
【StableDiffusion】便利すぎるおすすめ拡張機能Extensions【10選】生産性が上がり!

この記事では、StableDiffusionWebUIに入れると作業がとてもはかどる拡張機能をご紹介させていただきます。
拡張機能の追加はすべて同じで以下の手順です。
拡張機能【Extensions】の追加手順【ローカル環境・SageMakerの場合】
1.Extensionsタブに移動
2.install from ULRタブに移動
3.URL for extensionsに拡張機能のURLを入れる
例)https://github.com/DominikDoom/a1111-sd-webui-tagcomplete.git
4.installボタンをクリック
5.install ボタン下に「restart」と出たら

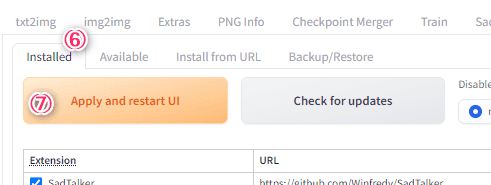
6.installedタブに移動
7.Apply and restart UIをクリックするとWebUIが再起動します
再起動したら完了です。
拡張機能【Extensions】の追加手順【GoogleColabの場合】
以下コードをカスタマイズしてご使用ください。
!git clone [Githubの拡張機能URL] /content/stable-diffusion-webui/extensions/[拡張機能名]
例:TIled Diffusionの場合
!git clone https://github.com/DominikDoom/a1111-sd-webui-tagcomplete /content/stable-diffusion-webui/extensions/a1111-sd-webui-tagcompletegooglecolabのノートブック内に拡張機能のコードが記載された場所があるので、1行空けて追加してください。

使用するノートブックによってフォルダ構成が違う場合があります。
他の拡張機能追加コードと同じ構成に合わせるようにお願いします。
Youtubeでも解説しています
TikTok×AIがめっちゃ熱い!
TikTokは新たに再生回数によって収益化できるプログラムを発表しました。
そによりバズ動画を作って投稿するだけで収益化できるようになりました。
私もトリビア系や英語系などの動画で実際に収益化しています。
今後AIの規制が厳しくなる前の今がチャンス
Kさんが出されている情報ですが、様々なジャンルに対応しているのでかなりおすすめです。

ControlNet【画像加工】
ControlNetは機能がおおすぎてここでは解説しきれないので、よく使われるOpenpose,canny,reference_onlyについて、どういったことができるのかだけ解説します。
導入方法と使い方については別記事でまとめています。
openpose
openposeを使えば、簡単にポーズをとらせることができます。
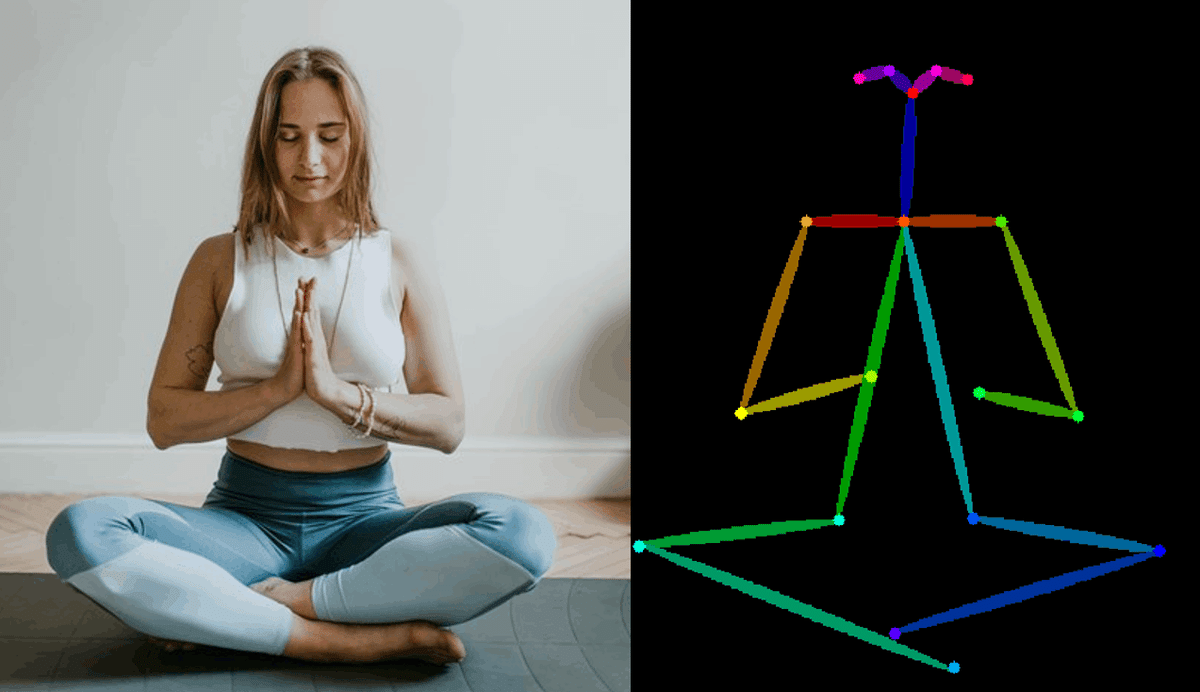

