
とーふ流モデルマージ作業時のマインドについて紹介!(階層マージ番外編)

はじめに
今回は、私がマージモデルを製作する際、どのようにやっているか、Weight(比率・レシピ)はどのように決めているのか、そのマインドをご紹介しようと思います!
同じような記事を前に出してなかったっけ?と思った方もいると思います。
この記事でも、私のマージ方法について説明していますが、あくまでも大まかな流れだけの説明でした。
今回は、どのようにレシピを決めているのか、そこに触れていきたいと思います。
今回はSuper Mergerの使い方については説明していません。
Super Mergerを利用した階層マージ方法を何となく分かっている、という前提でお話を進めますので、まだの方は上記の記事を一読してみてからご覧ください。
また、今回の記事の内容は、深くまで踏み込んだ説明もしている為、階層マージについてある程度の知識は必要かもしれません。
Mind1 : 階層別の影響
階層マージをする際に、大前提として拡散モデルにおける階層とは何ぞやというものを、何となくでも知っておく必要があると思います。
前回の記事では、階層別の影響度をマトリクス図にして載せていました。
(今回は、流し見による語弊がないように画像は添付していません)
あくまでもマトリクス図は目安で、前の記事でもお話ししましたが、実際はマトリクス図の通りに変化が働かないことが多いです。
”人体や背景などの部品を認識しているわけではないので、ここは顔を担当している階層だから、顔を描画するよ!といった挙動をしているわけではない”
ということです。
じゃあ、あのマトリクス図が間違いなの?というと全てが間違いというわけでもありません。
では、何を目安にマージを行えばいいの?ということですが、鍵となるのはやっぱりU-Netです。
今回は、肝となるU-Netの各要素を、何となく覚えて頂いてマージに生かして頂ければと思います。
Stable Diffusionの大枠
ここでは、Stable Diffusionの細かな仕組みの説明はしませんが、U-Netを知る上では避けては通れないと思ってます。
Stable Diffusionは、大きく分けて3つの役割で構成されています。
U-Net(拡散モデル)
VAE(変分オートエンコーダ)
Text Encoder(テキストエンコーダ, Transformer)
中でも、U-Netは「生成の中核(逆拡散による復号過程)」を担っています。
これだけでも、なんか重要そう!って思いますよね。
以下のQiita記事(オミータ氏のQiita記事)がとても分かりやすく、凄く知見が広がります。
Stable Diffusionの仕組みについて、凄く分かりやすいのでもっと知りたい方は、是非読んでみてください。
各層の要素について
実はとってもわかりやすい表が、Super MergerのGithubにあります。

elemental_en.md - List of elements
上記のリンクでは、各階層の要素が表に纏められています。
この表は、横軸の項目は階層を示しており、縦軸の項目は要素を示しています。
[ null ]と書かれている階層では、表目の左項に記載のある要素がない階層になります。
この要素こそ、U-NetのResBlock、AttnBlockの中身が含まれています。
ResBlockは主に時刻要素を扱い、AttnBlockはテキストからの条件を扱います。
ResBlockやAttnBlockは、各要素毎の集合体です。
中でも、AttnBlockの内容はCLIPに大きく寄与する部分です。
AttnBlockの階層に、Self Attention層とCross Attention層が存在します。
主に、Text Encoderからの入力はCross Attention層で処理が行われます。

