
DALL-Eアーキテクチャは何故描写の崩壊が抑えられているのか?

はじめに
今、巷で高精細で描写の崩壊がしにくいと言われる、OpenAI社のDALL-E 3が話題ですね!
DALL-E 3の前身であるDALL-E、DALL-E 2で使用されているDALL-Eアーキテクチャと、現在主流になっているStable Diffusionは何が違うのかを説明していきたいと思います。
今回の内容は、比較的専門用語が飛び交うので、事前知識がないと「???」となるかもしれません。ご了承ください…。
事前知識はこちらをご覧ください。
DALL-Eとは
DALL-Eの読み方は「ダリ」です。
DALL-Eはシュールレアリスム画家のサルバドール・ダリが名前の由来になっています。
DALL-Eは現在も進化を続けており、非常に精細で描画の崩壊が抑えられていると話題になっています。
OpenAI社が提唱したDALL-Eアーキテクチャを使用して動作しており、自然な描写、フォトリアリズムに特化し、違和感を覚えさせない描写を実現しています。
また、同社の文章生成AIであるGPT-4とシームレスな連携を兼ね備えています。
DALL-Eの概要
DALL-Eは特徴はStable Diffusionベースのアーキテクチャではなく、独自のアーキテクチャを採用している点にあります。
また、DALL-Eも動作プロセス上でCLIPを使用しておりStable Diffusion同様、Transformerを利用しています。
使用されている学習モデルはOpenAI社が独自にPre-Trainedしたモデルであり、LAION等のデータセットが使用されているとされています。
しかし、同社の学習済みモデルは非公開であり、使用したデータセットの全容は不明ですが、インターネット上の大規模なデータを元にトレーニングされています。
このDALL-Eアーキテクチャは同種のDiffusionモデル(拡散モデル)であり、かつOpenAI社が開発した「GLIDE」を改良したものになります。
DALL-EアーキテクチャとStable Diffusionの違い
ここから、本題に入ります。
DALL-Eアーキテクチャは、Stable Diffusionと動作原理の根幹は一緒です。
まずは、Stable Diffusionのアーキテクチャについて簡単に触れていきます。
Stable DiffusionはLatent Diffusionが前身技術となっており、潜在空間における拡散モデル(U-Net)を利用して推論し、逆復号処理を経て画像を出力します。
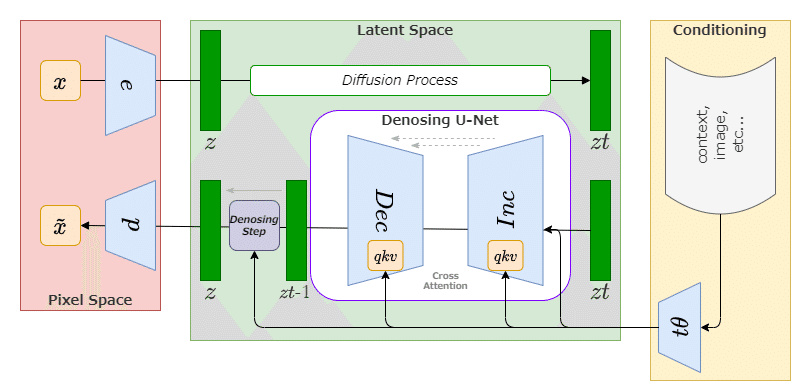
対して、DALL-Eアーキテクチャは事前分布を利用し、キャプションからある程度の画像特徴量を埋め込むプロセス経て、Decodingしています。
さらに、PromptからCLIPの画像特徴量を、CLIP画像エンコーダ部分で反転させて画像を生成することから、「unCLIP」と呼ばれています。

出典元:Hierarchical Text-Conditional Image Generation with CLIP Latents
https://arxiv.org/pdf/2204.06125.pdf
AR(自己回帰事前分布)またはPrior(拡散モデル事前分布)へ受け渡し、画像の埋め込み特徴を生成します。
この画像埋め込みが、Diffusion Decoder(拡散デコーダ)の条件付けに使用され、最終的な画像を生成、出力するものになります。
DALL-Eではこの拡散デコード部分を、GLIDEベースを使用して処理されています。
したがって、事前分布行うことで、画像表現を明示化することができ、写実性の向上とキャプションロス(キャプションの損失)を低減させることで、Stable Diffusionよりも精密で精細な画像を与える傾向を実現しています。
このことから、損失が少なく写実的な結果を得られるので、崩壊をある程度抑制出来ていると思われます。
しかし、このアーキテクチャにはデメリットも存在します。
写実性が向上することで、逆に独創性が低下してしまう恐れがあるということです。
ここで言う独創性の低下というのは、画風や構図が類似するという意味ではなく、普遍的でクリエイティビティさが損なわれる可能性があるという意味になります。
2023.10.11追記
新清士氏のポストにて、元画像と類似する可能性がある点が指摘されました。
記事執筆時は、「写実性の向上をすることで、独創性が低下してしまう恐れがある」という推測を立てていました。
