
【STATA Techs-004】ヒストグラムと散布図

THEME:ヒストグラムと散布図
GOAL:STATAでヒストグラムと散布図を作成できるようになる
◯サンプルデータ◯
◯使用コマンド◯
histogram varname
:変数のヒストグラムを表示
※「hist」だけでも可
twoway scatter varname varname
:2変数の散布図を表示
※「scatter」だけでも可
※ varname varnameはY軸、X軸の順でコマンド
twoway scatter varname varname, jitter(#)
:プロットを#%分ぶれさせた2変数の散布図を表示する
※「scatter」だけでも可
※ varname varnameはY軸、X軸の順でコマンド
twoway scatter varname1 varname2,|| lfit varname1 varname2
:varname3とvarname4の単回帰線がひかれた2変数の散布図を表示する
※「scatter」だけでも可
※ varname1 varname2はY軸、X軸の順でコマンド
※ 「lfit varname1 varname2」は他の変数でも可
twoway scatter varname1 varname2 if d_varname==0 || scatter varname1 varname2 if d_varname==1
:d_varname(ダミー変数)が0をとるか1をとるかで色が異なる散布図を表示する
※「scatter」だけでも可
※ varname1 varname2はY軸、X軸の順でコマンド
◯やり方◯
①ヒストグラム
ヒストグラムとは、量的データの度数分布をグラフで表したもので、縦軸は度数、横軸は階級を表します。Excelでは度数分布表をfrequency関数を使用し作成した上でヒストグラムを作りますが、STATAでは以下のコマンドで返されます。
では、「income」のヒストグラムを作ってみましょう。コマンドは以下の通りです。
histogram income
ヒストグラムのコマンド要素
histgram varname, OPTION
<OPTION>
・freq:横軸を標本数に設定
・percent:縦軸を比率(パーセント)にする
・width (X):ヒストグラムの縦棒のデータ幅の大きさをXの値だけ大きくする
・start(Y):横軸をYの値からスタートさせる
・by(Z):カテゴリー変数Z毎の図を作成
例)hist varname, freq width(3) start(0) by(year)
=「yearごとに3刻みで横軸を0からスタートさせたvarnameのヒストグラムを作成せよ」
コマンドすると、上のような表が表示されます。ヒストグラムの特徴をみてみましょう。「【STATA Techs-002】データの要約」で歪度、尖度を扱いましたが、推定値は、歪度が4.8、尖度が38.8でした。確認ですが、歪度は分布が正規分布からどれだけ逸脱しているかを表す統計量で、左右対称性を示す指標です。分布の山が左にずれて裾が右に伸びているときは正の値を、山が右にずれて裾が左に伸びているときは負の値をとり、正規分布では0となります。今回のヒストグラムは、山が左にずれて裾が右に伸びている歪度4.8の分布であることがわかります。
次に、尖度は、分布が正規分布からどれだけ逸脱しているかを表す統計量で、山の尖り度と裾の広がり度を示します。3未満のときは尖りが緩やかで裾が短く、3より大きいときは尖りが急で裾長に。正規分布では3となります。今回のヒストグラムは、裾が広く、尖度が38.8の分布であることがわかります。
②散布図
次に、散布図を作ってみましょう。今回は修学年数(「eduyear」)を使ってみます。サンプルデータのeduyearは欠損値(「99」)を含むので、このままでは使えません。欠損値は無回答などの観測不可の回答のことを指します。また、STATAでは原則として元の変数はいじらずに、加工・処理用の変数を作成した上で新変数を加工するといった形をとります。従って、一度「eduyear2」というeduyearのコピー変数を一度作成し、eduyear2の「99」を欠損値処理した上で、eduyear2とincomeの散布図を見ていきましょう。コマンドは以下のとおりです。
gen eduyear2 = eduyear
recode eduyear2 99=.
