
Pythonライブラリ(SQL):sqlite3

概要
Pythonの標準ライブラリでSQLを使用できるsqlite3を紹介します。SQLとはデータベース(以下DB)を操作するための言語です。sqlite3はRDBMS形式でありテーブルと呼ばれるExcelみたいな表形式に近い形で操作できます。
sqlite3は大規模向けではなくプロトタイプや小規模向けとのことです。

sqlite3はPythonライブラリですがクエリはSQL文法で記載が必要ですが本記事ではライブラリの記法がメインのためSQL文は説明しません。
1.基本操作1:DBの接続/切断
1-1.DB接続/作成:sqlite3.connect(path)
sqlite3はSQLの「CREATE DATABASE <DB名>」という操作はなく、dbファイルでDBを管理します。DB接続はsqlite3.connect(filepath)です。もし指定パスにファイルがなければ新規作成となります。
[In]
import sqlite3
path_DB = 'note_sqlite3.db' # DBファイルのパス
conn = sqlite3.connect(path_DB) # DBに接続/新規作成
conn
[Out]
<sqlite3.Connection at 0x18d8c530d50>
1ー2.DB切断:conn.close()
DB接続を切断する場合はconn.close()を使用します。DB接続中はメモリを使用するため基本的に処理完了後にDBは切断します。
[In]
conn.close()
[Out]
メモリを開放して、これ以降のDB操作はできない(操作する場合は再接続が必要)2.基本操作2:DB操作
前章で作成したDBの操作を紹介します。正確には異なるのですが全体的なイメージは下記としています。
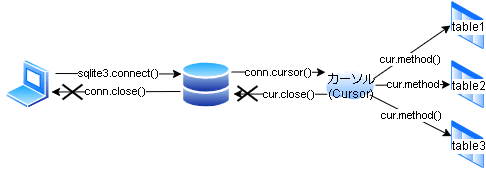
2-1.カーソル取得(Cursor):conn.cursor()
DB接続後は直接SQL処理するのではなくCursorと呼ばれるオブジェクトを作成して、Cursorを使用してSQL操作します。
[In]
cur = conn.cursor() #Cursorオブジェクトを取得なおDB接続と同様にカーソルもcur.close()で切断可能です。おそらく通常はconn.close()だけ使用するためあまり使わないと思います。
[In]
cur.close()2-2.クエリ(SQL文)の実行:cur.execute(query)
DBにSQL操作をする場合はcur.execute(クエリ:SQL文)を記載します。
[In]※参考例
cur.execute("""
SELECT *
FROM sqlite_master
WHERE type='table'
""")
[Out]
※初期ではデータ登録していないため出力無しなお公式Docsよりクエリは置換できる文字列記法ではセキュリティがおちると説明しているため文字置換をqueryの変数には入れないようにします。

2-3.登録の反映(確定):conn.commit()
DMLを実行した場合、実行中はデータは存在しますがそのままDB切断(conn.close())するとデータは保存されません。データ操作を反映させるためにはconn.commit()の処理が必要となります。
【データ操作言語(DML:Data Manipulation Language)一覧】
●SELECT:テーブルから行を検索する
●INSERT:テーブルに新規行を登録する
●UPDATE:テーブルの行を更新する
●DELETE:テーブルの行を削除する
通常のSQL文だと下記の通り<BEGIN TRANSACTION;>と<COMMIT;>で挟みますがsqlite3ではconn.commit()が役割を担ってそうです。
[SQL文でのデータ登録]※sqlite3では下記記法は使用できない
BEGIN TRANSACTION;
INSERT INTO <Table> VALUES <data1>
INSERT INTO <Table> VALUES <data2>
INSERT INTO <Table> VALUES <data3>
COMMIT;2-4.登録の取り消し:conn.rollback()