要するに、プロンプトで入力された文字列による条件付けは、ここのCross Attention層による影響が大きく関わっているということですね。
なので、上記に記載したGithub - Super Mergerのリンク先でもあるように、
基本的にはattnが顔や服装の情報を担っているようです。
elemental_ja.md - 要素一覧
と書かれております。
これは、Cross Attention層のk,vに入力される、テキスト(プロンプト)が、大きく作用するからです。
ひとまずは、そのような役割をする要素であることを念頭に置いておきましょう。
[ ちょっと踏み込んだ補足 ]
Self Attention層のqkvとCross Attention層のqkvは、要素一覧上では明記されていません。
(attn1とattn2という表記になっている:Github - Super Merger [要素一覧]内のマトリクス表内)
Self Attention層のqkvに入力されるのは、Linear層からのWeightで作られており、Cross Attention層は、qのみU-Net内で平坦化した1次元ベクトルを用いて、k,vはテキストの埋め込みを利用して作られている点が相違してます。
# Self Attention Layer Forward
h_ = x
h_ = self.norm(h_)
q = self.q(h_)
k = self.k(h_)
v = self.v(h_)
~ 中略 ~
# Cross Attention Layer Forward
h = self.heads
q = self.to_q(x)
context = default(context, x)
k = self.to_k(context)
v = self.to_v(context)コードを読み解いていくと、attn1がSelf Attention、attn2がCross Attentionを担っていると思われます。
但し、テキストがない場合は、attn2もSelf Attentionの振る舞いで扱われるようです。
self.attn1 = CrossAttention(query_dim=dim, heads=n_heads, dim_head=d_head, dropout=dropout) # is a self-attention
self.ff = FeedForward(dim, dropout=dropout, glu=gated_ff)
self.attn2 = CrossAttention(query_dim=dim, context_dim=context_dim,
heads=n_heads, dim_head=d_head, dropout=dropout) # is self-attn if context is noneまた、中間層(Middle Block)では、常にSelf Attentionで扱われるようです。
self.middle_block = TimestepEmbedSequential(
ResBlock(
ch,
time_embed_dim,
dropout,
dims=dims,
use_checkpoint=use_checkpoint,
use_scale_shift_norm=use_scale_shift_norm,
),
AttentionBlock(
ch,
use_checkpoint=use_checkpoint,
num_heads=num_heads,
num_head_channels=dim_head,
use_new_attention_order=use_new_attention_order,
) if not use_spatial_transformer else SpatialTransformer( # always uses a self-attn
ch, num_heads, dim_head, depth=transformer_depth, context_dim=context_dim,
disable_self_attn=disable_middle_self_attn, use_linear=use_linear_in_transformer,
use_checkpoint=use_checkpoint
),※私はこのように認識していますが、間違っていたらご指摘願います…
Mind2 : マージレシピの決め方
ここからが本題です。
いつも私がどのようにマージレシピを決めているかをご紹介します。
今回使用するモデル
今回使用するモデルは、私が公開している以下モデルを使用します。
Model A : LastpieceCore A0751
Model B : VoidnoiseCore R0829
レシピを作成するツールとして、MAGiCを使用していきます。
プロット設定
今回は以下を目標にして、マージを進めていきたいと思います。
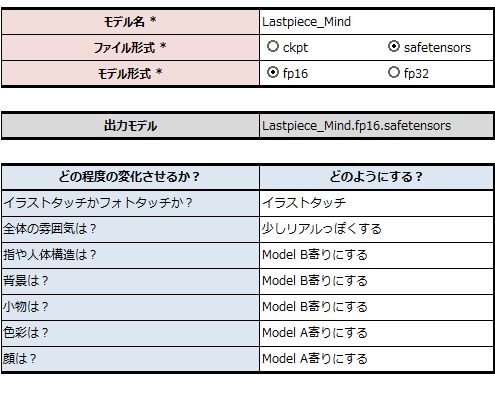
今回は分かりやすくするために、プロットを書きましたが、最近は記載しないことが多いです。
というのも、旧シリーズモデルに寄せるという明確な目標があるので、最近は記載していませんが、新しい試みのモデル製作の場合では、記載するようにしています。
サンプルプロンプトとサンプル設定を決める
サンプルプロンプトはあまりがっつり考えてません。
但し、基本的にLoRAは使わないように意識しています。(LoRAによるモデルのブレをなくす為)
今回は以下のプロンプトと設定を使用することにしました。
Prompt
kawaii, cute,(1 girl,solo:1.3),rust eyes:1.5,[youthful],blush hair, long hair, bangs, hair_ornament,
quilted jacket,large breasts,
BREAK
best quality,8k,raw photo,realistic,absurdres,highres,ultra detailed,beautiful eyes,
BREAK
drop,apartment,graveyard,railroad crossing,DuskNegative Prompt
EasyNegativeV2,negative_hand-neg,(worst quality:1.5),(low quality:1.5),(normal quality:1.5),(monochrome),
(grayscale),(watermark),(white letters),signature,username,text,error,(manicure),(nsfw),(earing)Parameters
Sampler: DPM++ 2M Karras
Step: 35
CFG scale: 11.0
Denoising strength: 0.6
Clip skip: 2
Hires upscale: 2
Hires steps: 15
Hires upscaler: Latent (nearest)
VAE: voidnoise.vae.tuned
LoRAは使いませんが、TIは使います…。
というのも、恐らく多くの方が使って生成していると思うので、ネガティブプロンプトはあくまでも実際の生成に近い状態でテストしたい為です。
テストマージ実施
まずは、どの程度変化が生まれるのか、プリセット(FLATシリーズ)を用いてテストマージを行います。
私は、テストマージ用に以下のマージプリセットを追加しています。
FLAT_50 0,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5,0.5Model A / Bをオール0.5の割合で混ぜ合わせるようのプリセットです。
では、早速作っていってみましょう。
まずは、Seedはオールランダムで、FLAT系全てをX/Y/Z Plotに入れて出力してみます。
Seedを固定しない理由は、近景・中景・遠景が生成されるSeedを特定していないので、とりあえずSeedは固定せずに回します。
生成する枚数は、状況に応じて変えていますが、とりあえず3枚でPlot出力できるようにしています。
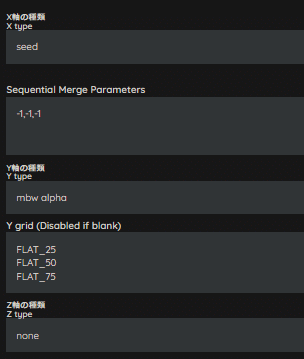