今回は無料で配布されている画像をもとにしましたが、ポーズを作ってよみこませることもできます。
写真以外にデッサンポーズで画像を作ってその画像をもとにしてポーズをとらせることも可能です。
openposeは他にも種類があります。
openpose:体、顔の向きなど
openpose_faceonly:顔・表情のみ
openpose_face:顔・表情、方や腕の動きも
openpose_hand:手・指
openpose_full:すべて
canny
cannyは写真から線画を作り、その線画をもとに色を塗っていくイメージです。

なので、色の塗り替えや、実写系写真をイラストに変換することができます。よくある写真をアニメ画像にするAIアプリに似ていますね。

reference_only
首から上の特徴を強く残して画像を生成してくれます。
顔を固定したまま様々なポーズをとらせたり服を着せることができるので、グラビア写真集などで活用できそうです。

Tile_resample
Tileのモデルを使うと以下画像のように一瞬で高解像度化してくれます。
高解像度化する方法として、HiresやTile Diffusionが有名ですが、ControlNetのTileとの大きな違いは、元の画像のスタイルを維持したまま高解像度化してくれることです。

Hiresを使うと以下画像のように元の画像が結構変わってしまうことがよくあります。

ControlNetの導入方法~使い方は別記事でまとめています
a1111-sd-webui-tagcomplete【呪文プロンプト補助】
呪文(プロンプト)を入力した際に単語を提案してくれる機能です。
1文字入れるだけでそこから人気順に単語を提案してくれます。
これはとても便利です。まだプロンプトに慣れていない初心者の方もそうですが、上級者でも英単語のスペルを忘れることがあるのでそれを補ってくれるのはとても嬉しい機能です

インストールURL
https://github.com/DominikDoom/a1111-sd-webui-tagcomplete.giteasy-prompt-selector【呪文プロンプト補助】
この機能はtagcompleteにも似ていますが、この機能は日本語で書かれており選択すると単語がプロンプトに入力されます。
特に表情の単語とか覚えていなくてもワンクリックで入力してくれるのは助かります。

インストールURL
https://github.com/blue-pen5805/sdweb-easy-prompt-selector.gitadetailer
After Detailerという拡張機能で、顔の崩れを防いでくれたり、顔の差分画像の生成もできるとても便利な機能です。
せっかくかわいいイラストができたのに、顔がちょっとくずれてしまっている。表情がわかりにくい。顔がぼやけている。
そんなときに使えるのがこの機能。

非常に便利な機能ですが、この機能を使用すると2倍くらい時間がかかってしまうので、常に使う機能ではありません。
画像生成した後に気に入ったイラストだけを後で補正するのに使いましょう。
顔の崩れを修正してくれるだけではなく、顔の差分も作れます。

adetailerの使い方
adetailerを有効にすると画像生成にかかる時間が2倍かかります。
なので、基本的には画像を生成後に気に入った画像で顔を修正したい場合に使います。
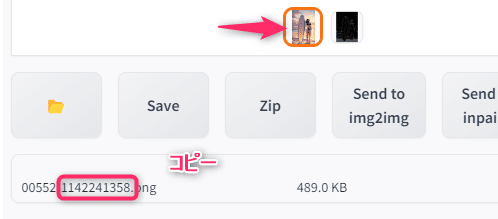
画像をクリックし、Saveをクリックすると番号が表示されます。
その番号をコピーし、Seedに貼り付けしましょう。
こうすることで同じ画像が生成できます。
顔のはっきりさせたい場合は「Enable Adetailer」にチェックを入れて「Adetailer model」をface_yolov8n.ptに変更してGenerateするだけで顔がはっきりした画像が生成できます。
表情を変更する場合はAdetailer promptにAngly,grinなどの表情プロンプトをいれてGenerateすれば表情を変更できます。