DMLの処理を取り消したい場合はconn.rollback()とします。なお、commit()後の変更は取り消しできません。
[In]
conn.rollback() #操作の取り消し3.テーブル操作:(CRUD操作)
基本的にはcur.execute(query)でのqueryにSQL文を記載するためPythonではなくSQL講座に近くなります。ただしsqlite3とSQL文で違う部分も含めて記載していきます。
なおSQL文はデータに文字列も追加するためクエリは"で記載しました。
3-1.テーブル作成:CREATE TABLE
SQL文でのテーブル作成は下記の通りです。
[SQL:テーブル作]
CREATE TABLE <テーブル名>
(<列名1> <データ型> <列名1へのデータ制約>
<列名2> <データ型> <列名2へのデータ制約>
<列名3> <データ型> <列名3へのデータ制約>
・
・
・
);今回は"Shohin"テーブルを作成してみます(イメージは下図参照)。なお同名のテーブルがあるとエラーになるため2回以上実行するとエラーがでます。

[In]
import sqlite3
path_DB = 'note_sqlite3.db' # DBファイルのパス
conn = sqlite3.connect(path_DB) # DBに接続/新規作成
cur = conn.cursor() #Cursorオブジェクトを取得
query_create_table = """
CREATE TABLE Shohin
(shohin_id INTEGER PRIMARY KEY AUTOINCREMENT,
shohin_mei VARCHAR(100) NOT NULL,
shohin_bunrui VARCHAR(32) NOT NULL,
hanbai_tanka INTEGER ,
shiire_tanka INTEGER ,
torokubi DATE);
"""
cur.execute(query_create_table) # SQL文を実行:Shohinテーブルを作成
[Out]
空テーブルがDB内に作成される参考までに各記述の意味は下記の通りです。
【注意事項および項目説明】
●SQLと同様にカラム名は半角アルファベット、数字、アンダーバーのみ
●AUTOINCREMENT:データ未入力でも連番をつける
●NOT NULL:データの未入力があるとエラーを出す
●PRIMARY KEY(主キー制約):データの重複ができない制約を追加
●データ型:整数(INTEGER)や文字列(VARCHAR)などを指定
ちなみに「PostgreSQLでMySQLのAUTO_INCREMENTを使う」を参考に下記で記載してみましたがAUTO_INCREMENTの機能はつかず、下記のまま"NOT NULL"の後ろにAUTOINCREMENTを記載するとエラーがでます。
[In]
import sqlite3
path_DB = 'note_sqlite3.db' # DBファイルのパス
conn = sqlite3.connect(path_DB) # DBに接続/新規作成
cur = conn.cursor() #Cursorオブジェクトを取得
query_create_table = """
CREATE TABLE Shohin
(shohin_id SERIAL NOT NULL ,
shohin_mei VARCHAR(100) NOT NULL,
shohin_bunrui VARCHAR(32) NOT NULL,
hanbai_tanka INTEGER ,
shiire_tanka INTEGER ,
torokubi DATE ,
PRIMARY KEY (shohin_id));
"""
cur.execute(query_create_table) # SQL文を実行:Shohinテーブルを作成
[Out]
空テーブルがDB内に作成される3-2.テーブルにデータ追加:INSERT
SQL文でのテーブルへのデータ追加は下記の通りです。
[SQL文:INSERT]
INSERT INTO <テーブル名> (列1, 列2, 列3,・・・・) VALUES (値1, 値2, 値3・・・);idはAUTO_INCREMENT機能を入れているため他の列データを追加します。データ追加後のテーブルは下記のようになります。

