
話している言葉をリアルタイムに翻訳してテキストを表示させる

こんにちは。
音楽家育成塾のこうたろうです。
この記事では話している言葉をリアルタイムに翻訳してテキスト表示させるプログラムを公開します。
音楽家はやはり国境を超えて仕事をすることも多い分けです。
仕事中は英語でもいいですが、プライベートでもっと仲良くなりたい時は旅先で翻訳ツールを使うことが多いでしょう。
外国の方ともっとコミュニケーションを取るためにプログラムを使いましょう。
ちなみに、ファイルからテキスト生成や、テキストを音声ファイルにする方法や、WordPressに自動投稿するまでの技術はこちらの記事です。
こちらも参考にしてください。
リアルタイム翻訳
日本語で話している内容をリアルタイムでスペイン語に翻訳し続けるプログラムを作成していきましょう。
これを実現するには、AzureのSpeech SDKを使って音声認識を行い、その結果をAzure Translator Text APIを使ってスペイン語に翻訳します。
APIはMicrosoft Azureの公式サイトより取得し、APIキーやエンドポイントが漏れることのないように厳重に管理し、従量課金制度の無料枠を必ず確認しながら進めてください。
プログラムの概要
リアルタイム音声認識: マイクから音声を取得し、Azure Speech-to-Textで日本語のテキストに変換します。
翻訳: 翻訳APIを使って、日本語のテキストをスペイン語に翻訳します。
停止機能: プログラムは常に音声を処理し続けますが、Ctrl + C や別の方法で停止できるようにします。
pip install azure-cognitiveservices-speech requests
import azure.cognitiveservices.speech as speechsdk
import requests
import threading
import time
# Azure Speech-to-Text の設定
speech_subscription_key = "YOUR_SPEECH_SUBSCRIPTION_KEY"
speech_region = "YOUR_SPEECH_REGION"
# Azure Translator の設定
translator_subscription_key = "YOUR_TRANSLATOR_SUBSCRIPTION_KEY"
translator_endpoint = "https://api.cognitive.microsofttranslator.com/"
translator_region = "YOUR_TRANSLATOR_REGION"
# Azure Speech-to-Textでリアルタイムに日本語を認識する関数
def start_speech_recognition(should_stop):
# 音声認識の設定
speech_config = speechsdk.SpeechConfig(subscription=speech_subscription_key, region=speech_region)
speech_config.speech_recognition_language = "ja-JP" # 日本語の音声を認識
audio_config = speechsdk.AudioConfig(use_default_microphone=True)
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_config)
def recognized_callback(event):
if event.result.reason == speechsdk.ResultReason.RecognizedSpeech:
text = event.result.text
print(f"Recognized (Japanese): {text}")
translated_text = translate_text(text, target_language="es")
print(f"Translated (Spanish): {translated_text}")
elif event.result.reason == speechsdk.ResultReason.NoMatch:
print("No speech could be recognized.")
elif event.result.reason == speechsdk.ResultReason.Canceled:
cancellation_details = event.result.cancellation_details
print(f"Speech Recognition canceled: {cancellation_details.reason}")
if cancellation_details.reason == speechsdk.CancellationReason.Error:
print(f"Error details: {cancellation_details.error_details}")
# 音声認識のイベントハンドラを設定
speech_recognizer.recognized.connect(recognized_callback)
# 音声認識を非同期で開始
print("Starting continuous recognition. Press Ctrl+C to stop...")
speech_recognizer.start_continuous_recognition()
# 停止条件が満たされるまで待機
try:
while not should_stop.is_set():
time.sleep(0.1)
except KeyboardInterrupt:
print("Stopping...")
