
Pythonライブラリ(時系列解析):Prophet

1.概要
1-1.ライブラリの説明
Meta(旧facebook)社が提供している時系列解析モデルのProphetを紹介します。本技術で為替や株価などを過去のトレンドから推測可能です。
(※結論として予測精度の幅が広いため実用的には参考値程度にしかならない)
参考までにProphetの意味は”預言者”とのことです。
1-2.モデルの詳細
下記に論文が公開されておりますので確認可能です。
https://peerj.com/preprints/3190.pdf
1-3.サンプル用の時系列データ取得
サンプル用データは時系列であれば何でも問題ないですが私は「bitFlyerでのbitcoinの終値日時データ」を使用しました。
CSVデータを下記サイトから取得して"data"フォルダに保管しました。

1-3.解析用データ用クラス作成
データ解析用のクラスを作成します。全コードは下記の通りですが、ここは重要ではないためアウトプットの形だけ同じであれば何でもよいです。
参考として各関数の機能は下記の通りです。
HorizontalDisplay:DataFrameを並列表示させる
getDataFrame_csv:CSVを結合して一つのDataFrameを作成
splitDataFrame:指定した割合(ratio)のデータ数でDataFrameを分割
strnum2int:CSVデータがカンマ区切りの文字列のため整数に変換
[IN]
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os
import glob
import datetime
class HorizontalDisplay:
def __init__(self, *args):
self.args = args
def _repr_html_(self):
template = '<div style="float: left; padding: 10px;">{0}</div>'
return "\n".join(template.format(arg._repr_html_())
for arg in self.args)
def getDataFrame_csv(root:str):
files = glob.glob(f'{root}/*.csv')
df = pd.DataFrame()
for file in files:
df = df.append(pd.read_csv(file, index_col=0, parse_dates=True))
return df
def splitDataFrame(df, ratio:int):
qty_data = len(df)
idx_split = int(qty_data * ratio)
df_pre = df.iloc[:idx_split] #前半
df_post = df.iloc[idx_split:] #後半
return df_pre, df_post
def strnum2int(strnum:str):
return int(strnum.replace(',', '')) #CSVデータがカンマ区切りの文字列のため整数に変換
df = getDataFrame_csv(root='data')
df_BTC = df[['BTC']] #BTCのみ抽出:2重括弧はDataFrame型
df_BTC = df_BTC.dropna() #欠損値を削除
df_BTC = df_BTC.reset_index() #Dateをcolumnに移動させるためにindexをリセット
df_BTC['BTC'] = df_BTC['BTC'].apply(strnum2int) #文字列を整数に変換
df_BTC_train, df_BTC_test = splitDataFrame(df_BTC, ratio=0.9)
HorizontalDisplay(df_BTC, df_BTC_train, df_BTC_test)
[OUT]
左から順に1.全データ、2.前半90%のデータ、3.後半10%のデータ
2.環境構築
2-1.ライブラリのインストール
ProphetはsklearnのAPIに従っており事前に下記をインストールします。旧ver.では"pip install fbprophet"ですが最新ver(v1.0)では"prophet"を使用します。
また"PyStan"も合わせてインストールしておきます。
[Terminal]
pip install pystan
pip install prophet2-2.エラー時の参考資料
私はあきらめてColabを使用しておりますが、ローカルPCでエラーが発生した方向けにエラー集をおいておきます(可能性としてはVersion管理が必要な可能性があります)。
3.時系列解析:シンプルVer.
