
自動で文字起こししてエクセル形式で保存する~Amazon transcribeを使うときのTips

このnoteでは、AWSを用いた文字起こしの方法についてまとめます。文字起こしは議事録製作やインタビューなどで必要になりますが、外注すると高い、全部自力でやると恐ろしく面倒、ということでなるべく自動化したいところ。そのために、ここではAWSのAmazon transcribeという文字起こしサービスを使います。
このサービスは発表直後こそ話題になったものの、データ形式がどうにも使いづらく、なんだかんだとあまり使われていない印象でした。エクセルのような形式での手軽なダウンロードができず、.jsonという形式でのダウンロードしかできなかったために非エンジニアには使いづらかったわけです。それでほとんどどうしようもないような文章形式の文字起こしだけが生まれていました。

このnoteは、このどうしようもないデータを、とりあえず綺麗なエクセルデータにするためのTipsです。もちろん文字起こし自体の精度もあるのですが、こうした形式になればある程度綺麗に文字おこしする対象も絞れるし、内容の概要はつかめます。また、綺麗な文字起こしをつくるためのたたきにもなるでしょう。
この作業のステップ、はじめは面倒に思えますが一度やってみると2回目はとても楽になります。
実はjsonをcsvにサッとコンバートするサービスも多くあるのですが、Amazon transcribeの形式が合わないのか量が多いからなのかあまりうまくいかないことが多かったです。うまくいったと思ったらデータがオーバーしていて課金制だったり。
また、サーバーに全文データをそのままアップするものは文字起こしでは向かないことも多いと考えられるし、ブラウザで処理しようとして展開すると文字起こしのデータは重くてブラウザがとまったりもしました。いろいろとやり方はあり得ると思うのですが、このnoteではちょっと強引ではありますが非エンジニアでも特にストレスなく進められる方法をまとめました。
➀Amazon transcribeからjsonファイルをゲットする
Amazon transcribeを開く。
まずはAmazon transcribeを開くところからスタートします。
アカウントなどを登録すると、jobを作るというのがあると思います。そこを開くと、「S3からファイルを選んでね」というのが出てくると思います。



S3というのは簡単にいえばストレージのようなものです。なので、①S3にファイルをアップし、②Amazon transcribeからそのファイルを参照して処理する、という流れになります。ここにファイルをあげておけば、いろんなAWSのサービスでそのファイルを使うことができるようになります。S3のページに移動してファイルをさくっとアップしましょう。
手順は簡単で、①まずバケットと呼ばれるフォルダのようなものをつくり、②そこにデータをアップする、だけです。

文字起こし作業を開始する
S3でデータをアップできたらAmazon transcribeに戻り、文字起こし作業を再開します。Create jobからはじめます。途中の設定では言語を日本語にし、複数人数がいる場合にはAudio identificationをオンにしておいてください。

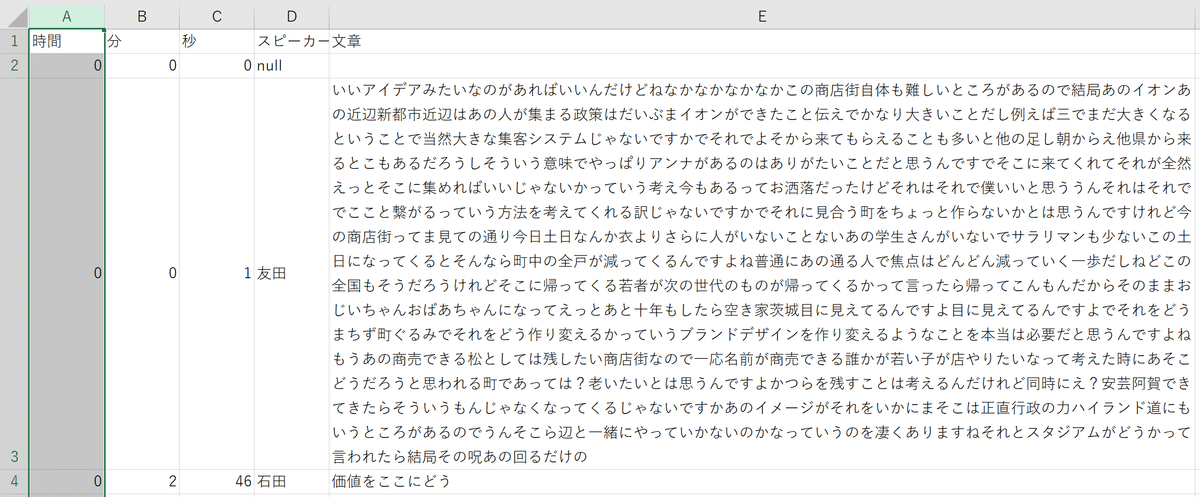
少し時間がかかってファイルができあがります。出来上がったファイルをみると、おおよそそれなりに文字おこしができているのがわかります。しかしまだどうにも使いようがありません。
ファイルをダウンロードすると、jsonというファイル形式でファイルがゲットできます。ファイル名は「asrOutput.json」となるかと思います。データを整理できるファイル形式なのですが、非エンジニアにはとかく扱いづらい。ここまではなんとかきたけど、よくわからずに辞めてしまった人も多いかもしれない。ここから、かなり強引にエクセルファイルに仕立て上げていきます。
②その後、transcript.pyでtxtに変換する
ダウンロードしたjsonファイルを綺麗にし、csvに変換していきます。そのために、コードをかかずにプログラムを使います。
②-1:Spyderをインストールする。
Pythonを使いますが、ややこしいことは何もしないので、とりあえずAnacondaをインストールしてください。するとSpyderというアプリが入っているのでこれを開きます。ややこしい!と思われるかもしれませんが、Pythonなどを使うときにあると便利なのでいれておきましょう。何も考える必要は特にありませんのでご安心ください。
https://www.anaconda.com/products/individual
②-2:transcript.pyと.jsonを同じフォルダに入れる
今回は、trhrさんが作ってくださっている変換のPythonスクリプトを活用します。jsonをテキストファイルに変換するプログラムです。
以下のリンクからZipでファイル一式をダウンロードします。とりあえずダウンロードしましょう。
解凍したら、好きな場所に新しいフォルダをつくってAmazon transcribeからダウンロードしたjsonファイルとtranscript.pyファイルを同じフォルダに入れます。