その推測は得ていたようですが、「画風や構図が類似するという意味ではない」という点については、本ポストの結果より懐疑的になりました。
予想以上に元画像に類似する生成物を出力する恐れがあるかもしれませんので、訂正致します。
DALL-E3で「写実性が向上することで、逆に独創性が低下してしまう恐れがある」とされている現象に、もしかしたら近い現象なのだろうかというのに出会った。ジャングルで豚が車を襲っているという冗談めいた画像を分析させて、そのプロンプトで生成させたところ、平和な感じだったので、T-Rexのように凶… https://t.co/NL78wOFMi9 pic.twitter.com/xiajoJKmWM
— 新清士@(生成AI)インディゲーム開発者 (@kiyoshi_shin) October 11, 2023
Stable Diffusion-UnCLIP
ここまで、unCLIPなどはOpenAI社独自の技術である、という風に見えていましたが、実は、StabilityAI社もunCLIP処理について提唱しています。
Stable Diffusion v2.1ではUnCLIPモデルがあり、StabilityAI社では「Stable diffusion Reimagine」と呼ばれています。
こちらも非常に精密で精細、かつ写実的な出力が得られます。
補足
ここで今から補足する点は、とても重要です。
「元画像の特徴量をベースに、CLIP画像埋め込みを生成し条件付けを行う」ということから、「元画像を参考にしてimg2imgをしていると同義ではないか」と思う方がいらっしゃるかもしれません。
それは間違った認識ですので、補足させて頂きます。
img2imgは画像の特徴を潜在空間へ受け渡すのに対し、今回のAR及び拡散モデル事前分布によって得られる画像特徴量というのは、CLIPで学習したキャプション+画像から、事前に特徴のベクトル量を予想立てて条件付けを生成する為、元画像の構図や画風、人物像等をそのまま受け渡すわけではなく、「〇〇という言葉は〇〇である」という概念に近いものを事前に把握する意味合いが強いです。
人間的思考で言えば、「〇〇ちゃんって誰?」という会話(キャプション)を得たときに、記憶している内容から、その方の顔や特徴を思い浮かべると思います。
その際、構図や時間帯、思い出す事柄はバラバラだと思います。
つまり、AIにおける事前分布は、この人間的思考の挙動に近く、数多くの学習内容から特徴量を求め、画像埋め込みを作成している為、単一画像を条件に特徴を得ているわけではありません。
総論
DALL-Eアーキテクチャ及びStable diffusion Reimagineについては、一言で言うと「学習した元画像の特徴量に近い画像を再生成するもの」という意味合いが強いかもしれません。
故に、写実性の向上が見込まれている、ということになります。
なので、従来のStable Diffusionモデルでは、多くの物体の複雑な重なりや指、細い物体の描写など、畳み込みネットワークで処理されていた為、苦手とされていましたが、この部分を事前分布とunCLIPにより、その物体の特徴量の精度を上げることができ、より写実的に推論することができるようになったと思われます。
おわりに
今回は、今巷で話題のDALL-Eの仕組みについてお伝えしました!
ちょっと専門的な部分が多くて、取っ付きにくい部分があったと思いますが、概念的な部分もあるので、文章でお伝えするのがすこぶる難しいんです…。
DALL-E 3の人気が凄く、生成待ちの時間も長くなってきました。
まだDALL-E 3を触ったことがない方は、是非この機会に生成してみましょう!
DALL-E 3 APIを利用して提供しているサービスはこちら!
参考文献
*1
Hierarchical Text-Conditional Image Generation with CLIP Latents
Submission date : Wed, 13 Apr 2022 01:10:33 UTC
Submit From : Aditya Ramesh
https://arxiv.org/abs/2204.06125
*2
Zero-Shot Text-to-Image Generation
Submission date : Fri, 26 Feb 2021 23:26:05 UTC
Submit From : Aditya Ramesh
https://arxiv.org/abs/2102.12092
この記事が参加している募集
よろしければサポートお願いします!✨ 頂いたサポート費用は活動費(電気代や設備費用)に使わさせて頂きます!✨