[In]
cur.execute("INSERT INTO Shohin (shohin_mei, shohin_bunrui, hanbai_tanka, shiire_tanka, torokubi) VALUES ('Tシャツ' ,'衣服', 1000, 500, '2009-09-20');")
cur.execute("INSERT INTO Shohin (shohin_mei, shohin_bunrui, hanbai_tanka, shiire_tanka, torokubi) VALUES ('穴あけパンチ', '事務用品', 500, 320, '2009-09-11');")
cur.execute("INSERT INTO Shohin (shohin_mei, shohin_bunrui, hanbai_tanka, shiire_tanka, torokubi) VALUES ('カッターシャツ', '衣服', 4000, 2800, NULL);")
cur.execute("INSERT INTO Shohin (shohin_mei, shohin_bunrui, hanbai_tanka, shiire_tanka, torokubi) VALUES ('包丁', 'キッチン用品', 3000, 2800, '2009-09-20');")
cur.execute("INSERT INTO Shohin (shohin_mei, shohin_bunrui, hanbai_tanka, shiire_tanka, torokubi) VALUES ('圧力鍋', 'キッチン用品', 6800, 5000, '2009-01-15');")
cur.execute("INSERT INTO Shohin (shohin_mei, shohin_bunrui, hanbai_tanka, shiire_tanka, torokubi) VALUES ('フォーク', 'キッチン用品', 500, NULL, '2009-09-20');")
cur.execute("INSERT INTO Shohin (shohin_mei, shohin_bunrui, hanbai_tanka, shiire_tanka, torokubi) VALUES ('おろしがね', 'キッチン用品', 880, 790, '2008-04-28');")
cur.execute("INSERT INTO Shohin (shohin_mei, shohin_bunrui, hanbai_tanka, shiire_tanka, torokubi) VALUES ('ボールペン', '事務用品', 100, NULL, '2009-11-11');")
conn.commit() #変更をコミット(保存)
[Out]
Shohinテーブルの中にデータが追加された【注意点】
●conn.commit()をしないとDB切断時に追加したデータは消えます
●idのみにPRIMARY_KEYを入れているため現状では同じデータでも登録できてしまいます。データの重複をさせない場合は別列も含めてPRIMARY_KEYとして登録させます。
●一つのクエリにまとめてINSERT記述はできません(下記参照)
[In]※エラー構文
query_insert_table="""
BEGIN TRANSACTION;
INSERT INTO Shohin VALUES ('Tシャツ' ,'衣服', 1000, 500, '2009-09-20');
INSERT INTO Shohin VALUES ('穴あけパンチ', '事務用品', 500, 320, '2009-09-11');
COMMIT;
"""
cur.execute(query_insert_table) # SQL文を実行:Shohinテーブルにデータを挿入
[Out]
Warning: You can only execute one statement at a time.3-3.データの読み込み:SELECT
SQL文でのテーブルデータの取得は下記の通りです。