まずはQuickStartに従って簡単な処理方法を学びます。
インポートは旧ver.では"from fbprophet import Prophet"ですが最新(Google Colabでの使用)では下記を使用します。
[IN]
from prophet import Prophet3-1.カラムの修正:[ds,y]
まず初めにProphetを使用するためには時刻・日時のカラムを’ds’、値(目的変数)を'y'というカラム名に変更する必要があります。
[IN]
df_BTC_train.columns = ['ds', 'y'] # Prophetの入力に合わせるためにカラム名を変更
df_BTC_test.columns = ['ds', 'y'] # Prophetの入力に合わせるためにカラム名を変更
HorizontalDisplay(df_BTC_train.head(3), df_BTC_test.head(3))
[OUT]
ds y ds y
0 2014-06-02 65,484 2722 2022-01-18 4,744,768
1 2014-06-03 69,775 2723 2022-01-19 4,872,532
2 2014-06-04 66,625 2724 2022-01-20 4,915,9283-2.アルゴリズム選択
次に時系列分析のアルゴリズムを選択します。選択肢は下記の通りですが詳細は次章で説明します。
3-3.学習:model.fit()
データの学習はsklearn-APIと同様に"model.fit()"で実行します。
[IN]
from prophet import Prophet
model = Prophet()
model.fit(df_BTC_train)
[OUT]
INFO:prophet:Disabling daily seasonality. Run prophet with daily_seasonality=True to override this.
DEBUG:cmdstanpy:input tempfile: /tmp/tmpp3xp9u1y/2tl_0d9h.json
DEBUG:cmdstanpy:input tempfile: /tmp/tmpp3xp9u1y/0j2ox41r.json
DEBUG:cmdstanpy:idx 0
DEBUG:cmdstanpy:running CmdStan, num_threads: None