詳しい使い方はこちらの記事で解説しています。
sd-webui-ar【画像サイズ変更】
画像サイズをワンクリックで変更する

https://github.com/alemelis/sd-webui-arTiled Diffusion
Stable Diffusionで生成したイラストをアップスケール(高解像度化)するためにハイレゾ(Hires.fix)を使っている方もいるかもしれません。
ですが、ハイレゾは大容量のVRAMが必要で、途中でエラーになって停止してしまうことがあります。(私はRTX3060を使っていますがエラーがよく出ます)
エラーも出ることなく安定して、元のイラストを保持したまま、高解像度化してくれるのがTiled Diffusionです。

Tiled Diffusionの使い方
Tiled Diffusionはtxt2imgでもimg2imgのどちらでも使用することができますが、今回はimg2imgでのやり方で解説いたします。
まずはtxt2imgで生成した画像をimg2imgへ送ります
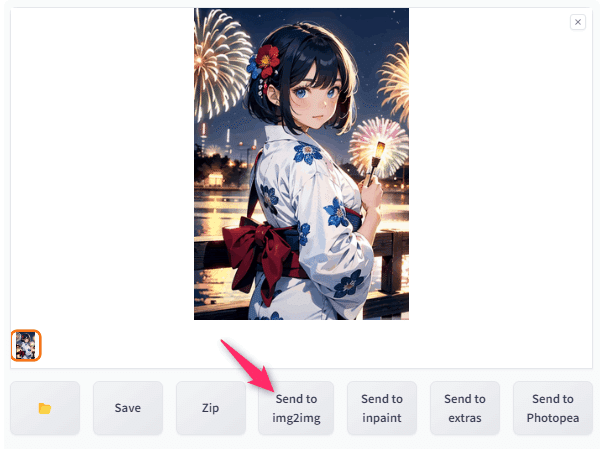
img2imgに画像が入った状態になります。

後は設定をしていきます。
プロンプト、ネガティブプロンプトは画像生成時と同じのでOKです。
Sampling method、CFG Scaleは生成時と同じに合わせます。
Denoising stengthだけ低めに設定します。0.3~0.5推奨
高くすると画像が荒れだします。
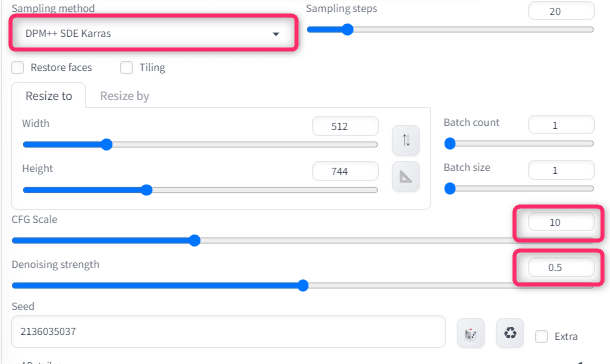
次はTiled Diffusionを開き、以下設定をします。
1.「Enable Tiled Diffusion」にチェックを入れます
2.「Keep input image size」にもチェックを入れます
3.MethodをMultiDiffusionを選択
4.Latent tile batch sizeは1にします
5.Upscalerは任意のもので大丈夫です。
6.Scale Factorは何倍の解像度にするかです。今回は2倍にします。

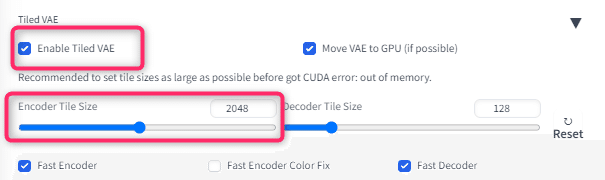
Tile VAEも設定します。
1.Enable TIled VAEにチェックを入れます。
2.Encoder TIle Sizeはデフォルトの2048でOKですが、エラーが出るようであれば低めに設定してください。
準備ができたら「Generate」するとアップスケールできます。
元の画像をほとんど変えずに解像度を上げることができました。


https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111Civitai Helper
Civitai Helperの主な機能は、CivitaiからダウンロードしたモデルやLoRaのサムネイルをダウンロードしたり、Web UIでCivitaiモデルやLoRAのURLを入力するだけでダウンロードできる拡張機能です。
サムネイルダウンロード機能「Scan Models for Civitai」の使い方
モデルとかLoRAがいっぱいあると、これどんなモデルだったかな?ってわからなくなる時あるんですよね。
そんなときにサムネイルがあると便利です!


