
AIを使ってXMLを「復権」させる(中編)

前回の記事で、XMLというデータ形式がもつ可能性について紹介しました。
今回は、XMLのちょっとした応用を考えてみます。その上でXMLの可能性・弱点・その克服とさらなる発展の可能性について考察を進めていきます。
XMLでデータベースを作る
私はそのうち小説を書いて出版したいという野望を持っています。
壮大な設定に裏打ちされたラノベの長編連作を世に問いたい。
それには、ネタのしっかりした管理も重要でしょう。ストーリーを作ったはいいが、既に過去のエピソードで戦死したはずのキャラを未来のバトルに登場させたりしたら目も当てられません。
魔法の体系とかも整理しておきたいですね。神聖魔法に精霊魔法、それぞれの魔法に火属性とか水属性とか土属性とかあり、水属性の魔法は火属性の魔法より強かったりするのです。そういう複雑な話を作家が自分の頭の中だけで整理できているはずがありません。
コンピューターが必要です。そして、データベースです。
データベースといってもいろいろ。ペライチのCSVファイルで充分な事例もあるでしょうが、少し本格的なものを考えるならエクセル・アクセス・PostgreSQLとかいろいろなアプリを使って構築することが多いでしょう。
しかし、様々な要素を勘案するに、上記の目論見に資するにはXMLデータベースこそ最適と思われるのです。
テストケース
いきなりラノベ創作となるとさすがに荷が重いので、とりあえず既存かつ単純な物語を題材に、お試しで小さな登場人物データベースを作ってみましょう。
「桃太郎」の登場人物を独自設計のXMLデータの形で纏めてみました。だいたい下のような形になります。
<?xml
version="1.0" encoding="UTF-8"?>
<db xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="chars.xsd">
<chars>
<item id="momotaro">
<name>桃太郎</name>
<gender>男</gender>
<desc>
桃から生まれた強い子。 鬼ヶ島に鬼を退治に行く。
</desc>
</item>
<item id="inu">
<name>犬</name>
<gender>男</gender>
<desc>
桃太郎に黍団子を貰って子分になる。一緒に鬼を退治に行く。
</desc>
</item>
<item id="saru">
<name>猿</name>
<gender>男</gender>
<desc>
桃太郎に黍団子を貰って子分になる。一緒に鬼を退治に行く。
</desc>
</item>
<item id="kiji">
<name>雉</name>
<gender>男</gender>
<desc>
桃太郎に黍団子を貰って子分になる。一緒に鬼を退治に行く。
</desc>
</item>
</chars>
<rels>
<item id="momotaro_inu">
<char1>momotaro</char1>
<char2>inu</char2>
<type>
家来
</type>
</item>
<item id="momotaro_saru">
<char1>momotaro</char1>
<char2>saru</char2>
<type>
家来
</type>
</item>
<item id="momotaro_kiji">
<char1>momotaro</char1>
<char2>kiji</char2>
<type>
家来
</type>
</item>
</rels>
</db>ここで扱っているのは、登場人物の個別データと、登場人物間の関係性についての情報。これらをそれぞれ、chars, rels要素として表現しています。
使ってみよう
情報がXMLデータベース化できると何が嬉しいのか?それをみるために、さっそく利用してみましょう。
ここでChatGPTの登場です。XMLデータベースファイルをChatGPTにアップロードしたうえで、いくつか質問をしてみます。
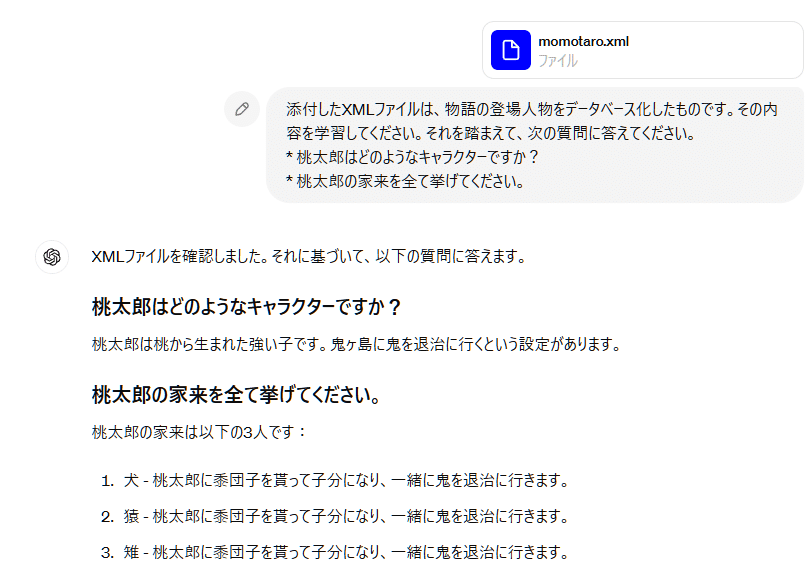
XMLデータをちゃんと学習してくれていますね。
情報を取り出すにあたって、ややこしいメニューを辿ったり、難解なSQLとかVBAのマクロとかに頭を悩ます必要はありません。日本語で問い合わせれば事足りるわけです。これだけで既にアドバンテージですね。
データベースに直接書かれていない情報を出してもらう
もう少し高度な質問をしてみましょう。
簡単なルールを提示し、データを活用した「推論」をさせてみます。