DEBUG:cmdstanpy:CmdStan args: ['/usr/local/lib/python3.7/dist-packages/prophet/stan_model/prophet_model.bin', 'random', 'seed=48206', 'data', 'file=/tmp/tmpp3xp9u1y/2tl_0d9h.json', 'init=/tmp/tmpp3xp9u1y/0j2ox41r.json', 'output', 'file=/tmp/tmpp3xp9u1y/prophet_modelbqbyac16/prophet_model-20221117130448.csv', 'method=optimize', 'algorithm=lbfgs', 'iter=10000']
13:04:48 - cmdstanpy - INFO - Chain [1] start processing
INFO:cmdstanpy:Chain [1] start processing
13:04:49 - cmdstanpy - INFO - Chain [1] done processing
INFO:cmdstanpy:Chain [1] done processing
<prophet.forecaster.Prophet at 0x7f56207e73d0>3-4.推論
学習したモデルを使用して将来のデータ予測を実施ますがProphet独自のプロセスがありますので注意が必要です。
3-4-1.予測用期間作成:make_future_dataframe
Prophetで推論する時には(元データを含む)推論したい開始から終了期間を指定する必要があります(データの"ds"に相当)。
Prophetには本データ用メソッドとして”model.make_future_dataframe
(<予測したい期間>, freq=<期間の単位(D, Hなど)>)”を使用します。
下記サンプルコードですが引数に('3', 'D')を指定すると学習したデータに3日分追加された時刻データがDataFrame型で出力されました。
[IN]
date_future = model.make_future_dataframe(3, freq='D')
HorizontalDisplay(df_BTC_train, date_future)
[OUT]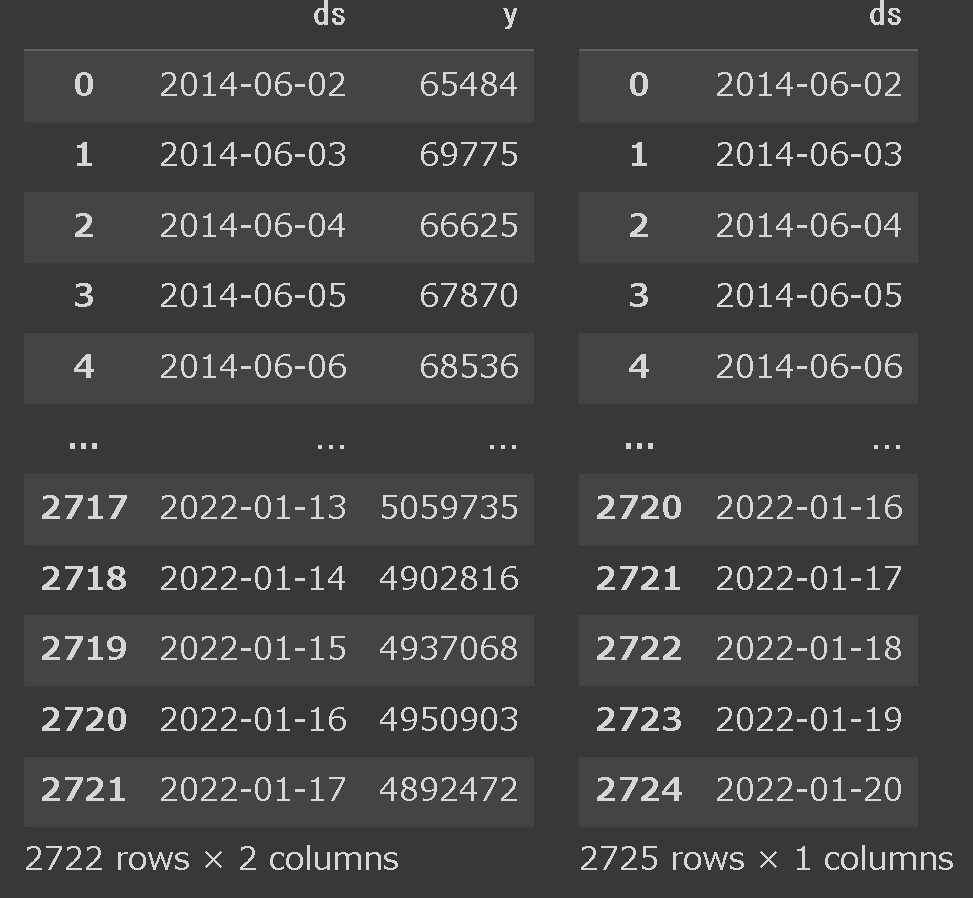
今回の分割データ(test)は303個(日分)あるため"303"を指定しました。
[IN]
date_future = model.make_future_dataframe(303, freq='D')