# 音声認識を停止
speech_recognizer.stop_continuous_recognition()
# Azure Translatorで日本語テキストをスペイン語に翻訳する関数
def translate_text(text, target_language="es"):
path = '/translate'
constructed_url = translator_endpoint + path
params = {
'api-version': '3.0',
'to': target_language # スペイン語に翻訳
}
headers = {
'Ocp-Apim-Subscription-Key': translator_subscription_key,
'Ocp-Apim-Subscription-Region': translator_region,
'Content-type': 'application/json'
}
body = [{
'text': text
}]
request = requests.post(constructed_url, params=params, headers=headers, json=body)
response = request.json()
if response:
translated_text = response[0]['translations'][0]['text']
return translated_text
else:
print("Translation failed.")
return None
# メイン処理
def main():
should_stop = threading.Event() # プログラム停止のフラグ
# 音声認識と翻訳を別スレッドで実行
recognition_thread = threading.Thread(target=start_speech_recognition, args=(should_stop,))
recognition_thread.start()
# プログラムを停止するにはCtrl+Cを押してください
try:
while True:
time.sleep(0.1)
except KeyboardInterrupt:
print("Stopping translation...")
should_stop.set() # 停止フラグを立てる
recognition_thread.join() # スレッドの終了を待つ
# 実行部分
if __name__ == "__main__":
main()
プログラムの説明:
リアルタイム音声認識:
start_speech_recognition 関数は、マイクから日本語音声をリアルタイムで取得し、Azure Speech-to-Textを使ってその音声をテキストに変換します。
recognized_callback で音声認識結果を受け取り、認識されたテキストを出力します。
翻訳機能:
translate_text 関数では、Azure Translatorを使って日本語のテキストをスペイン語に翻訳します。target_language="es"としてスペイン語を指定しています。
プログラムの停止方法:
プログラムは、Ctrl + C を押すことで停止します。threading.Event を使用して、停止フラグを設定し、音声認識と翻訳のスレッドを安全に停止します。
マイク入力の使用:
speechsdk.AudioConfig(use_default_microphone=True) により、デフォルトのマイクが音声入力として使用されます。
使い方:
プログラムを実行すると、マイクで日本語の音声をリアルタイムに認識し、それをスペイン語に翻訳して出力します。
Ctrl + C を押すとプログラムが停止します。
注意点:
APIキーとリージョンの設定: speech_subscription_key、translator_subscription_key などのAzure設定を自分のAzureアカウントに合わせて入力してください。
マイクの設定: マイクのデフォルト設定が使われますが、必要に応じて他のマイクデバイスを指定することもできます。
レスポンス速度: Azure Speech-to-TextとTranslator APIの応答速度によって、認識と翻訳に若干の遅延が生じる可能性があります。
これで、日本語の音声をスペイン語にリアルタイムで翻訳し、出力するプログラムが実現できます。
実行結果はご覧の通り。
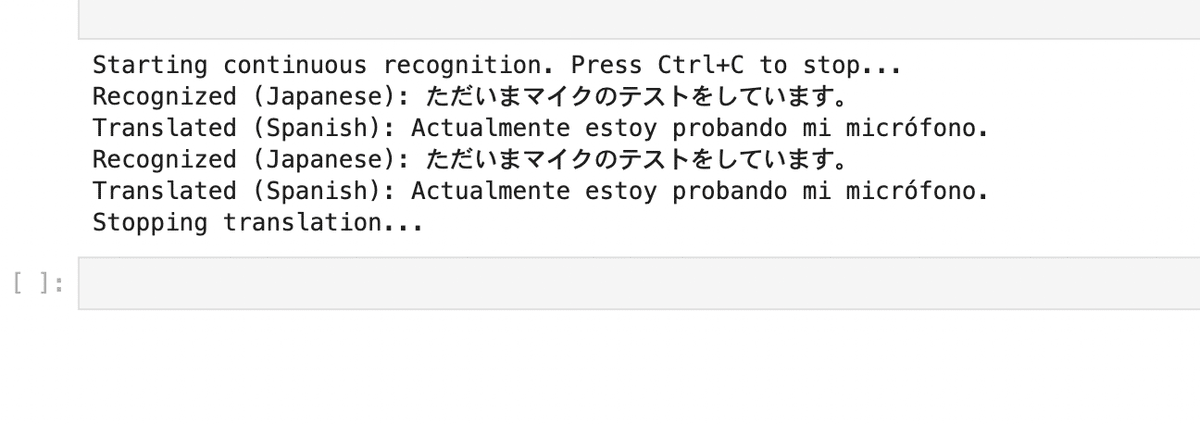
逆も然り
import azure.cognitiveservices.speech as speechsdk
import requests
import threading
import time
# Azure Speech-to-Text の設定
speech_subscription_key = "YOUR_SPEECH_SUBSCRIPTION_KEY"
speech_region = "YOUR_SPEECH_REGION"
# Azure Translator の設定
translator_subscription_key = "YOUR_TRANSLATOR_SUBSCRIPTION_KEY"
translator_endpoint = "https://api.cognitive.microsofttranslator.com/"
translator_region = "YOUR_TRANSLATOR_REGION"