[SQL文:データ取得]
SELECT <列名1>, <列名2>,・・・・
FROM <テーブル名>;
[全列データ取得]
SELECT *
FROM <テーブル名>;sqlite3ではSELECT文を実施しても値は出力されずCursorオブジェクト内に保持されます。データの出力は別途Cursorオブジェクトから取得します。
3-3-1.読み込みデータ取得1:Cursorイテレーター
SELECT文実行後にcursorをイテレータとして操作できます。
[In]
cur.execute("""
SELECT *
FROM Shohin;
""")
for row in cur:
print(row) #tuple形式で出力
[Out]
(1, 'Tシャツ', '衣服', 1000, 500, '2009-09-20')
(2, '穴あけパンチ', '事務用品', 500, 320, '2009-09-11')
(3, 'カッターシャツ', '衣服', 4000, 2800, None)
(4, '包丁', 'キッチン用品', 3000, 2800, '2009-09-20')
(5, '圧力鍋', 'キッチン用品', 6800, 5000, '2009-01-15')
(6, 'フォーク', 'キッチン用品', 500, None, '2009-09-20')
(7, 'おろしがね', 'キッチン用品', 880, 790, '2008-04-28')
(8, 'ボールペン', '事務用品', 100, None, '2009-11-11')リストで取得するならfetchall()でもよいですが下記でも記載はできます。
[In]
cur.execute("""
SELECT *
FROM Shohin;
""")
list(cur)
[Out]
[(1, 'Tシャツ', '衣服', 1000, 500, '2009-09-20'),
(2, '穴あけパンチ', '事務用品', 500, 320, '2009-09-11'),
(3, 'カッターシャツ', '衣服', 4000, 2800, None),
(4, '包丁', 'キッチン用品', 3000, 2800, '2009-09-20'),
(5, '圧力鍋', 'キッチン用品', 6800, 5000, '2009-01-15'),
(6, 'フォーク', 'キッチン用品', 500, None, '2009-09-20'),
(7, 'おろしがね', 'キッチン用品', 880, 790, '2008-04-28'),
(8, 'ボールペン', '事務用品', 100, None, '2009-11-11')]3-3-2.読み込みデータ取得2:fetchone/many/all
Cursorオブジェクトをイテレーターとして使用せずメソッドでデータ抽出する場合は下記メソッドを使用します。
【fetchメソッド】
●cur.fetchone():1行ごとに各列のデータをtupleで取得
●cur.fetchmany(行数):指定行ごとのデータをListで取得
●cur.fetchall():全データをListで取得
[In]
cur.execute("""
SELECT *
FROM Shohin;
""")
cur.fetchone()
[Out]
(1, 'Tシャツ', '衣服', 1000, 500, '2009-09-20')
※For文を使用すると1行分のTupleがFor文で出力される。
[In]
cur.execute("""
SELECT *
FROM Shohin;
""")
cur.fetchmany(2)
[Out]
[(1, 'Tシャツ', '衣服', 1000, 500, '2009-09-20'),
(2, '穴あけパンチ', '事務用品', 500, 320, '2009-09-11')]
※For文を使用すると指定行分のリストデータがFor文で出力される。
[In]
cur.execute("""
SELECT *
FROM Shohin;
""")
cur.fetchall()
[Out]
<sqlite3.Cursor at 0x16b0da16180>
[(1, 'Tシャツ', '衣服', 1000, 500, '2009-09-20'),