HorizontalDisplay(df_BTC_train, date_future)
[OUT]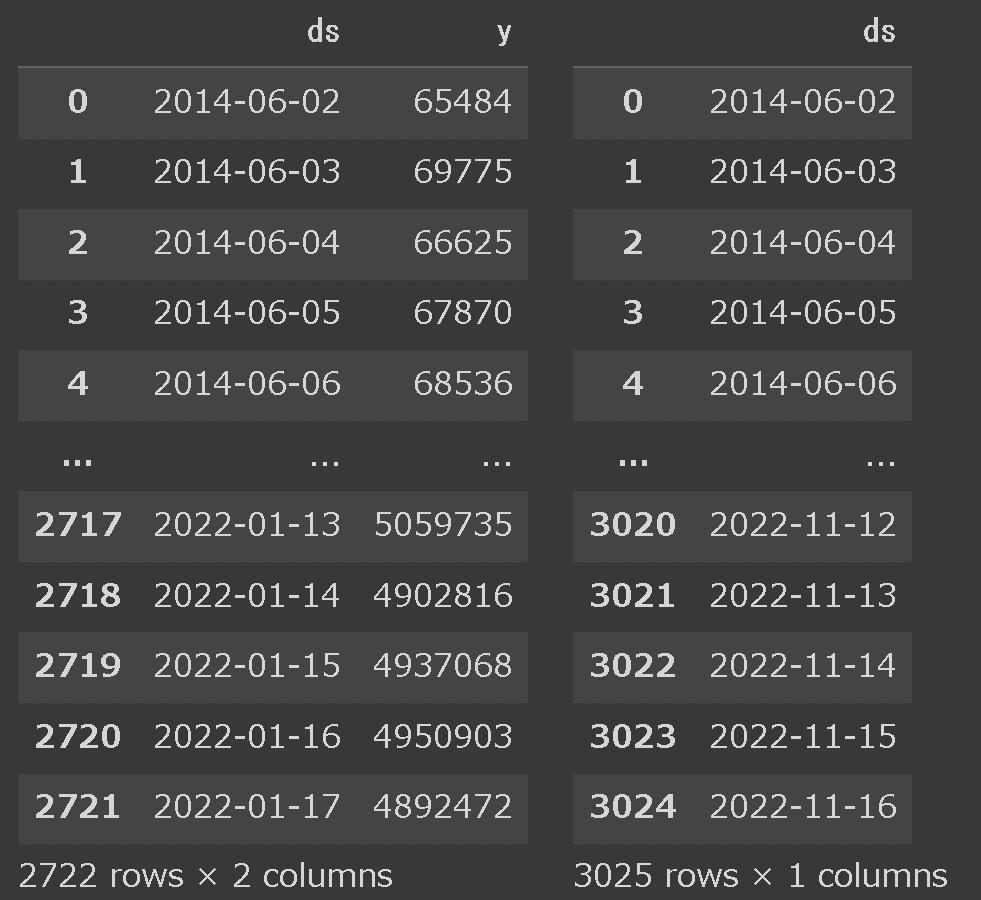
3-4-2.推論:model.predict(date)
学習したデータから将来の値を使用するにはmodel.predict()の引数に前項で求めた将来期間を入力することで実行します。
[IN]
forecast = model.predict(date_future)
forecast
[OUT]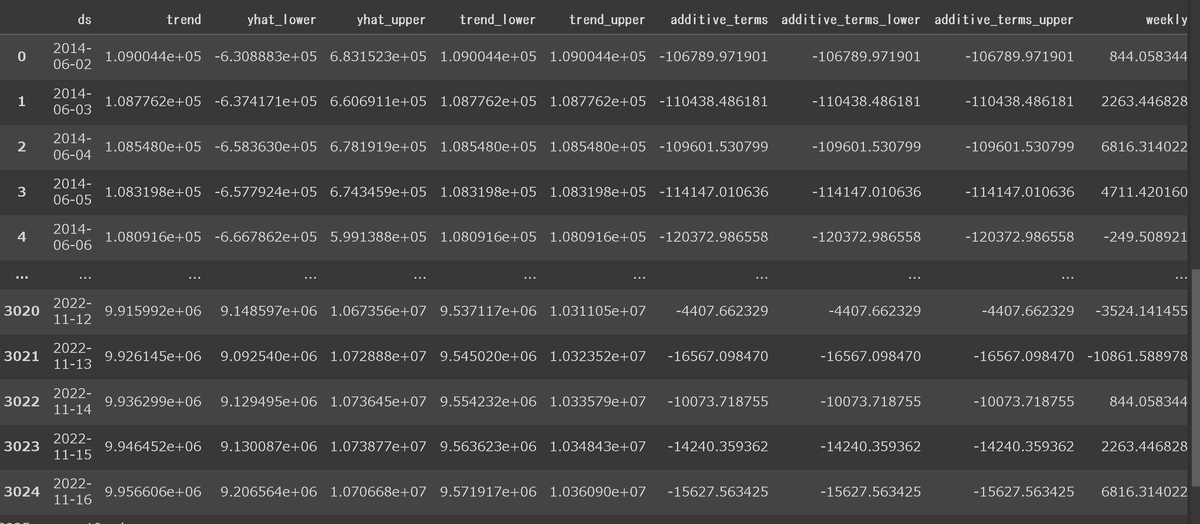
メインデータとして"予測値:yhat、予測値の下限:yhat_lower、予測値の上限:yhat_upper"を抽出してみました。
[IN]
forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']]
[OUT]
3-5.可視化
3-5-1.model.plot(forecast)
Matplotlibベースのグラフを表示するにはmodel.plot(<推論データ>)を使用します。
[IN]
import matplotlib.pyplot as plt
model.plot(forecast)
plt.ticklabel_format(style='plain',axis='y') #style='plain':普通の表記, style='sci':指数表記
plt.show()
[OUT]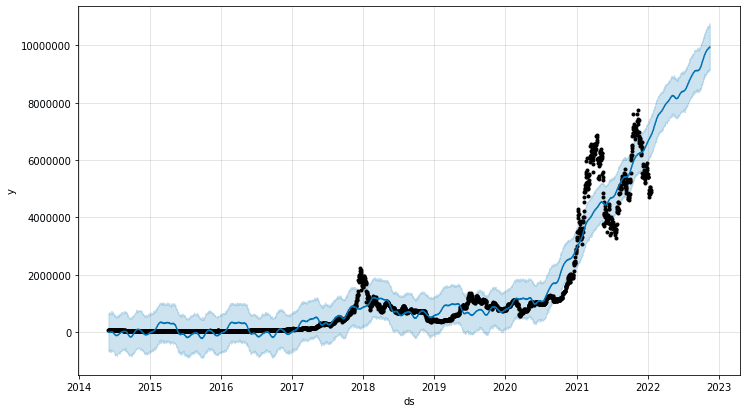
Plotlyベースのインタラクティブな図を表示したい場合は"plot_plotly(<モデルのインスタンス>, <推論データ>)"を使用します。
[IN]
from prophet.plot import plot_plotly, plot_components_plotly
plot_plotly(model, forecast)
[OUT]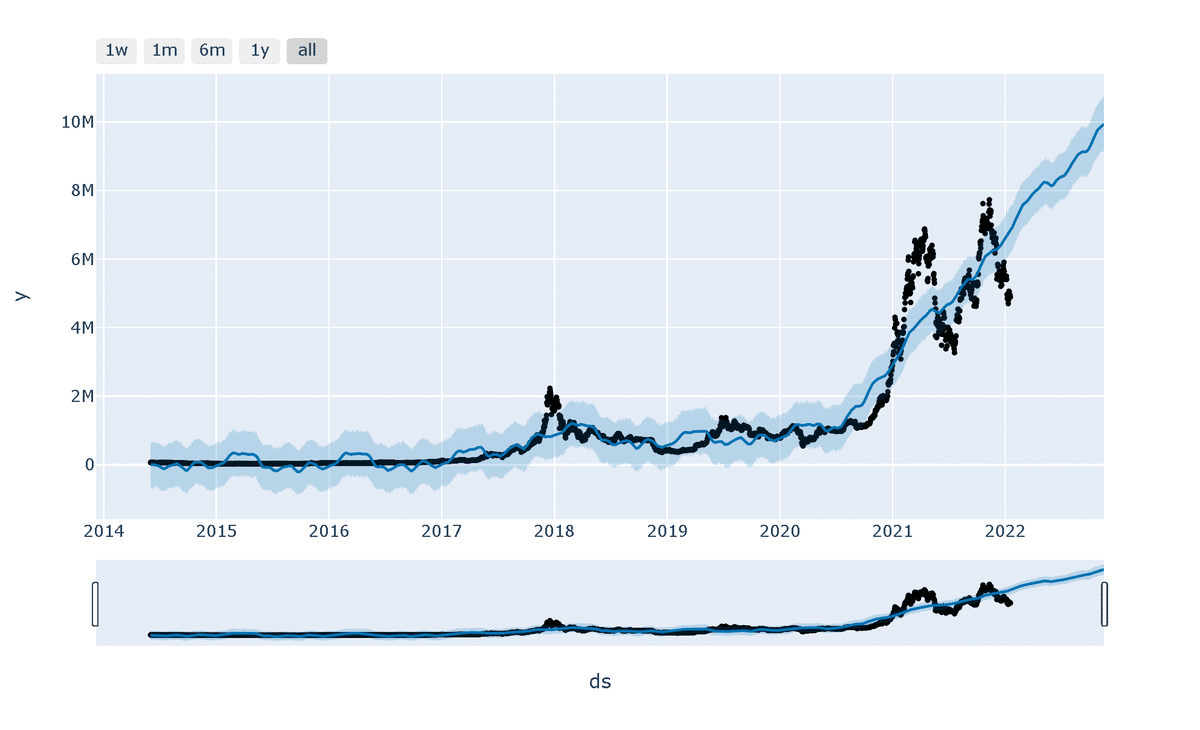
3-5-2.トレンド・周期確認:model_plot_components()
学習データのトレンドや周期を確認するには”model.plot_components
(forecast)”を使用します。
[IN]
model.plot_components(forecast)
plt.show()
[OUT]
上記より下記が確認できます。
長期周期(トレンド):上昇傾向
週周期:水曜日に増加傾向
年周期:3-5月にかけて増加
こちらもPlotlyベースのインタラクティブな図を表示可能です。