「Skip NSFW Preview Images」以外にすべてチェックを入れて「Scan」ボタンをクリックするとサムネイルがダウンロードされます。
「Skip NSFW Preview Images」のチェックは成人向けです。
チェックを入れるとダウンロードされません。

「Scan」してから「花札マーク」のボタンを押すとサムネイルが反映されているのがわかります。
ただし、Hagging Faceからダウンロードしたモデルはサムネイルは出ません。
モデルダウンロード機能「Scan Models for Civitai」の使い方
Scan Models for Civitaiは、Web UI上でCivitaiのモデルやLoRaをダウンロードできる機能です。
これ使うといちいちWeb UIを再起動しなくて済みます。
GoogleColab版やSagemaker版を使っている方におすすめです。
新しいモデルやLoRaを使いたくなって追加したけど、再起動する必要がありますが、この機能を使えば再起動の必要がないのであると便利です。
まずは、モデルのURLをコピーします

コピーしたURLを「Civitai URL」に入れ、「Get Model info by Civitai Url」ボタンをクリックします。
Civitaiからモデル情報が取得されます。
Sub-folderか/を選び、Model Versionも選びます
全ての項目が埋まったら「Download Model」ボタンをクリックするとダウンロードされます。

反映されない場合は、「Refresh」ボタンを押すと出てくるはずです。

https://github.com/butaixianran/Stable-Diffusion-Webui-Civitai-Helper.gitPrompt All in One
「Prompt All in One」の拡張機能をインストールするとプロンプト入力欄に色んな機能が追加されます。
All in Oneというだけあって、プロンプトを簡単に操作できる機能がこの機能に集約されています!
翻訳機能、プロンプトの重みづけ、プロンプトをドラッグ&ドロップで並び替え、お気に入り機能、履歴機能もあったりでとってもおすすめです!

プロンプト簡単編集機能
プラスマイナスでプロンプトに重みづけ、()で影響を強め、[]で影響を弱めします。
手入力をしなくてもボタンで操作できます。
プロンプトお気に入り機能
よく使うプロンプトはお気に入りに登録しておくと便利です!

プロンプト履歴機能
過去に使用したプロンプトが自動で残ります。
WebUIを再起動しても残っているので、便利です。

プロンプト翻訳機能
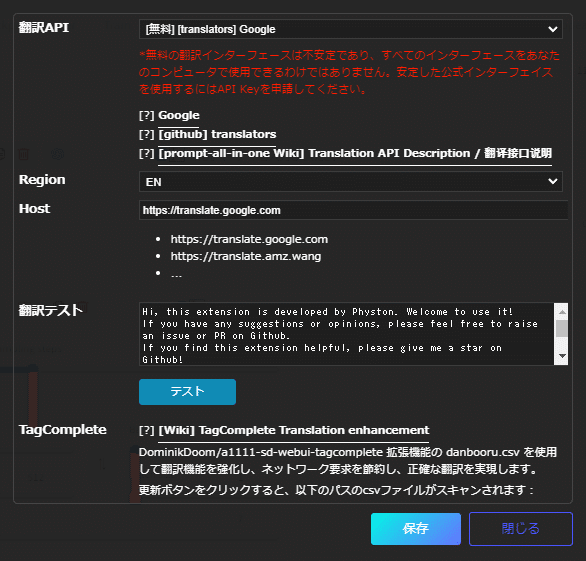
翻訳機能を使うためには少し設定が必要です。
歯車マークをクリックし、その中のAPIマークをクリックします。