(2, '穴あけパンチ', '事務用品', 500, 320, '2009-09-11'),
(3, 'カッターシャツ', '衣服', 4000, 2800, None),
(4, '包丁', 'キッチン用品', 3000, 2800, '2009-09-20'),
(5, '圧力鍋', 'キッチン用品', 6800, 5000, '2009-01-15'),
(6, 'フォーク', 'キッチン用品', 500, None, '2009-09-20'),
(7, 'おろしがね', 'キッチン用品', 880, 790, '2008-04-28'),
(8, 'ボールペン', '事務用品', 100, None, '2009-11-11')]3-4.データの更新:UPDATE
SQL文でのテーブルデータの更新(上書き)は下記の通りです。
[SQL文:データ更新(列全体)]
UPDATE <テーブル名>
SET <列名> = <式> ;
[SQL文:データ更新(条件指定)]
UPDATE <テーブル名>
SET <列名> = <式>
WHERE <条件>; sqlite3でUPDATE文を記載してみます。
※rollback()は元データに戻すためだけに使用するため通常は不要
[In]
cur.execute("""
UPDATE Shohin
SET torokubi = '2022-03-20'
""")
cur.execute("SELECT * FROM Shohin;") # SQL文を実行:Shohinテーブルを表示
print(cur.fetchall())
conn.rollback() #変更を戻す※通常は更新後にconn.commit()を実行
[Out]
(1, 'Tシャツ', '衣服', 1000, 500, '2022-03-20')
(2, '穴あけパンチ', '事務用品', 500, 320, '2022-03-20')
(3, 'カッターシャツ', '衣服', 4000, 2800, '2022-03-20')
(4, '包丁', 'キッチン用品', 3000, 2800, '2022-03-20')
(5, '圧力鍋', 'キッチン用品', 6800, 5000, '2022-03-20')
(6, 'フォーク', 'キッチン用品', 500, None, '2022-03-20')
(7, 'おろしがね', 'キッチン用品', 880, 790, '2022-03-20')
(8, 'ボールペン', '事務用品', 100, None, '2022-03-20')[In]
cur.execute("""
UPDATE Shohin
SET hanbai_tanka = hanbai_tanka * 10
WHERE shohin_bunrui = 'キッチン用品';
""")
cur.execute("SELECT * FROM Shohin;") # SQL文を実行:Shohinテーブルを表示
print(cur.fetchall())
conn.rollback() #変更を戻す※通常は更新後にconn.commit()を実行
[Out]
(1, 'Tシャツ', '衣服', 1000, 500, '2009-09-20')
(2, '穴あけパンチ', '事務用品', 500, 320, '2009-09-11')
(3, 'カッターシャツ', '衣服', 4000, 2800, None)
(4, '包丁', 'キッチン用品', 30000, 2800, '2009-09-20')
(5, '圧力鍋', 'キッチン用品', 68000, 5000, '2009-01-15')
(6, 'フォーク', 'キッチン用品', 5000, None, '2009-09-20')
(7, 'おろしがね', 'キッチン用品', 8800, 790, '2008-04-28')
(8, 'ボールペン', '事務用品', 100, None, '2009-11-11')3-5.データの削除:DELETE
SQL文でのテーブルデータの削除は下記の通りです。
[SQL文:データ削除(全データ)]
DELETE FROM <テーブル名>;
【SQL文:データ削除(条件指定)】
DELETE FROM <テーブル名>