[IN]
from prophet.plot import plot_plotly, plot_components_plotly
plot_components_plotly(model, forecast)
[OUT]
3-6.性能評価
こちらはProphetの機能ではなく単純に正解値と予測値を比較します。コードの処理手順は下記の通りです。
Prophetの予測値からテストデータ(正解データ)の期間部分だけを抽出
x軸用の期間データを抽出
正解値はテストデータ、予測値は'yhat'を使用してプロット
[IN]
_y_pred = forecast[['ds', 'yhat']]
y_pred = _y_pred[_y_pred['ds']>='2022-1-18']
date_test = y_pred['ds']
import matplotlib.dates as mdates
import japanize_matplotlib
fig, ax = plt.subplots(figsize=(10, 6))
ax.plot(date_test, df_BTC_test['y'], label='正解', c='k')
ax.plot(date_test, y_pred['yhat'], label='予測値', c='b')
weeks = mdates.WeekdayLocator(byweekday=mdates.TH)
ax.xaxis.set_major_locator(weeks)
ax.tick_params(axis='x', rotation=90)
ax.grid(); ax.legend();ax.set_title('BTCの正解値と予測値のトレンド')
plt.show()
[OUT]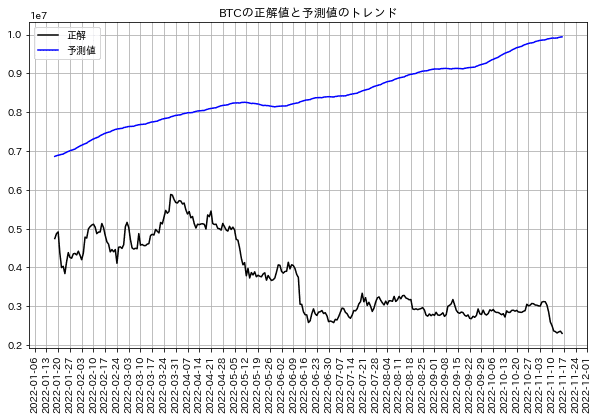
今回の結果では予測値は右肩上がりに対して実際の値は3月以降から急激に下がっております。
おそらくですがトレンドの影響よりイベントの影響(アメリカの指標の悪化やFTX破綻など)が大きな影響を及ぼしていると考えられます。
4.時系列解析:シンプルVer.(別データ使用)
(アルゴリズムによる最適化はしておりませんが)仮想通貨では精度が低かったため別データとして日経平均を用いて性能を再検証します。

4-1.日経平均データの取得
株価データは「pandas-datareader」を用いて取得しました。詳細は別記事をご確認ください。ポイントは下記の通りです。
pandas-datareaderの出力はPandas形式かつ降順:昇順にソート