今回は、FLAT_25とFLAT_50の間くらいを狙っていきたいですね。
FLAT_25だとイラスト感が強く、FLAT_50・FLAT_75だとフォト感が強すぎます。
レシピの塩梅が見えてきたと思います。
0.25~0.5の間であとは調整をしていく感じになります。
続いて、大体半分の全階層0.35で生成してみましょう。
プリセットは用意されていませんので、私はMAGiCを使用してマージ記録をメモしています。


では、生成してみましょう。
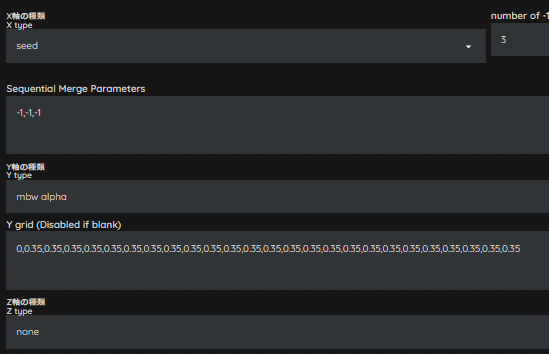

さっきよりは、大分イメージに近づいたような気がします。
人物はもう少しイラスト調に寄せたいですが、背景はこれ以上イラスト調にしたくないので、階層毎にWeightを変更していきます。
ここで、Mind1で説明した各層の要素が絡んできます。
人物に焦点を当てたいので、AttnBlockが存在する階層のWeightを変更していきます。
影響要素が多いUpSample層、かつattn要素が含まれるOUT03~OUT11までを0.25へ変更してみます。

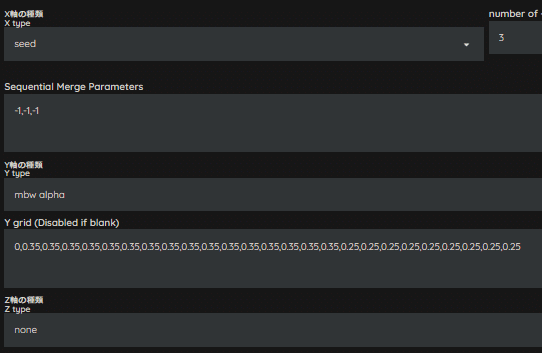

人物は微量ですが、イラスト調が強くなりましたね。
しかし、まだイメージしている人物像には達していません。
もう少しイラスト調にしたいので、再度レシピを見直します。
ResBlockにあるconv要素が影響しているかもしれないので、OUT05とOUT08のWeightをさらに下げて、0.15へ変更してみます。