翻訳APIは「APIキーが不要です」と書かれているのは無料で使えます。
特にこだわりがなければGoogleを選んで保存します。
Google翻訳が悪いのか、うまく翻訳されない時があります。
おまけ機能ぐらいで考えたほうがいいかもしれません。

https://github.com/Physton/sd-webui-prompt-all-in-onemodel-toolkit
「model-toolkit」という拡張機能があります。
これを使えば、容量の大きいモデルを軽量化することができます。
モデルをたくさん入れているとストレージを圧迫してしまって困りますよね・・・。
軽量化しても生成される画像が劣化することはありませんのでご安心ください。
model-toolkitの使い方
まず、「model-toolkit」をインストールすると「Toolkit」タブが追加されます。
1.Toolkit内にSourceに軽量化したいモデルを選択します。
2.Loadボタンをクリックします。

3.どのくらい軽量化されるのか表示されます。
今回は3.97GBから1.99GBに軽量化できるようです。
4.Saveボタンをクリックすると「models\Stable-diffusion」に保存されます。
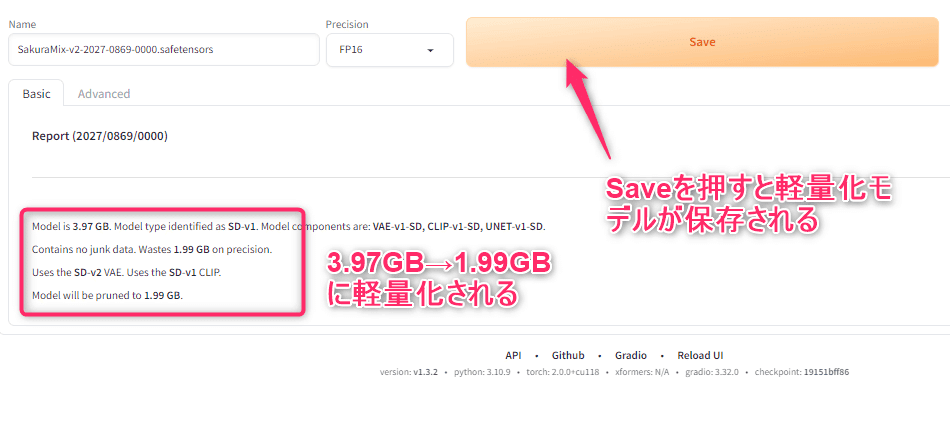
オリジナルのモデルは削除して問題ありません。

左が圧縮したモデル 右がオリジナルのモデルです。
ほとんど差がないのがわかります。

https://github.com/arenasys/stable-diffusion-webui-model-toolkitImage Browser
Stable Diffusionで生成した画像は「outputs」にすべて自動保存されますが、エクスプローラーを別画面で開いて確認するのって地味にめんどくさいんですよね。
過去に生成した画像がWeb UI上で確認できる機能があるんです!
これ使いだすと手放せません。
機能を追加すると「Image Browser」タブが追加されます。
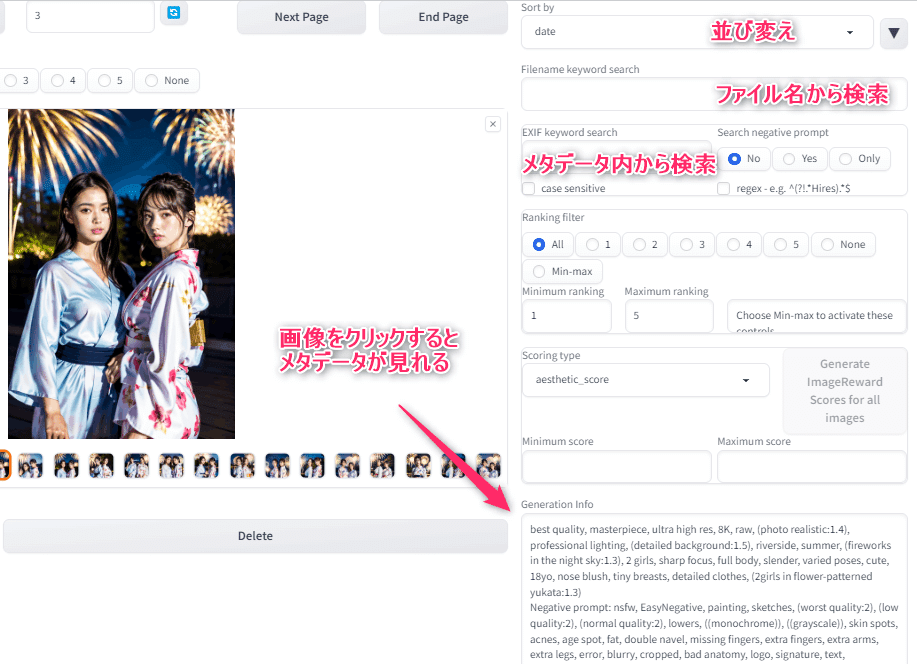
まず最初に「リフレッシュ、更新」ボタンをクリックすると過去に生成した画像が表示されます。
次へ、前へボタンでページをめくれます。