# Azure Speech-to-Textでリアルタイムにスペイン語を認識する関数
def start_speech_recognition(should_stop):
# 音声認識の設定
speech_config = speechsdk.SpeechConfig(subscription=speech_subscription_key, region=speech_region)
speech_config.speech_recognition_language = "es-ES" # スペイン語の音声を認識
audio_config = speechsdk.AudioConfig(use_default_microphone=True)
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_config)
def recognized_callback(event):
if event.result.reason == speechsdk.ResultReason.RecognizedSpeech:
text = event.result.text
print(f"Recognized (Spanish): {text}")
translated_text = translate_text(text, target_language="ja")
print(f"Translated (Japanese): {translated_text}")
elif event.result.reason == speechsdk.ResultReason.NoMatch:
print("No speech could be recognized.")
elif event.result.reason == speechsdk.ResultReason.Canceled:
cancellation_details = event.result.cancellation_details
print(f"Speech Recognition canceled: {cancellation_details.reason}")
if cancellation_details.reason == speechsdk.CancellationReason.Error:
print(f"Error details: {cancellation_details.error_details}")
# 音声認識のイベントハンドラを設定
speech_recognizer.recognized.connect(recognized_callback)
# 音声認識を非同期で開始
print("Starting continuous recognition. Press Ctrl+C to stop...")
speech_recognizer.start_continuous_recognition()
# 停止条件が満たされるまで待機
try:
while not should_stop.is_set():
time.sleep(0.1)
except KeyboardInterrupt:
print("Stopping...")
# 音声認識を停止
speech_recognizer.stop_continuous_recognition()
# Azure Translatorでスペイン語テキストを日本語に翻訳する関数
def translate_text(text, target_language="ja"):
path = '/translate'
constructed_url = translator_endpoint + path
params = {
'api-version': '3.0',
'to': target_language # 日本語に翻訳
}
headers = {
'Ocp-Apim-Subscription-Key': translator_subscription_key,
'Ocp-Apim-Subscription-Region': translator_region,
'Content-type': 'application/json'
}
body = [{
'text': text
}]
request = requests.post(constructed_url, params=params, headers=headers, json=body)
response = request.json()
if response:
translated_text = response[0]['translations'][0]['text']
return translated_text
else:
print("Translation failed.")
return None
# メイン処理
def main():
should_stop = threading.Event() # プログラム停止のフラグ
# 音声認識と翻訳を別スレッドで実行
recognition_thread = threading.Thread(target=start_speech_recognition, args=(should_stop,))
recognition_thread.start()
# プログラムを停止するにはCtrl+Cを押してください
try:
while True:
time.sleep(0.1)
except KeyboardInterrupt:
print("Stopping translation...")