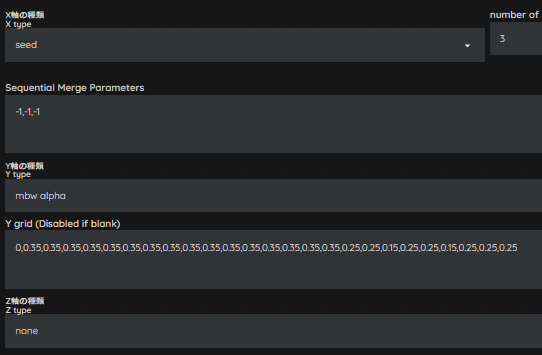

人物はイメージするものになりました!
微量な変化ですが、細部が変化しているのが分かります。
ただ、一つ問題が生じています。
背景が若干イラスト寄りになってしまっていることです。
人物はイメージ通りですが、背景も変える為に、再度階層マージをすると、人物・背景ともに複合的に変化してしまいます。
まずは、ここで一旦マージして、一時モデルを作成しておきます。
一時モデルは「Lastpiece_Mind_alpha」としています。

ベースモデルが複数ある場合は、この作業を続けて行っていきます。
今回は2モデルのみなので、次に進みます。
微調整マージ(Selfモード)
ここからは本格的に微調整になります。
以前は、Elemental Mergeを使用したりしていましたが、Super Mergerにて革命的なアップデート(Selfモードの追加)がありましたので、最近はこちらを使用しています。
Selfモードとは、モデル内の元々のパラメータをalpha倍するというものになります。
$$
theta_0[key] = theta_0[key] * alpha
$$
なので、特定要素を指定して、Elemental Mergeの要領で指定して、要素を強めることができます。
Selfモードの使い方としては、微調整したいModelをA、B同一にし、Weight Sum・Selfを選択、use MBWを無効、alpha=1にします。

あとは、XかY軸どちらかにelementalを指定して、Elemental Mergeの記載方法に則り、Weightはalpha倍率を指定します。
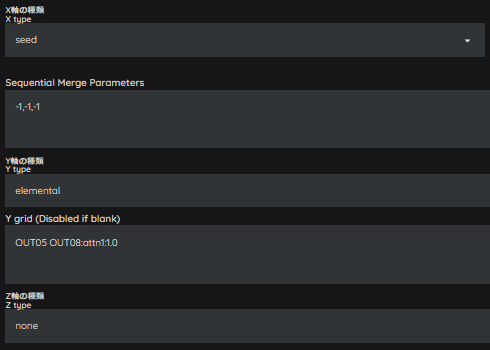
では、レシピを作成していきましょう。
今回は、Self Attention層を変更していってみます。
ひとまず、OUT05とOUT08の倍率を0.9倍してみましょう。
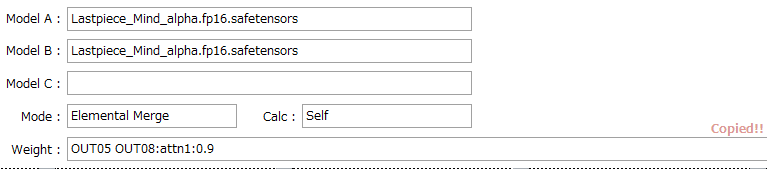
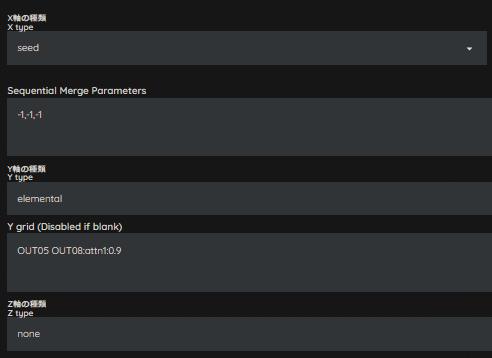