画像を1枚クリックすると、メタデータ(画像生成時のプロンプト、ネガティブプロンプト)が見れます。
これも便利ですよね。
そして、ファイル名で検索したり、メタデータから検索することも可能です。
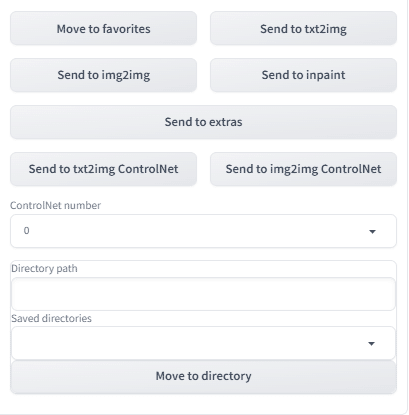
画像をインペイントに送ったり、コントロールネットに送ったりもできます。
favoritesボタンを押すとお気に入りに追加でき、お気に入りフォルダで管理できるのも便利ですよ!
https://github.com/AlUlkesh/stable-diffusion-webui-images-browser番外編【あると便利な拡張機能】
Canvas-Zoom
StableDiffusionWebUIのinpaintは画面が小さくて塗りにくい!
そんな時に使えるのがこのCanvas-Zoomで、画面を大きくして塗りやすくします。
Shift + マウスホイールをくりくりするとinpaintのキャンバスを拡大縮小することができます。
細かいところを塗るときに便利です。

ダウンロードURL
https://github.com/richrobber2/canvas-zoom.gittagger【画像からプロンプト生成】
Taggerは、画像を自動で分析し、画像の特徴をタグ付けをしてくれます。
画像の特徴からワードを自動で入れてくれるので、同じような画像を生成したい、LoRAを作る場合などに有効です。
使い方は、Taggerタブに移動し、画像をドロップします。
自動でプロンプトを生成してくれるので、send to txt2imgかSend to img2imgでプロンプトを送りす。

ただし、クオリティ系プロンプトとネガティブプロンプトは含まれないので手動でいれてください。
ダウンロードURL
https://github.com/toriato/stable-diffusion-webui-wd14-tagger.gitOpen Pose Editor
「Open Pose Editor」は、棒人間を編集してControlNetに送ることができます。
とらせたいポーズの画像を探すのって結構大変です。
デッサン人形を遣う方法もありますが、これはWeb UI上から操作できるので便利です。
Open Poseをよく使う方はあると重宝します。

Addボタンを押せば二人もできます。

https://github.com/fkunn1326/openpose-editorVAE切り替え
VAEの切り替えって結構手間かかりませんか?
拡張機能とは違いますが、設定を変更するだけでVAE切り替えがとっても楽になります。

VAE切り替えの設定変更方法
settingsタブに移動し、左メニューにある「User interface」を開きます。
その中の「Quicksettings list」の項目があります。
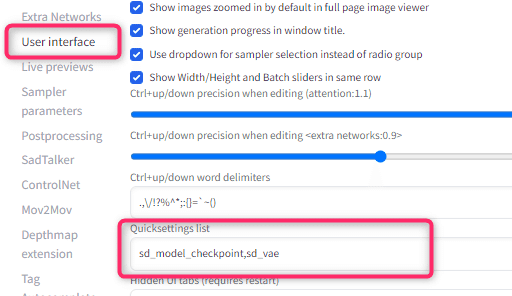
初期設定だと「sd_model_checkpoint」だけなので、以下のとおり変更します。
変更出来たら、「Apply settinsg」→「Reload UI」の順でWeb UIを再起動しましょう。
sd_model_checkpoint,sd_vae
再起動が完了するとモデル切り替えの隣にVAE切り替えが表示されます。

まとめ
今回はStableDiffusionWebUIで使えるとっても便利な拡張機能を8つ紹介させていただきました。
気に入った機能があればぜひ使ってみてください。