データは[始値, 高値, 安値, 終値, 出来高]がある。中長期目線で瞬間的なデータは不要と判断して終値(Close)を使用する
日付はIndexについているためカラム側へ移動させる処理が必要
土日や祝日など休場日のデータ無し:”model.make_future_dataframe”を使用すると連続日となるため別の処理でデータ抽出が必要
[IN]
import pandas_datareader as pdr
stockcodes = {'Nikkei':'^NKX',
'TOYOTA':'7203.JP'}
df_descending = pdr.data.DataReader(stockcodes['Nikkei'], 'stooq') #Stooqから日経平均株価を取得
df_all = df_descending.sort_index(ascending=True) #日付の昇順に並び替え
df = df_all[['Close']] #株価の終値のみ抽出
df = df.reset_index(drop=False) #Indexにある日付をcolumnに移動させる
df.columns = ['ds', 'y'] # Prophetの入力に合わせるためにカラム名を変更
df_train, df_test = splitDataFrame(df, ratio=0.9) #訓練データとテストデータに分割
HorizontalDisplay(df_train, df_test)
[OUT]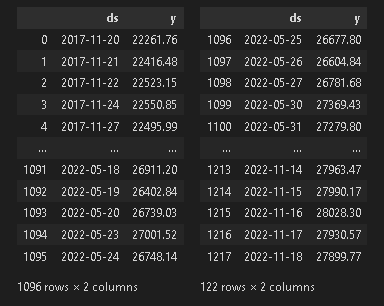
4-2.学習・推論
シンプルVer.と同じく学習・推論を実施します。なお日付は休日・祝日を抜いたデータを使用したいためオリジナルの日付データをそのまま使用しました(※オリジナルデータより将来のデータを予想する場合は要調整)。
[IN]
model = Prophet()
model.fit(df_train)
date_future = pd.concat([df_train[['ds']], df_test[['ds']]], axis=0)
forecast = model.predict(date_future)
forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']]
[OUT]
INFO:prophet:Disabling daily seasonality. Run prophet with daily_seasonality=True to override this.