背景の光沢具合や質感が、だいぶイメージに近くなりました。
もう少し調整してみましょう。
次は、0.85倍で実施してみましょう。

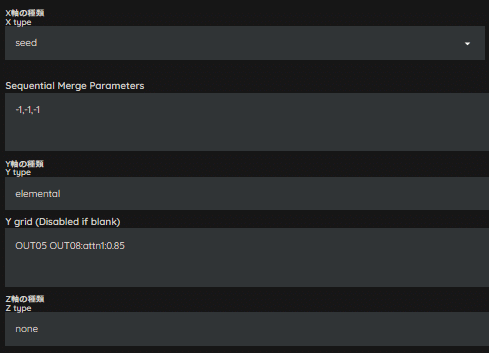

これでも大分良いですが、ちょっとイラスト感が薄くなったので、0.85~0.9倍の間で調整してみます。
0.88倍で試してみます。

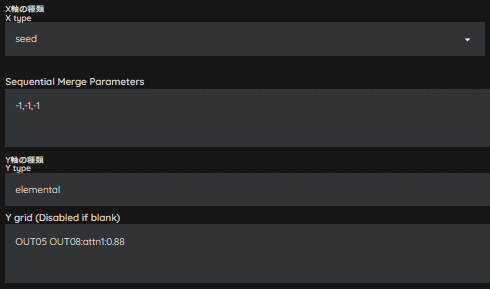

[ Selfモードの補足 ]
Selfモードの倍率は少し変えるだけで結構変わる印象があります。
大きい倍率にせず微量ずつ変化させたほうが良いです。
また、今回は減算方向への調整でしたが、加算方向側への調整も可能です。
かなりイメージ通りになりました!
これで打ち止めにしたいので、一旦マージを完了させます。
一時モデル名は「Lastpiece_Mind_beta」とします。

微調整マージ(Adjust)
続いて、色合いと描き込み量の調整に移ります。
今回はもう少しコントラストと色調を強く、描き込み量を少しフラットにしたいので、Adjustマージを使用して調整します。
Adjustとは?
モデルの描き込み量や色調を補正します。LoRAとは異なる仕組みを用いています。U-Netの入出力に当たる部分を調整することで画像の描き込みや色調を調節します。
elemental_ja.md - Adjust
Adjustの設定項目は以下になります。
/*
IN、OUT、OUT2 : 描き込み量/ノイズ量
CONT : コントラスト
COL1、COL2、COL3 : 色調
*/
adjust = IN, OUT, OUT2, CONT, COL1, COL2, COL3
Adjustの使い方としては、微調整したいModelをA、B同一にし、Weight Sum・normalを選択とします。
ここでは、use MBWとalphaの設定は、ひとまず気にしなくてもいいです。

Seedを固定しなくてもいいですが、変化量を確認する上では、固定した方が比較しやすいので、私は固定しています。
今回は、Seedを「1441085789」としました。

次に、X軸はalpha、Y軸はpinpoint adjustを指定します。
この項目はやってもやらなくても、どちらでも問題ありません。
マージモデルの変化量を要素別に確認する為なので、一度に変化を確認したい場合は、次へお進みください。
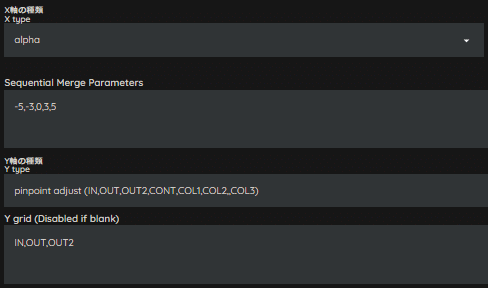
上図の例では、IN、OUT、OUT2、それぞれの変化量を確認しています。
以下では、それぞれの要素をPlot出力したものになります。



ここまでは、1要素ごとの変化でした。
次に、複合的に変化させてどうなるか確認してみましょう。
X軸はseed、Y軸はadjustを選択してください。
Adjustの記載ルールに則って、レシピを入れてみましょう。
今回は、Seedを「1441085789」、レシピは「0,0,0,-1,1,1,1」としました。
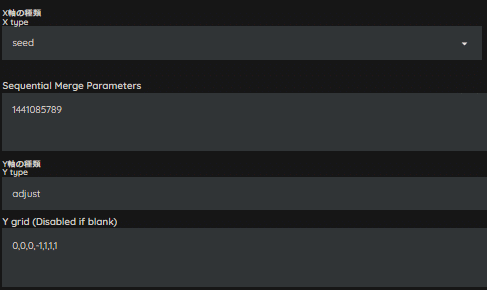