should_stop.set() # 停止フラグを立てる
recognition_thread.join() # スレッドの終了を待つ
# 実行部分
if __name__ == "__main__":
main()
他の言語も設定を変えるだけ
音声認識言語の変更:
speech_config.speech_recognition_language = "es-ES" を設定して、スペイン語を認識するようにしています。
翻訳言語の変更:
translate_text 関数では、target_language="ja" を指定して、スペイン語のテキストを日本語に翻訳します。
プログラムの動作:
リアルタイム音声認識:
スペイン語の音声をマイクから取得し、Azure Speech-to-Textを使ってリアルタイムにテキストに変換します。
翻訳:
取得されたスペイン語のテキストを、Azure Translatorを使って日本語に翻訳します。
プログラムの停止:
プログラムはCtrl+Cを押すことで停止できます。threading.Eventによる停止フラグを用いて、音声認識と翻訳のスレッドを安全に終了させます。
二人で話して同時通訳
日本語を日本語として認識してスペイン語に翻訳し、スペイン語をスペイン語として認識して日本語に翻訳するプログラムを作成できます。このプログラムでは、2つの言語(日本語とスペイン語)を同時に処理し、それぞれ適切に翻訳する必要があります。
仕組みの概要
音声認識: Azure Speech SDKを使って日本語とスペイン語の音声をそれぞれ認識。
翻訳: 認識された日本語はスペイン語に、スペイン語は日本語に翻訳。
リアルタイム処理: 会話が続く間、双方の言語をリアルタイムで翻訳し続けます。
プログラム全体のフロー
マイクから音声をキャプチャ。
日本語の場合はスペイン語に翻訳。
スペイン語の場合は日本語に翻訳。
結果をリアルタイムで表示し続ける。
Ctrl + Cで停止。
pip install azure-cognitiveservices-speech requests
import azure.cognitiveservices.speech as speechsdk
import requests
import threading
import time
# Azure Speech-to-Text の設定
speech_subscription_key = "YOUR_SPEECH_SUBSCRIPTION_KEY"
speech_region = "YOUR_SPEECH_REGION"
# Azure Translator の設定
translator_subscription_key = "YOUR_TRANSLATOR_SUBSCRIPTION_KEY"
translator_endpoint = "https://api.cognitive.microsofttranslator.com/"
translator_region = "YOUR_TRANSLATOR_REGION"
# Azure Speech-to-Textで日本語かスペイン語を認識する関数
def start_speech_recognition(should_stop):
# 音声認識の設定(日本語)
speech_config_ja = speechsdk.SpeechConfig(subscription=speech_subscription_key, region=speech_region)
speech_config_ja.speech_recognition_language = "ja-JP" # 日本語を認識
recognizer_ja = speechsdk.SpeechRecognizer(speech_config=speech_config_ja)
# 音声認識の設定(スペイン語)
speech_config_es = speechsdk.SpeechConfig(subscription=speech_subscription_key, region=speech_region)
speech_config_es.speech_recognition_language = "es-ES" # スペイン語を認識
recognizer_es = speechsdk.SpeechRecognizer(speech_config=speech_config_es)
# 日本語が認識された時の処理
def recognized_ja_callback(event):
if event.result.reason == speechsdk.ResultReason.RecognizedSpeech:
text = event.result.text
print(f"Recognized (Japanese): {text}")
translated_text = translate_text(text, target_language="es")
print(f"Translated to Spanish: {translated_text}")
elif event.result.reason == speechsdk.ResultReason.Canceled:
print("Japanese recognition canceled")
# スペイン語が認識された時の処理
def recognized_es_callback(event):
if event.result.reason == speechsdk.ResultReason.RecognizedSpeech:
text = event.result.text
print(f"Recognized (Spanish): {text}")
translated_text = translate_text(text, target_language="ja")
print(f"Translated to Japanese: {translated_text}")
elif event.result.reason == speechsdk.ResultReason.Canceled:
print("Spanish recognition canceled")
# イベントハンドラを設定
recognizer_ja.recognized.connect(recognized_ja_callback)
recognizer_es.recognized.connect(recognized_es_callback)
# 日本語とスペイン語の認識を開始
recognizer_ja.start_continuous_recognition()
recognizer_es.start_continuous_recognition()
# 停止条件が満たされるまで待機
try:
while not should_stop.is_set():
time.sleep(0.1)
except KeyboardInterrupt:
print("Stopping...")
