
【W8】タンパク質データの取得_05_Step2_02_Query2RCSB

【W8の目的】
(i) PDBデータベースからEGFRの全てのPDB IDを取得し、
(ii) X線結晶構造解析による構造で、最も質の良い4つのタンパク質ーリガンド複合体構造を取得して保存します。
Python版はより発展的です。
前回からデモデータを使ってW8のStep2を見始めました。
Step1で得られた
EGFRに関する156のPDB IDを用いて、

Step2では

PDB IDをキーにPDBから必要なデータを取得するため、まずは左端のColumn ExpressionsノードでGraphQL形式のクエリを作成しました。
以下余談ですがそもそも「クエリ」って何と 訳すんだっけと思って読みました。
https://wa3.i-3-i.info/word11290.html
リンクはいいけど転載は控えて欲しいとのことですので私の感想を述べますと、クエリはクエリであって、代わりの単語ってあまりないんですね。強いて言うなら「問い合わせ」。
今回作成したクエリの一つを例に挙げると
{ entry(entry_id: "2RGP") { pdbx_vrpt_summary { PDB_resolution } nonpolymer_entities { pdbx_entity_nonpoly { comp_id } rcsb_nonpolymer_entity { formula_weight } } } }entry_id: が”2EB3"の{PDB_resolution}と{comp_id}と{formula_weight}を問い合わせています。
pdbx_vrpt_summaryやnonpolymer_entities { pdbx_entity_nonpolyなどの文字列は各データがPDBデータベースのどこに格納されているかを指定しています。
ただ、このクエリだけではまだ検索は出来ません。データベースのURLを指定しなければならないからです。
URLって今更ながら何だっけと思ったら下記ご参照ください。
https://wa3.i-3-i.info/word114.html
【Column Expressionsノードおかわり】

設定:
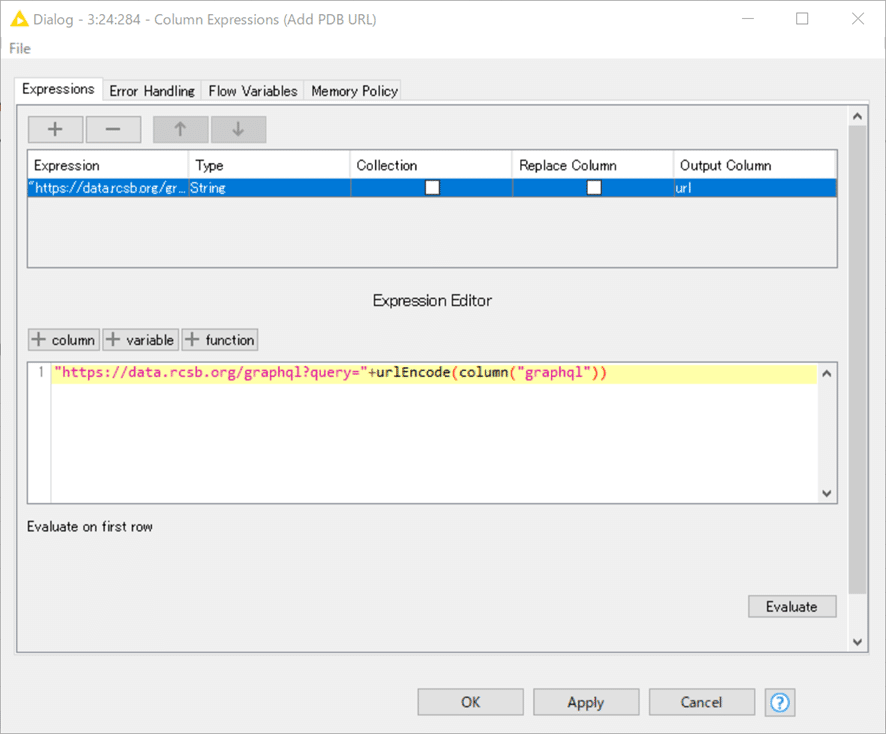
クエリをどこに投げたらいいかを指定するためには
"https://data.rcsb.org/graphql?query="+urlEncode(column("graphql"))
すなわち、RSCBの提供しているGraphQLのサイト(https://data.rcsb.org/graphql/)へ
URL形式でクエリ文字列をつけてあげたらいいのです。
結果:156個のURLが完成しました。