ここまでがAdjustの使い方です。
少し脱線しましたが、本題に戻ります。
今回は、色調とコントラストを少し強めに、描き込み量は少しフラットを目標にします。
上図のPlot画像を参考に、レシピを作ってみます。

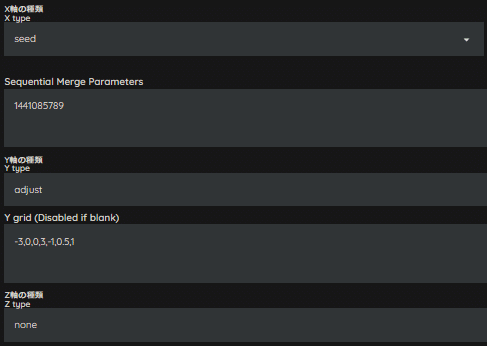
今回は上図のようにしてみました。
早速Plot出力してみましょう。

描き込み量は良いですが、色調とコントラストはもう少し強くしたいので、微調整を続けます。
コントラストを上げると、おのずと色調も強くなるので、コントラストのみ上げてみます。
CONTを「5」にしてみます。

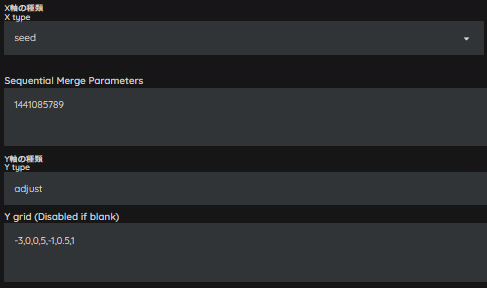

少し強くなりましたね。
もう少し強くします。CONTを「7」にしてみます。
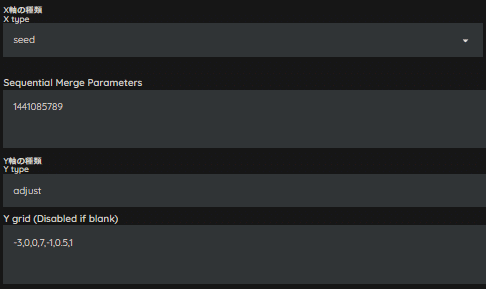


イメージ通りの色調とコントラストになりました!
ここまで来たら、最終段階です。
モデルを完成出力させましょう。
今回は、完成モデル名として「LastpieceMind」としました。

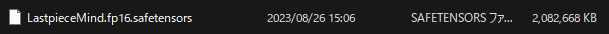
マージモデルが遂に完成しました!
早速、生成してみましょう!
Mind3 : 色んなシチュエーションで出力してみる
モデルが完成したら、様々なシチュエーションで出力してみます。
苦手な描写がないか、プロンプトの効きは大丈夫か、などを調べていきます。
私の場合、プロンプトを都度変えるのが面倒なので、Dynamic Promptsのワイルドカードを利用して調べるようにしています。
Dynamic Promptsの使い方については、今回は割愛させて頂きます。
では、今回のモデルをDynamic Promptsを利用して出力してみます!



大分いい感じになりましたね!
では、このモデルの推奨設定を調べていきましょう。
Mind4 : 推奨設定を調べる
ここからは、通常のX/Y/Z Plotで生成して、推奨設定を調べていきます。
調べる順序は好みがあると思いますが、私は以下の順序で調べてます。
Sampler
VAE
Hires Upscaler
CFG Scale
Denoising Strength
Step
Hires Step
Clip Skip
Hires Upscale
これと言った理由はありません…
ただ、いつも使ってる設定から、どの程度変化が生まれるかが比較しやすいので、最初は視覚的に影響があるものを行っていき、後半は前半の包括的な変化となりえるもの(例えば、サイズだったり、Samplerの収束だったり)を調べるようにしてます。
以下は、推奨設定を調べてる作業例です。
VAE

Sampler

おわりに
今回は、とーふ流のモデルマージ時のマインドをご紹介しました!
実際の作業内容だったり考え方は、あまり公開してる方がいないので、どんな感じで考えているのか、どうやっているのかというところが参考になればいいなーって思います!
私のやり方が一番いい方法という訳ではありませんが、皆さんのモデルマージの一助になれば嬉しいです。
これを機に、皆さんもモデルマージやりませんか?
いいなと思ったら応援しよう!