twoway scatter eduyear2 income
これで一旦は散布図が作成できました。しかし、eduyear(2)は中卒(「9」年)、高卒(「12」年)、大卒(「16」年)、大学院卒(「18」年)に集中しているので、みにくくなっています。これを解決するために、どれだけ密集しているかを確認するコマンドがあります。先ほどのコマンドに、「, jitter(#)」を加えると、#%分、サンプルがぶれた散布図が作成されます。jitter(5)だと5%、, jitter(10)だと10%ずれます。今回は10%ずらしたものを作成しましょう。コマンドは以下のとおりです。
twoway scatter eduyear2 income, jitter(10)
これで大卒にサンプルが集中していたことがわかりました。
次に、散布図を男女別に色分けしてみましょう。このコマンドは指定のダミー変数(0か1をとる2値データ。今回はd_sex)が0をとるのか1をとるのかで散布図を色分けできます。また、ダミー変数だけでなく、コマンドに加えていけば、さらに色分けすることが可能です。コマンドは以下のとおりです。
twoway scatter eduyear2 income if d_sex==0, jitter(10) || scatter eduyear2 income if d_sex==1, jitter(10)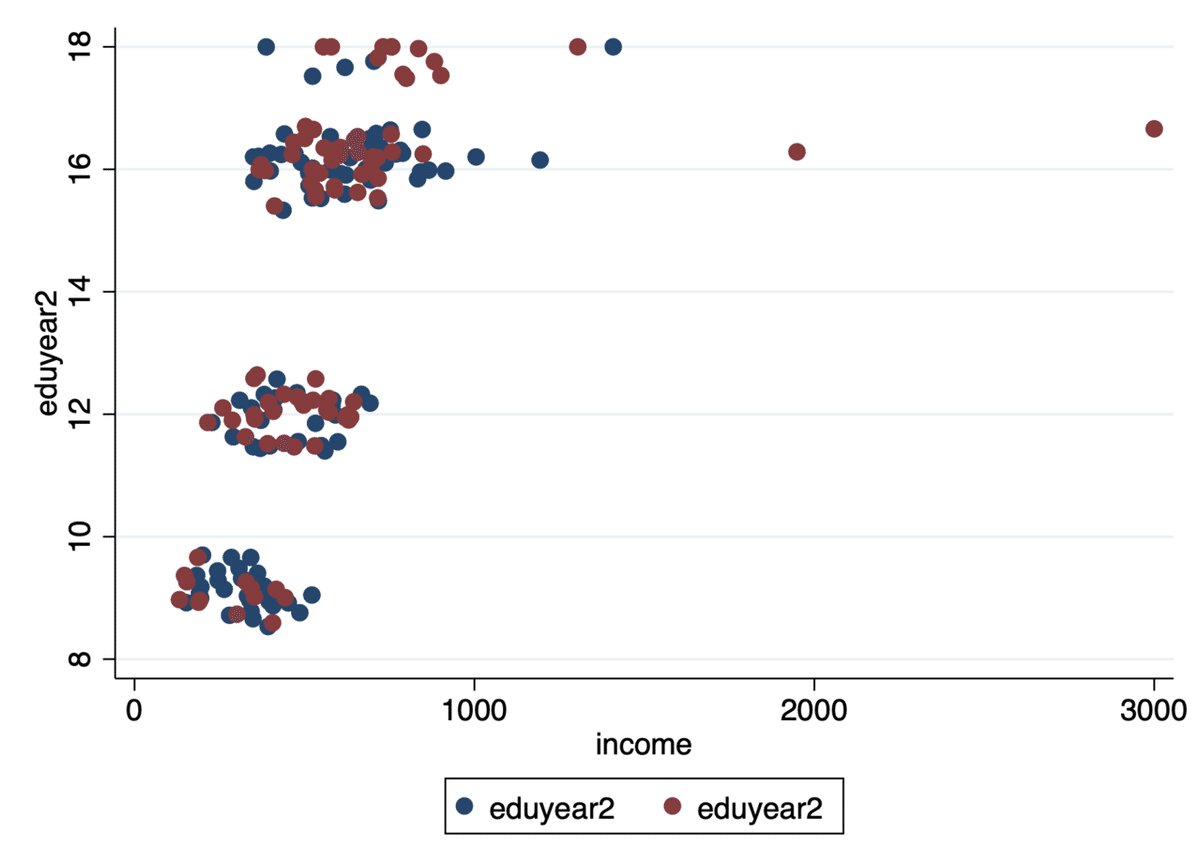
先のコマンドは、「twoway scatter eduyear2 income if d_sex==0, jitter(10)」の部分と、「scatter eduyear2 income if d_sex==1, jitter(10)」の部分で分かれていて、この2つを「||」が区切っています。「if d_sex==0」は「d_sexが「0」をとる場合色を別にする」ことをコマンドします。「if d_sex==1」も同様です。今回は、d_sexが「0(男性)」が青、d_sexが「1(女性)」が赤で色付けされています。これでみやすい散布図ができました。
最後に、散布図に単回帰線を引いてみましょう。単回帰分析に関しては別記事で取り扱います。コマンドは以下のとおりです。
twoway scatter eduyear2 income,|| lfit eduyear2 income
======
本田恒平(Kohei Honda)
一橋大学大学院経済学研究科博士後期課程(政治経済学、労働政策)
▼質問やご意見等はコメントかホームページのフォームから▼
▼SNS▼
Twitter: https://mobile.twitter.com/4strings725
Facebook: https://www.facebook.com/profile.php?id=100002374515435