WHERE <条件>;sqlite3では下記のような記載になります。
[In]
cur.execute("""
DELETE FROM Shohin
""")
cur.execute("SELECT * FROM Shohin;") # SQL文を実行:Shohinテーブルを表示
print(cur.fetchall())
conn.rollback() #変更を戻す※通常は更新後にconn.commit()を実行
[Out]
データなし※上記よりテーブル内データが全部削除された
->rollback()で復元しているがcommit()すると元に戻らない[In]
cur.execute("""
DELETE FROM Shohin
WHERE hanbai_tanka <= 1000;
""")
cur.execute("SELECT * FROM Shohin;") # SQL文を実行:Shohinテーブルを表示
print(cur.fetchall())
conn.rollback() #変更を戻す※通常は更新後にconn.commit()を実行
[Out]
(3, 'カッターシャツ', '衣服', 4000, 2800, None)
(4, '包丁', 'キッチン用品', 3000, 2800, '2009-09-20')
(5, '圧力鍋', 'キッチン用品', 6800, 5000, '2009-01-15')4.PandasでのSQL操作
Pandasを使用してsqlite3へデータ追加や抽出をしたいと思います。まずサンプル用データを下記の通り作成しました。
[In]
import pandas as pd
import numpy as np
from sklearn import datasets
np.random.seed(0) #乱数値を固定
idx_random = np.random.randint(0, len(datasets.load_iris().data), size=10) #乱数で10個のインデックスを取得->array([ 47, 117, 67, 103, 9, 21, 36, 87, 70, 88])
iris = datasets.load_iris() #Irisデータセットを読み込み
columns = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width'] #列名指定※半角スペースやカッコはエラーになるため除去
data, label = pd.DataFrame(iris.data, columns=columns), pd.DataFrame(iris.target, columns=['target'])
label = label['target'].map({0: 'setosa', 1: 'versicolor', 2: 'virginica'}) #ラベルを数値から文字列に変換
df = pd.concat([data, label], axis=1) #データとラベルを結合
df_iris = df.iloc[idx_random, :] #ランダムに10個データを取得
df_iris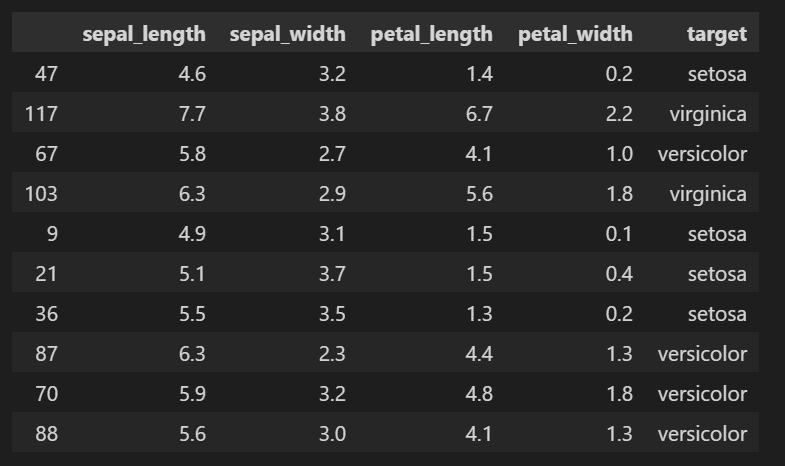
4-1.テーブル作成:df.to_sql()
df.to_sql()を使用することでDataFrame型データをテーブルとしてDBに追加できます。今回はIrisテーブルとしてデータ追加します。
【引数の説明】
●con:SQLAlchemyかsqlite3のDBを選択
●if_exists{'fail'、 'replace'、 'append'}、default'fail ':既設テーブルがある場合の処理(エラー処理、上書き可、既設テーブルにデータ追加)
●index(defalut:True):DataFrameのIndexデータをテーブルに記載
[In]
df_iris.to_sql('Iris', conn, if_exists='replace') #Irisテーブルにデータを保存※テーブル上書き可
cur.execute("SELECT * FROM Iris;") # SQL文を実行:Shohinテーブルを表示
for row in cur:
print(row)
