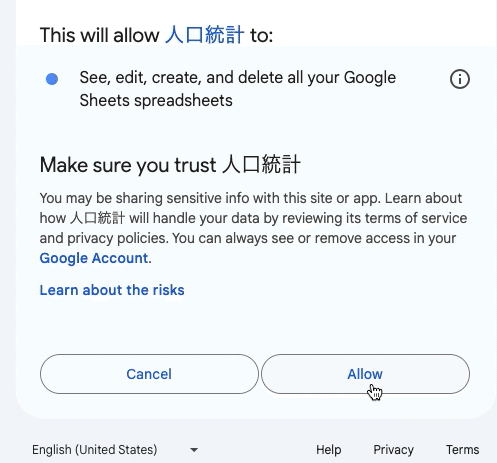

最終的にWebアプリのURLが表示され、デプロイが完了します。(上の画面のようになっていたらOK!)
これで、Googleスプレッドシート、Google Apps Scriptでの設定は完了です。
3. AppGyverとウェブアプリのURLを連携する
ここから、AppGyverとの連携に移ります。
(1) 作成したAppGyverの画面を開き、DATAの項目を選択。
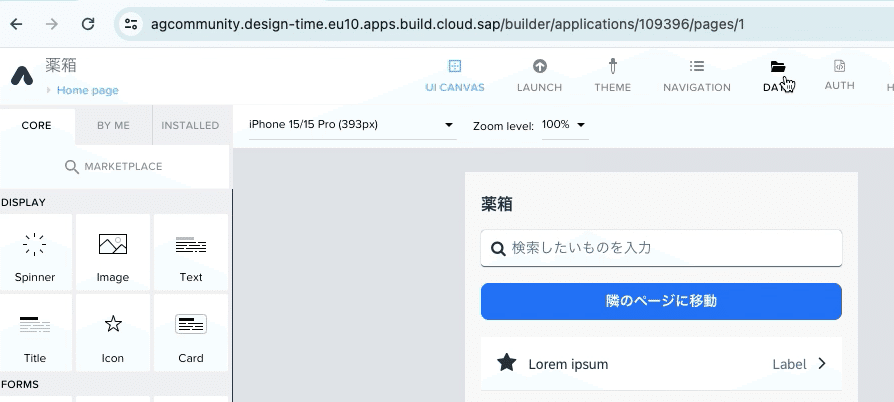
(2) データ接続の画面に移るため、「CREATE DATA ENTITY」→「REST API direct integration」を選択。

(3)データ連携の画面が出るため、「BASE」の部分から編集

・Resource ID → 自由に記載(英語のみ)
・Short description → 記載不要
・Resource URL → GASでデプロイしたウェブアプリのURLを貼り付け
(↓これのことです:URLはApps Scriptの「デプロイ」→「デプロイを管理」から確認できます)

(4)「GET COLLECTION」の欄に移動し、「Query parameter」を以下のように修正

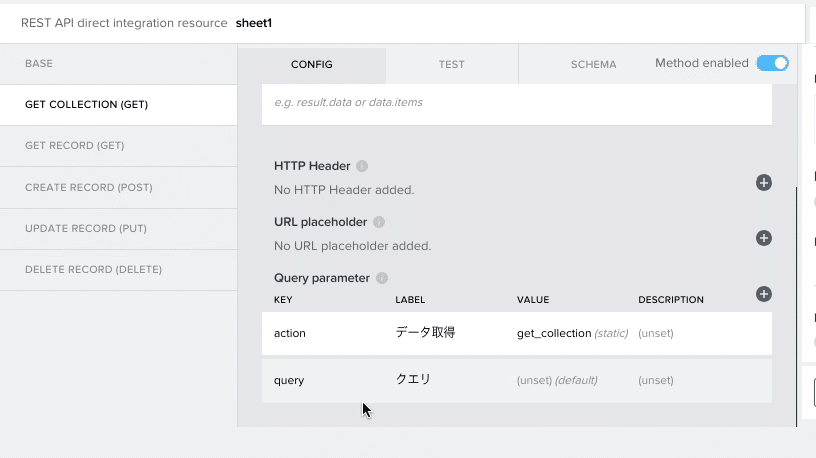
(5)「CONFIG」の隣にある「TEST」画面に移動し、クエリのところに何でもいいので、県の名前(一部でも可)を入れて、「RUN TEST」を実行。
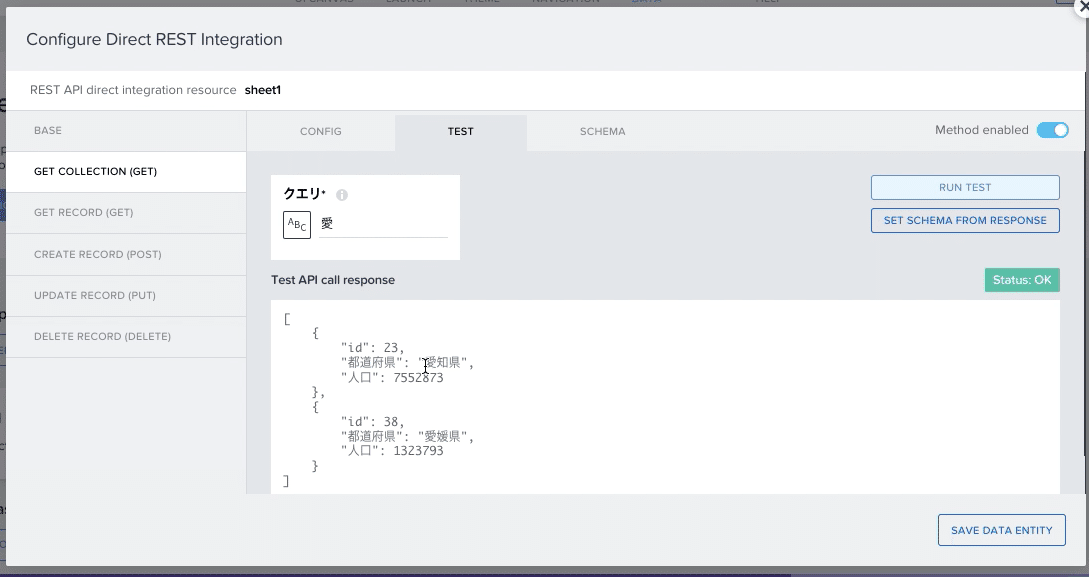
緑色の枠で「Status OK」と出て、下の欄に結果が表示されたら、連携成功です。(上記の画面参照)
(今回は「愛」とだけクエリに入力し、愛知県と愛媛県の結果を表示させてます)
(6)「SET SCHEMA FROM RESPONSE」を押し、「SCHEMA」画面に移動し、列の名前(id、都道府県、人口)が全て表示されていたら、上手く呼び出せている証拠です。