DEBUG:cmdstanpy:input tempfile: /tmp/tmp18n7dpc6/vdno1mcd.json
DEBUG:cmdstanpy:input tempfile: /tmp/tmp18n7dpc6/zw4wzhww.json
DEBUG:cmdstanpy:idx 0
DEBUG:cmdstanpy:running CmdStan, num_threads: None
DEBUG:cmdstanpy:CmdStan args: ['/usr/local/lib/python3.7/dist-packages/prophet/stan_model/prophet_model.bin', 'random', 'seed=69579', 'data', 'file=/tmp/tmp18n7dpc6/vdno1mcd.json', 'init=/tmp/tmp18n7dpc6/zw4wzhww.json', 'output', 'file=/tmp/tmp18n7dpc6/prophet_modelr6j6nl0h/prophet_model-20221119131731.csv', 'method=optimize', 'algorithm=lbfgs', 'iter=10000']
13:17:31 - cmdstanpy - INFO - Chain [1] start processing
INFO:cmdstanpy:Chain [1] start processing
13:17:32 - cmdstanpy - INFO - Chain [1] done processing
INFO:cmdstanpy:Chain [1] done processing

4-3.性能評価
得られた予測値と正解値を比較できるように可視化しました。結果としては微妙です。調整無しでは不十分でありアルゴリズムの追加が必要です。
[IN]
import matplotlib.pyplot as plt
model.plot(forecast)
plt.ticklabel_format(style='plain',axis='y') #style='plain':普通の表記, style='sci':指数表記
plt.show()
[OUT]
[IN]
_y_pred = forecast[['ds', 'yhat']]
y_pred = _y_pred[_y_pred['ds']>='2022-5-25']
date_test = y_pred['ds']
import matplotlib.dates as mdates
import japanize_matplotlib
fig, ax = plt.subplots(figsize=(10, 6))
ax.plot(date_test, df_test['y'], label='正解', c='k')
ax.plot(date_test, y_pred['yhat'], label='予測値', c='b')
weeks = mdates.WeekdayLocator(byweekday=mdates.TH)
ax.xaxis.set_major_locator(weeks)
ax.tick_params(axis='x', rotation=90)
ax.grid(); ax.legend();ax.set_title('Nikkei 225の正解値と予測値のトレンド比較')
plt.show()
[OUT]
5.アルゴリズムによる最適化
追って
参考資料
資料1:公式Docs
https://peerj.com/preprints/3190.pdf
あとがき
今まで見たことがない謎のエラーが出てるし”pip install hijri_converter”でも"pip install --upgrade prophet"でも改善されないのでColabで検証したけど、Copilot使えないとやりにくい・・・・
ImportError: cannot import name 'GREGORIAN_RANGE' from 'hijri_converter.ummalqura'この記事が気に入ったらサポートをしてみませんか?