[Out]
(47, 4.6, 3.2, 1.4, 0.2, 'setosa')
(117, 7.7, 3.8, 6.7, 2.2, 'virginica')
(67, 5.8, 2.7, 4.1, 1.0, 'versicolor')
(103, 6.3, 2.9, 5.6, 1.8, 'virginica')
(9, 4.9, 3.1, 1.5, 0.1, 'setosa')
(21, 5.1, 3.7, 1.5, 0.4, 'setosa')
(36, 5.5, 3.5, 1.3, 0.2, 'setosa')
(87, 6.3, 2.3, 4.4, 1.3, 'versicolor')
(70, 5.9, 3.2, 4.8, 1.8, 'versicolor')
(88, 5.6, 3.0, 4.1, 1.3, 'versicolor')4-2.データの読み込み:pd.read_sql(query, conn)
PandasはDBを指定してクエリを記載することでDataFrame型データとしてテーブルを取得することが可能です。
[IN]
pd.read_sql("SELECT * FROM Iris;", conn) #SQL文を実行してDataFrameに変換
[Out]
下記参照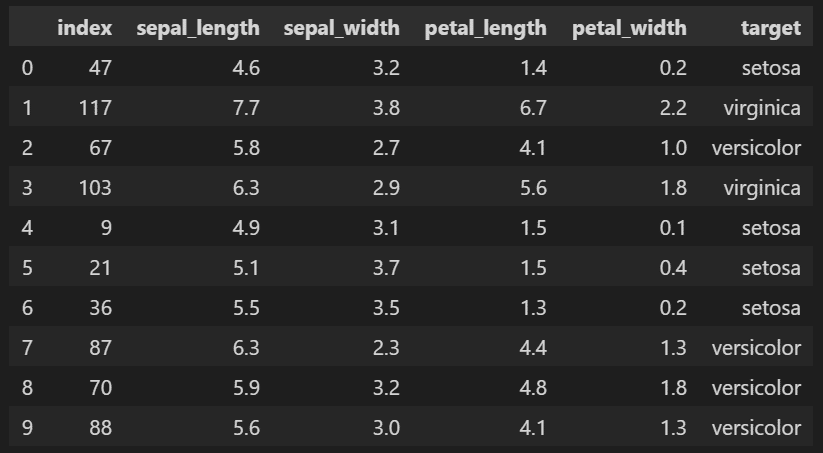
5.応用操作:sqlite3のDB確認
5-1.テーブル一覧取得
sqlite3の"sqlite_master"にメタ情報がはいっておりWHERE条件の指定でテーブル一覧を取得できます。
※sqlite_sequenceという謎テーブルがありますが通常は2つだと思います。
[In]
cur.execute("""
SELECT *
FROM sqlite_master
WHERE type='table'
""")
for row in cur:
print(row)
[Out]
('table', 'Shohin', 'Shohin', 2, 'CREATE TABLE Shohin\n(shohin_id INTEGER PRIMARY KEY AUTOINCREMENT,\n shohin_mei VARCHAR(100) NOT NULL,\n shohin_bunrui VARCHAR(32) NOT NULL,\n hanbai_tanka INTEGER ,\n shiire_tanka INTEGER ,\n torokubi DATE)')
('table', 'sqlite_sequence', 'sqlite_sequence', 3, 'CREATE TABLE sqlite_sequence(name,seq)')
('table', 'Iris', 'Iris', 4, 'CREATE TABLE "Iris" (\n"index" INTEGER,\n "sepal_length" REAL,\n "sepal_width" REAL,\n "petal_length" REAL,\n "petal_width" REAL,\n "target" TEXT\n)')5-2.一時的な使用:sqlite3.connect(‘:memory:’)
一時的な使用としてはDBpathを指定する代わりに':memory:'と記載することでDB切断時まで一時的に使用可能です(データはメモリ上で管理)。
[In]
conn_temp = sqlite3.connect(':memory:') #テンポラリDBを作成
cur_temp = conn_temp.cursor()
df_iris.to_sql('Iris', conn_temp, if_exists='replace') #テンポラリDBにデータを保存
cur_temp.execute("SELECT * FROM Iris;") # SQL文を実行:Shohinテーブルを表示
for row in cur_temp:
print(row)
conn_temp.close()
[Out]
上記Irisと同じだがdbファイルは作成されない
6.予備章
SQL応用を記載する場合用に空ける(多分しないと思うけど)
7.番外編1:ターミナルから操作