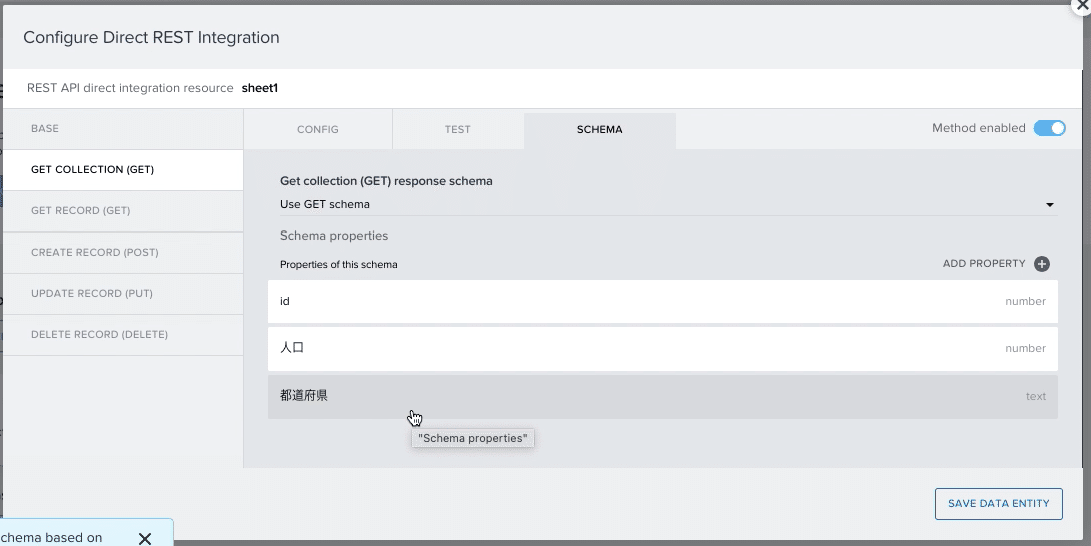
これで、「GET COLLECTION」は完了。
(7)次に、「GET COLLECTION」の下にある「GET RECORD」に移ります。
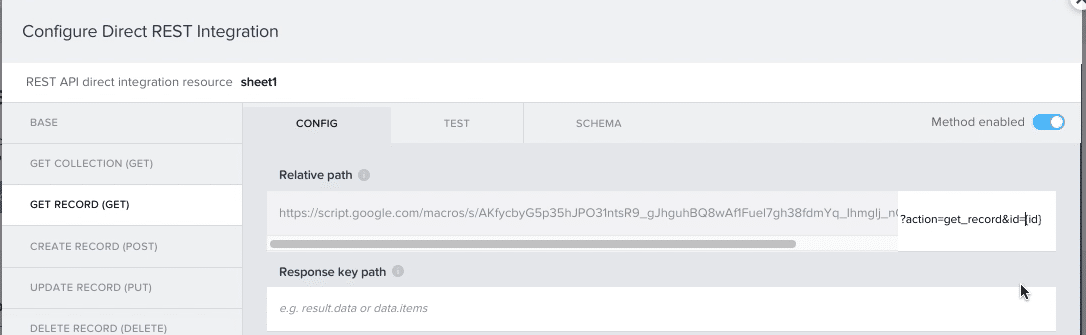
「Relative path」の白地の部分に以下の文字を追加。
?action=get_record&id=[id]
(8)「CONFIG」の隣にある「TEST」画面に移動し、idのところ1から47までの数字を入れて、「RUN TEST」を実行。

こちらも、緑色の枠でOKと出て、下の欄に結果が表示されたら、連携成功です。

その後、「GET COLLECTION」の時と同じく、「SET SCHEMA FROM RESPONSE」を押し、「SCHEMA」画面に移動し、列の名前(id、都道府県、人口)が全て表示されていたら、上手く呼び出せている証拠です。
(9)最後に「SAVE DATA ENTITY」で保存をし、データの連携が完了。

お疲れ様でした! これでデータの連携は以上です!
・最後に
今回の内容はいかがだったでしょうか。
少し複雑な内容でしたが、この部分が上手く繋がった時は、
私は結構感動しました。
このやり方を覚えると、他のノーコードアプリではできない自由度の高いアプリが開発できますので、ぜひ覚えていただければと思います。
質問点や改善点があれば、ぜひコメントを頂ければと思います!
次回は、実際にAppGyverのアプリ上で今回連携したデータの呼び出しを行ってみたいと思います。
それでは、次回もよろしくお願いします!