# 音声認識を停止
recognizer_ja.stop_continuous_recognition()
recognizer_es.stop_continuous_recognition()
# Azure Translatorでテキストを翻訳する関数
def translate_text(text, target_language):
path = '/translate'
constructed_url = translator_endpoint + path
params = {
'api-version': '3.0',
'to': target_language # 翻訳先言語を設定
}
headers = {
'Ocp-Apim-Subscription-Key': translator_subscription_key,
'Ocp-Apim-Subscription-Region': translator_region,
'Content-type': 'application/json'
}
body = [{
'text': text
}]
request = requests.post(constructed_url, params=params, headers=headers, json=body)
response = request.json()
if response:
translated_text = response[0]['translations'][0]['text']
return translated_text
else:
print("Translation failed.")
return None
# メイン処理
def main():
should_stop = threading.Event() # プログラム停止のフラグ
# 音声認識と翻訳を別スレッドで実行
recognition_thread = threading.Thread(target=start_speech_recognition, args=(should_stop,))
recognition_thread.start()
# プログラムを停止するにはCtrl+Cを押してください
try:
while True:
time.sleep(0.1)
except KeyboardInterrupt:
print("Stopping translation...")
should_stop.set() # 停止フラグを立てる
recognition_thread.join() # スレッドの終了を待つ
# 実行部分
if __name__ == "__main__":
main()
音声認識の設定:
日本語 ("ja-JP") とスペイン語 ("es-ES") の2つの音声認識を同時に実行します。
日本語音声が認識された場合はスペイン語に翻訳し、スペイン語音声が認識された場合は日本語に翻訳します。
リアルタイムでの翻訳:
translate_text 関数で、日本語をスペイン語に、スペイン語を日本語に翻訳します。翻訳はAzure Translator APIを利用しています。
マルチスレッド処理:
音声認識と翻訳処理は別スレッドで実行され、プログラムはCtrl+Cで停止するまで動作します。
停止機能:
Ctrl+Cで停止すると、threading.Eventを使って認識処理を停止します。
翻訳後のテキストを音声として自動で読み上げる
スペイン語の音声をリアルタイムで認識し、それを翻訳した後に翻訳された言語で音声として読み上げるプログラムを作成することができます。このプログラムでは、Azure Speech-to-Textを使用してスペイン語の音声を認識し、Azure Translatorを使用して翻訳し、最終的に**Azure Speech Synthesis (Text-to-Speech)**を使って翻訳結果を音声として読み上げます。
プログラムのフロー:
スペイン語で話した内容をマイクから取得。
Azure Speech-to-Textでスペイン語の音声をテキストに変換。
Azure Translatorでスペイン語のテキストを指定された言語に翻訳。
Azure Speech Synthesis (Text-to-Speech) で翻訳された言語で音声を読み上げる。
pip install azure-cognitiveservices-speech requests
import azure.cognitiveservices.speech as speechsdk
import requests
import time
# Azure Speech-to-Text の設定
speech_subscription_key = "YOUR_SPEECH_SUBSCRIPTION_KEY"
speech_region = "YOUR_SPEECH_REGION"
# Azure Translator の設定
translator_subscription_key = "YOUR_TRANSLATOR_SUBSCRIPTION_KEY"
translator_endpoint = "https://api.cognitive.microsofttranslator.com/"
translator_region = "YOUR_TRANSLATOR_REGION"
# Azure Speech Synthesis の設定
tts_subscription_key = "YOUR_SPEECH_SUBSCRIPTION_KEY"
tts_region = "YOUR_SPEECH_REGION"
# Azure Translatorでスペイン語テキストを翻訳する関数
def translate_text(text, target_language):
path = '/translate'
constructed_url = translator_endpoint + path
params = {
'api-version': '3.0',
'to': target_language # 翻訳先言語を設定
}
headers = {
'Ocp-Apim-Subscription-Key': translator_subscription_key,
'Ocp-Apim-Subscription-Region': translator_region,
'Content-type': 'application/json'
}
body = [{
'text': text
}]
request = requests.post(constructed_url, params=params, headers=headers, json=body)
response = request.json()
if response:
translated_text = response[0]['translations'][0]['text']
return translated_text
else:
print("Translation failed.")