データベースに直接記載しているのは「子分」の情報だけです。しかしルールを与えることで「親分」について答えさせることが出来ました。
データベースに直接書かれていない情報をもっと出してもらう
更にルールを追加して、より高度な推論をしてもらいます。

こんな感じで、データベースに直接記述されていない事項を、XMLデータとChatGPTの力を組み合わせることで導き出せるのです。
百人のキャラが登場する大戦争の物語の中で細かなエピソードを繋ぎ合わせていきたいとなったとき、このようなツールが使えることの意義は大きいはずです。
XMLをデータベースに利用する意義
データベースの基盤をXMLにする利点は色々挙げられます。
フリーテキストが簡単にDB化できる。
始めにレコード構造を厳格に決めておく必要は無く、個々のデータ構造を柔軟に調整できる。データ間に構造の違いがあっても差し支えない。
階層構造を持つデータを無理なく表現できる。
強力なXMLデータ対応ツールが応用可能。
ただ、大きな弱点があった
上記のように、XMLには様々な長所があります。しかし、HTMLほどあまねく普及しているという感じではないですね。何故でしょう。
端的に言えば、作成や運用が面倒だったのですね。
アプリの設定や情報交換にXMLに代わって良く使われているのがJSONです。見比べてみれば、JSONが極めてシンプルで与し易し、XMLより便利となるのは無理がないところではあります。
また、前記事で説明したとおり、XMLの作成や利用に関しては、XPathやXML Schemaという強力で有用な仕組みがあります。とはいっても、それをマスターするにはそれなりの根気が必要なのも確かでした。使いこなすまで行けずに学習途中で挫折した人達もいたでしょう。
XMLには、ウェブブラウザにおけるHTMLのような緩さがありません。いくら柔軟な構造が定義できるといっても、その定義からちょっとでも外れるとたちまち文句を言われて先に進めなくなるのがXMLの世界です。
こういうところから、なかなかその筋のプロ以外には敬遠されるところがあっただろうと思います。
しかし、その面倒な部分の多くを今やAIに肩代わりさせることができるのです。そして、強力な入力支援機能を備えたVScodeのような優れたツールも登場しています。もはやXMLの弱点は克服されつつあります。
次回予告
XMLの面倒くさい所をどうやって克服するのか。データの保守管理そしてさらに高度なデータ利活用をどうやって成し遂げるのか。引き続き「登場人物XMLデータベース」を見ながら考えていきたいと思います。