②-3:Pythonのファイルを動かす。
先ほどインストールしたSpyderを起動して「Open file」から、transcript.pyファイルを開きます。開いたら、一点だけ変更します。ファイル名だけ、
filename=sys.argv[1]を、
filename="asrOutput.json"にしてください(要するに、"(jsonのファイル名)"となればOK)。元のでもうまくいくかもしれませんが、変えとくと安心です。

そしてSpyderの左上の「再生」ボタンを押します。すると、jsonファイルがテキストデータとして整理されて出力されます。ファイルは、jsonファイルとpyファイルをいれておいたフォルダの中につくられます。
コードがかかわってくる作業はここで終わりです。
③Wordの置換機能でデータを修正
作成されたtxtファイルをメモで開いてWordに張り付けてしまいましょう。

このファイルを、ここからcsvの形式に変換していきます。csvは基本的には「a,b,c」というようなコンマと改行で表現されます。変換はWordの「置換」という機能をもちいて行います。ちょっと荒業です。
検索ボックスで「置換」と打ち込み置換ダイアログを開きましょう。

いくつか細かい置換をするので、詳細設定から「あいまい検索」のチェックを外してください。そしてデータをcsvの形式にするために、次の7点についてデータを修正します。
➀変な半角スペースを消します:「(半角スペース)」→「(空白)」
②行のあきを消します:「^p^p」→「^p」
③データをcsv形式に近づけます:「[」→「(空白)」
④データをcsv形式に近づけます:「]」→「,」
⑤データをcsv形式に近づけます:「:」→「,」
⑥「spk_0」→「(話者名)」←任意
⑦「spk_1」→「(話者名その2)」←任意
ここまで変換できたら、テキストをコピーし新しくメモに貼ります。↓こんな感じになっているはずです。

④メモ帳にテキストをはり、CSV形式で保存する
作成したメモ帳に貼られたテキストを、.csvファイルで保存してください。メモ帳の選択肢からcsv保存の選択肢はでてこないので、自分で「(ファイル名).csv」とうち、保存します。

このとき、文字コードの形式が元の形式とエクセルの読み込みの形式で異なり、文字化けを起こすので、保存ダイアログにでてくる「文字コード」を「UTF-8」から「ANIS」に変えておいてください。
⑤あとはちょこちょこ修正する
できあがったcsvファイルをエクセルで開いて確認します。綺麗にできていたらひとまず作業は終了です。

とはいえ、そもそもの文字起こしのクオリティでうまくいっていない箇所もあるので、必要なレベルで修正します。まだまだAmazon transcribe自体の文字起こしのクオリティもそのまま使えるほど十分なほどには高くはありませんが、おおよその内容をつかむには十分です。また、今後の改善も期待できるでしょう。
最後に:どこで工夫するか
Amazon transcribeを活用するためのTipsでした。
文字起こしには、さまざまな工夫のポイントがあると思います。あらかじめしっかりとシステムや発話する場の状況を設定をして「Group Transcribe」を用いてみたり(案外けっこうつかえます)、Google meetやZoomでのリアルタイム文字起こしを活用してみたりするといった、AWSをつかわない選択肢もあるでしょう。ちなみに、Wordをローカルのアプリでなくchromeで開くと、音声ファイルの文字起こしができます(ディクテーションタブからできる)。これも便利ですが、ややクオリティがAWSより低いかな、という印象です。あるいはマイクなどを工夫する余地もあると思いますし、しっかりと発声するなどの工夫もよいかもしれません。
文字起こしはある程度必要になる一方でけっこうコストが高い作業なので、さまざまな工夫を重ねながら、場面や状況に応じて適切に対応できるといいのかな、と思います。
(終わり)
いいなと思ったら応援しよう!