return None
# Azure Speech Synthesisで翻訳テキストを読み上げる関数
def speak_text(text, language_code):
speech_config = speechsdk.SpeechConfig(subscription=tts_subscription_key, region=tts_region)
speech_config.speech_synthesis_voice_name = language_code # 音声合成の言語と音声を指定
audio_config = speechsdk.AudioConfig(use_default_speaker=True)
synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config)
result = synthesizer.speak_text_async(text).get()
if result.reason == speechsdk.ResultReason.SynthesizingAudioCompleted:
print(f"Synthesized speech: {text}")
elif result.reason == speechsdk.ResultReason.Canceled:
cancellation_details = result.cancellation_details
print(f"Speech synthesis canceled: {cancellation_details.reason}")
# Azure Speech-to-Textでリアルタイムにスペイン語を認識し、翻訳後に音声を生成する関数
def start_speech_recognition():
# 音声認識の設定(スペイン語)
speech_config = speechsdk.SpeechConfig(subscription=speech_subscription_key, region=speech_region)
speech_config.speech_recognition_language = "es-ES" # スペイン語を認識
audio_config = speechsdk.AudioConfig(use_default_microphone=True)
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_config)
# 音声認識時の処理
def recognized_callback(event):
if event.result.reason == speechsdk.ResultReason.RecognizedSpeech:
text = event.result.text
print(f"Recognized (Spanish): {text}")
# 翻訳する
translated_text = translate_text(text, target_language="ja") # ここでは日本語に翻訳
if translated_text:
print(f"Translated (Japanese): {translated_text}")
# 翻訳されたテキストを読み上げ
speak_text(translated_text, "ja-JP-NanamiNeural") # 日本語の音声合成に設定
elif event.result.reason == speechsdk.ResultReason.NoMatch:
print("No speech could be recognized.")
elif event.result.reason == speechsdk.ResultReason.Canceled:
cancellation_details = event.result.cancellation_details
print(f"Speech Recognition canceled: {cancellation_details.reason}")
if cancellation_details.reason == speechsdk.CancellationReason.Error:
print(f"Error details: {cancellation_details.error_details}")
# 音声認識のイベントハンドラを設定
speech_recognizer.recognized.connect(recognized_callback)
# 音声認識を非同期で開始
print("Starting continuous recognition. Press Ctrl+C to stop...")
speech_recognizer.start_continuous_recognition()
# プログラムを停止するまで待機
try:
while True:
time.sleep(0.1)
except KeyboardInterrupt:
print("Stopping...")
# 音声認識を停止
speech_recognizer.stop_continuous_recognition()
# メイン処理
def main():
start_speech_recognition()
# 実行部分
if __name__ == "__main__":
main()
音声認識 (Speech-to-Text):
start_speech_recognition 関数で、スペイン語の音声をリアルタイムで認識します。
speech_config.speech_recognition_language = "es-ES" により、スペイン語の認識が行われます。
翻訳 (Translator Text API):
認識されたスペイン語のテキストを、translate_text 関数を使って指定された言語(ここでは日本語 "ja")に翻訳します。
音声合成 (Text-to-Speech):
翻訳されたテキストは、speak_text 関数で指定された言語の音声(ここでは "ja-JP-NanamiNeural" 日本語の声)を使って読み上げます。
音声合成にはAzureのSpeech Synthesis機能を利用しています。
説明の補足:
ja-JP-NanamiNeural は日本語の音声モデルです。スペイン語や他の言語に翻訳する場合は、それに応じた音声モデルを指定する必要があります。例えば、英語に翻訳して英語で読み上げる場合は en-US-AriaNeural を使用します。
音声モデルの詳細はMicrosoft Azureの音声リファレンスを参照してください。
無限ループ:
プログラムはCtrl + Cを押すまで動作し続け、リアルタイムでスペイン語の音声を翻訳して読み上げます。

この記事が気に入ったらチップで応援してみませんか?