1行が画面に収まりきらないし、もはや人に読みやすい記述にはなっていないです。黄緑色でマークしたPDB ID部分以外は156行すべて同じ文字列です。こういった変換をノード一つで実装できるのはありがたいですね。
また、今回あえてColumn Expressionsノードを2つに分けて段階的に処理して下さっているのは、URLの作成方法が理解しやすいようにと教育的配慮して下さったのだと推測します。
【RCSB探訪】
さて、W8には下記の通り注釈があります。

Step1と2はRCSBのサイトが変わったので、それに合わせて改良されたWFになっているのだそうです。
先日紹介した通り今はさらに改変があったのか、WFが一部動作しないですね。
Step1ではUniPlotIDを変えたら他のたんぱく質のデータが入手できますし、Step2ではクエリの文字列を編集すれば欲しい情報を指定できるとあります。
前回も思ったのですが、このクエリを自分の思い通りにカスタマイズするのはかなりの理解度が必要な気がします。
少しは勉強してみようと、上記の助言に従ってRCSBのサイトを観に行ってみました。
…正直言って、「ムリ」って思いました。初心者にはきついです。
一方で、PDBが玄人のどのような質問にも答えを用意しようと言う真摯な姿勢には感服しました。このサイト、本当に情報量が多いです。いったい何人の方々が何年かけてここまで築きあげられたサイトなのでしょうか。
蓄えられ続けるデータ群と進化し続けるシステムは一つの人類の叡智の集積であると思いました。
さて、ただ眺めて感心しているだけだと先に進めないですね。ごく一部のみGoogle翻訳して引用します。
core_entry:PDBエントリに関連するデータ。4文字のpdb_idで識別されます。
core_polymer_entity:PDBエントリ内の各高分子分子エンティティのデータ。によって識別されます_
core_nonpolymer_entity:PDBエントリ内の各非ポリマー分子エンティティのデータ。によって識別されます_
core_assembly:PDBエントリ内の各生物学的アセンブリのデータ。によって識別されます-
core_polymer_entity_instance:チェーンとも呼ばれる特定の高分子分子エンティティのインスタンス。によって識別されます。
core_chem_comp:化学成分。3文字のchem_comp_idで識別
上記を見ると、自分が欲しい情報がどのエンティティにありそうかの推測ぐらいはできるかもと思いました。
エンティティって何だと思った方はこちら。
https://wa3.i-3-i.info/word17504.html
ブルース・リーの教えを知ることができます。
(参考動画)
遊び始めてしまったのでそろそろ次回へ。
おまけ:
【おすすめのIT用語辞典】
PCS運営の下記サイト、いつもお世話になっております。
https://wa3.i-3-i.info/index.html
IT用語を平易に説明して下さるのみでなく、コラムも素敵です。
https://wa3.i-3-i.info/column78.html
引用しすぎはダメでしょうが、エッセンスだけならと最近心ひかれた言葉を借用します。
始める前の合言葉:「やらないより百倍マシ」
始めるときの合言葉:「ダメだったら止めればいい」
始めてからの合言葉:「どーせ、やるなら」
前回KNIMESTとしてのこの1年間の活動を振り返ったのですが、上記の言葉が実にしっくりするのです。
KNIMEもケモインフォマティクスも世に玄人さんが優れた情報発信をして下さっているので、もし私が先に勉強して玄人になってからなんて考えていたら…。
始めてみて、人様に説明するためにと学んだ時間は学習効率が高かったように思います。いわゆるアクティブラーニング(機械学習でなく教育の方です)を自分で体験することになりました。
間違えた問題を正しく見直すのも重要なそうなので、間違いを恐れすぎないで発信し、気付いた間違いは素直に学びの機会とできたらとあらためて思っています。
皆さんにお願いです。おそらく既に私は間違ったことを書いてきていると思うのですが、自分では気づけないでいるのではと不安です。
DMなどへこそっとお知らせいただける方、大歓迎です。何卒!
いいなと思ったら応援しよう!