番外編としてターミナルからsqlite3を操作してみます。VS CODEなどのIDEで操作できるため滅多に使用しないですが参考までに紹介します。
DB接続はターミナルからdbファイルディレクトリで下記を実行します。
[Terminal] DB接続
sqlite3 ファイル名.db接続出来たらターミナルに"sqlite>"と記載されるのでターミナル上に直接SQL文を記載できます。DB切断に関しては".exit"でじっこうできます。
[Terminal] DB切断
sqlite> .exit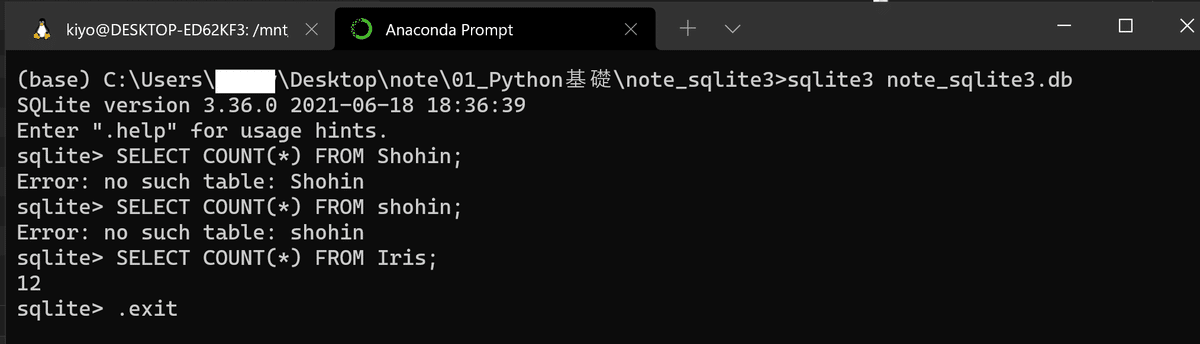
8.番外編2:Jupyterで操作(ipython-sql)
2章ではsqlite3.connect(path)からDB接続して操作を実行しましたがJupyterのマジックコマンドでも操作可能ので参考までに紹介します。
8-1.sqlite.dbへ接続
まず初めに「ipython-sql」をインストールします。
[Terminal]
pip install ipython-sqlsqlite3のdbファイルが同じディレクトリにあることを確認して下記コードを実行することでデータを取得することが出来ます。
[In]
#%sqlのマジックコマンドを使用できるようにする。
%load_ext sql
#指定ファイルのDB接続
%sql sqlite:///note_sqlite3.db
#Irisテーブルから全データ取得
%sql SELECT * FROM Iris;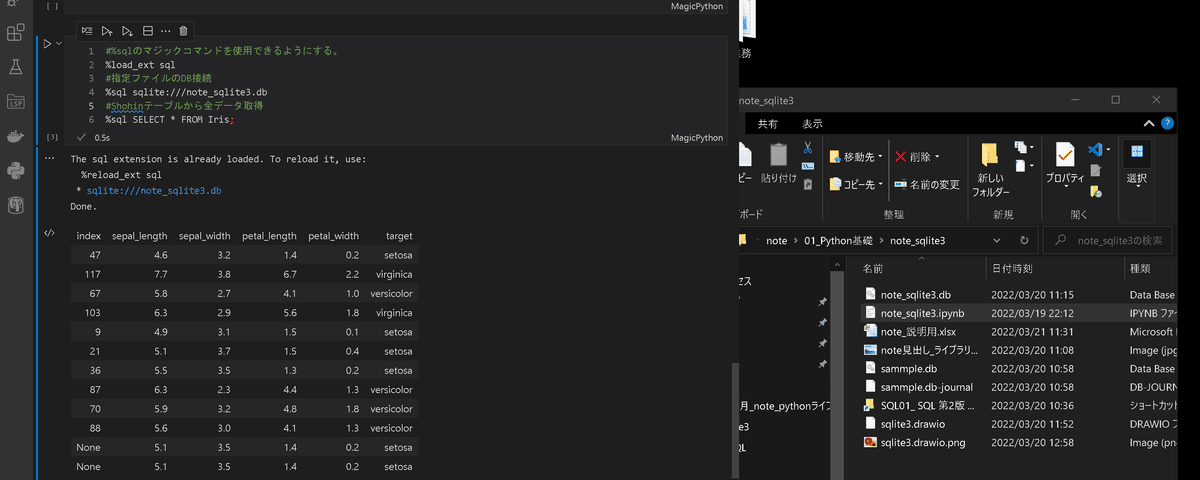
8-2.PostgreSQL
ipython-sqlではPostgreSQLへの接続も可能です。本記事ではpostgreは説明しませんので「SQL 第2版 ゼロからはじめるデータベース操作」のshopデータベースのshohinテーブルを作成済みとします。
8-2-1.事前準備
postgresへの接続には「ipython-sql」と「psycopg2」の2つのライブラリが必要なためインストールします。
[Terminal]
pip install ipython-sql
pip install psycopg2次にPostgreのパスを通します。コントロールパネル->システム環境変数に各自のPostgreのbinフォルダを追加します。
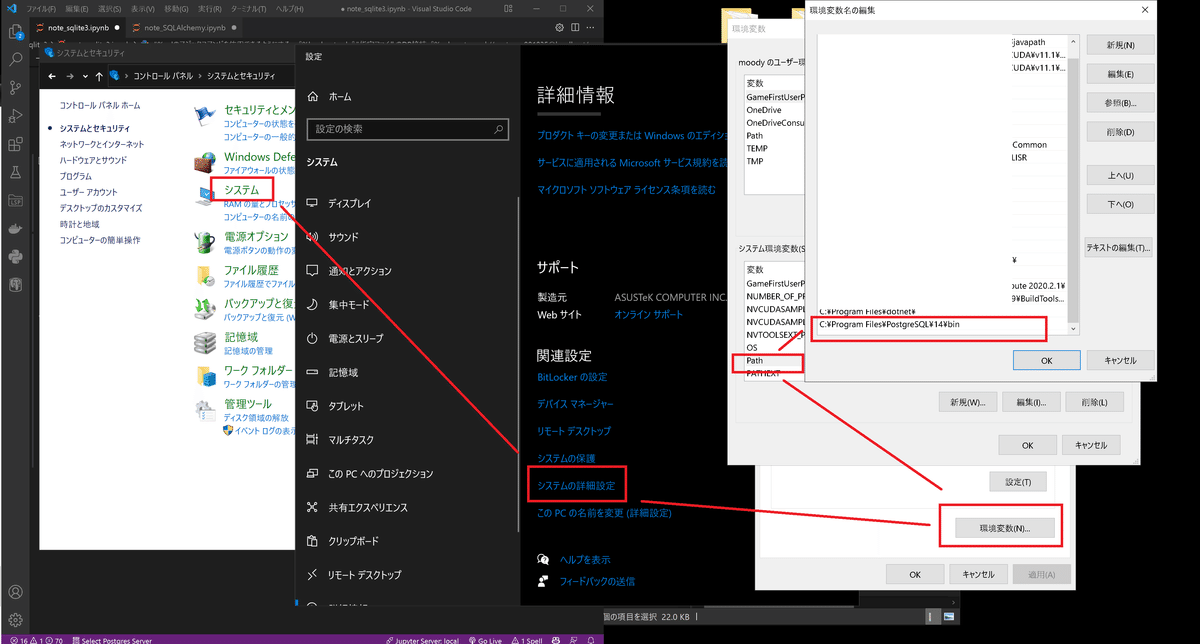
8-2-2.PostgreSQLへ接続
Postgreへの接続は設定時のパスワードおよび作成したDB名が必要です。
[PostgreSQLのshopデータベースへ接続]
%sql postgresql://postgres:<password>@localhost/<DB名>今回は自分のPCにあるshopデータベースへ接続します。またパスワードは"note"と仮定して記載しました。
[In]
#%sqlのマジックコマンドを使用できるようにする。
%load_ext sql
#指定ファイルのDB接続
%sql postgresql://postgres:note@localhost/shop
#Shohinテーブルから全データ取得
%sql SELECT * FROM Shohin;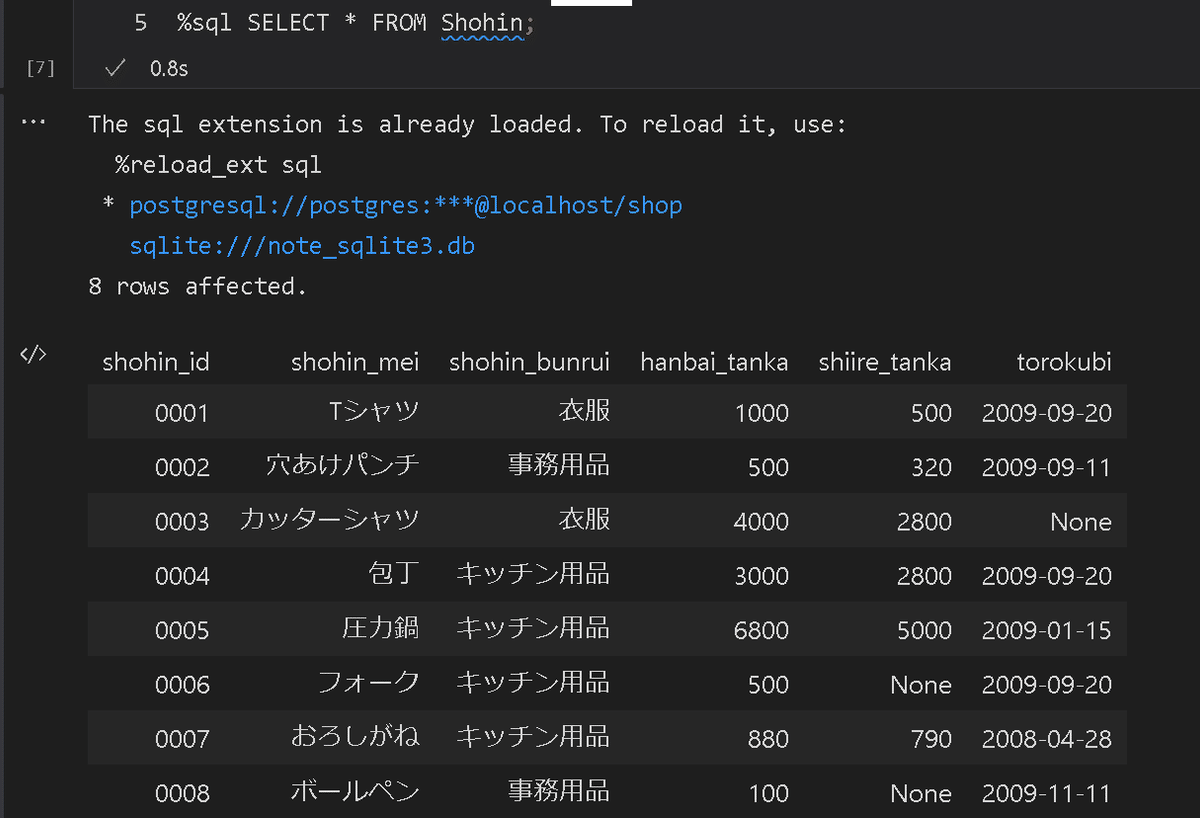
参考資料
1.SQL学び初めの方には一押しの本です。
2.補助的にみると理解が深まります。
MySQLのテーブル結合チートシートhttps://t.co/cVjapx8Vl0 pic.twitter.com/cIMFzZs46z
— QDくん⚡️Python x 機械学習 x 金融工学 (@developer_quant) January 29, 2023
3.補足としてみてもよいと思う(記載が丁寧)
4.こちらも勉強してね
あとがき
おそらくPythonライブラリのSQL AlchemyやSQLModel、またはSQLそのものPostgresを使用する可能性が高いと思うけど、まずは地道に一歩から学んでいく。
なおPRIMARY_KEYでid以外の重複防止に関しては理解できたら修正予定。
今後はSQLを使用してメーカー連絡先DBを作成する予定です(名刺が完全に管理されているならEightのビジネス版でもよいかもしれないけど)。